 基于對等網絡P2P技術和CDN內容分發網絡實現多媒體監控系統的設計
基于對等網絡P2P技術和CDN內容分發網絡實現多媒體監控系統的設計
引 言
對等網絡P2P(Peer-to-peer)技術是目前國際計算機網絡技術領域研究的一個熱點。該技術的雛形產生于20世紀70年代,典型代表是UseNet和FidoNet;而CDN內容分發網絡(Content Distri-bution Network)則是將網站的內容或媒體發布到最接近用戶的網絡“邊緣”,當用戶訪問時,系統自動無縫地把用戶重定向到邊緣服務器,從而減輕中心服務器和主干網絡的壓力,提升流媒體或網站的性能。
隨著網絡技術的迅猛發展,流媒體內容在互聯網中大量傳播,對于高質量的流媒體分發服務體現得越加明顯,因而為大量用戶提供快速,高質量的流媒體分發服務成為了最近研究的熱點和難點。
在多媒體監控系統中所要傳輸的數據量是相當大的,主要包括:控制信息、反饋信息、視頻、音頻和其他如文本信息等。對于傳統的基于C/S模式或B/S模式的多媒體監控系統,在監控點和監控中心之間進行這些大量流媒體數據傳輸,服務器性能會直線下降。基于此本文把P2P技術引入到該多媒體監控系統設計中主要做了如下改進:
(1)設計了基于P2P和CDN的監控傳輸子系統。
(2)客戶利用P2P方式從邊緣服務器得到服務,同時原始服務器和邊緣服務器之間的內容發布也通過P2P方式進行,通過這種方式有效地利用了系統中網絡帶寬和主機資源,減輕了原始服務器和邊緣服務器的壓力,減少了主干網數據流量,降低了運營商的成本,提高了客戶的服務質量。
(3)為了緩解網絡I/O和磁盤I/O的矛盾,在傳輸子系統的設計中采用半同步/半異步的方式將網絡I/O與磁盤I/O分開,并通過任務池的方式進行緩沖。
(4)設計了線程池動態管理算法,有效減小了CPU的負載壓力,提高了網絡吞吐量和系統整體性能。
(5)針對傳統方式的缺點進行了有效的改進,利用半同步/半異步的方式建立系統框架,利用任務池對數據的讀寫請求進行封裝,采用線程池對任務池中的任務進行高效異步處理。通過對任務的閑置情況進行統計,并結合系統的當前資源利用情況,對任務池和線程池進行動態管理,降低了CPU的負載,提高了系統的吞吐量。
2 系統框架
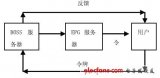
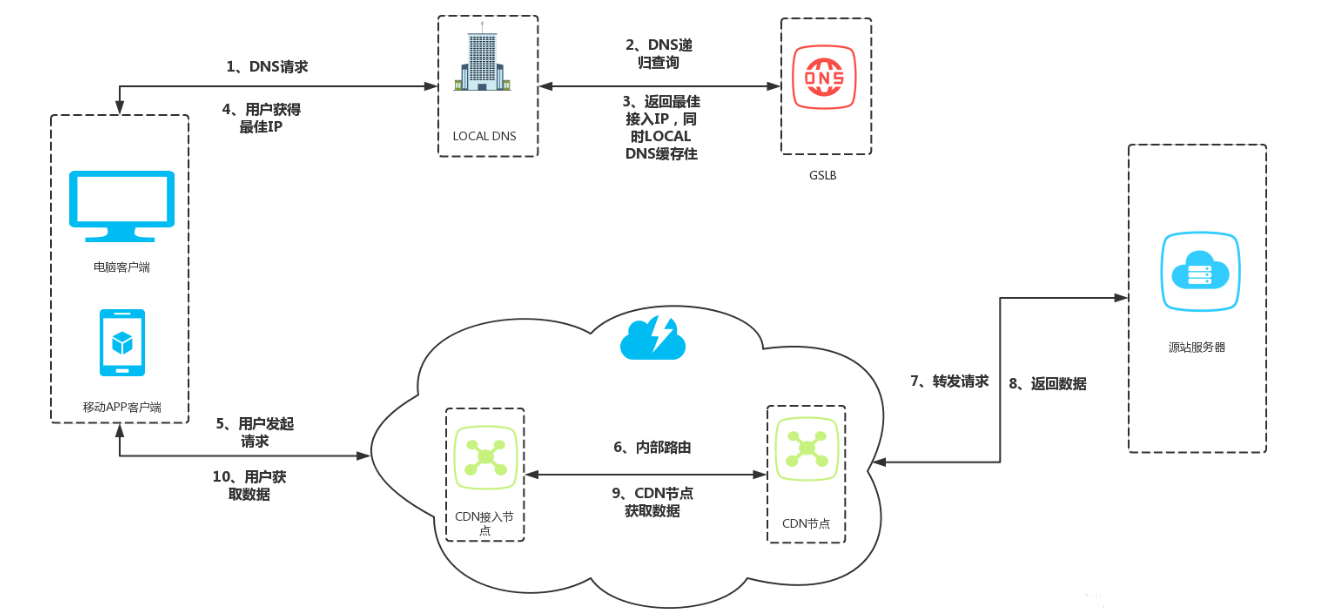
系統總體布局如圖1所示,邊緣服務器將會與若干客戶節點形成P2P網絡,提供高效的服務質量,便于降低服務器的負載。
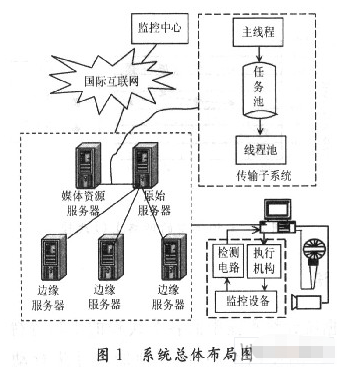
當客戶在邊緣服務器上請求資源不命中時,邊緣服務器會向原始服務器請求,原始服務器會根據具體請求要求,將需要的媒體資源通過該文實現的高效傳輸子系統存儲在本地,然后利用P2P的方式向多個邊緣服務器發布內容。
通過這種方式有效減輕了原始服務器在內容發布時的壓力。理論上它只要將一個完整的媒體副本發送出去,其他邊緣服務器會根據P2P的方式得到一個完整的副本。同理,當邊緣服務器向客戶提供服務時,理論上它也只需要傳輸一個副本,多個客戶端就可以得到完整的服務。原始服務器和媒體資源服務器通常是在一個子網中,網絡速度比磁盤I/O速度更快。此時,磁盤I/O成了系統的瓶頸。為了緩解網絡I/O和磁盤1/O的矛盾,在傳輸子系統的設計當中采用半同步/半異步的方式將網絡I/O與磁盤I/O分離開,并通過任務池的方式進行緩沖。
