 語義分割在三元組關系抽取中的作用是什么?
語義分割在三元組關系抽取中的作用是什么?
1. 總述
關系抽取(Relation Extraction, RE)是從純文本中提取未知關系事實,是自然語言處理領域非常重要的一項任務。過去的關系抽取方法主要將注意力集中于抽取單個實體對在某個句子內反映的關系,然而單句關系抽取在實踐中受到不可避免的限制:在真實場景如醫療、金融文檔中,有許多關系事實是蘊含在文檔中不同句子的實體對中的,且文檔中的多個實體之間,往往存在復雜的相互關系。如下圖所示:
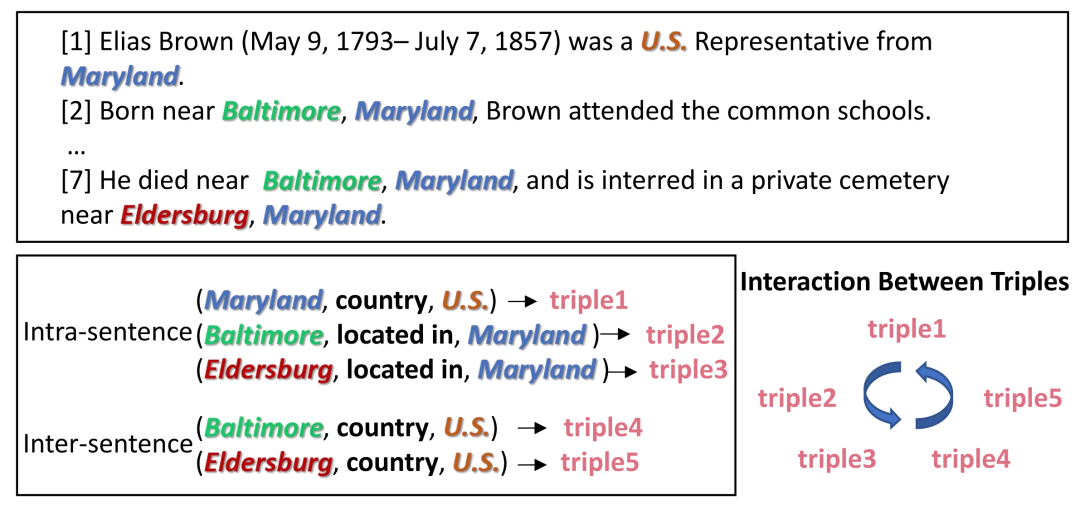
圖中包括了文章中的三個關系事實(從文檔標注的諸多關系事實中采樣得到),其中涉及這些關系事實的命名實體用彩色著色,其它命名實體用下劃線標出。與句子級相比,文檔級關系抽取中的文本要長得多,并且包含更多的實體, 這使得文檔級關系抽取更加困難。其中(Maryland, country, US)、(Baltimore, located_in, Maryland) 和 (Eldersburg, located_in, Maryland)三組triples中的實體在同一個句子中的出現,這種句內關系相對容易識別。