") 用生成模型來做圖像恢復(fù)的介紹和回顧
用生成模型來做圖像恢復(fù)的介紹和回顧
導(dǎo)讀
本文給出了圖像恢復(fù)的一般性框架,編解碼器 + GAN,后面的圖像復(fù)原基本都是這個(gè)框架。
本文會介紹圖像修復(fù)的目的,它的應(yīng)用,等等。然后,我們將深入研究文獻(xiàn)中關(guān)于圖像修復(fù)的第一個(gè)生成模型(即第一個(gè)基于GAN的修復(fù)算法,上下文編碼器)。
目標(biāo)
很簡單的!我們想要填補(bǔ)圖像中缺失的部分。
應(yīng)用
移除圖像中不需要的部分(即目標(biāo)移除)
修復(fù)損壞的圖像(可以擴(kuò)展到修復(fù)電影)
很多其他應(yīng)用!
術(shù)語
給出一個(gè)有一些缺失區(qū)域的圖像,我們定義
缺失像素/生成像素/空洞像素:待填充區(qū)域的像素。
有效像素/ground truth像素:和缺失像素含義相反。需要保留這些像素,這些像素可以幫助我們填補(bǔ)缺失的區(qū)域。
傳統(tǒng)方法
給出一個(gè)有一些缺失區(qū)域的圖像,最典型的傳統(tǒng)方法填充缺失區(qū)域是復(fù)制粘貼。
主要思想是從圖像本身或一個(gè)包含數(shù)百萬張圖像的大數(shù)據(jù)集中尋找最相似的圖像補(bǔ)丁,然后將它們粘貼到缺失的區(qū)域。
然而,搜索算法可能是耗時(shí)的,它涉及到手工設(shè)計(jì)距離的度量方法。在通用化和效率方面仍有改進(jìn)的空間。
數(shù)據(jù)驅(qū)動的基于深度學(xué)習(xí)的方法
由于卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks, CNNs)在圖像處理方面的成功,很多人開始將CNNs應(yīng)用到自己的任務(wù)中。基于數(shù)據(jù)驅(qū)動的深度學(xué)習(xí)方法的強(qiáng)大之處在于,如果我們有足夠的訓(xùn)練數(shù)據(jù),我們就可以解決我們的問題。
如上所述,圖像修復(fù)就是將圖像中缺失的部分補(bǔ)上。這意味著我們想要生成一些不存在或沒有答案的東西。因此,所有基于深度學(xué)習(xí)的修復(fù)算法都使用生成對抗網(wǎng)絡(luò)(GANs)來產(chǎn)生視覺上吸引人的結(jié)果。為什么視覺上吸引人呢?由于沒有模型來回答生成的問題,人們更喜歡有良好視覺質(zhì)量的結(jié)果,這是相當(dāng)主觀的!
對于那些可能不知道GANs的讀者,我推薦你先去了解一下。這里以圖像修復(fù)為例,簡單地說,典型的GAN由一個(gè)生成器和一個(gè)鑒別器組成。生成器負(fù)責(zé)填補(bǔ)圖像中缺失的部分,鑒別器負(fù)責(zé)區(qū)分已填充圖像和真實(shí)圖像。請注意,真實(shí)的圖像是處于良好狀態(tài)的圖像(即沒有缺失的部分)。我們將隨機(jī)地將填充的圖像或真實(shí)的圖像輸入識別器來欺騙它。最終,如果鑒別器不能判斷圖像是被生成器填充的還是真實(shí)的圖像,生成器就能以良好的視覺質(zhì)量填充缺失的部分!
