 深度學習中動作識別網絡學習
深度學習中動作識別網絡學習
動作識別網絡
深度學習在人體動作識別領域有兩類主要的網絡,一類是基于姿態評估,基于關鍵點實現的動作識別網絡;另外一類是直接預測的動作識別網絡。關于姿態評估相關的網絡模型應用,我們在前面的文章中已經介紹過了。OpenVINO2021.2版本中支持的動作識別網絡都不是基于關鍵點輸出的,而是基于Box直接預測,當前支持動作識別的預訓練模型與識別的動作數目支持列表如下:
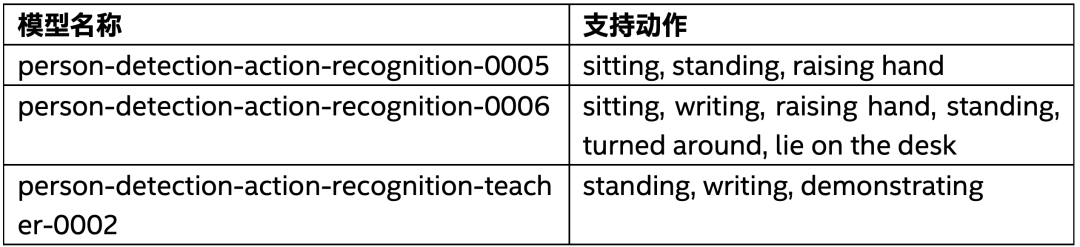
表-1
輸入與輸出格式
以person-detection-action-recognition-0005模型為例說明它們的輸入與輸出數據格式支持,我也不知道什么原因(個人猜測因為Caffe框架的原因),網絡的輸出居然都是SSD原始檢測頭,怎么解析,我有妙招,稍后送上!先看一下輸入與輸出格式說明:
輸入格式:
格式 NCHW=[1x3x400x680] ,Netron實際查看:
注意:OpenVINO2021.2安裝之后的文檔上格式說明是NHWC
輸出格式:
輸出有七個分支頭的數據,它們的名稱跟維度格式列表如下:
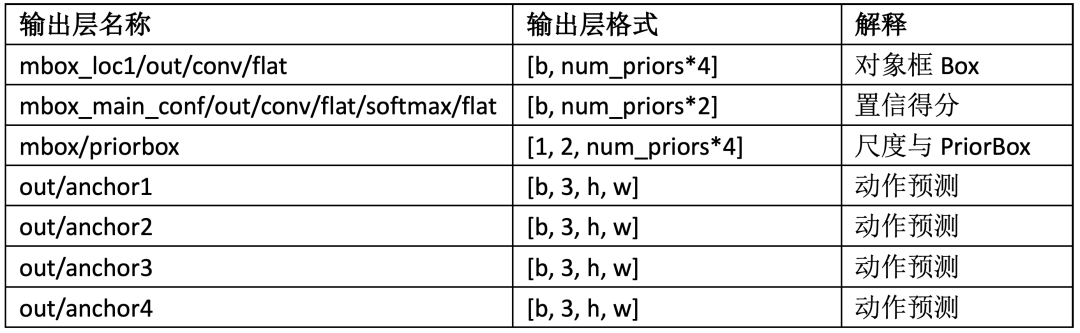
表-2
關于輸出格式的解釋,首先是num_priors值是多少,骨干網絡到SSD輸出頭,是實現了16倍的降采樣,最終輸出的h x w=25x43然后每個特征點預測4個PriorBox, 每個特征點預測動作,總計有三類的動作,所以動作預測輸出為: [b, 3, h, w] = [1x3x25x43],總計PriorBoxes數目為:num_priors=25x43x4=4300,這些都是SSD檢測頭的原始輸出,沒有非最大抑制,沒有經過轉換處理,所以想直接解析它們對開發應用的人來說是一個大麻煩!
輸出數據解析與處理問題
person-detection-action-recognition-0005網絡推理之后的輸出數據解析跟后處理特別的復雜,怎么解析原始輸出頭是個技術活,我從示例代碼中提取跟整理出來兩個C++文件,它們是:
action_detector.h
cnn.h
以及它們的實現文件:
action_detector.cpp
cnn.cpp
這個其中最重要的就是有個ActionDetection類,它有幾個方法,分別是:
void enqueue(const cv::Mat &frame)
void submitRequest()
void wait()
DetectedActions fetchResults()
這幾個方法的解釋分別如下:
enqueue方法的就是實現了推理請求創建與圖像數據的輸入設置,它的代碼實現如下:
if (!request) {
request = net_.CreateInferRequestPtr();
}
width_ = static_cast《float》(frame.cols);
height_ = static_cast《float》(frame.rows);
Blob::Ptr inputBlob = request-》GetBlob(input_name_);
matU8ToBlob《uint8_t》(frame, inputBlob);
enqueued_frames_ = 1;
submitRequest方法,就是執行推理,支持同步與異步推理執行模型,它的代碼實現如下:
if (request == nullptr) return;
if (isAsync) {
request-》StartAsync();
}
else {
request-》Infer();
}
wait方法,當同步推理時候無需調用,異步推理調用
fetchResults方法,該方法是推理過程中最復雜的部分,負責解析輸出的七個分支數據,生成Box與action標簽預測。簡單的說它的執行過程是這樣,首先獲取輸出的七個輸出數據,然后轉換為基于Mat的數據,然后循環每個特征圖的特征點預測Box與置信得分,大于閾值的置信得分對應的預測Box與PriorBox計算真實的BOX坐標,同時閾值化處理Action的置信得分,最終對結果完整非最大抑制之后輸出,得到數據結構為:
struct DetectedAction {
/** @brief BBox of detection */
cv::Rect rect;
/** @brief Action label */