然而,跨句實體之間的關系識別更具挑戰性, 例如,關系事實(Baltimore,country,U.S.)和(Eldersburg,country,U.S.)中的相關實體并沒有出現在同一個句子中并且需要長距離依賴, 具體來說,多個三元組之間的相互依賴是有利的,可以為實體多的情況下的關系分類提供指導。例如,如果句內關系 (Maryland, country, US) 已被識別,則{US} 不可能處于任何 person-social 關系中,例如"is the father of." 此外,根據{Eldersburg} 位于{Maryland} 和{Maryland} 屬于{US} 的三元組,我們可以推斷{Eldersburg} 屬于{US} . 如上所述,每個關系三元組可以向同一文本中的其他關系三元組提供信息。
文檔級關系抽取主要面臨以下三個挑戰:
1.相同關系會出現在多個句子。在文檔級關系抽取中,單一關系可能出現在多個輸入的句子中,因此模型需要依賴多個句子進行關系推斷。
2.相同實體會具有多個指稱。在復雜的文檔中,同一個實體具有各種各樣的指稱,因此模型需要聚合不同的指稱學習實體表示。
3.不同三元組之間需要信息交互。文檔包含多個實體關系三元組,不同的實體關系三元組之間存在邏輯關聯,因此模型需要捕捉同一篇文檔中三元組之間的信息交互。
