 一篇讓你熟練掌握 MyBatis-Plus!
一篇讓你熟練掌握 MyBatis-Plus!
MyBatis-plus 是一款 Mybatis 增強工具,用于簡化開發,提高效率。下文使用縮寫 mp來簡化表示 MyBatis-plus,本文主要介紹 mp 搭配 Spring Boot 的使用。
注:本文使用的 mp 版本是當前最新的3.4.2,早期版本的差異請自行查閱文檔
官方網站:baomidou.com/
快速入門
?????????1.創建一個Spring Boot項目。?????????
2.導入依賴
《?xml version=“1.0” encoding=“UTF-8”?》
《project xmlns=“http://maven.apache.org/POM/4.0.0” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd”》
《modelVersion》4.0.0《/modelVersion》
《parent》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-starter-parent《/artifactId》
《version》2.3.4.RELEASE《/version》
《relativePath/》
《/parent》
《groupId》com.example《/groupId》
《artifactId》mybatis-plus《/artifactId》
《version》0.0.1-SNAPSHOT《/version》
《name》mybatis-plus《/name》
《properties》
《java.version》1.8《/java.version》
《/properties》
《dependencies》
《dependency》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-starter《/artifactId》
《/dependency》
《dependency》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-starter-test《/artifactId》
《scope》test《/scope》
《/dependency》
《dependency》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-configuration-processor《/artifactId》
《/dependency》
《dependency》
《groupId》com.baomidou《/groupId》
《artifactId》mybatis-plus-boot-starter《/artifactId》
《version》3.4.2《/version》
《/dependency》
《dependency》
《groupId》mysql《/groupId》
《artifactId》mysql-connector-java《/artifactId》
《scope》runtime《/scope》
《/dependency》
《dependency》
《groupId》org.projectlombok《/groupId》
《artifactId》lombok《/artifactId》
《/dependency》
《/dependencies》
《build》
《plugins》
《plugin》
《groupId》org.springframework.boot《/groupId》
《artifactId》spring-boot-maven-plugin《/artifactId》
《/plugin》
《/plugins》
《/build》
《/project》
3.配置數據庫
# application.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc//localhost:3306/yogurt?serverTimezone=Asia/Shanghai
username: root
password: root
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #開啟SQL語句打印
4.創建一個實體類
package com.example.mp.po;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
5.創建一個mapper接口
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
public interface UserMapper extends BaseMapper《User》 { }
6.在SpringBoot啟動類上配置mapper接口的掃描路徑
package com.example.mp;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan(“com.example.mp.mappers”)
public class MybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlusApplication.class, args);
}
}
7.在數據庫中創建表
DROP TABLE IF EXISTS user;
CREATE TABLE user (
id BIGINT(20) PRIMARY KEY NOT NULL COMMENT ‘主鍵’,
name VARCHAR(30) DEFAULT NULL COMMENT ‘姓名’,
age INT(11) DEFAULT NULL COMMENT ‘年齡’,
email VARCHAR(50) DEFAULT NULL COMMENT ‘郵箱’,
manager_id BIGINT(20) DEFAULT NULL COMMENT ‘直屬上級id’,
create_time DATETIME DEFAULT NULL COMMENT ‘創建時間’,
CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user (id)
) ENGINE=INNODB CHARSET=UTF8;
INSERT INTO user (id, name, age ,email, manager_id, create_time) VALUES
(1, ‘大BOSS’, 40, ‘boss@baomidou.com’, NULL, ‘2021-03-22 0900’),
(2, ‘李經理’, 40, ‘boss@baomidou.com’, 1, ‘2021-01-22 0900’),
(3, ‘黃主管’, 40, ‘boss@baomidou.com’, 2, ‘2021-01-22 0900’),
(4, ‘吳組長’, 40, ‘boss@baomidou.com’, 2, ‘2021-02-22 0900’),
(5, ‘小菜’, 40, ‘boss@baomidou.com’, 2, ‘2021-02-22 0900’)
8.編寫一個SpringBoot測試類
package com.example.mp;
import com.example.mp.mappers.UserMapper;
import com.example.mp.po.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
import static org.junit.Assert.*;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SampleTest {
@Autowired
private UserMapper mapper;
@Test
public void testSelect() {
List《User》 list = mapper.selectList(null);
assertEquals(5, list.size());
list.forEach(System.out::println);
}
}
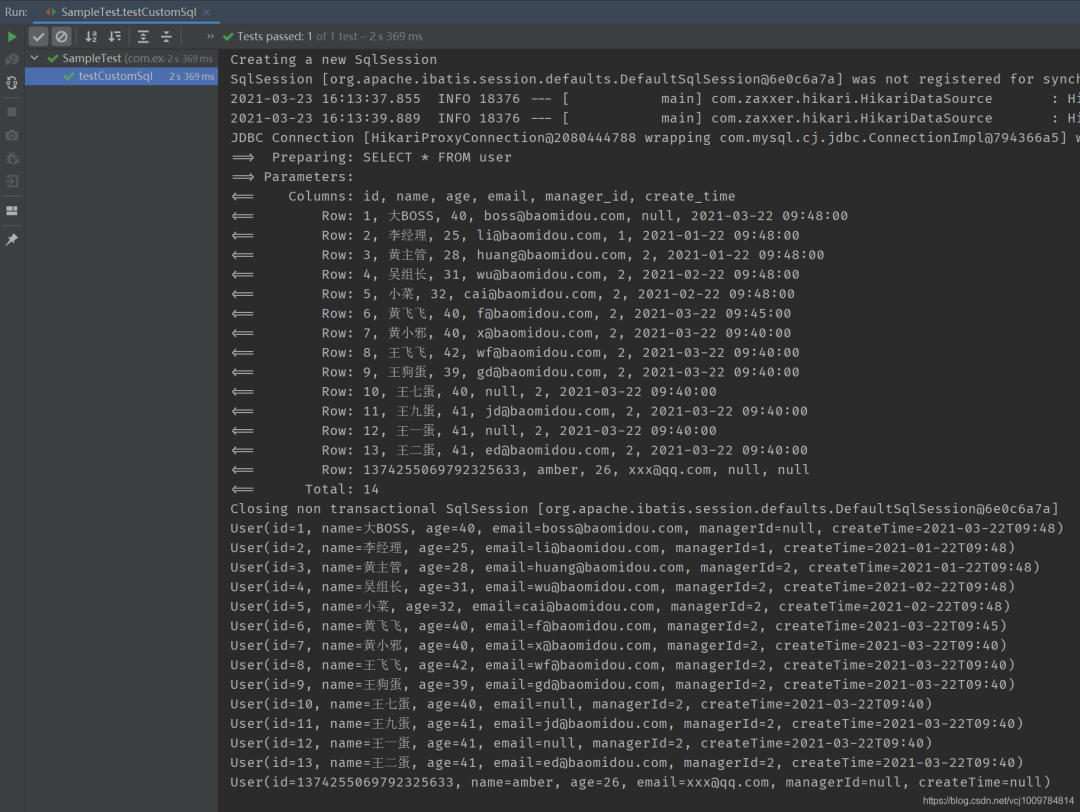
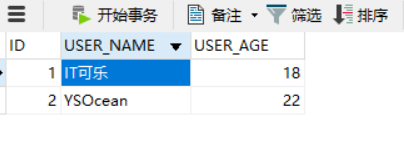
準備工作完成,數據庫情況如下:
項目目錄如下:
運行測試類
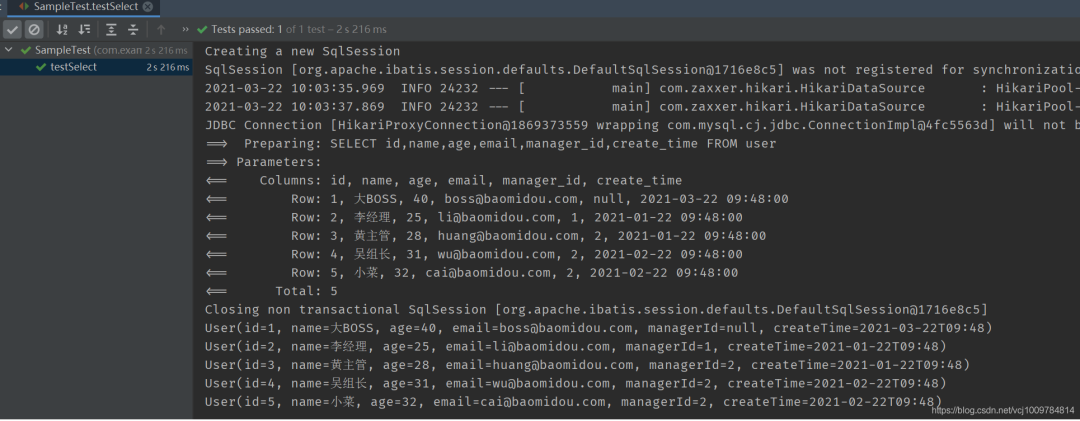
可以看到,針對單表的基本CRUD操作,只需要創建好實體類,并創建一個繼承自BaseMapper的接口即可,可謂非常簡潔。并且,我們注意到,User類中的managerId,createTime屬性,自動和數據庫表中的manager_id,create_time對應了起來,這是因為mp自動做了數據庫下劃線命名,到Java類的駝峰命名之間的轉化。
核心功能
注解
mp一共提供了8個注解,這些注解是用在Java的實體類上面的。
@TableName
注解在類上,指定類和數據庫表的映射關系。實體類的類名(轉成小寫后)和數據庫表名相同時,可以不指定該注解。
@TableId
注解在實體類的某一字段上,表示這個字段對應數據庫表的主鍵。當主鍵名為id時(表中列名為id,實體類中字段名為id),無需使用該注解顯式指定主鍵,mp會自動關聯。若類的字段名和表的列名不一致,可用value屬性指定表的列名。另,這個注解有個重要的屬性type,用于指定主鍵策略。
@TableField
注解在某一字段上,指定Java實體類的字段和數據庫表的列的映射關系。這個注解有如下幾個應用場景。關于Spring項目中的注解,這篇做了詳細介紹:注解介紹
排除非表字段
若Java實體類中某個字段,不對應表中的任何列,它只是用于保存一些額外的,或組裝后的數據,則可以設置exist屬性為false,這樣在對實體對象進行插入時,會忽略這個字段。排除非表字段也可以通過其他方式完成,如使用static或transient關鍵字,但個人覺得不是很合理,不做贅述
字段驗證策略
通過insertStrategy,updateStrategy,whereStrategy屬性進行配置,可以控制在實體對象進行插入,更新,或作為WHERE條件時,對象中的字段要如何組裝到SQL語句中。
字段填充策略
通過fill屬性指定,字段為空時會進行自動填充
@Version
樂觀鎖注解
@EnumValue
注解在枚舉字段上
@TableLogic
邏輯刪除
KeySequence
序列主鍵策略(oracle)
InterceptorIgnore
插件過濾規則
CRUD接口
mp封裝了一些最基礎的CRUD方法,只需要直接繼承mp提供的接口,無需編寫任何SQL,即可食用。mp提供了兩套接口,分別是Mapper CRUD接口和Service CRUD接口。并且mp還提供了條件構造器Wrapper,可以方便地組裝SQL語句中的WHERE條件。
Mapper CRUD接口
