 如何從13個Kaggle比賽中挑選出的最好的Kaggle kernel
如何從13個Kaggle比賽中挑選出的最好的Kaggle kernel
導讀
覆蓋了模型相關的方方面面,從數據準備到模型的推理,每個階段的方法和要點,非常多的參考資料,足夠看一段時間了。
任何領域的成功都可以歸結為一套小規則和基本原則,當它們結合在一起時會產生偉大的結果。機器學習和圖像分類也不例外,工程師們可以通過參加像Kaggle這樣的競賽來展示最佳實踐。在這篇文章中,我將給你很多資源來學習,聚焦于從13個Kaggle比賽中挑選出的最好的Kaggle kernel。
這些比賽是:
Intel Image Classification:https://www.kaggle.com/puneet6060/intel-image-classification
Recursion Cellular Image Classification:https://www.kaggle.com/c/recursion-cellular-image-classification
SIIM-ISIC Melanoma Classification:https://www.kaggle.com/c/siim-isic-melanoma-classification
APTOS 2019 Blindness Detection:https://www.kaggle.com/c/aptos2019-blindness-detection/notebooks
Diabetic Retinopathy Detection:https://www.kaggle.com/c/diabetic-retinopathy-detection
ML Project?—?Image Classification:https://www.kaggle.com/c/image-classification-fashion-mnist/notebooks
Cdiscount’s Image Classification Challenge:
https://www.kaggle.com/c/cdiscount-image-classification-challenge/notebooks
Plant seedlings classifications:
https://www.kaggle.com/c/plant-seedlings-classification/notebooks
Aesthetic Visual Analysis:
https://www.kaggle.com/c/aesthetic-visual-analysis/notebooks
我們會討論調試深度學習解決方案的三個主要方面:
數據
模型
損失函數
還有很多例子項目(和參考資料)供你參考。
數據
圖像預處理 + EDA
每一個機器學習/深度學習解決方案都從原始數據開始。在數據處理管道中有兩個基本步驟。第一步是探索性數據分析 (EDA)。它幫助我們分析整個數據集并總結它的主要特征,比如類分布、大小分布等等。通常使用可視化方法來顯示這種分析的結果。第二步是圖像預處理,目的是對原始圖像提高圖像數據(也稱為圖像特征)的質量,通過抑制不必要的扭曲,縮放,增強重要的特征,使數據更適合模型并提高性能。你可以鉆研這些Kaggle筆記本,看看一些圖像預處理技術:
Visualisation:
https://www.kaggle.com/allunia/protein-atlas-exploration-and-baseline#Building-a-baseline-model-
Dealing with Class imbalance:https://www.kaggle.com/rohandeysarkar/ultimate-image-classification-guide-2020
Fill missing values (labels, features and, etc.):https://www.kaggle.com/datafan07/analysis-of-melanoma-metadata-and-effnet-ensemble
Normalisation?:https://www.kaggle.com/vincee/intel-image-classification-cnn-keras
Pre-processing:
https://www.kaggle.com/ratthachat/aptos-eye-preprocessing-in-diabetic-retinopathy#3.A-Important-Update-on-Color-Version-of-Cropping-&-Ben‘s-Preprocessing
數據增強
數據增強 可以通過從現有的訓練樣本中生成更多的訓練數據來擴展我們的數據集。通過大量的隨機轉換生成新的樣本,這些轉換不僅可以生成可信的圖像,而且還反映了真實的場景 —— 稍后將對此進行詳細介紹。這種技術得到了廣泛的應用,不僅僅是在訓練模型的數據樣本太少的情況下。在這種情況下,模型開始記憶訓練集,但無法泛化(在從未見過的數據上表現很差)。通常,當一個模型在訓練數據上表現很好,但在驗證數據上表現很差時,我們稱之為過擬合。為了解決這個問題,我們通常會嘗試獲取新數據,如果沒有可用的新數據,則可以使用數據增強。注:一般的經驗法則是始終使用數據增強技術,因為它有助于使我們的模型見識更多的變化并更好地泛化。即使我們有一個很大的數據集,也要使用數據增強,但這是以較慢的訓練速度為代價的,因為增強是在線完成的(即在訓練期間)。此外,對于每個任務或數據集,我們必須使用反映可能的現實場景的增強技術(例如,如果我們有一個貓/狗探測器,我們可以使用水平翻轉、剪裁、亮度和對比度,因為這些增強匹配不同的照片拍攝方式。這里是一些Kaggle比賽notebooks,你可以查看流行的數據增強技術:
Horizontal Flip:
https://www.kaggle.com/datafan07/analysis-of-melanoma-metadata-and-effnet-ensemble
Random Rotate and Random Dihedral:https://www.kaggle.com/iafoss/pretrained-resnet34-with-rgby-0-460-public-lb
Hue, Saturation, Contrast, Brightness, Crop:https://www.kaggle.com/cdeotte/triple-stratified-kfold-with-tfrecords
Colour jitter:
https://www.kaggle.com/nroman/melanoma-pytorch-starter-efficientnet
模型
開發一個基線