上層的主線程處理epoll異步事件和協議交互,框架將接收到的數據按照固定大小封裝在任務里面,然后將任務放回任務池,下層線程池負責從任務池中取出任務,進行具體的磁盤讀寫操作,操作完成后線程和任務分別回到線程池和任務池等待調度。
3 算法實現
為了對線程池進行有效的動態管理,需要采集各種性能參數,經過綜合分析之后,對線程池做出調整。該算法中參考了兩個最關鍵的參數,即任務的平均等待時間和CPU使用率。通過任務的平均等待時間,可以分析得到當前線程池需要調整的方向。通過CPU使用率可以得到是否需要增加或者減少線程。
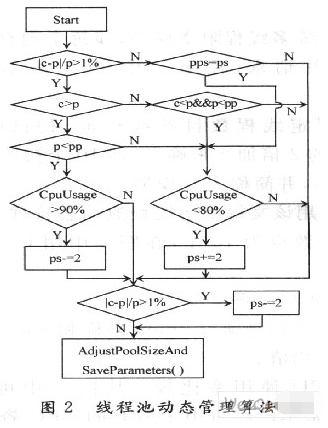
圖2中c(current)表示線程池當前平均等待時間;p(previous)表示線程池上次等待時間;pp表示上上次等待時間;ps(pool size)表示線程池大小;pps表示上次線程池大小。該算法中并不是對等待時間的絕對值進行比較,而是對currTime和preTime進行比較,如果差異大于1%,線程池可能需要調整,調整方向需要根據currTime和preTime的大小關系來決定。如果currTime大于preTime,需要進一步比較pre-Time和prepreTime的關系;如果preTime小于prepreTime,并且CPU使用率大于90%,那么減小線程池。減小的步長(stride)為2。如果preTime大于prepreTime,并且CPU使用率小于80%,則增大線程池,增加的步長為2。如果currTime小于preTime,并且preTime小于prepreTime,則增大線程池。
簡而言之,算法通過對currTime,preTime,prepre-
Time三者的關系進行比較,確定線程池是否需要調整。
當需要減小線程池時,需要進一步判斷CPU的使用率,只有CPU大于一個閥值時才進行減小操作,因為CPU的負載太小也是一種資源浪費;同理,當需要增大線程池時,也只能在CPU小于一個閥值時,才能進行增加操作,因為CPU的負載不能過大。
4 實驗分析
因為媒體資源服務器和原始服務器多在同一個子網中,因此實驗的環境也通過一個局域網模擬,服務器的基本配置是:兩個Intel雙核Xeon 3 GHz芯片、2 048 KB緩存、4 GB內存、1 000 Mb/s網卡。
4.1 三種模型的實驗數據
實驗通過傳輸子系統從負載發生器下載數據來模擬大量數據請求,并分別收集下列三種模型的實驗數據:
(1)傳統多線程阻塞模型,即每個現存阻塞得處理一個單獨的請求,在圖3中用A表示,并簡稱為A模型。
(2)固定線程數目的線程池,初試線程數采用CPU個數的2倍加2來確定,即10個初始線程,在圖3中用B表示,并簡稱為B模型。
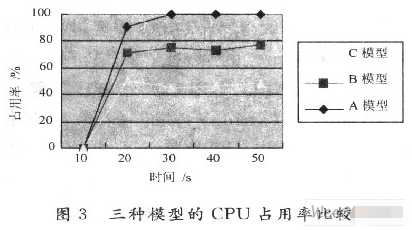
(3)采用該文提出的線程池動態管理算法的模型,初試線程個數也為10個,在圖3中用C表示,并簡稱C模型。
4.2 分析數據得平均值