只需定義好實體類,然后創建一個接口,繼承mp提供的BaseMapper,即可食用。mp會在mybatis啟動時,自動解析實體類和表的映射關系,并注入帶有通用CRUD方法的mapper。BaseMapper里提供的方法,部分列舉如下:
insert(T entity) 插入一條記錄
deleteById(Serializable id) 根據主鍵id刪除一條記錄
delete(Wrapper《T》 wrapper) 根據條件構造器wrapper進行刪除
selectById(Serializable id) 根據主鍵id進行查找
selectBatchIds(Collection idList) 根據主鍵id進行批量查找
selectByMap(Map《String,Object》 map) 根據map中指定的列名和列值進行等值匹配查找
selectMaps(Wrapper《T》 wrapper) 根據 wrapper 條件,查詢記錄,將查詢結果封裝為一個Map,Map的key為結果的列,value為值
selectList(Wrapper《T》 wrapper) 根據條件構造器wrapper進行查詢
update(T entity, Wrapper《T》 wrapper) 根據條件構造器wrapper進行更新
updateById(T entity)
。。。
下面講解幾個比較特別的方法
selectMaps
BaseMapper接口還提供了一個selectMaps方法,這個方法會將查詢結果封裝為一個Map,Map的key為結果的列,value為值
該方法的使用場景如下:
只查部分列
當某個表的列特別多,而SELECT的時候只需要選取個別列,查詢出的結果也沒必要封裝成Java實體類對象時(只查部分列時,封裝成實體后,實體對象中的很多屬性會是null),則可以用selectMaps,獲取到指定的列后,再自行進行處理即可
比如
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.select(“id”,“name”,“email”).likeRight(“name”,“黃”);
List《Map《String, Object》》 maps = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
進行數據統計
比如
// 按照直屬上級進行分組,查詢每組的平均年齡,最大年齡,最小年齡
/**
select avg(age) avg_age ,min(age) min_age, max(age) max_age from user group by manager_id having sum(age) 《 500;
**/
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.select(“manager_id”, “avg(age) avg_age”, “min(age) min_age”, “max(age) max_age”)
.groupBy(“manager_id”).having(“sum(age) 《 {0}”, 500);
List《Map《String, Object》》 maps = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
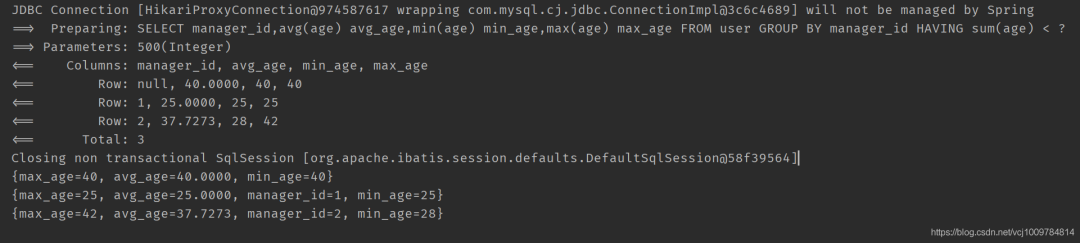
selectObjs
只會返回第一個字段(第一列)的值,其他字段會被舍棄
比如
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.select(“id”, “name”).like(“name”, “黃”);
List《Object》 objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}
得到的結果,只封裝了第一列的id
selectCount
查詢滿足條件的總數,注意,使用這個方法,不能調用QueryWrapper的select方法設置要查詢的列了。這個方法會自動添加select count(1)
比如
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(“name”, “黃”);
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
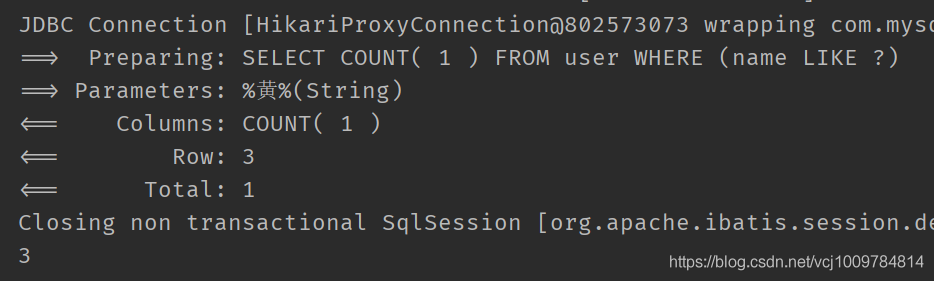
Service CRUD 接口
另外一套CRUD是Service層的,只需要編寫一個接口,繼承IService,并創建一個接口實現類,即可食用。(這個接口提供的CRUD方法,和Mapper接口提供的功能大同小異,比較明顯的區別在于IService支持了更多的批量化操作,如saveBatch,saveOrUpdateBatch等方法。
食用示例如下
1.首先,新建一個接口,繼承IService
package com.example.mp.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.mp.po.User;
public interface UserService extends IService《User》 {
}
2.創建這個接口的實現類,并繼承ServiceImpl,最后打上@Service注解,注冊到Spring容器中,即可食用
package com.example.mp.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.mp.mappers.UserMapper;
import com.example.mp.po.User;
import com.example.mp.service.UserService;
import org.springframework.stereotype.Service;
@Service
public class UserServiceImpl extends ServiceImpl《UserMapper, User》 implements UserService { }
3.測試代碼
package com.example.mp;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.example.mp.po.User;
import com.example.mp.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ServiceTest {
@Autowired
private UserService userService;
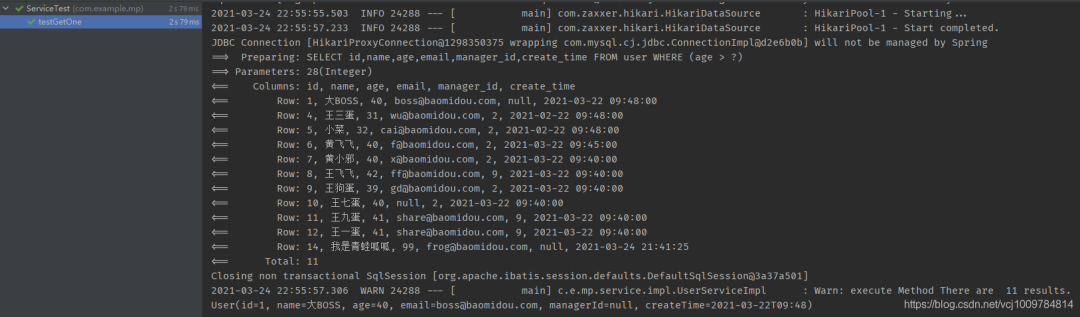
@Test
public void testGetOne() {
LambdaQueryWrapper《User》 wrapper = Wrappers.《User》lambdaQuery();
wrapper.gt(User::getAge, 28);
User one = userService.getOne(wrapper, false); // 第二參數指定為false,使得在查到了多行記錄時,不拋出異常,而返回第一條記錄
System.out.println(one);
}
}
4.結果
另,IService也支持鏈式調用,代碼寫起來非常簡潔,查詢示例如下
@Test
public void testChain() {
List《User》 list = userService.lambdaQuery()
.gt(User::getAge, 39)
.likeRight(User::getName, “王”)
.list();
list.forEach(System.out::println);
}
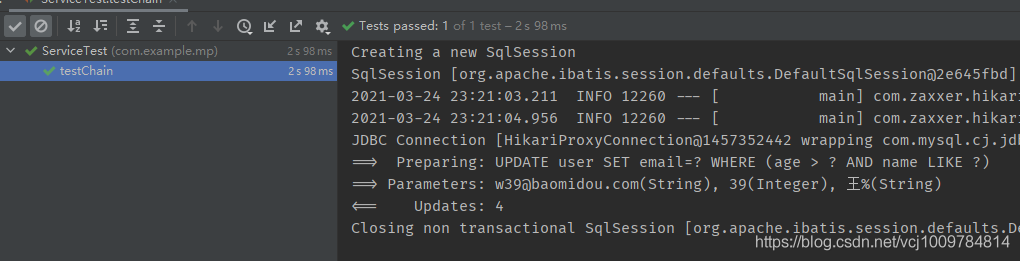
更新示例如下
@Test
public void testChain() {
userService.lambdaUpdate()
.gt(User::getAge, 39)
.likeRight(User::getName, “王”)
.set(User::getEmail, “w39@baomidou.com”)
.update();
}
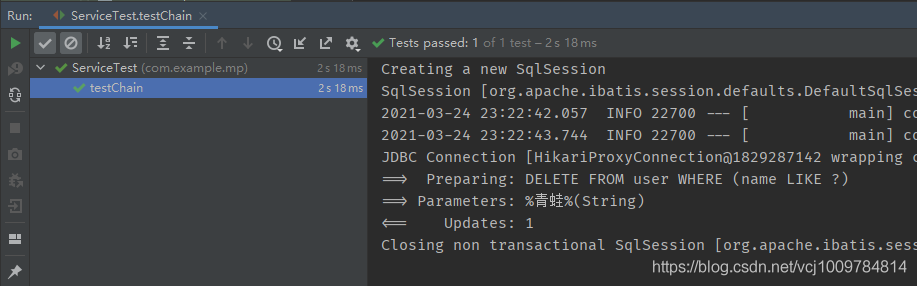
刪除示例如下
@Test
public void testChain() {
userService.lambdaUpdate()
.like(User::getName, “青蛙”)
.remove();
}
條件構造器
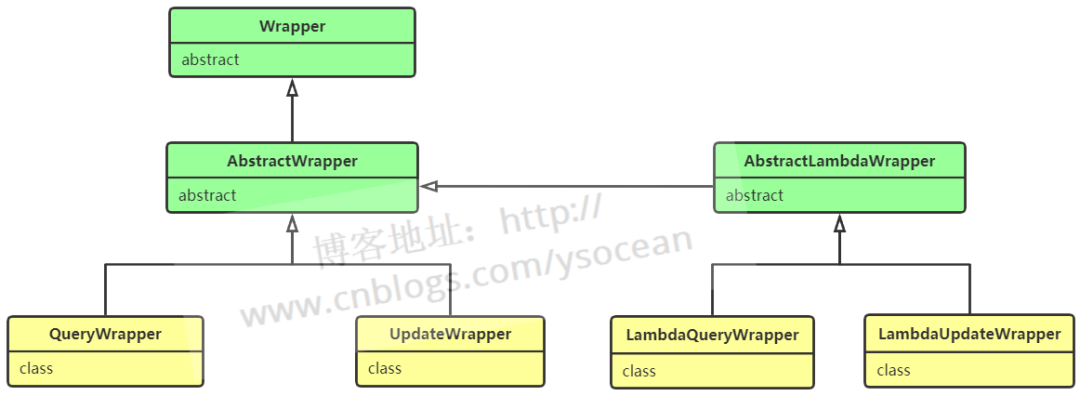
mp讓我覺得極其方便的一點在于其提供了強大的條件構造器Wrapper,可以非常方便的構造WHERE條件。條件構造器主要涉及到3個類,AbstractWrapper。QueryWrapper,UpdateWrapper,它們的類關系如下
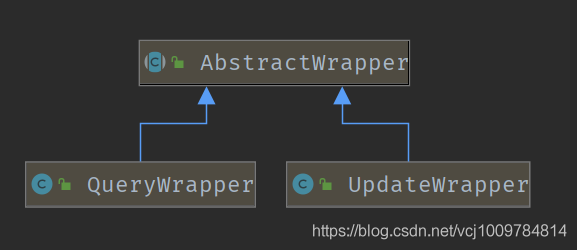
在AbstractWrapper中提供了非常多的方法用于構建WHERE條件,而QueryWrapper針對SELECT語句,提供了select()方法,可自定義需要查詢的列,而UpdateWrapper針對UPDATE語句,提供了set()方法,用于構造set語句。條件構造器也支持lambda表達式,寫起來非常舒爽。
下面對AbstractWrapper中用于構建SQL語句中的WHERE條件的方法進行部分列舉
eq:equals,等于
allEq:all equals,全等于
ne:not equals,不等于
gt:greater than ,大于 》
ge:greater than or equals,大于等于≥
lt:less than,小于《
le:less than or equals,小于等于≤
between:相當于SQL中的BETWEEN
notBetween
like:模糊匹配。like(“name”,“黃”),相當于SQL的name like ‘%黃%’
likeRight:模糊匹配右半邊。likeRight(“name”,“黃”),相當于SQL的name like ‘黃%’
likeLeft:模糊匹配左半邊。likeLeft(“name”,“黃”),相當于SQL的name like ‘%黃’
notLike:notLike(“name”,“黃”),相當于SQL的name not like ‘%黃%’
isNull
isNotNull
in
and:SQL連接符AND
or:SQL連接符OR
apply:用于拼接SQL,該方法可用于數據庫函數,并可以動態傳參
。。。。。。。
使用示例
下面通過一些具體的案例來練習條件構造器的使用。(使用前文創建的user表)
// 案例先展示需要完成的SQL語句,后展示Wrapper的寫法
// 1. 名字中包含佳,且年齡小于25
// SELECT * FROM user WHERE name like ‘%佳%’ AND age 《 25