在這里,我們使用一個非常簡單的架構創建一個基本的模型,沒有任何正則化或dropout層,看看我們是否能超過50%的準確率基線。盡管我們不可能總能達到這個目標,但如果我們在嘗試了多種合理的架構后不能超過基線,那么輸入數據可能不包含模型進行預測所需的信息。
用Jeremy Howard的名言:“你應該能夠在15分鐘內使用50%或更少的數據集快速測試你是否正在朝著一個有希望的方向前進,如果沒有,你必須重新考慮一切。”
開發一個足夠大可以過擬合的模型
一旦我們的基線模型有足夠的能力超過基線分數,我們就可以增加基線模型的能力,直到它在數據集上過擬合為止,然后我們就開始應用正則化。我們可以通過以下方式增加模塊容量:
添加更多層
使用更好的結構
更完善的訓練流程
結構
根據文獻,以下架構的改進提高了模型的容量,但幾乎沒有改變計算復雜度。
Residual Networks
Wide Residual Networks
Inception
EfficientNet
Swish activation
Residual Attention Network
大多數時候,模型容量和精度是正相關的 —— 隨著容量的增加,精度也會增加,反之亦然。
訓練過程
下面是一些你可以用來調整你的模型的訓練過程,通過實例項目來看看它們是如何工作的:
Mixed-Precision Training
Large Batch-Size Training
Cross-Validation Set
Weight Initialization
Self-Supervised Training (Knowledge Distillation)
Learning Rate Scheduler
Learning Rate Warmup
Early Stopping
Differential Learning Rates
Ensemble
Transfer Learning
Fine-Tuning
超參數調試
與參數不同,hyperparameters是由你在配置模型時指定的(即學習率、epoch的數量、hidden units的數量、batch size大小等)。你可以通過使用hyperparameter調優庫,比如Scikit learn Grid Search,Keras Tuner來自動化這個過程,而不是去手動配置。這些庫會在你指定的范圍內嘗試所有的hyperparameter組合,返回表現最好的模型。需要調優的超參數越多,過程就越慢,因此最好選擇模型超參數的最小子集進行調優。并不是所有的模型超參數都同樣重要。一些超參數會對機器學習算法的行為產生巨大的影響,進而影響其性能。你應該小心地選擇那些對模型性能影響最大的參數,并對它們進行調優以獲得最佳性能。
正則化
這種方法迫使模型學習有意義和具有泛化能力的數據表示,通過對記憶/過擬合和欠擬合進行懲罰來實現,使模型對于它沒見過的數據更魯棒。解決上述問題的一個簡單方法是獲得更多的訓練數據,因為一個模型訓練的數據越多,自然就會泛化得越好。這里有一些技巧你可以試著減輕過擬合和欠擬合,項目如下:
Adding Dropout:https://www.kaggle.com/allunia/protein-atlas-exploration-and-baseline
Adding or changing the position of Batch Norm:https://www.kaggle.com/allunia/protein-atlas-exploration-and-baseline
Data augmentation:https://www.kaggle.com/cdeotte/triple-stratified-kfold-with-tfrecords
Mixup:https://arxiv.org/abs/1710.09412
Weight regularization:https://www.kaggle.com/allunia/protein-atlas-exploration-and-baseline
Gradient clipping:https://www.kaggle.com/allunia/protein-atlas-exploration-and-baseline
損失函數
損失函數也被稱為成本函數或目標函數,用于查找目標輸出的模型之間的差異,并幫助模型最小化它們之間的距離。
這里是一些最流行的損失函數,與項目實例,你會發現一些技巧,以提高你的模型的能力:
Label smoothing
Focal loss
SparseMax loss and Weighted cross-entropy
BCE loss, BCE with logits loss and Categorical cross-entropy loss
Additive Angular Margin Loss for Deep Face Recognition
評估 + 錯誤分析
在這里,我們做消融研究,并分析我們的實驗結果。我們確定了我們的模型的弱點和長處,并確定了未來需要改進的地方。在這個階段,你可以使用以下技術,并在鏈接的示例中查看它們是如何實現的:
Tracking metrics and Confusion matrix:
https://www.kaggle.com/vincee/intel-image-classification-cnn-keras
Grad CAM:https://arxiv.org/pdf/1610.02391v1.pdf
Test Time Augmentation (TTA):
https://www.kaggle.com/iafoss/pretrained-resnet34-with-rgby-0-460-public-lb
有許多實驗跟蹤和管理工具,采取最小設置為你自動保存所有數據,這使消融研究更容易。
最后
有許多方法來調整你的模型,并且新的想法總是會出現。深度學習是一個快速發展的領域,沒有什么靈丹妙藥。我們必須做很多實驗,足夠的試驗和錯誤會帶來突破。
英文原文:https://neptune.ai/blog/image-classification-tips-and-tricks-from-13-kaggle-competitions
—版權聲明—
來源丨AI公園 作者 | Prince Canuma 編譯 | ronghuaiyang
僅用于學術分享,版權屬于原作者。
若有侵權,請聯系刪除或修改!
編輯:jq
-
eda
+關注
關注
71文章
2712瀏覽量
172937 -
函數
+關注
關注
3文章
4308瀏覽量
62445 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998
原文標題:圖像分類:來自Kaggle中13個項目的Tips和Tricks
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何從參數和價格2個維度來挑選合適的LoRa模塊