第一個(gè)基于GAN的修復(fù)方法:上下文編碼器
在對image inpainting做了簡單的介紹之后,我希望你至少知道什么是image inpainting, GANs(一種生成模型)是inpainting領(lǐng)域常用的一種。現(xiàn)在,我們將深入研究本系列的第一篇論文。
Intention
作者想訓(xùn)練一個(gè)CNN來預(yù)測圖像中缺失的像素。眾所周知,典型的CNNs(例如LeNet手寫數(shù)字識別和AlexNet圖像分類)包含許多的卷積層來提取特征,從簡單的結(jié)構(gòu)特征到高級的語義特征(即早期層簡單的特征,比如邊緣,角點(diǎn),到后面的層的更復(fù)雜的特征模式)。對于更復(fù)雜的功能模式,作者想利用學(xué)到的高層語義特征(也稱為隱藏特征)來幫助填充缺失的區(qū)域。
此外,為修復(fù)而學(xué)習(xí)的特征需要對圖像進(jìn)行更深層次的語義理解。因此,學(xué)習(xí)到的特征對于其他任務(wù)也很有用,比如分類、檢測和語義分割。
背景
在此,我想為讀者提供一些背景信息,
Autoencoders:這是一種通常用于重建任務(wù)的CNN結(jié)構(gòu)。由于其形狀,也有人稱之為沙漏結(jié)構(gòu)模型。對于這個(gè)結(jié)構(gòu),輸出大小與輸入大小相同,我們實(shí)際上有兩個(gè)部分,一個(gè)是編碼器,另一個(gè)是解碼器。
編碼器部分用于特征編碼,針對輸入得到緊湊潛在的特征表示,而解碼器部分則對潛在特征表示進(jìn)行解碼。我們通常把中間層稱為低維的“瓶頸”層,或者簡單地稱之為“瓶頸”,因此整個(gè)結(jié)構(gòu)看起來就像一個(gè)沙漏。
讓我們想象一下,我們將一幅完好無損的圖像輸入到這個(gè)自動編碼器中。在這種情況下,我們期望輸出應(yīng)該與輸入完全相同。這意味著一個(gè)完美的重建。如果可能的話,“瓶頸”是輸入的一個(gè)完美的緊湊潛在特征表示。
更具體地說,我們可以使用更少的數(shù)字來表示輸入(即更有效,它與降維技術(shù)有關(guān))。因此,這個(gè)“瓶頸”包含了幾乎所有的輸入信息(可能包括高級語義特征),我們可以使用它來重構(gòu)輸入。
上下文編碼器進(jìn)行圖像生成
首先,輸入的是mask圖像(即有中心缺失的圖像)。輸入編碼器以獲得編碼后的特征。然后,本文的主要貢獻(xiàn)是在編碼特征和解碼特征之間放置通道全連接層,以獲得更好的語義特征(即“瓶頸”)。最后,解碼器利用“瓶頸”特征重建缺失的部分。讓我們來看看他們的網(wǎng)絡(luò)內(nèi)部。
編碼器
編碼器使用AlexNet結(jié)構(gòu),他們用隨機(jī)初始化權(quán)值從頭開始訓(xùn)練他們的網(wǎng)絡(luò)。
與原始的AlexNet架構(gòu)和圖2所示的自動編碼器相比,主要的區(qū)別是中間的通道全連接層。如果網(wǎng)絡(luò)中只有卷積層,則無法利用特征圖上距離很遠(yuǎn)的空間位置的特征。為了解決這個(gè)問題,我們可以使用全連接層,即當(dāng)前層的每個(gè)神經(jīng)元的值依賴于上一層的所有神經(jīng)元的值。然而,全連接層會引入許多參數(shù),8192x8192=67.1M,這甚至在GPU上也很難訓(xùn)練,作者提出了通道全連接層來解決這個(gè)問題。
通道全連接層
實(shí)際上,通道全連接層非常簡單。我們只是完全獨(dú)立地連接每個(gè)通道而不是所有的通道。例如,我們有m個(gè)大小為n x n的特征映射。如果使用標(biāo)準(zhǔn)的全連接層,我們會有m2n?個(gè)參數(shù),對于通道級的全連接層,我們只有mn?個(gè)參數(shù)。因此,我們可以在距離很遠(yuǎn)的空間位置上捕獲特征,而不需要添加那么多額外的參數(shù)。
解碼器
對于解碼器來說,這只是編碼過程的反向。我們可以使用一系列的轉(zhuǎn)置卷積來獲得期望大小的重建圖像。
損失函數(shù)
本文使用的損失函數(shù)由兩項(xiàng)組成。第一項(xiàng)是重建損失(L2損失),它側(cè)重于像素級的重建精度(即PSNR方向的損失),但總是會導(dǎo)致圖像模糊。第二個(gè)是對抗損失,它通常用于GANs。它鼓勵(lì)真實(shí)圖像和填充圖像之間數(shù)據(jù)分布更接近。
對于那些對損失函數(shù)感興趣的讀者,我強(qiáng)烈推薦你們閱讀這篇論文中的方程。在這里,我只是口頭描述每個(gè)損失項(xiàng)。
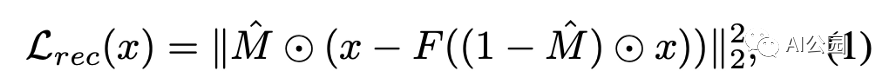
重建損失(L2損失),M表示缺失的區(qū)域(1表示缺失區(qū)域,0表示有效像素),F(xiàn)是生成器
L2損失:計(jì)算生成的像素與對應(yīng)ground truth像素之間的L2距離(歐幾里得距離)。只考慮缺失區(qū)域。
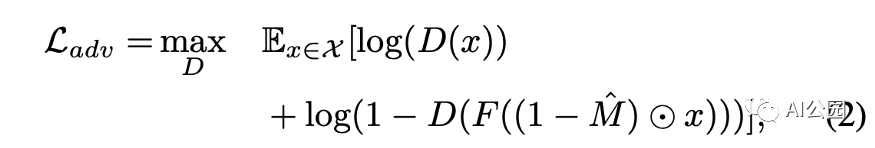
對抗損失,D是鑒別器。我們希望訓(xùn)練出一種能夠區(qū)分填充圖像和真實(shí)圖像的鑒別器