int label;
/** @brief Confidence of detection */
float detection_conf;
/** @brief Confidence of predicted action */
float action_conf;
這樣就完成了對輸出的數據解析。
這個就是上述四個相關依賴文件,我已經把其他不相關的或者非必要的依賴全部去掉,基于這四個相關文件,就可以實現對表-1中動作識別模型的推理與解析輸出顯示。
動作識別代碼演示
動作識別代碼演示基于person-detection-action-recognition-0005網絡模型完成,該模型是基于室內場景數據訓練生成的,適合于教育智慧教室應用場景。首先需要初始化動作檢測類與初始化推理引擎加載,然后配置動作檢測類的相關參數,這些參數主要包括以下:
- 模型的權重文件路徑
- 推理引擎的計算設備支持
- 對象檢測閾值
- 動作預測閾值
- 支持動作類別數目
- 是否支持異步推理
等等。
配置完成之后設置與初始化ActionDetection類,然后就可以直接調用上述提到幾個類方法完成整個推理與輸出,根據輸出結果繪制與顯示即可,這部分的代碼如下:
cv::Mat frame = cv::imread(“D:/action_001.png”);
InferenceEngine::Core ie;
std::unique_ptr《AsyncDetection《DetectedAction》》 action_detector;
// Load action detector
ActionDetectorConfig action_config(model_xml);
action_config.deviceName = “CPU”;
action_config.ie = ie;
action_config.is_async = false;
action_config.detection_confidence_threshold = 0.1f;
action_config.action_confidence_threshold = 0.1f;
action_config.num_action_classes = 3;
action_detector.reset(new ActionDetection(action_config));
action_detector-》enqueue(frame);
action_detector-》submitRequest();
DetectedActions actions = action_detector-》fetchResults();
std::cout 《《 actions.size() 《《 std::endl;
for (int i = 0; i 《 actions.size(); i++) {
std::cout 《《 actions[i].rect 《《 std::endl;
std::cout 《《 actions[i].label 《《 std::endl;
cv::rectangle(frame, actions[i].rect, cv::Scalar(0, 0, 255), 2, 8, 0);
putText(frame, action_text_labels[actions[i].label], actions[i].rect.tl(), cv::FONT_HERSHEY_SIMPLEX, 0.75, cv::Scalar(0, 0, 255), 2, 8);
}
cv::imshow(“動作識別演示”, frame);
cv::waitKey(0);
return 0;
責任編輯:haq
-
深度學習
+關注
關注
73文章
5493瀏覽量
120979
原文標題:OpenVINO? 室內動作識別
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
AI大模型與深度學習的關系
基于Python的深度學習人臉識別方法
深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
深度學習中的模型權重
深度學習與卷積神經網絡的應用
深度學習在自動駕駛中的關鍵技術
深度解析深度學習下的語義SLAM

詳解深度學習、神經網絡與卷積神經網絡的應用

GPU在深度學習中的應用與優勢






 工商網監
工商網監
評論