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(“name”, “佳”).lt(“age”, 25);
List《User》 users = userMapper.selectList(wrapper);
// 下面展示SQL時,僅展示WHERE條件;展示代碼時, 僅展示Wrapper構建部分
// 2. 姓名為黃姓,且年齡大于等于20,小于等于40,且email字段不為空
// name like ‘黃%’ AND age BETWEEN 20 AND 40 AND email is not null
wrapper.likeRight(“name”,“黃”).between(“age”, 20, 40).isNotNull(“email”);
// 3. 姓名為黃姓,或者年齡大于等于40,按照年齡降序排列,年齡相同則按照id升序排列
// name like ‘黃%’ OR age 》= 40 order by age desc, id asc
wrapper.likeRight(“name”,“黃”).or().ge(“age”,40).orderByDesc(“age”).orderByAsc(“id”);
// 4.創建日期為2021年3月22日,并且直屬上級的名字為李姓
// date_format(create_time,‘%Y-%m-%d’) = ‘2021-03-22’ AND manager_id IN (SELECT id FROM user WHERE name like ‘李%’)
wrapper.apply(“date_format(create_time, ‘%Y-%m-%d’) = {0}”, “2021-03-22”) // 建議采用{index}這種方式動態傳參, 可防止SQL注入
.inSql(“manager_id”, “SELECT id FROM user WHERE name like ‘李%’”);
// 上面的apply, 也可以直接使用下面這種方式做字符串拼接,但當這個日期是一個外部參數時,這種方式有SQL注入的風險
wrapper.apply(“date_format(create_time, ‘%Y-%m-%d’) = ‘2021-03-22’”);
// 5. 名字為王姓,并且(年齡小于40,或者郵箱不為空)
// name like ‘王%’ AND (age 《 40 OR email is not null)
wrapper.likeRight(“name”, “王”).and(q -》 q.lt(“age”, 40).or().isNotNull(“email”));
// 6. 名字為王姓,或者(年齡小于40并且年齡大于20并且郵箱不為空)
// name like ‘王%’ OR (age 《 40 AND age 》 20 AND email is not null)
wrapper.likeRight(“name”, “王”).or(
q -》 q.lt(“age”,40)
.gt(“age”,20)
.isNotNull(“email”)
);
// 7. (年齡小于40或者郵箱不為空) 并且名字為王姓
// (age 《 40 OR email is not null) AND name like ‘王%’
wrapper.nested(q -》 q.lt(“age”, 40).or().isNotNull(“email”))
.likeRight(“name”, “王”);
// 8. 年齡為30,31,34,35
// age IN (30,31,34,35)
wrapper.in(“age”, Arrays.asList(30,31,34,35));
// 或
wrapper.inSql(“age”,“30,31,34,35”);
// 9. 年齡為30,31,34,35, 返回滿足條件的第一條記錄
// age IN (30,31,34,35) LIMIT 1
wrapper.in(“age”, Arrays.asList(30,31,34,35)).last(“LIMIT 1”);
// 10. 只選出id, name 列 (QueryWrapper 特有)
// SELECT id, name FROM user;
wrapper.select(“id”, “name”);
// 11. 選出id, name, age, email, 等同于排除 manager_id 和 create_time
// 當列特別多, 而只需要排除個別列時, 采用上面的方式可能需要寫很多個列, 可以采用重載的select方法,指定需要排除的列
wrapper.select(User.class, info -》 {
String columnName = info.getColumn();
return !“create_time”.equals(columnName) && !“manager_id”.equals(columnName);
});
Condition
條件構造器的諸多方法中,均可以指定一個boolean類型的參數condition,用來決定該條件是否加入最后生成的WHERE語句中,比如
String name = “黃”; // 假設name變量是一個外部傳入的參數
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(StringUtils.hasText(name), “name”, name);
// 僅當 StringUtils.hasText(name) 為 true 時, 會拼接這個like語句到WHERE中
// 其實就是對下面代碼的簡化
if (StringUtils.hasText(name)) {
wrapper.like(“name”, name);
}
實體對象作為條件
調用構造函數創建一個Wrapper對象時,可以傳入一個實體對象。后續使用這個Wrapper時,會以實體對象中的非空屬性,構建WHERE條件(默認構建等值匹配的WHERE條件,這個行為可以通過實體類里各個字段上的@TableField注解中的condition屬性進行改變)
示例如下
@Test
public void test3() {
User user = new User();
user.setName(“黃主管”);
user.setAge(28);
QueryWrapper《User》 wrapper = new QueryWrapper《》(user);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
執行結果如下。可以看到,是根據實體對象中的非空屬性,進行了等值匹配查詢。
若希望針對某些屬性,改變等值匹配的行為,則可以在實體類中用@TableField注解進行配置,示例如下
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE) // 配置該字段使用like進行拼接
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
運行下面的測試代碼
@Test
public void test3() {
User user = new User();
user.setName(“黃”);
QueryWrapper《User》 wrapper = new QueryWrapper《》(user);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
從下圖得到的結果來看,對于實體對象中的name字段,采用了like進行拼接

@TableField中配置的condition屬性實則是一個字符串,SqlCondition類中預定義了一些字符串以供選擇
package com.baomidou.mybatisplus.annotation;
public class SqlCondition {
//下面的字符串中, %s 是占位符, 第一個 %s 是列名, 第二個 %s 是列的值
public static final String EQUAL = “%s=#{%s}”;
public static final String NOT_EQUAL = “%s《》#{%s}”;
public static final String LIKE = “%s LIKE CONCAT(‘%%’,#{%s},‘%%’)”;
public static final String LIKE_LEFT = “%s LIKE CONCAT(‘%%’,#{%s})”;
public static final String LIKE_RIGHT = “%s LIKE CONCAT(#{%s},‘%%’)”;
}
SqlCondition中提供的配置比較有限,當我們需要《或》等拼接方式,則需要自己定義。比如
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”) // 這里相當于大于, 其中 》 是字符實體
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
測試如下
@Test
public void test3() {
User user = new User();
user.setName(“黃”);
user.setAge(30);
QueryWrapper《User》 wrapper = new QueryWrapper《》(user);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
從下圖得到的結果,可以看出,name屬性是用like拼接的,而age屬性是用》拼接的

allEq方法
allEq方法傳入一個map,用來做等值匹配
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, “黃飛飛”);
wrapper.allEq(param);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}

當allEq方法傳入的Map中有value為null的元素時,默認會設置為is null
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, null);
wrapper.allEq(param);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
若想忽略map中value為null的元素,可以在調用allEq時,設置參數boolean null2IsNull為false
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, null);
wrapper.allEq(param, false);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
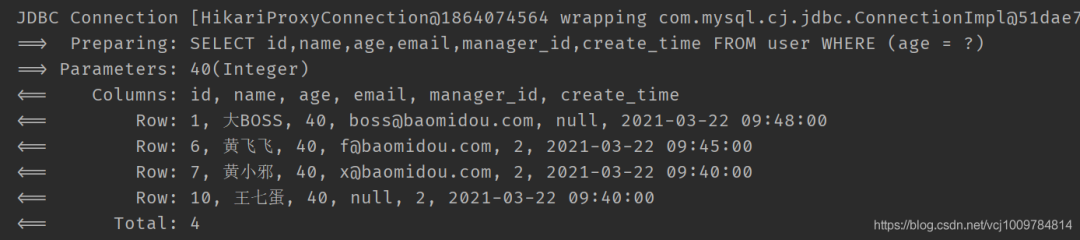