對抗損失:對抗鑒別器的結(jié)構(gòu)如圖4所示。鑒別器的輸出是一個(gè)二進(jìn)制值0或1。如果輸入是真實(shí)圖像,則為1,如果輸入是填充圖像,則為0。
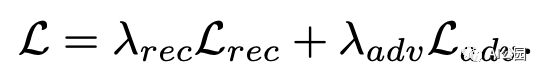
聯(lián)合損失,Lambda_rec為0.999,Lambda_adv為0.001
使用隨機(jī)梯度下降(SGD),Adam優(yōu)化器交替訓(xùn)練生成器和鑒別器。
實(shí)驗(yàn)結(jié)果
評估使用了兩個(gè)數(shù)據(jù)集,即Paris Street View和ImageNet。
作者首先展示了修復(fù)結(jié)果,然后他們還表明,作為預(yù)訓(xùn)練步驟,學(xué)習(xí)到的特征可以遷移到其他任務(wù)中。
語義修復(fù)
作者與傳統(tǒng)的最近鄰修復(fù)算法進(jìn)行了比較。顯然,該方法優(yōu)于最近鄰修復(fù)方法。
我們可以看到L2損失傾向于給出模糊的圖像(第二列)。L2 +對抗性的損失給更清晰的填充圖像。對于NN-Inpainting,他們只是復(fù)制和粘貼最相似的圖像補(bǔ)丁到缺失的區(qū)域。
特征學(xué)習(xí)
為了顯示他們學(xué)習(xí)到的特征的有用性,作者嘗試編碼不同的圖像patch,并根據(jù)編碼的特征得到最相似的patch。在圖7中。作者將其與傳統(tǒng)的HOG和典型的AlexNet進(jìn)行了比較。它們實(shí)現(xiàn)了與AlexNet類似的表現(xiàn),但AlexNet是在一百萬張標(biāo)有數(shù)據(jù)集的圖像上預(yù)訓(xùn)練的。
如表2所示,在ImageNet上預(yù)訓(xùn)練過的模型具有最好的性能,但需要昂貴的標(biāo)簽。在該方法中,上下文是用于訓(xùn)練模型的監(jiān)督。這就是他們所謂的通過修復(fù)圖像來學(xué)習(xí)特征。很明顯,它們學(xué)習(xí)到的特征表示與其他借助輔助監(jiān)督訓(xùn)練的模型相當(dāng),甚至更好。
總結(jié)
所提出的上下文編碼器訓(xùn)練可以在上下文的條件下生成圖像。在語義修復(fù)方面達(dá)到了最先進(jìn)的性能。
學(xué)習(xí)到的特征表示也有助于其他任務(wù),如分類,檢測和語義分割。
要點(diǎn)
我想在這里強(qiáng)調(diào)一些要點(diǎn)。
對于圖像修復(fù),我們必須使用來自有效像素的“提示”來幫助填充缺失的像素。“上下文”一詞是指對整個(gè)圖像本身的理解。
本文的主要貢獻(xiàn)是通道全連接層。其實(shí),理解這一層并不難。對我來說,它是Non-Local Neural Networks或Self-Attention的早期版本/簡化版本。主要的一點(diǎn)是,前一層的所有特征位置對當(dāng)前層的每個(gè)特征位置都有貢獻(xiàn)。從這個(gè)角度來看,我們對整個(gè)圖像的語義理解會更加深入。這個(gè)概念在后面的文章中被廣泛采用!
所有后來的修復(fù)論文都遵循了GAN-based結(jié)構(gòu)(即編碼器-解碼器結(jié)構(gòu))。人們的目標(biāo)是具有良好視覺質(zhì)量的充滿圖像。
英文原文:https://medium.com/analytics-vidhya/introduction-to-generative-models-for-image-inpainting-and-review-context-encoders-13e48df30244
編輯:jq
-
解碼器
+關(guān)注
關(guān)注
9文章
1131瀏覽量
40679 -
編碼器
+關(guān)注
關(guān)注
45文章
3597瀏覽量
134170 -
GaN
+關(guān)注
關(guān)注
19文章
1919瀏覽量
73004 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22171
原文標(biāo)題:用生成模型來做圖像恢復(fù)的介紹和回顧:上下文編碼器
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
字節(jié)發(fā)布SeedEdit圖像編輯模型
Meta發(fā)布Imagine Yourself AI模型,重塑個(gè)性化圖像生成未來
經(jīng)典卷積網(wǎng)絡(luò)模型介紹
如何用C++創(chuàng)建簡單的生成式AI模型
Runway發(fā)布Gen-3 Alpha視頻生成模型
OpenAI發(fā)布圖像檢測分類器,可區(qū)分AI生成圖像與實(shí)拍照片
KOALA人工智能圖像生成模型問世
韓國科研團(tuán)隊(duì)發(fā)布新型AI圖像生成模型KOALA,大幅優(yōu)化硬件需求
谷歌模型合成工具怎么用
谷歌Gemini AI模型因人物圖像生成問題暫停運(yùn)行
openai發(fā)布首個(gè)視頻生成模型sora
Stability AI試圖通過新的圖像生成人工智能模型保持領(lǐng)先地位






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論