然而先前的基于graph或基于transformer的模型僅單獨地使用實體對,而未考慮關系三元組之間的全局信息。本文創新性地提出DocuNet模型,首次將文檔級關系抽取任務類比于計算機視覺中的語義分割任務。DocuNet模型利用編碼器模塊捕獲實體的上下文信息,并采用U-shaped分割模塊在image-style特征圖上捕獲三元組之間的全局相互依賴性,通過預測實體級關系矩陣來捕獲local和global信息以增強文檔級關系抽取。實驗結果表明,我們的方法可以在三個基準數據集DocRED,CDR和GDA上獲得SOTA性能。
2.方法
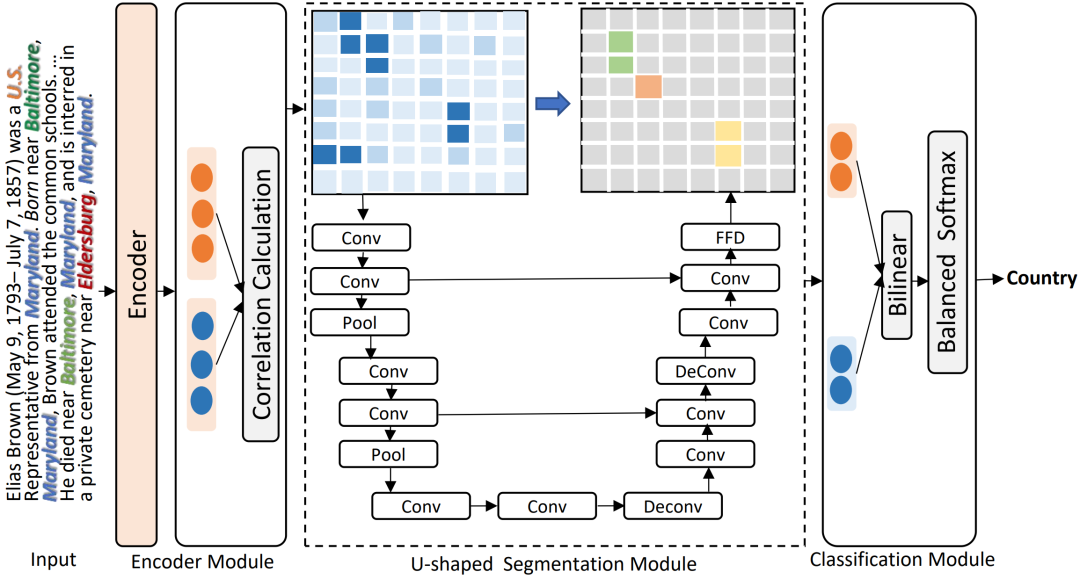
具體來說,DocuNet模型分為三個模塊:
(1)Encoder Module
我們將triple抽取視為sequence-to-sequence的任務,以更好地對實體和關系之間的交叉依賴進行建模。我們將輸入文本和輸出三元組定義為源和目標序列。源序列僅由輸入句子的標記組成,例如“[CLS] The United States President Trump was raised in the borough of Queens ...[SEP]”。我們連接由特殊標記 ”< e >” 和 ”< /e >”分隔的每個實體/關系的三元組作為目標序列。
