 在目前深度學習中比較普及的“物件檢測”應用
在目前深度學習中比較普及的“物件檢測”應用
接下來的重點,就是在目前深度學習中比較普及的“物件檢測”應用,重點主要有以下三部分:
1. 簡單說明“物件檢測”的內容。
2. 使用本項目的 detecnet 物件分類指令,進行多樣化的推理識別測試。
3. 深入說明 jetson.inference 模塊的 detectNet() 以及相關的函數用法。
如此讓大家能快速掌握這項物件檢測功能,以及開發代碼的重點。
物件檢測(object detection)簡單說明
這是比圖像分類更進一步的應用,因為日常生活中,在絕大部分可看到的畫面中,不會只存在一個物體,通常是多種類別的多個物體,左圖識別出有“四個人”、右圖識別出“一個人與一匹馬”,當然真的要細部再探索的話,還有其他類別的物體也可以被識別,這是視覺類深度學習中使用頻率最高的一種應用。
在物件檢測的識別中,還只是比較“概略性”地將物體用“矩形框”的方式來標識,那能不能將物體的“實際形狀”更細膩地標識出來呢?當然可以,這就是更高階的“語義分割”應用,留在下一篇文章里面說明。
前面的圖像分類是以“一張圖像”為單位,這里的物件檢測則是以“物件框”為單位,因此所需要的數據集就不僅僅是圖像了,還要將圖像中所需要的類別加以標注,然后存成特定格式之后,提供給訓練框架去進行模型訓練,這是相當耗費人力的一個過程,而且標注的細膩程度也會對最終的精確度產生影響。
關于這個模型的訓練過程,會在后面的文章中帶著大家動手做一次,這也是整個 Hello AI World 項目中的一部分,而且也提供非常好用的工具,協助大家采集數據、標注物件框、進行模型訓練等。
以上就是物件檢測的簡單說明,接下去直接使用項目提供的 detectnet 指令來進行實驗。
detectnet 指令的使用
與 imagenet 的調用邏輯是一樣的,當系統編譯好之后,就生成 detectnet 指令,可以在 Jetson 設備中任何地方調用。同樣的,項目也為 detectnet 準備了幾個預訓練好的網絡模型,可以非常輕松地調用,預訓練模型。
系統預設的神經網絡是 “SSD-Mobilenet-v2”,基于 91 種分類的 COCO 數據集進行模型訓練,詳細的類別內容可以參考 ~/jetson-inference/data/networks 目錄下的ssd_coco_labels.txt,事實上能識別的物件有 90 種,另外加一個 “unlabeled” 種類。
detectnet 的參數調用與 imagenet 幾乎一致,輸入源與輸出標的的支持方式完全相同,因此我們可以執行下面指令,直接看看得到怎樣的效果:

在執行過程中,會看到命令終端不斷出現類似下圖的信息,里面顯示一些重要的信息,包括“使用的網絡模型文件”、“4 個執行階段占用時間”、“檢測到滿足閾值的物件數”、“物件類別/置信度”,以及“物件位置”等信息。
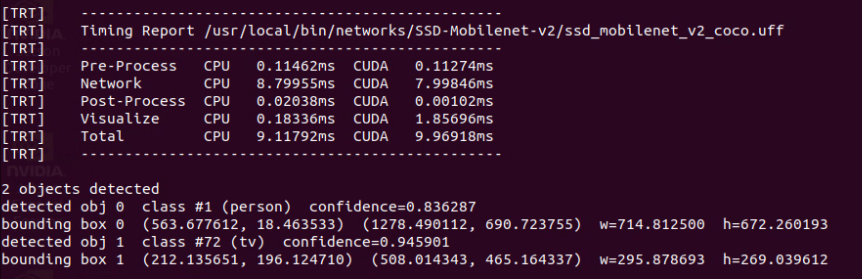
detectnet 也能導出 RTP 視頻流到指定的電腦,詳細用法請參考前面 “Utils的videoOutput 工具”一文中有詳細說明,這個用法的實用度非常高,可以讓你將 Jetson Nano 2GB 設備放置在任何能接網絡的角落,不斷讀取攝像頭內容在 Jetson 上執行物件識別,然后將結果傳輸到你的桌面電腦或筆記本上,這樣你就可以非常輕松地進行監控。
輸入 “detectnet --help” 可以得到完整的幫助信息,由于內容太多,我們在這里不占用篇幅去說明,多嘗試一些指令的組合,會讓你進一步掌握這個指令的重點。
接下來看看如何在 Python 代碼中,調用這個項目的物件檢測函數,來開發自己的物件檢測應用。
detectNet()函數的用法
與前面圖像分類的邏輯一樣,作者雖然在 ~/jetson-inference/python/examples 下面提供了一個 my-detection.py 范例,這個就是我們一開始所示范的“ 10 行代碼威力”的內容,這個范例的好處是“代碼量最少”,但對應的缺點就是“彈性小、完整度不夠”,因此從務實的角度,我們還是推薦以 /usr/local/bin/detect.py 這只代碼為主,這只代碼能執行的功能,與 detectnet 指令幾乎一致。
與 imagenet.py 代碼相同的,一開始有一段“參數解析”的指令,如下截圖:
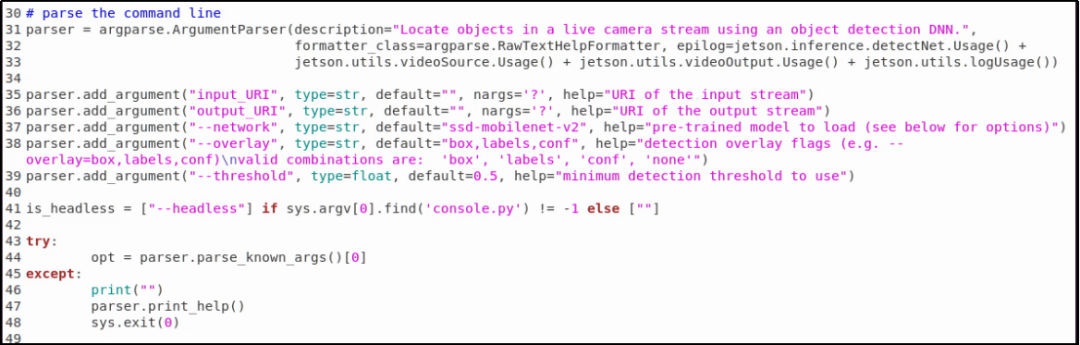
這部分同樣請參考先前的“參數解析功能”文章,在這里不重復贅述。接下來我們將與物件檢測有關的指令挑出來說明,這樣可以讓讀者更加容易將焦點集中在有關的部分:
51 行:net = jetson.inference.detectNet(opt.network, sys.argv, opt.threshold)
用 jetson.inferene.detectNet() 函數建立 net 這個物件檢測對象,與前面的 imageNet() 的邏輯是一樣的,不過這里所輸入的參數,除了 network(網絡模型類別)之外,還多了一個 threshold(閾值)。因為物件檢測的功能,是要在圖像中識別出“所有可能”的物件,如果沒有一個“最低門檻”的限制,就會滿屏都是物件。
系統已經給這兩個參數都提供預設值,network 預設為 “SSD-Mobilenet-v2”、threshold 預設值為 0.5。
如果要在代碼外部利用參數去改變設定,就可以如以下方式:
--network=multiped,表示要使用“Multiped-500”這個網絡模型
--threshold=0.3,表示將閾值改成0.3
這樣 net 對象就具備了執行物件檢測的相關功能,然后再繼續以下的步驟。
63 行:detections = net.Detect(img, overlay=opt.overlay)
這道指令,就是將 input.Capture() 獲取的一幀圖形,傳入 net.Detect() 函數去執行物件檢測的推理識別計算,另一個參數 “overlay” 的功能是“檢測覆蓋”的一個標識,只影響顯示輸出的方式,與檢測結果并沒有關系,大部分時候都不需要去改變。
這里最重要的是 detections 這個數組變量,由于每幀圖像所檢測出來物件數量是不固定的,數組的結構在說明文件中并未完整表達,因此需要從執行的代碼中去找到蛛絲馬跡,這個部分在下一道指令中可以找到答案。
66~69 行:
print(“detected {:d} objects in image”.format(len(detections)))
for detection in detections:
print(detection)
這部分執行完之后,會在命令終端上顯示兩個很重要的信息:
本幀圖像所找到滿足閾值的物件數量。
前面變量detections的數據結構。
在命令終端執行以下指令,
看看所顯示的信息,如下截屏:
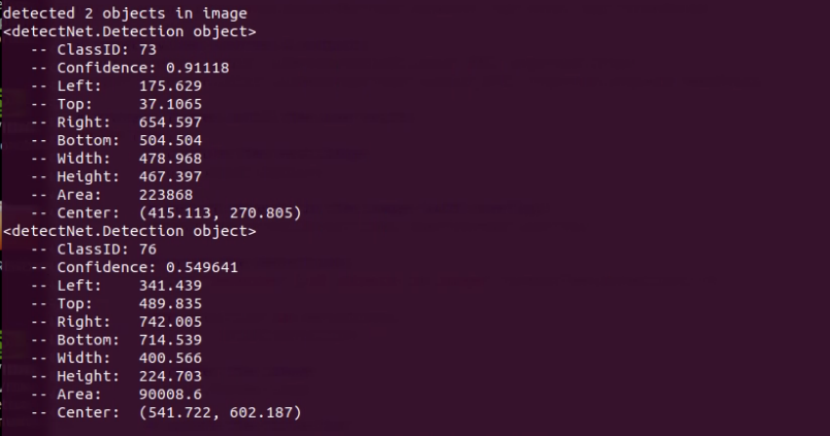
這里可以看到,代碼最后面 “len(detections)” 的值,就是本幀圖像所檢測到的物件數量,而 detections 的數據結構就是:
ClassID:類別編號
Confidence:置信度
Left:標框左坐標
Top:標框上坐標
Right:標框右坐標
Bottom:標框下坐標
Width:框的寬度 = Right - Left
Height:框的高度 = Bottom - Top
Area:面積 = Width x Height
Center:中心點坐標 = ( (Left+Right)/2, (Top+Bottom)/2 )
確認了 net.Detect() 返回值之后,就能很輕易地以這些數據去開發滿足特定要求的應用。
至于后面的 output.Render(img)、output.Status() 這些函數,在前面的文章里面都講解的很清楚,這里不再重復。
到這里,要利用 Hello AI World 這個項目所提供的庫資源,去開發自己的應用程序,就顯得非常簡單了。
編輯:jq
-
函數
+關注
關注
3文章
4308瀏覽量
62445 -
代碼
+關注
關注
30文章
4753瀏覽量
68368 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998
原文標題:Jetson Nano 2GB 系列文章(23): “Hello AI World 的物件識別應用
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
FPGA做深度學習能走多遠?
深度學習算法在嵌入式平臺上的部署
深度學習在工業機器視覺檢測中的應用
基于AI深度學習的缺陷檢測系統
深度學習在視覺檢測中的應用
TensorFlow與PyTorch深度學習框架的比較與選擇
深度解析深度學習下的語義SLAM


基于機器視覺和深度學習的焊接質量檢測系統

如何基于深度學習模型訓練實現圓檢測與圓心位置預測

GPU在深度學習中的應用與優勢






 工商網監
工商網監
評論