若想要在執行allEq時,過濾掉Map中的某些元素,可以調用allEq的重載方法allEq(BiPredicate《R, V》 filter, Map《R, V》 params)
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
Map《String, Object》 param = new HashMap《》();
param.put(“age”, 40);
param.put(“name”, “黃飛飛”);
wrapper.allEq((k,v) -》 !“name”.equals(k), param); // 過濾掉map中key為name的元素
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
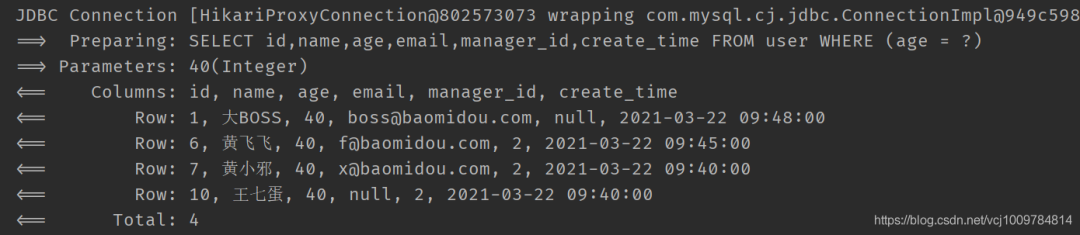
lambda條件構造器
lambda條件構造器,支持lambda表達式,可以不必像普通條件構造器一樣,以字符串形式指定列名,它可以直接以實體類的方法引用來指定列。示例如下
@Test
public void testLambda() {
LambdaQueryWrapper《User》 wrapper = new LambdaQueryWrapper《》();
wrapper.like(User::getName, “黃”).lt(User::getAge, 30);
List《User》 users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
像普通的條件構造器,列名是用字符串的形式指定,無法在編譯期進行列名合法性的檢查,這就不如lambda條件構造器來的優雅。
另外,還有個鏈式lambda條件構造器,使用示例如下
@Test
public void testLambda() {
LambdaQueryChainWrapper《User》 chainWrapper = new LambdaQueryChainWrapper《》(userMapper);
List《User》 users = chainWrapper.like(User::getName, “黃”).gt(User::getAge, 30).list();
users.forEach(System.out::println);
}
更新操作
上面介紹的都是查詢操作,現在來講更新和刪除操作。
BaseMapper中提供了2個更新方法
updateById(T entity)
根據入參entity的id(主鍵)進行更新,對于entity中非空的屬性,會出現在UPDATE語句的SET后面,即entity中非空的屬性,會被更新到數據庫,示例如下
@RunWith(SpringRunner.class)
@SpringBootTest
public class UpdateTest {
@Autowired
private UserMapper userMapper;
@Test
public void testUpdate() {
User user = new User();
user.setId(2L);
user.setAge(18);
userMapper.updateById(user);
}
}
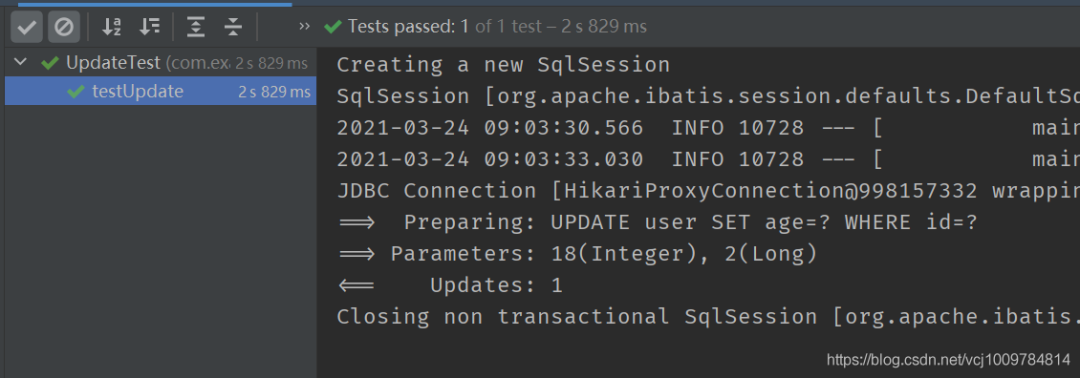
update(T entity, Wrapper《T》 wrapper)
根據實體entity和條件構造器wrapper進行更新,示例如下
@Test
public void testUpdate2() {
User user = new User();
user.setName(“王三蛋”);
LambdaUpdateWrapper《User》 wrapper = new LambdaUpdateWrapper《》();
wrapper.between(User::getAge, 26,31).likeRight(User::getName,“吳”);
userMapper.update(user, wrapper);
}
額外演示一下,把實體對象傳入Wrapper,即用實體對象構造WHERE條件的案例
@Test
public void testUpdate3() {
User whereUser = new User();
whereUser.setAge(40);
whereUser.setName(“王”);
LambdaUpdateWrapper《User》 wrapper = new LambdaUpdateWrapper《》(whereUser);
User user = new User();
user.setEmail(“share@baomidou.com”);
user.setManagerId(10L);
userMapper.update(user, wrapper);
}
注意到我們的User類中,對name屬性和age屬性進行了如下的設置
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”)
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
執行結果
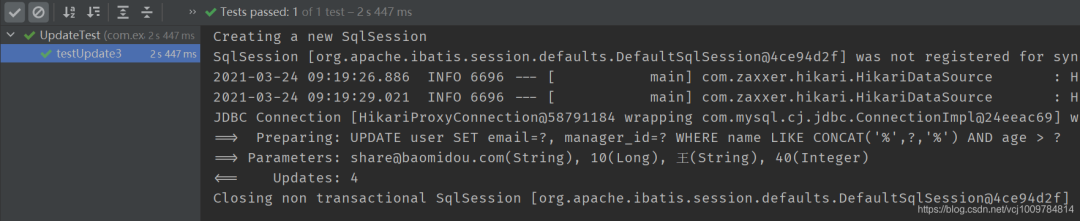
再額外演示一下,鏈式lambda條件構造器的使用
@Test
public void testUpdate5() {
LambdaUpdateChainWrapper《User》 wrapper = new LambdaUpdateChainWrapper《》(userMapper);
wrapper.likeRight(User::getEmail, “share”)
.like(User::getName, “飛飛”)
.set(User::getEmail, “ff@baomidou.com”)
.update();
}
反思
由于BaseMapper提供的2個更新方法都是傳入一個實體對象去執行更新,這在需要更新的列比較多時還好,若想要更新的只有那么一列,或者兩列,則創建一個實體對象就顯得有點麻煩。針對這種情況,UpdateWrapper提供有set方法,可以手動拼接SQL中的SET語句,此時可以不必傳入實體對象,示例如下
@Test
public void testUpdate4() {
LambdaUpdateWrapper《User》 wrapper = new LambdaUpdateWrapper《》();
wrapper.likeRight(User::getEmail, “share”).set(User::getManagerId, 9L);
userMapper.update(null, wrapper);
}
刪除操作
BaseMapper一共提供了如下幾個用于刪除的方法
deleteById 根據主鍵id進行刪除
deleteBatchIds 根據主鍵id進行批量刪除
deleteByMap 根據Map進行刪除(Map中的key為列名,value為值,根據列和值進行等值匹配)
delete(Wrapper《T》 wrapper) 根據條件構造器Wrapper進行刪除
與前面查詢和更新的操作大同小異,不做贅述
自定義SQL
當mp提供的方法還不能滿足需求時,則可以自定義SQL。
原生mybatis
示例如下
注解方式
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* @Author yogurtzzz
* @Date 2021/3/18 11:21
**/
public interface UserMapper extends BaseMapper《User》 {
@Select(“select * from user”)
List《User》 selectRaw();
}
xml方式
《?xml version=“1.0” encoding=“UTF-8”?》
《!DOCTYPE mapper PUBLIC “-//mybatis.org//DTD Mapper 3.0//EN” “http://mybatis.org/dtd/mybatis-3-mapper.dtd”》
《mapper namespace=“com.example.mp.mappers.UserMapper”》
《select id=“selectRaw” resultType=“com.example.mp.po.User”》
SELECT * FROM user
《/select》
《/mapper》
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper《User》 {
List《User》 selectRaw();
}
使用xml時,若xml文件與mapper接口文件不在同一目錄下,則需要在application.yml中配置mapper.xml的存放路徑
mybatis-plus:
mapper-locations: /mappers/*
若有多個地方存放mapper,則用數組形式進行配置
mybatis-plus:
mapper-locations:
- /mappers/*
- /com/example/mp/*
測試代碼如下
@Test
public void testCustomRawSql() {
List《User》 users = userMapper.selectRaw();
users.forEach(System.out::println);
}
結果
mybatis-plus
也可以使用mp提供的Wrapper條件構造器,來自定義SQL
示例如下
注解方式
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.toolkit.Constants;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper《User》 {
// SQL中不寫WHERE關鍵字,且固定使用${ew.customSqlSegment}
@Select(“select * from user ${ew.customSqlSegment}”)
List《User》 findAll(@Param(Constants.WRAPPER)Wrapper《User》 wrapper);
}
xml方式
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import java.util.List;
public interface UserMapper extends BaseMapper《User》 {
List《User》 findAll(Wrapper《User》 wrapper);
}
《?xml version=“1.0” encoding=“UTF-8”?》
《!DOCTYPE mapper PUBLIC “-//mybatis.org//DTD Mapper 3.0//EN” “http://mybatis.org/dtd/mybatis-3-mapper.dtd”》