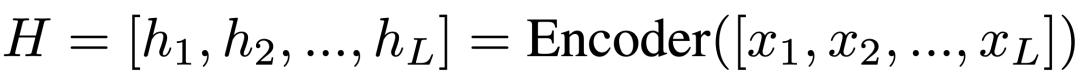
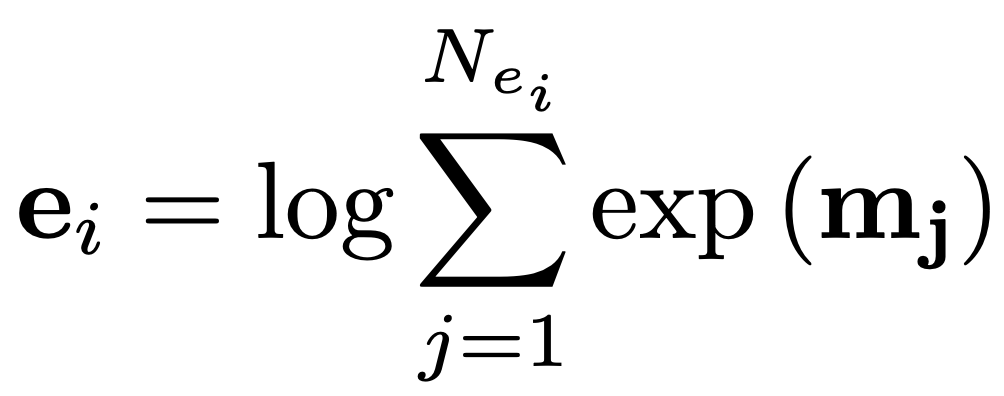
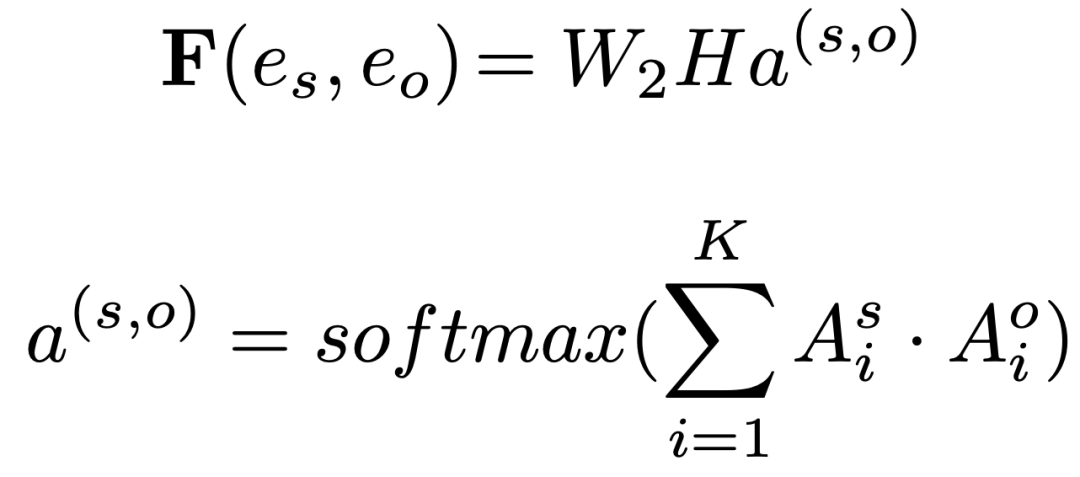
其中是實體感知注意力的注意力權重,對于矩陣中的每個實體,它們的相關性由一維特征向量捕獲。
(2)U-shaped Segmentation Module
三元組之間存在局部語義依賴,語義分割中的CNN可以促進感受野中實體對之間的局部信息交換。文檔級RE還需要全局信息來推斷三元組之間的關系,語義分割模塊中的下采樣和上采樣可以擴大當前實體pair對嵌入的感受野,能夠增強全局隱式推理:
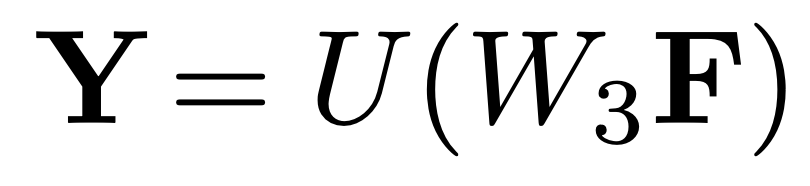
我們把實體級關系矩陣作為D-channel圖像,我們將文檔級關系預測公式化為像素級掩碼, 其中N是從所有數據集樣本中統計出的最大實體數。
(3)Classification Module
