 perf_counter在測量系統的性能中有何作用?
perf_counter在測量系統的性能中有何作用?
不知不覺中,perf_counter已經經歷了大大小小7個版本:
提高了delay_us()的精度
增加了對GCC、IAR的支持
改進了__cycleof__()宏,使其支持嵌套、并不再強制綁定 printf()
如果你使用的是Arm Compiler5(armcc)或是Arm Compiler 6(armclang),移植就特別簡單。你可以按照這篇文章的手把手教程在5分鐘內完成部署。
對于GCC和IAR來說,由于它們都不支持 Arm Compiler5/6 所特有的Linker語法——$Sub$$和$Super$$,因此無法直接通過 Lib 的方式實現對已有SysTick應用的 “寄居”——這里就只能忍痛割愛了。 這并不影響我們以源代碼的形式將它們加入已有的 GCC 或是 IAR 工程。大體步驟如下: 第一步:將perf_counter.c和perf_counter.h拷貝到你的工程目錄下,并將perf_counter.c 加入到編譯列表中; 第二步:將perf_counter.h所在的路徑加入到編譯器的頭文件搜索路徑中;
第三步:perf_counter.c依賴CMSIS5.4.0及其以上版本,確保你的工程中正確的包含了對CMSIS的支持。(這里就不再贅述)。
第四步:在需要用到perf_counter功能的C源文件中加入對頭文件的包含:
#include "perf_counter.h"
第五步:一般來說,用戶會在某一個地方,比如main()函數內完成對CPU工作頻率的配置,我們應該在完成這一工作之后確保全局變量SystemCoreClock被正確的更新——保存當前CPU的工作頻率,比如:
externuint32_tSystemCoreClock;voidmain(void){system_clock_update();//!更新CPU工作頻率SystemCoreClock=72000000ul//!假設更新后的系統頻率是 72MHz...}
一般來說,你的芯片工程如果本身都是基于較新的CMSIS框架而創建的,你的啟動文件中已經為你定義好了全局變量SystemCoreClock——當然,凡事都有例外,如果你在編譯的時候報告找不到變量SystemCoreClock或者說“Undefined symbol __SystemCoreClock” 之類的,你自己定義一下就好了,比如:
uint32_tSystemCoreClock;voidmain(void){system_clock_update();//!更新CPU工作頻率SystemCoreClock=72000000ul//!假設更新后的系統頻率是 72MHz...}
在這以后,我們需要對perf_counter庫進行初始化。這里分兩種情況:
1、用戶自己的應用里完全沒有使用SysTick。對于這種情況,我們要在 main.c (或者別的什么源文件里)添加一個SysTick中斷處理程序:
#include "perf_counter.h"... __attribute__((used))//!
然后我們在main()函數里初始化perf_counter服務:
#include
需要特別注意的是:由于用戶并沒有自己初始化SysTick,因此我們需要將這一情況告知perf_counter庫——由它來完成對SysTick的初始化——這里傳遞false給函數init_cycle_counter()就是這個功能。如果由perf_counter 庫自己來初始化SysTick,它會為了自己功能更可靠將 SysTick的溢出值(LOAD寄存器)設置為最大值(0x00FFFFFF)。
2、用戶自己的應用里使用了SysTick,擁有自己的初始化過程。對于這種情況,我們需要確保一件事情:即,SysTick的CTRL寄存器的 BIT2(SysTick_CTRL_CLKSOURCE_Msk)是否被置位了——如果其值是1,說明SysTick使用了跟CPU一樣的工作頻率,那么SysTick的測量結果就是CPU的周期數;如果其值是0,說明SysTick使用了來自于別處的時鐘源,這個時鐘源具體頻率是多少就只能看芯片手冊了(比如STM32就喜歡將系統頻率做 1/8 分頻后提供給SysTick作為時鐘源),此時SysTick測量出來的結果就不是CPU的周期數。
在確保了CTRL寄存器的BIT2被正確置位,并且SysTick中斷被使能(置位BIT1,SysTick_CTRL_TICKINT_Msk)后,我們可以簡單的通過init_cycle_counter()函數告訴perf_counter模塊:SysTick被用戶占用了——這里傳遞 true 就實現這一功能。
#include
當然,不要忘記向已經存在的SysTick_Handler()內加入perf_counter()的插入函數:
#include "perf_counter.h"... __attribute__((used))//!