《mapper namespace=“com.example.mp.mappers.UserMapper”》
《select id=“findAll” resultType=“com.example.mp.po.User”》
SELECT * FROM user ${ew.customSqlSegment}
《/select》
《/mapper》
分頁查詢
BaseMapper中提供了2個方法進行分頁查詢,分別是selectPage和selectMapsPage,前者會將查詢的結果封裝成Java實體對象,后者會封裝成Map《String,Object》。分頁查詢的食用示例如下
1. 創建mp的分頁攔截器,注冊到Spring容器中
package com.example.mp.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/** 新版mp **/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
/** 舊版mp 用 PaginationInterceptor **/
}
2. 執行分頁查詢
@Test
public void testPage() {
LambdaQueryWrapper《User》 wrapper = new LambdaQueryWrapper《》();
wrapper.ge(User::getAge, 28);
// 設置分頁信息, 查第3頁, 每頁2條數據
Page《User》 page = new Page《》(3, 2);
// 執行分頁查詢
Page《User》 userPage = userMapper.selectPage(page, wrapper);
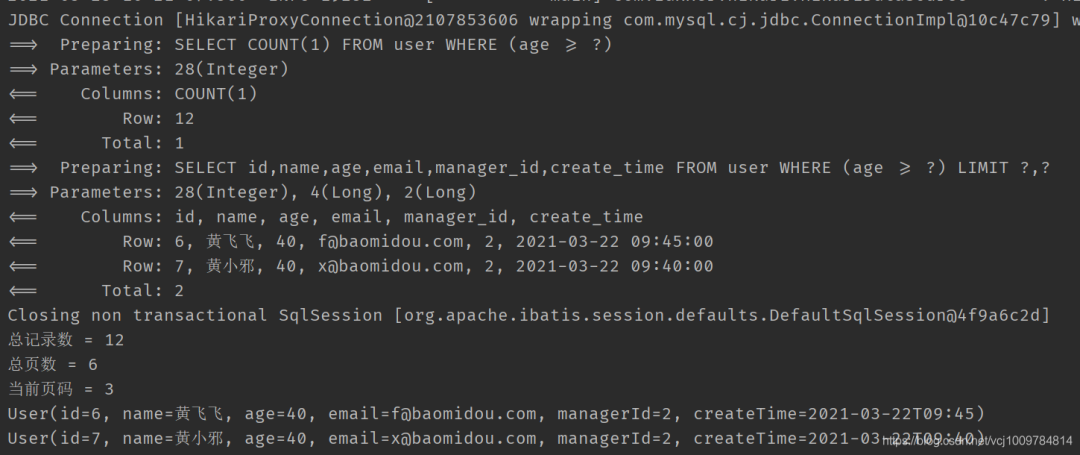
System.out.println(“總記錄數 = ” + userPage.getTotal());
System.out.println(“總頁數 = ” + userPage.getPages());
System.out.println(“當前頁碼 = ” + userPage.getCurrent());
// 獲取分頁查詢結果
List《User》 records = userPage.getRecords();
records.forEach(System.out::println);
}
3. 結果
4. 其他
注意到,分頁查詢總共發出了2次SQL,一次查總記錄數,一次查具體數據。若希望不查總記錄數,僅查分頁結果。可以通過Page的重載構造函數,指定isSearchCount為false即可
public Page(long current, long size, boolean isSearchCount)
在實際開發中,可能遇到多表聯查的場景,此時BaseMapper中提供的單表分頁查詢的方法無法滿足需求,需要自定義SQL,示例如下(使用單表查詢的SQL進行演示,實際進行多表聯查時,修改SQL語句即可)
1. 在mapper接口中定義一個函數,接收一個Page對象為參數,并編寫自定義SQL
// 這里采用純注解方式。當然,若SQL比較復雜,建議還是采用XML的方式
@Select(“SELECT * FROM user ${ew.customSqlSegment}”)
Page《User》 selectUserPage(Page《User》 page, @Param(Constants.WRAPPER) Wrapper《User》 wrapper);
2. 執行查詢
@Test
public void testPage2() {
LambdaQueryWrapper《User》 wrapper = new LambdaQueryWrapper《》();
wrapper.ge(User::getAge, 28).likeRight(User::getName, “王”);
Page《User》 page = new Page《》(3,2);
Page《User》 userPage = userMapper.selectUserPage(page, wrapper);
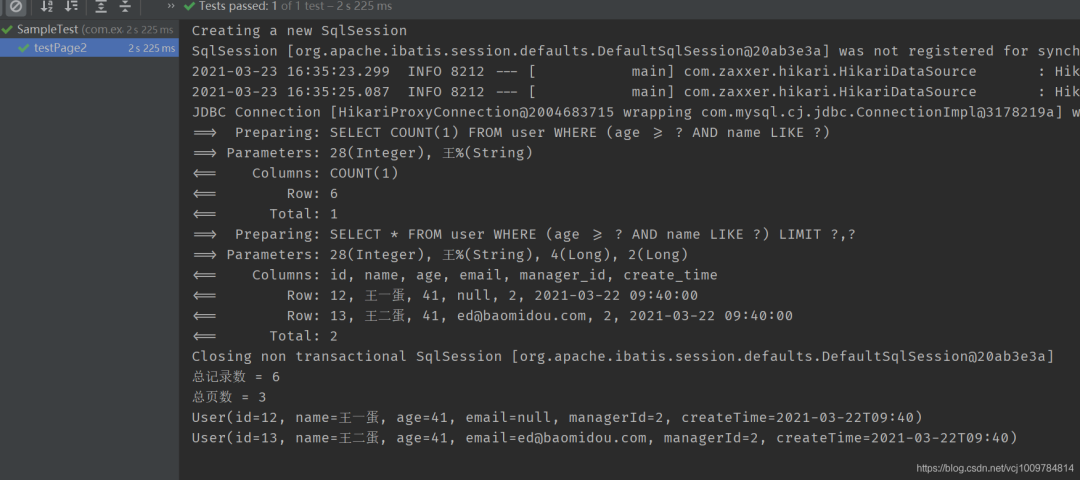
System.out.println(“總記錄數 = ” + userPage.getTotal());
System.out.println(“總頁數 = ” + userPage.getPages());
userPage.getRecords().forEach(System.out::println);
}
3. 結果
AR模式
ActiveRecord模式,通過操作實體對象,直接操作數據庫表。與ORM有點類似。
示例如下
讓實體類User繼承自Model
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.Data;
import lombok.EqualsAndHashCode;
import java.time.LocalDateTime;
@EqualsAndHashCode(callSuper = false)
@Data
public class User extends Model《User》 {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”)
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
直接調用實體對象上的方法
@Test
public void insertAr() {
User user = new User();
user.setId(15L);
user.setName(“我是AR豬”);
user.setAge(1);
user.setEmail(“ar@baomidou.com”);
user.setManagerId(1L);
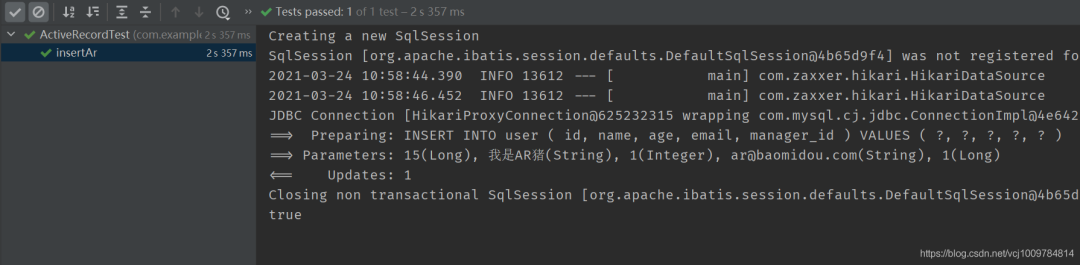
boolean success = user.insert(); // 插入
System.out.println(success);
}
結果
其他示例
// 查詢
@Test
public void selectAr() {
User user = new User();
user.setId(15L);
User result = user.selectById();
System.out.println(result);
}
// 更新
@Test
public void updateAr() {
User user = new User();
user.setId(15L);
user.setName(“王全蛋”);
user.updateById();
}
//刪除
@Test
public void deleteAr() {
User user = new User();
user.setId(15L);
user.deleteById();
}
主鍵策略
在定義實體類時,用@TableId指定主鍵,而其type屬性,可以指定主鍵策略。
mp支持多種主鍵策略,默認的策略是基于雪花算法的自增id。全部主鍵策略定義在了枚舉類IdType中,IdType有如下的取值
AUTO
數據庫ID自增,依賴于數據庫。在插入操作生成SQL語句時,不會插入主鍵這一列
NONE
未設置主鍵類型。若在代碼中沒有手動設置主鍵,則會根據主鍵的全局策略自動生成(默認的主鍵全局策略是基于雪花算法的自增ID)
INPUT
需要手動設置主鍵,若不設置。插入操作生成SQL語句時,主鍵這一列的值會是null。oracle的序列主鍵需要使用這種方式
ASSIGN_ID
當沒有手動設置主鍵,即實體類中的主鍵屬性為空時,才會自動填充,使用雪花算法
ASSIGN_UUID
當實體類的主鍵屬性為空時,才會自動填充,使用UUID
。。。。(還有幾種是已過時的,就不再列舉)
可以針對每個實體類,使用@TableId注解指定該實體類的主鍵策略,這可以理解為局部策略。若希望對所有的實體類,都采用同一種主鍵策略,挨個在每個實體類上進行配置,則太麻煩了,此時可以用主鍵的全局策略。只需要在application.yml進行配置即可。比如,配置了全局采用自增主鍵策略
# application.yml
mybatis-plus:
global-config:
db-config:
id-type: auto
下面對不同主鍵策略的行為進行演示
AUTO
在User上對id屬性加上注解,然后將MYSQL的user表修改其主鍵為自增。
@EqualsAndHashCode(callSuper = false)
@Data
public class User extends Model《User》 {
@TableId(type = IdType.AUTO)
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = “%s 》 #{%s}”)
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
測試
@Test
public void testAuto() {
User user = new User();
user.setName(“我是青蛙呱呱”);
user.setAge(99);
user.setEmail(“frog@baomidou.com”);
user.setCreateTime(LocalDateTime.now());
userMapper.insert(user);
System.out.println(user.getId());
}
結果
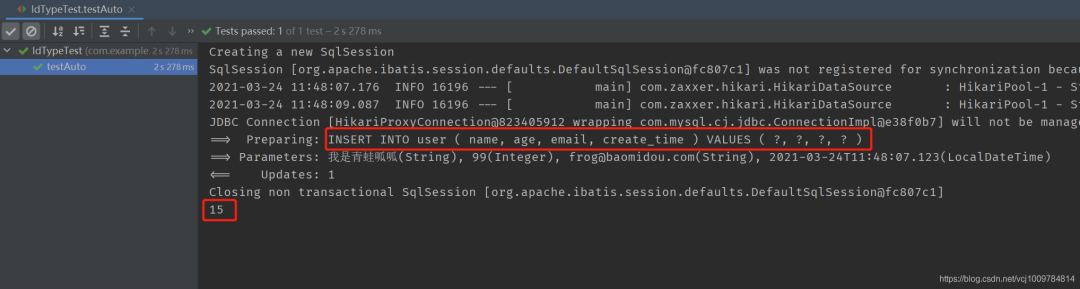
可以看到,代碼中沒有設置主鍵ID,發出的SQL語句中也沒有設置主鍵ID,并且插入結束后,主鍵ID會被寫回到實體對象。
NONE
在MYSQL的user表中,去掉主鍵自增。然后修改User類(若不配置@TableId注解,默認主鍵策略也是NONE)
@TableId(type = IdType.NONE)
private Long id;
插入時,若實體類的主鍵ID有值,則使用之;若主鍵ID為空,則使用主鍵全局策略,來生成一個ID。
其余的策略類似,不贅述
小結
AUTO依賴于數據庫的自增主鍵,插入時,實體對象無需設置主鍵,插入成功后,主鍵會被寫回實體對象。
INPUT完全依賴于用戶輸入。實體對象中主鍵ID是什么,插入到數據庫時就設置什么。若有值便設置值,若為null則設置null
其余的幾個策略,都是在實體對象中主鍵ID為空時,才會自動生成。
NONE會跟隨全局策略,ASSIGN_ID采用雪花算法,ASSIGN_UUID采用UUID
全局配置,在application.yml中進行即可;針對單個實體類的局部配置,使用@TableId即可。對于某個實體類,若它有局部主鍵策略,則采用之,否則,跟隨全局策略。
配置
mybatis plus有許多可配置項,可在application.yml中進行配置,如上面的全局主鍵策略。下面列舉部分配置項
基本配置