下面數據均是通過nmon采樣和ninon analyser分析得到的平均值。
(1)CPU使用率比較。從圖3中可以看到,在A模型中,基本已經占用了所有的CPU資源。因為每個線程服務一個請求,一旦請求大量到來,就會有大量的線程產生。而在B模型中,因為線程個數固定,且已經預先創建好,當請求量過大時,任務隊列會起到很好的緩沖作用。C模型是效果最好的,因為線程個數總是會被調整到最佳的個數,并且任務池的使用有效減少了系統中頻繁的內存申請和釋放操作。
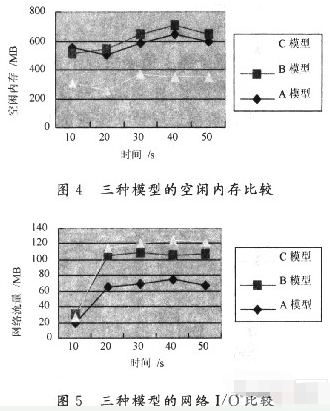
(2)空閑內存比較。從圖4中可以容易分析得到,當請求的總量相同的情況下,A和B模型占用的內存情況很接近。但是C模型中,任務池和線程池的大小都是動態伸縮的,提高了系統的處理能力,自然也會使用更多的內存。
(3)網絡I/O流量比較。圖5展現了3種模型的網絡I/O情況,在A模型中,因為采用的是阻塞的方式進行的,當套口已經沒有數據可讀,線程會阻塞等待數據的到達,而其他已經有數據到達的套接口則可能得不到處理,因此A模型的網絡吞吐量比較低。在B模型中,采用的非阻塞和線程池模型,一旦一個套接口將要發生阻塞,線程可以很快切換到其他已經有數據準備好的套接口上,加快了數據的接收速度,因此也提高了網絡的傳輸速度。在C模型中,減小了內存和CPU等部件的負載,提高了性能,動態任務池使得系統有比B模型更好的緩存能力,因此C模型比B模型網絡吞吐量更高是可以理解的。系統采用的是l 000 Mb/s網卡,基本達到了網卡的極限。
5 結 語
根據統計線程池中的各個線程的平均等待時間和當前CPU的使用率,對線程池的尺寸進行動態的調整。利用這種線程池動態管理算法,可以很好地適應Internet上客戶請求突發性變化的情況。當突然到來大量請求時,根據算法原理,可以增加適量的線程滿足額外的請求;當請求變少以后,會將線程的數量減少,從而減輕系統的壓力。經過實驗分析比較可以得出,采用線程池動態管理算法之后,有效減小了CPU的負載壓力,提高了網絡吞吐量和系統整體性能。但是,線程池的管理還有很多地方可以優化,比如調整線程池尺寸都是以2為步長進行調整的,但是這個步長是根據經驗得出來的,還沒有很好的理論依據。同時,可以增加更多的統計信息加入到算法的決策之中,提高算法的精確性。
這里實現了在多媒體監控傳輸系統中P2P和CDN的結合,引入半同步/半異步的模式,設計了系統框架,引入任務池和線程池等技術,解決了媒體資源服務器和原始服務器之間的高效傳輸子系統的網絡瓶頸,設計了有效的線程池動態管理算法。
責任編輯:gt
-
計算機
+關注
關注
19文章
7174瀏覽量
87158 -
服務器
+關注
關注
12文章
8701瀏覽量
84549 -
監控系統
+關注
關注
21文章
3769瀏覽量
172331
發布評論請先 登錄
相關推薦
P2P網絡工作的步驟是什么?
P2P媒體分發網絡中的數據下載調度策略
對等網絡資源搜索技術研究
對等網絡簡介及在IPTV網絡傳輸中的應用
移動對等網絡關鍵技術

非結構的P2P網絡拓撲模型



區塊鏈的協議分層P2P網絡介紹
流媒體內容分發終極解決方案:當融合CDN與P2P視頻交付結合





 工商網監
工商網監
評論