關于LRU(Least Recently Used)的邏輯實現

挑選海外云服務器提供商攻略
MOS管品牌之“巔峰對決”

工業生產中不可或缺的“操作利器”—RFID揀貨標簽

三星貼片電容挑選技巧是什么呢?
大學生學單片機不能錯過的比賽

BP神經網絡算法的基本流程
NBA比賽收視率的背后是什么?

【Rust AI】01. 使用Jupyter學習Rust
OpenCL多Kernel并行計算結果討論分析
Kaggle知識點:訓練神經網絡的7個技巧

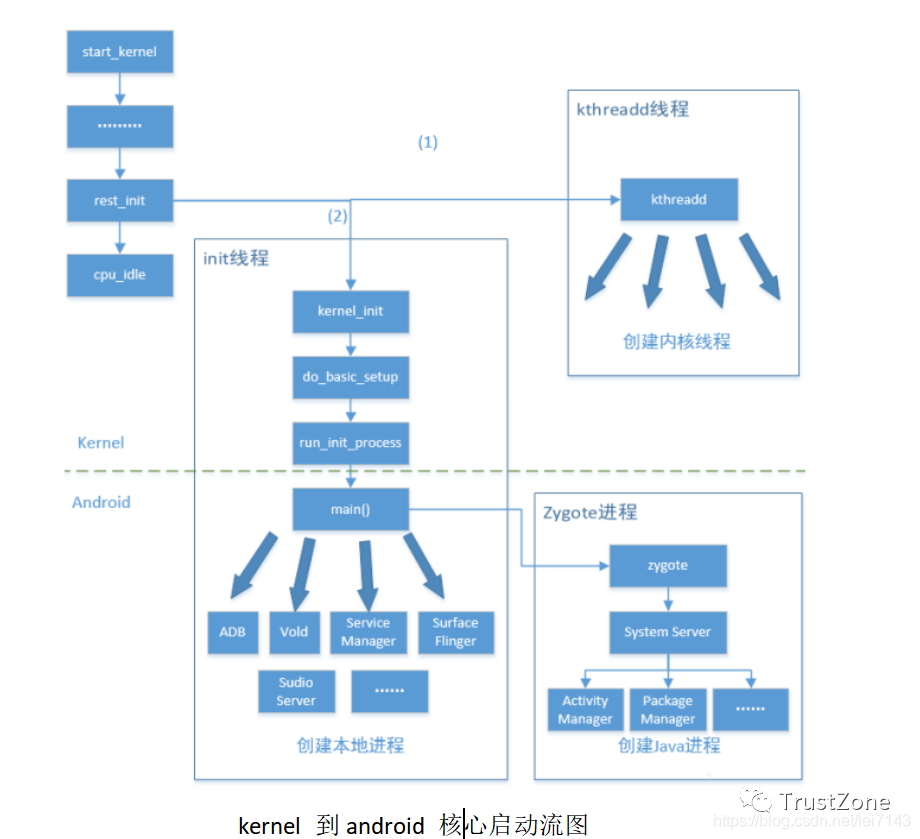
kernel到android核心啟動過程





 工商網監
工商網監
評論