configLocation:若有單獨的mybatis配置,用這個注解指定mybatis的配置文件(mybatis的全局配置文件)
mapperLocations:mybatis mapper所對應的xml文件的位置
typeAliasesPackage:mybatis的別名包掃描路徑
。。。。。
進階配置
mapUnderscoreToCamelCase:是否開啟自動駝峰命名規則映射。(默認開啟)
dbTpe:數據庫類型。一般不用配,會根據數據庫連接url自動識別
fieldStrategy:(已過時)字段驗證策略。該配置項在最新版的mp文檔中已經找不到了,被細分成了insertStrategy,updateStrategy,selectStrategy。默認值是NOT_NULL,即對于實體對象中非空的字段,才會組裝到最終的SQL語句中。
有如下幾種可選配置
這個配置項,可在application.yml中進行全局配置,也可以在某一實體類中,對某一字段用@TableField注解進行局部配置
這個字段驗證策略有什么用呢?在UPDATE操作中能夠體現出來,若用一個User對象執行UPDATE操作,我們希望只對User對象中非空的屬性,更新到數據庫中,其他屬性不做更新,則NOT_NULL可以滿足需求。
而若updateStrategy配置為IGNORED,則不會進行非空判斷,會將實體對象中的全部屬性如實組裝到SQL中,這樣,執行UPDATE時,可能就將一些不想更新的字段,設置為了NULL。
IGNORED:忽略校驗。即,不做校驗。實體對象中的全部字段,無論值是什么,都如實地被組裝到SQL語句中(為NULL的字段在SQL語句中就組裝為NULL)。
NOT_NULL:非NULL校驗。只會將非NULL的字段組裝到SQL語句中
NOT_EMPTY:非空校驗。當有字段是字符串類型時,只組裝非空字符串;對其他類型的字段,等同于NOT_NULL
NEVER:不加入SQL。所有字段不加入到SQL語句
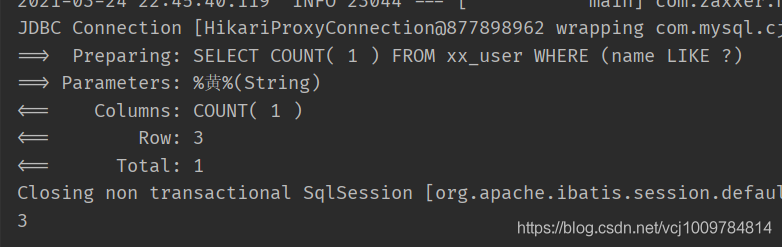
tablePrefix:添加表名前綴
比如
mybatis-plus:
global-config:
db-config:
table-prefix: xx_
然后將MYSQL中的表做一下修改。但Java實體類保持不變(仍然為User)。
測試
@Test
public void test3() {
QueryWrapper《User》 wrapper = new QueryWrapper《》();
wrapper.like(“name”, “黃”);
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
可以看到拼接出來的SQL,在表名前面添加了前綴
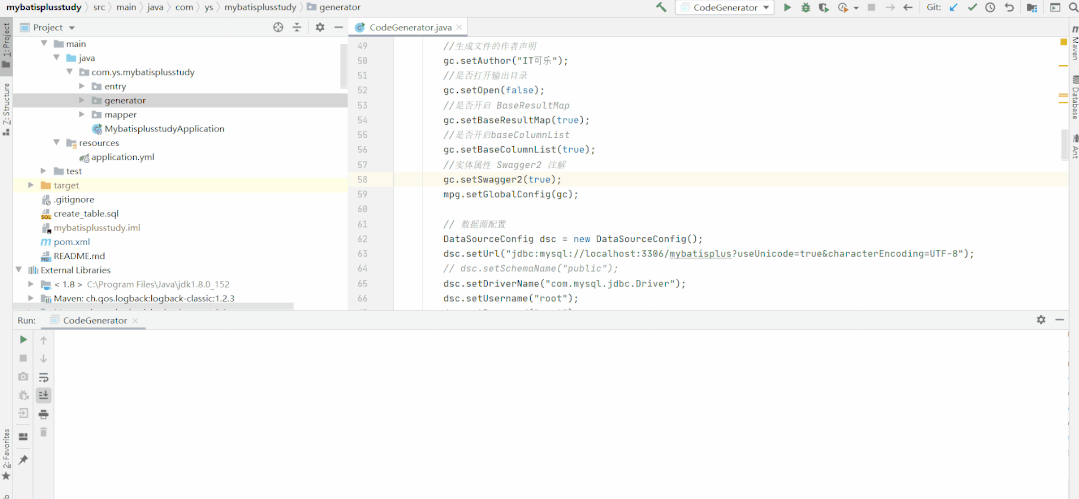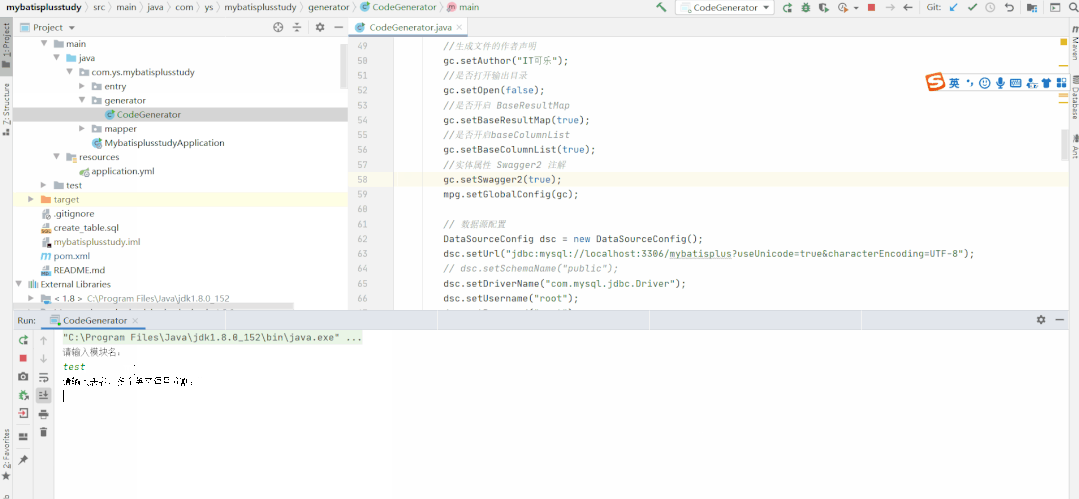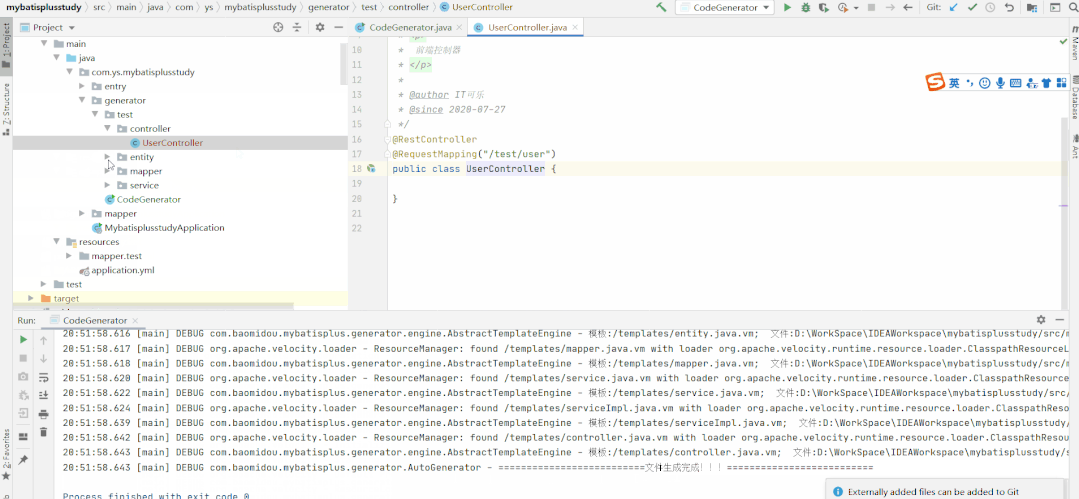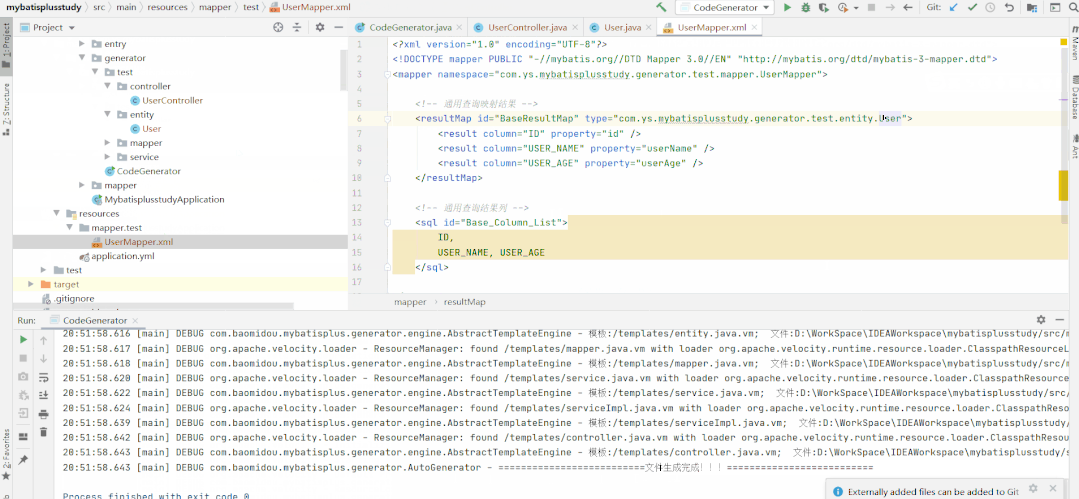
代碼生成器
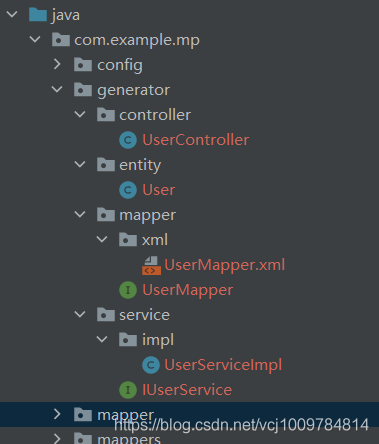
mp提供一個生成器,可快速生成Entity實體類,Mapper接口,Service,Controller等全套代碼。代碼生成的開源項目:一鍵生成前后端代碼!
示例如下
public class GeneratorTest {
@Test
public void generate() {
AutoGenerator generator = new AutoGenerator();
// 全局配置
GlobalConfig config = new GlobalConfig();
String projectPath = System.getProperty(“user.dir”);
// 設置輸出到的目錄
config.setOutputDir(projectPath + “/src/main/java”);
config.setAuthor(“yogurt”);
// 生成結束后是否打開文件夾
config.setOpen(false);
// 全局配置添加到 generator 上
generator.setGlobalConfig(config);
// 數據源配置
DataSourceConfig dataSourceConfig = new DataSourceConfig();
dataSourceConfig.setUrl(“jdbc//localhost:3306/yogurt?serverTimezone=Asia/Shanghai”);
dataSourceConfig.setDriverName(“com.mysql.cj.jdbc.Driver”);
dataSourceConfig.setUsername(“root”);
dataSourceConfig.setPassword(“root”);
// 數據源配置添加到 generator
generator.setDataSource(dataSourceConfig);
// 包配置, 生成的代碼放在哪個包下
PackageConfig packageConfig = new PackageConfig();
packageConfig.setParent(“com.example.mp.generator”);
// 包配置添加到 generator
generator.setPackageInfo(packageConfig);
// 策略配置
StrategyConfig strategyConfig = new StrategyConfig();
// 下劃線駝峰命名轉換
strategyConfig.setNaming(NamingStrategy.underline_to_camel);
strategyConfig.setColumnNaming(NamingStrategy.underline_to_camel);
// 開啟lombok
strategyConfig.setEntityLombokModel(true);
// 開啟RestController
strategyConfig.setRestControllerStyle(true);
generator.setStrategy(strategyConfig);
generator.setTemplateEngine(new FreemarkerTemplateEngine());
// 開始生成
generator.execute();
}
}
運行后,可以看到生成了如下圖所示的全套代碼
高級功能
高級功能的演示需要用到一張新的表user2
DROP TABLE IF EXISTS user2;
CREATE TABLE user2 (
id BIGINT(20) PRIMARY KEY NOT NULL COMMENT ‘主鍵id’,
name VARCHAR(30) DEFAULT NULL COMMENT ‘姓名’,
age INT(11) DEFAULT NULL COMMENT ‘年齡’,
email VARCHAR(50) DEFAULT NULL COMMENT ‘郵箱’,
manager_id BIGINT(20) DEFAULT NULL COMMENT ‘直屬上級id’,
create_time DATETIME DEFAULT NULL COMMENT ‘創建時間’,
update_time DATETIME DEFAULT NULL COMMENT ‘修改時間’,
version INT(11) DEFAULT ‘1’ COMMENT ‘版本’,
deleted INT(1) DEFAULT ‘0’ COMMENT ‘邏輯刪除標識,0-未刪除,1-已刪除’,
CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user2(id)
) ENGINE = INNODB CHARSET=UTF8;
INSERT INTO user2(id, name, age, email, manager_id, create_time)
VALUES
(1, ‘老板’, 40 ,‘boss@baomidou.com’ ,NULL, ‘2021-03-28 1340’),
(2, ‘王狗蛋’, 40 ,‘gd@baomidou.com’ ,1, ‘2021-03-28 1340’),
(3, ‘王雞蛋’, 40 ,‘jd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(4, ‘王鴨蛋’, 40 ,‘yd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(5, ‘王豬蛋’, 40 ,‘zd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(6, ‘王軟蛋’, 40 ,‘rd@baomidou.com’ ,2, ‘2021-03-28 1340’),
(7, ‘王鐵蛋’, 40 ,‘td@baomidou.com’ ,2, ‘2021-03-28 1340’)
并創建對應的實體類User2
package com.example.mp.po;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
以及Mapper接口
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User2;
public interface User2Mapper extends BaseMapper《User2》 { }
邏輯刪除
首先,為什么要有邏輯刪除呢?直接刪掉不行嗎?當然可以,但日后若想要恢復,或者需要查看這些數據,就做不到了。邏輯刪除是為了方便數據恢復,和保護數據本身價值的一種方案。
日常中,我們在電腦中刪除一個文件后,也僅僅是把該文件放入了回收站,日后若有需要還能進行查看或恢復。當我們確定不再需要某個文件,可以將其從回收站中徹底刪除。這也是類似的道理。
mp提供的邏輯刪除實現起來非常簡單
只需要在application.yml中進行邏輯刪除的相關配置即可
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 全局邏輯刪除的實體字段名
logic-delete-value: 1 # 邏輯已刪除值(默認為1)
logic-not-delete-value: 0 # 邏輯未刪除值(默認為0)
# 若邏輯已刪除和未刪除的值和默認值一樣,則可以不配置這2項
測試代碼
package com.example.mp;
import com.example.mp.mappers.User2Mapper;
import com.example.mp.po.User2;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class LogicDeleteTest {
@Autowired