給定實體pair的特征表示和實體級關系矩陣Y,我們使用前饋神經網絡將它們映射到隱藏表示z。然后,我們通過雙線性函數獲得實體pair之間關系預測的概率表示如下:
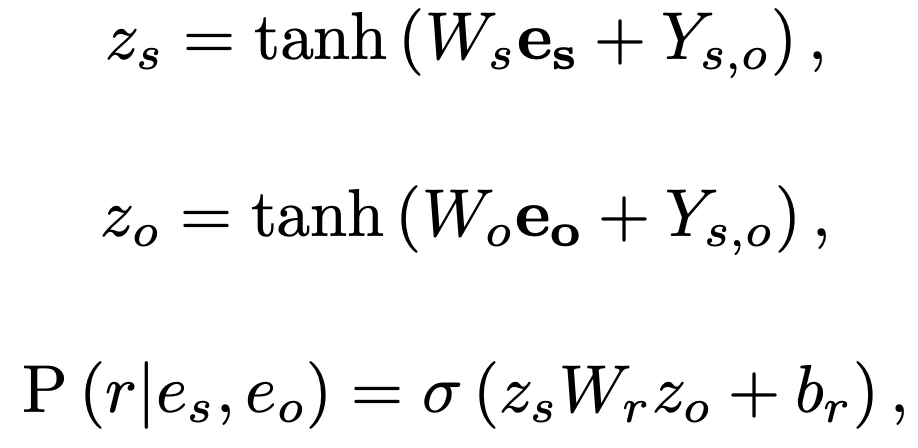
由于觀察到 RE 存在不平衡關系分布(許多實體對具有 NA 的關系),我們引入了一種平衡的 softmax 方法進行訓練:
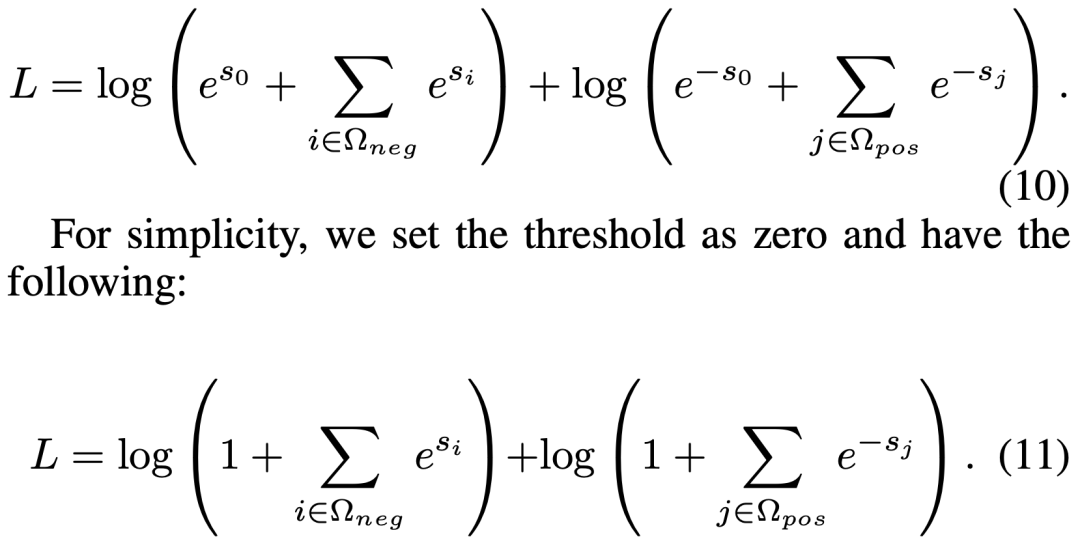
3. 實驗
(1)數據集
為了驗證DocuNet的效果,我們在三個文檔級關系抽取數據集上評測,數據集具體分析如下所示:
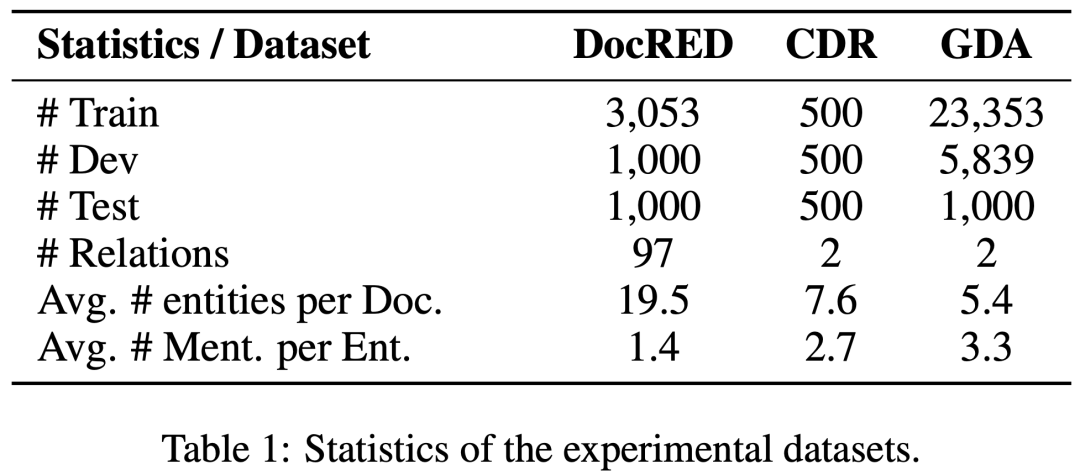
(2)實驗結果
由下面實驗結果表明,DocuNet比以往的文檔級關系抽取方法效果更佳。
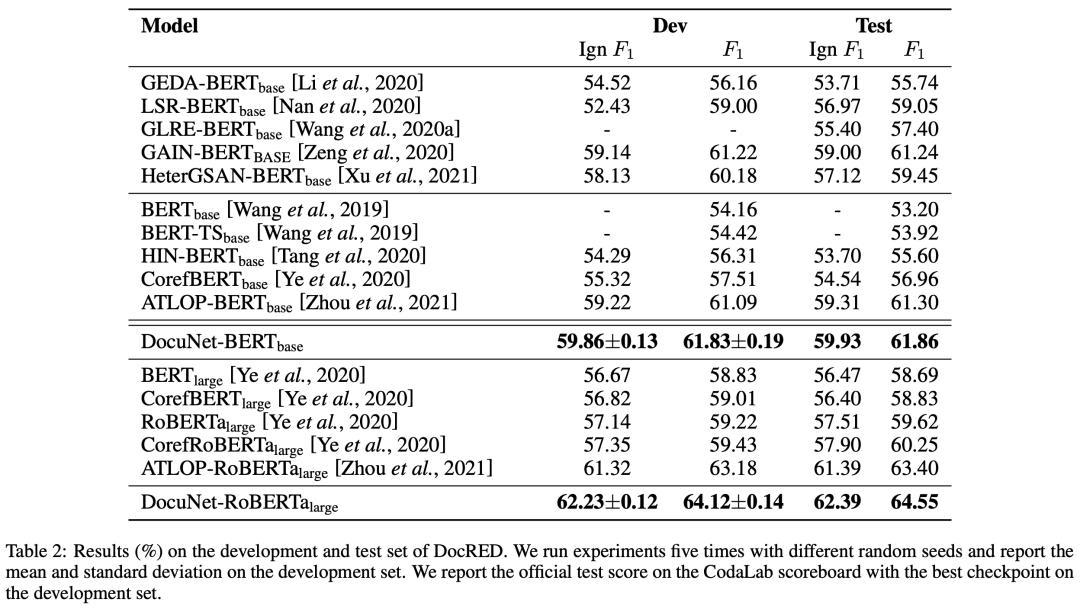
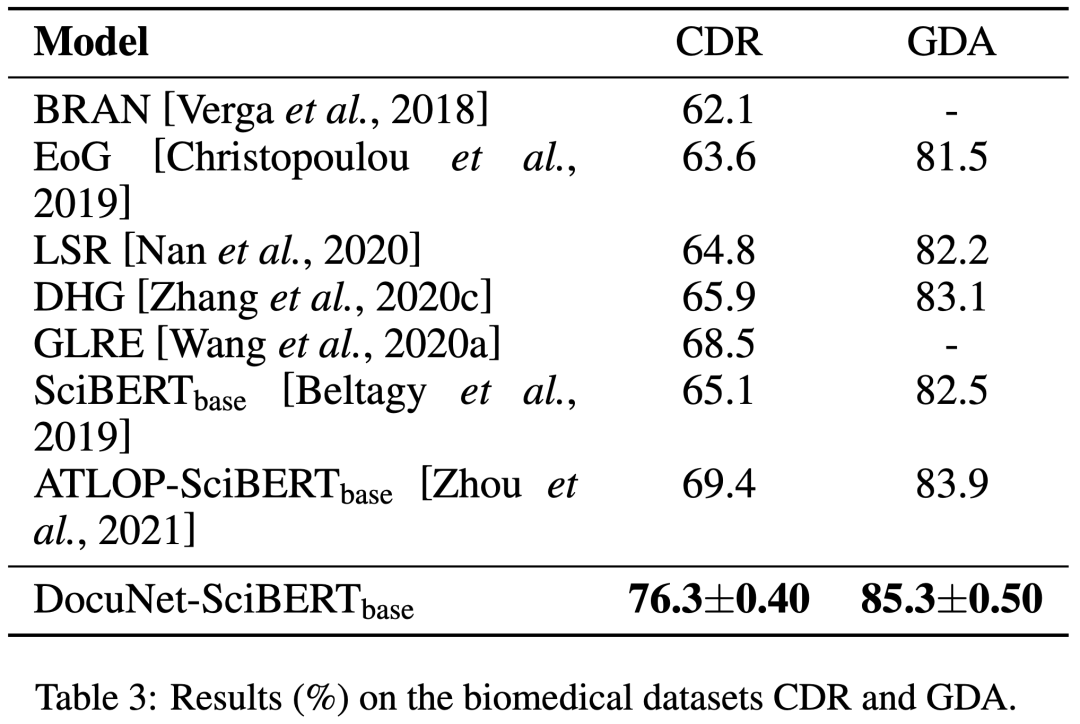
4. 總結與展望
在本文中,我們把文檔級關系抽取任務看作語義分割來求解,直接給出了如何將 UNet 應用于文檔級 RE 的解決方案,實驗結果表明U-shaped模塊能有效得理解局部上下文和全局相互依賴性。目前結果表明U-shaped模塊中的卷積學習了 RE 三元組之間的相互作用,但仍U-shaped模塊的推理作用尚是隱式的,未來對U-shaped模塊進一步的可視化分析有助于我們加強理解其是如何做三元組之間推理的。我們的方法證實了語義分割模塊在處理RE中有效性,仍需要更多的工作去探索U-shaped模塊在如aspect-based sentiment analysis等其他nlp任務上的應用。
-
語義
+關注
關注
0文章
21瀏覽量
8658 -
文本
+關注
關注
0文章
118瀏覽量
17068
原文標題:【IJCAI2021】長文本知識抽取:基于語義分割的文檔級三元組關系抽取
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
朗凱威三元鋰電池組 6020:高性能能源解決方案

三元鋰電池行業發展趨勢
三元鋰電池放電特性及應用
三元鋰電池使用壽命分析
三元鋰電池實際應用中的缺點
三元鋰電池的組成與功能
鴻蒙原生應用元服務開發-倉頡基礎數據類型元組類型

圖像語義分割的實用性是什么
圖像分割與語義分割中的CNN模型綜述
軟包三元鋰電池能和硬包三元鋰電池能混合用嗎
三元鋰離子電池優缺點分析






 工商網監
工商網監
評論