至此,我們就完成了perf_counter模塊在GCC和IAR中的部署。
如何測量代碼片斷占用了多少CPU資源?
很多時候,我們會關心某一段代碼或者函數究竟用了多少CPU周期,比如,我們寫了一個算法,你很擔心“這個算法究竟使用了多少CPU資源”,為了解決這個問題,我們需要用到如下的公式: CPU資源占用(百分比) = (函數運行所需的時間)(算法運行間隔的最小值) 100% 對于【函數運行所需的時間】和【算法運行間隔的最小值】來說,雖然它們都是時間單位,但考慮到CPU的頻率是給定的(不變的),因此,這里的時間單位在乘以CPU的工作頻率后都可以被換算為CPU的周期數。舉例來說,假如【算法運行間隔的最小值】是 20ms、CPU的頻率是72MHz,那么對應的周期數就是 72000000* (20ms / 1000ms) = 1440000 個周期。看來上述公式中唯一需要我們實際測量的就是【函數運行所需的周期數】了。
perf_counter提供了一個非常簡單的運算符:__cycleof__()。假設我們要測量的代碼片斷如下:
...my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();...則我們可以輕松的通過__cycleof__()運算來測量結果:
...__cycleof__("myalgorithm"){ my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}...如果你的系統支持printf(),則可以看到類似如下的輸出結果:

帶入上述公式:525139 /14400000 * 100% ≈36.5% 就計算出這個算法占用了大約36.5%的CPU資源,值得說明的是,從原理上看,這一方式對裸機和RTOS同樣有效哦。
有的小伙伴很快會說,我的系統并不允許我調用printf,那我還可以使用__cycleof__()么?當然了!就繼續以上述代碼為例子:
int32_tnCycleUsed=0; ...__cycleof__("my algorithm", { nCycleUsed = _; }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}...這里的代碼所實現的功能是:
測量了用戶函數my_algorithm_step_xxx()所使用的周期數:
測量的結果被轉存到了一個叫做nCycleUsed的變量中;
__cycleof__()將不會調用printf()進行任何內容輸出。
我相信很多小伙伴會揉了揉眼睛、仔細看了又看,然后回過頭來滿頭問號:
這是C語言? 這是什么語法? 不要懷疑,這就是C語言,只不過使用了一點GCC的語法擴展(感興趣的小伙伴可以復制這里的連接https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html#Statement-Exprs),考慮到本文只介紹perf_counter如何使用,而對其如何實現的并不關心,我們不妨略過GCC擴展語法的部分,專門來看看上述代碼的使用細節:
首先,為了方便大家觀察,我們先忽略圓括號內的部分:
...__cycleof__(...){ my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}...可以發現,這里跟此前并沒有什么不同:花括號包圍的部分就是我們要測量的代碼片斷;
接下來,我們專門來看__cycleof__()圓括號中的部分:
int32_tnCycleUsed=0; ...__cycleof__("my algorithm", { nCycleUsed = _;}){...}...容易發現,如果以“,” 為分隔符,那么實際傳遞給__cycleof__()的是兩個部分: 1、標注測量名稱的字符串
"my algorithm"2、一段用花括號括起來的代碼片斷:
{nCycleUsed = _;}其中,nCycleUsed是一個事先已經初始化好的變量。 這里,對于表示測量名稱的字符串"my algorithm",在這一用法下在最終的編譯結果里并不會占用任何RAM或者是ROM,但作為語法結構是必須的。 對于花括號所囊括的代碼片段來說,實際上在這個花括號里,你幾乎可以為所欲為:
你可以寫任意數量的代碼
你可以調用函數
你可以定義變量(當然這里定義變量肯定就是局部變量了)
但我們一般要做的事情其實是通過__cycleof__()所定義的一個局部變量"_"來獲取測量結果——這也是下面代碼的本意:
nCycleUsed = _;需要說明的是,這個局部變量"_"生命周期僅限于這個花括號中,因此不會影響 __cycleof__() 整個結構之外的部分——或者說,下述代碼是沒有意義的:
int32_t nCycleUsed = 0; ...__cycleof__("my algorithm", { nCycleUsed = _; }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();} printf("Cycle Used %d", _);編譯器會毫不客氣的告訴你 "_" 是一個未定義的變量,反之如果你這么做:
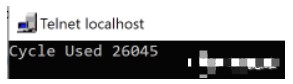
int32_t nCycleUsed = 0; ...__cycleof__("my algorithm", { nCycleUsed = _; printf("Cycle Used %d", _); }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c();}
則會看到你心怡的輸出結果:
沒有什么黑魔法
如果你對上述例子的等效形式(展開形式)感到非常好奇,其實大可不必,上述代碼在“邏輯上等效”于如下的形式:
int32_t nCycleUsed = 0; ...do {int64_t_=get_system_ticks(); { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } _ = get_system_ticks() - _; //!我們添加的代碼 nCycleUsed = _; printf("Cycle Used %d", _);}while(0);是不是突然就沒有那么神秘了?通過“邏輯等效”的形式展開,我們很容易發現一些有趣的內容:
起核心作用的是一個叫做get_system_ticks()的函數。實際上它返回的是從復位后 SysTick被使能至今所經歷的 CPU 周期數——由于它是int64_t 的類型,因此不用擔心超過 SysTick 24位計數器的量程,也不用擔心人類歷史范圍內會發生溢出的可能。知道這一點后,聰明的小伙伴就可以自己整活兒了。
由于 "_"是一個局部變量,因此可以判斷__cycleof__() 是支持嵌套的。
需要特別說明的是,get_system_tick()函數自己也是有CPU時鐘開銷的,所以如果要獲得較為精確的結果,推薦通過下面的方法來獲取校準值:
staticint64_ts_lPerfCalib; voidcalib_perf_counter(void){ int64_t lTemp = get_system_tick(); s_lPerfCalib = get_system_tick() - lTemp;} int64_tget_perf_counter_calib(void){return s_lPerfCalib;}具體如何使用,這里就不再贅述了。 說在后面的話。
perf_counter仍然在不停的演化中,這多虧了開源社區不斷的使用和反饋。perf_counter的應用場景實際上非常廣泛,包括但不限于:
為裸機或者RTOS提供Cycle級別的性能測量;
評估代碼片段的CPU占用;
算法精細優化時用于測量和觀察優化的效果;
測量中斷的響應時間;
測量中斷的發生間隔(查找最短時間間隔);
評估GUI的幀率或者刷新率;
與SystemCoreClock計算后,獲得一個系統時間戳(Timestamp);
當做Realtime Clock的基準;
作為隨機數種子
……
實際上perf_counter在我參與的另外一個開源項目arm-2d里也被悄悄的藏在了platform_utilities.lib中用來為例子代碼提供幀率的測量服務。
責任編輯:lq6
-
測量系統
+關注
關注
2文章
533瀏覽量
41353 -
Counter
+關注
關注
0文章
24瀏覽量
17980
原文標題:如何“優雅”的測量系統性能
文章出處:【微信號:InterruptISR,微信公眾號:嵌入式程序員】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【RA-Eco-RA2E1-48PIN-V1.0開發板試用】原創測量代碼運行時間
請問IC1(OPA140或OPA227)在電路中有什么作用?
導熱儀在材料性能分析中的重要作用

傳感器在控制系統中有什么作用
示波器探頭在高速信號測量中的作用
晶振在激光雷達系統中的作用有哪些
三坐標檢測技術在制造業中有何貢獻?

什么是勵磁電感?與漏磁電感有何區別呢?
如何在Aurix TC399中測量DMIPS?
default在單片機中有什么作用
高精度電壓源的作用及其在電壓測量中的應用






 工商網監
工商網監
評論