private User2Mapper mapper;
@Test
public void testLogicDel() {
int i = mapper.deleteById(6);
System.out.println(“rowAffected = ” + i);
}
}
結果
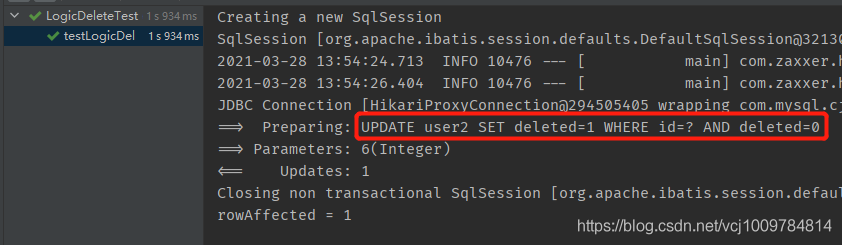
可以看到,發出的SQL不再是DELETE,而是UPDATE
此時我們再執行一次SELECT
@Test
public void testSelect() {
List《User2》 users = mapper.selectList(null);
}
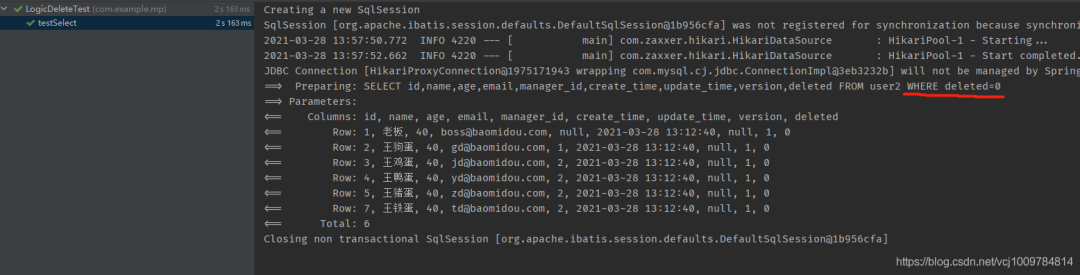
可以看到,發出的SQL語句,會自動在WHERE后面拼接邏輯未刪除的條件。查詢出來的結果中,沒有了id為6的王軟蛋。
若想要SELECT的列,不包括邏輯刪除的那一列,則可以在實體類中通過@TableField進行配置
@TableField(select = false)
private Integer deleted;
可以看到下圖的執行結果中,SELECT中已經不包含deleted這一列了
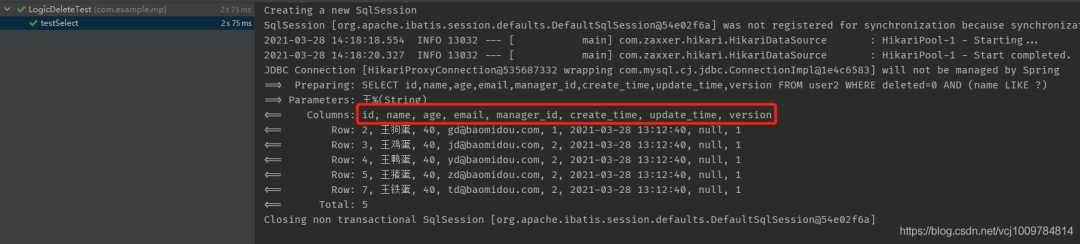
前面在application.yml中做的配置,是全局的。通常來說,對于多個表,我們也會統一邏輯刪除字段的名稱,統一邏輯已刪除和未刪除的值,所以全局配置即可。當然,若要對某些表進行單獨配置,在實體類的對應字段上使用@TableLogic即可
@TableLogic(value = “0”, delval = “1”)
private Integer deleted;
小結
開啟mp的邏輯刪除后,會對SQL產生如下的影響
INSERT語句:沒有影響
SELECT語句:追加WHERE條件,過濾掉已刪除的數據
UPDATE語句:追加WHERE條件,防止更新到已刪除的數據
DELETE語句:轉變為UPDATE語句
注意,上述的影響,只針對mp自動注入的SQL生效。如果是自己手動添加的自定義SQL,則不會生效。比如
public interface User2Mapper extends BaseMapper《User2》 {
@Select(“select * from user2”)
List《User2》 selectRaw();
}
調用這個selectRaw,則mp的邏輯刪除不會生效。
另,邏輯刪除可在application.yml中進行全局配置,也可在實體類中用@TableLogic進行局部配置。
自動填充
表中常常會有“新增時間”,“修改時間”,“操作人” 等字段。比較原始的方式,是每次插入或更新時,手動進行設置。mp可以通過配置,對某些字段進行自動填充,食用示例如下
1. 在實體類中的某些字段上,通過@TableField設置自動填充
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
@TableField(fill = FieldFill.INSERT) // 插入時自動填充
private LocalDateTime createTime;
@TableField(fill = FieldFill.UPDATE) // 更新時自動填充
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
2. 實現自動填充處理器
package com.example.mp.component;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component //需要注冊到Spring容器中
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
// 插入時自動填充
// 注意第二個參數要填寫實體類中的字段名稱,而不是表的列名稱
strictFillStrategy(metaObject, “createTime”, LocalDateTime::now);
}
@Override
public void updateFill(MetaObject metaObject) {
// 更新時自動填充
strictFillStrategy(metaObject, “updateTime”, LocalDateTime::now);
}
}
測試
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName(“王一蛋”);
user.setAge(29);
user.setEmail(“yd@baomidou.com”);
user.setManagerId(2L);
mapper.insert(user);
}
根據下圖結果,可以看到對createTime進行了自動填充
注意,自動填充僅在該字段為空時會生效,若該字段不為空,則直接使用已有的值。如下
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName(“王一蛋”);
user.setAge(29);
user.setEmail(“yd@baomidou.com”);
user.setManagerId(2L);
user.setCreateTime(LocalDateTime.of(2000,1,1,8,0,0));
mapper.insert(user);
}

更新時的自動填充,測試如下
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName(“王一蛋”);
user.setAge(99);
mapper.updateById(user);
}

樂觀鎖插件
當出現并發操作時,需要確保各個用戶對數據的操作不產生沖突,此時需要一種并發控制手段。悲觀鎖的方法是,在對數據庫的一條記錄進行修改時,先直接加鎖(數據庫的鎖機制),鎖定這條數據,然后再進行操作;而樂觀鎖,正如其名,它先假設不存在沖突情況,而在實際進行數據操作時,再檢查是否沖突。樂觀鎖的一種通常實現是版本號,在MySQL中也有名為MVCC的基于版本號的并發事務控制。
在讀多寫少的場景下,樂觀鎖比較適用,能夠減少加鎖操作導致的性能開銷,提高系統吞吐量。
在寫多讀少的場景下,悲觀鎖比較使用,否則會因為樂觀鎖不斷失敗重試,反而導致性能下降。
樂觀鎖的實現如下:
取出記錄時,獲取當前version
更新時,帶上這個version
執行更新時, set version = newVersion where version = oldVersion
如果oldVersion與數據庫中的version不一致,就更新失敗
這種思想和CAS(Compare And Swap)非常相似。
樂觀鎖的實現步驟如下
1. 配置樂觀鎖插件
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/** 3.4.0以后的mp版本,推薦用如下的配置方式 **/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
/** 舊版mp可以采用如下方式。注意新舊版本中,新版的類,名稱帶有Inner, 舊版的不帶, 不要配錯了 **/
/*
@Bean
public OptimisticLockerInterceptor opLocker() {
return new OptimisticLockerInterceptor();
}
*/
}
2. 在實體類中表示版本的字段上添加注解@Version
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@Version
private Integer version;
private Integer deleted;
}
測試代碼
@Test
public void testOpLocker() {
int version = 1; // 假設這個version是先前查詢時獲得的
User2 user = new User2();
user.setId(8L);
user.setEmail(“version@baomidou.com”);
user.setVersion(version);
int i = mapper.updateById(user);
}
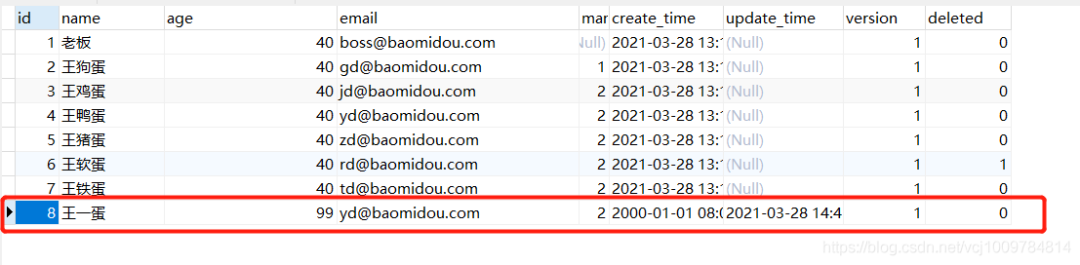
執行之前先看一下數據庫的情況
根據下圖執行結果,可以看到SQL語句中添加了version相關的操作
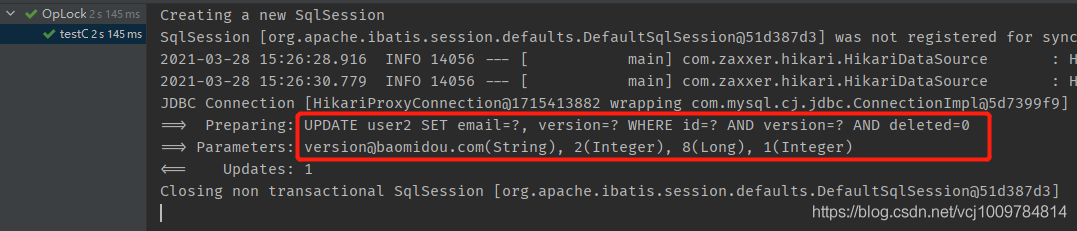
當UPDATE返回了1,表示影響行數為1,則更新成功。反之,由于WHERE后面的version與數據庫中的不一致,匹配不到任何記錄,則影響行數為0,表示更新失敗。更新成功后,新的version會被封裝回實體對象中。
實體類中version字段,類型只支持int,long,Date,Timestamp,LocalDateTime
注意,樂觀鎖插件僅支持**updateById(id)與update(entity, wrapper)方法**
注意:如果使用wrapper,則wrapper不能復用!示例如下
@Test
public void testOpLocker() {
User2 user = new User2();
user.setId(8L);
user.setVersion(1);
user.setAge(2);
// 第一次使用
LambdaQueryWrapper《User2》 wrapper = new LambdaQueryWrapper《》();
wrapper.eq(User2::getName, “王一蛋”);
mapper.update(user, wrapper);
// 第二次復用
user.setAge(3);
mapper.update(user, wrapper);
}
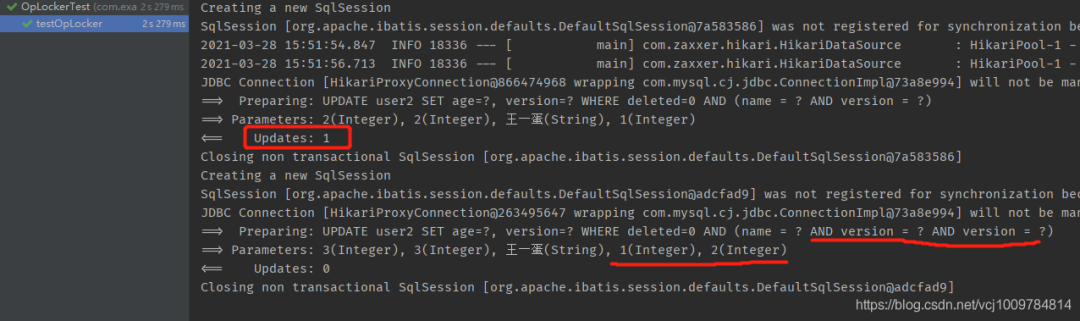
可以看到在第二次復用wrapper時,拼接出的SQL中,后面WHERE語句中出現了2次version,是有問題的。
性能分析插件
該插件會輸出SQL語句的執行時間,以便做SQL語句的性能分析和調優。
注:3.2.0版本之后,mp自帶的性能分析插件被官方移除了,而推薦食用第三方性能分析插件
食用步驟
1. 引入maven依賴
《dependency》
《groupId》p6spy《/groupId》
《artifactId》p6spy《/artifactId》
《version》3.9.1《/version》
《/dependency》
2. 修改application.yml
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver #換成p6spy的驅動
url: jdbcmysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai #url修改
username: root
password: root
3. 在src/main/resources資源目錄下添加spy.properties
#spy.properties
#3.2.1以上使用
modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory
# 真實JDBC driver , 多個以逗號分割,默認為空。由于上面設置了modulelist, 這里可以不用設置driverlist
#driverlist=com.mysql.cj.jdbc.Driver
# 自定義日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志輸出到控制臺
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
#若要日志輸出到文件, 把上面的appnder注釋掉, 或者采用下面的appender, 再添加logfile配置
#不配置appender時, 默認是往文件進行輸出的
#appender=com.p6spy.engine.spy.appender.FileLogger
#logfile=log.log
# 設置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前綴
useprefix=true
# 配置記錄 Log 例外,可去掉的結果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
# 日期格式
dateformat=yyyy-MM-dd HHss
# 是否開啟慢SQL記錄
outagedetection=true
# 慢SQL記錄標準 2 秒
outagedetectioninterval=2
# 執行時間設置, 只有超過這個執行時間的才進行記錄, 默認值0, 單位毫秒
executionThreshold=10
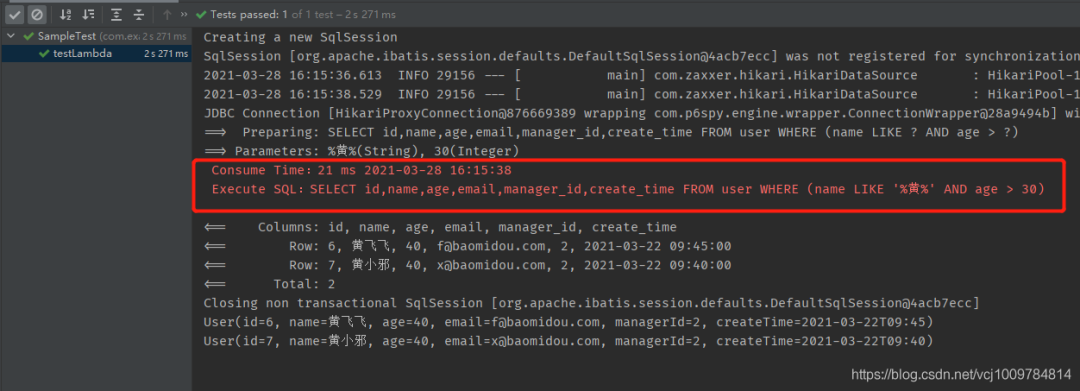
隨便運行一個測試用例,可以看到該SQL的執行時長被記錄了下來
多租戶SQL解析器
多租戶的概念:多個用戶共用一套系統,但他們的數據有需要相對的獨立,保持一定的隔離性。
多租戶的數據隔離一般有如下的方式:
不同租戶使用不同的數據庫服務器
優點是:不同租戶有不同的獨立數據庫,有助于擴展,以及對不同租戶提供更好的個性化,出現故障時恢復數據較為簡單。
缺點是:增加了數據庫數量,購置成本,維護成本更高
不同租戶使用相同的數據庫服務器,但使用不同的數據庫(不同的schema)
優點是購置和維護成本低了一些,缺點是數據恢復較為困難,因為不同租戶的數據都放在了一起
不同租戶使用相同的數據庫服務器,使用相同的數據庫,共享數據表,在表中增加租戶id來做區分
優點是,購置和維護成本最低,支持用戶最多,缺點是隔離性最低,安全性最低
食用實例如下
添加多租戶攔截器配置。添加配置后,在執行CRUD的時候,會自動在SQL語句最后拼接租戶id的條件
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TenantLineHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.TenantLineInnerInterceptor;
import net.sf.jsqlparser.expression.Expression;
import net.sf.jsqlparser.expression.LongValue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new TenantLineInnerInterceptor(new TenantLineHandler() {
@Override
public Expression getTenantId() {
// 返回租戶id的值, 這里固定寫死為1
// 一般是從當前上下文中取出一個 租戶id
return new LongValue(1);
}
/**
** 通常會將表示租戶id的列名,需要排除租戶id的表等信息,封裝到一個配置類中(如TenantConfig)
**/
@Override
public String getTenantIdColumn() {
// 返回表中的表示租戶id的列名
return “manager_id”;
}
@Override
public boolean ignoreTable(String tableName) {
// 表名不為 user2 的表, 不拼接多租戶條件
return !“user2”.equals(tableName);
}
}));
// 如果用了分頁插件注意先 add TenantLineInnerInterceptor 再 add PaginationInnerInterceptor
// 用了分頁插件必須設置 MybatisConfiguration#useDeprecatedExecutor = false
return interceptor;
}
}
測試代碼
@Test
public void testTenant() {
LambdaQueryWrapper《User2》 wrapper = new LambdaQueryWrapper《》();
wrapper.likeRight(User2::getName, “王”)
.select(User2::getName, User2::getAge, User2::getEmail, User2::getManagerId);
user2Mapper.selectList(wrapper);
}
動態表名SQL解析器
當數據量特別大的時候,我們通常會采用分庫分表。這時,可能就會有多張表,其表結構相同,但表名不同。例如order_1,order_2,order_3,查詢時,我們可能需要動態設置要查的表名。mp提供了動態表名SQL解析器,食用示例如下
先在mysql中拷貝一下user2表
配置動態表名攔截器
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TableNameHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.DynamicTableNameInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Random;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
DynamicTableNameInnerInterceptor dynamicTableNameInnerInterceptor = new DynamicTableNameInnerInterceptor();
HashMap《String, TableNameHandler》 map = new HashMap《》();
// 對于user2表,進行動態表名設置
map.put(“user2”, (sql, tableName) -》 {
String _ = “_”;
int random = new Random().nextInt(2) + 1;
return tableName + _ + random; // 若返回null, 則不會進行動態表名替換, 還是會使用user2
});
dynamicTableNameInnerInterceptor.setTableNameHandlerMap(map);
interceptor.addInnerInterceptor(dynamicTableNameInnerInterceptor);
return interceptor;
}
}
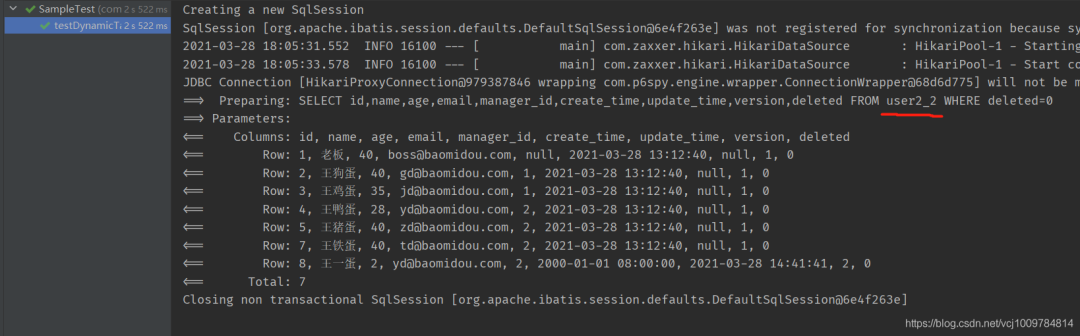
測試
@Test
public void testDynamicTable() {
user2Mapper.selectList(null);
}
總結
條件構造器AbstractWrapper中提供了多個方法用于構造SQL語句中的WHERE條件,而其子類QueryWrapper額外提供了select方法,可以只選取特定的列,子類UpdateWrapper額外提供了set方法,用于設置SQL中的SET語句。
除了普通的Wrapper,還有基于lambda表達式的Wrapper,如LambdaQueryWrapper,LambdaUpdateWrapper,它們在構造WHERE條件時,直接以方法引用來指定WHERE條件中的列,比普通Wrapper通過字符串來指定要更加優雅。另,還有鏈式Wrapper,如LambdaQueryChainWrapper,它封裝了BaseMapper,可以更方便地獲取結果。
條件構造器采用鏈式調用來拼接多個條件,條件之間默認以AND連接
當AND或OR后面的條件需要被括號包裹時,將括號中的條件以lambda表達式形式,作為參數傳入and()或or()
特別的,當()需要放在WHERE語句的最開頭時,可以使用nested()方法
條件表達式時當需要傳入自定義的SQL語句,或者需要調用數據庫函數時,可用apply()方法進行SQL拼接
條件構造器中的各個方法可以通過一個boolean類型的變量condition,來根據需要靈活拼接WHERE條件(僅當condition為true時會拼接SQL語句)
使用lambda條件構造器,可以通過lambda表達式,直接使用實體類中的屬性進行條件構造,比普通的條件構造器更加優雅
若mp提供的方法不夠用,可以通過自定義SQL(原生mybatis)的形式進行擴展開發
使用mp進行分頁查詢時,需要創建一個分頁攔截器(Interceptor),注冊到Spring容器中,隨后查詢時,通過傳入一個分頁對象(Page對象)進行查詢即可。單表查詢時,可以使用BaseMapper提供的selectPage或selectMapsPage方法。復雜場景下(如多表聯查),使用自定義SQL。
AR模式可以直接通過操作實體類來操作數據庫。讓實體類繼承自Model即可
編輯:jq
-
Ar
+關注
關注
24文章
5047瀏覽量
168589 -
MP
+關注
關注
0文章
38瀏覽量
36073 -
SQL
+關注
關注
1文章
750瀏覽量
43900 -
數據庫
+關注
關注
7文章
3711瀏覽量
64021
原文標題:熟練掌握 MyBatis-Plus,一篇就夠!
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
嵌入式工程師需要掌握哪些技術?
基于MicroPython的普中開發板攻略
SpringBoot實現動態切換數據源

掌握印制電路板上的干擾及抑制
mybatis框架的主要作用
mybatis和mybatisplus的區別
mybatis接口動態代理原理
mybatis的dao能重載嗎
數字IC設計工程師成長四階段是怎樣的?

如何熟練掌握40個電氣二次回路知識
MyBatis Plus如何簡化開發
mybatis plus的常規用法
如何一鍵生成mybatisplus





 工商網監
工商網監
評論