") ClickHouse列式存儲(chǔ)數(shù)據(jù)庫的性能特性及底層存儲(chǔ)原理
ClickHouse列式存儲(chǔ)數(shù)據(jù)庫的性能特性及底層存儲(chǔ)原理
ClickHouse是一款MPP架構(gòu)的列式存儲(chǔ)數(shù)據(jù)庫,但MPP和列式存儲(chǔ)并不是什么"稀罕"的設(shè)計(jì)。擁有類似架構(gòu)的其他數(shù)據(jù)庫產(chǎn)品也有很多,但是為什么偏偏只有ClickHouse的性能如此出眾呢?ClickHouse發(fā)展至今的演進(jìn)過程一共經(jīng)歷了四個(gè)階段,每一次階段演進(jìn),相比之前都進(jìn)一步取其精華去其糟粕。可以說ClickHouse汲取了各家技術(shù)的精髓,將每一個(gè)細(xì)節(jié)都做到了極致。接下來將介紹ClickHouse的一些核心特性,正是這些特性形成的合力使得ClickHouse如此優(yōu)秀。
01完備的DBMS功能
ClickHouse擁有完備的管理功能,所以它稱得上是一個(gè)DBMS ( Database Management System,數(shù)據(jù)庫管理系統(tǒng)),而不僅是一個(gè)數(shù)據(jù)庫。作為一個(gè)DBMS,它具備了一些基本功能,如下所示。
?DDL (數(shù)據(jù)定義語言):可以動(dòng)態(tài)地創(chuàng)建、修改或刪除數(shù)據(jù)庫、表和視圖,而無須重啟服務(wù)。
?DML (數(shù)據(jù)操作語言):可以動(dòng)態(tài)查詢、插入、修改或刪除數(shù)據(jù)。
?權(quán)限控制:可以按照用戶粒度設(shè)置數(shù)據(jù)庫或者表的操作權(quán)限,保障數(shù)據(jù)的安全性。
?數(shù)據(jù)備份與恢復(fù):提供了數(shù)據(jù)備份導(dǎo)出與導(dǎo)入恢復(fù)機(jī)制,滿足生產(chǎn)環(huán)境的要求。
?分布式管理:提供集群模式,能夠自動(dòng)管理多個(gè)數(shù)據(jù)庫節(jié)點(diǎn)。
這里只列舉了一些最具代表性的功能,但已然足以表明為什么Click House稱得上是DBMS了。
02列式存儲(chǔ)與數(shù)據(jù)壓縮
列式存儲(chǔ)和數(shù)據(jù)壓縮,對(duì)于一款高性能數(shù)據(jù)庫來說是必不可少的特性。一個(gè)非常流行的觀點(diǎn)認(rèn)為,如果你想讓查詢變得更快,最簡(jiǎn)單且有效的方法是減少數(shù)據(jù)掃描范圍和數(shù)據(jù)傳輸時(shí)的大小,而列式存儲(chǔ)和數(shù)據(jù)壓縮就可以幫助我們實(shí)現(xiàn)上述兩點(diǎn)。列式存儲(chǔ)和數(shù)據(jù)壓縮通常是伴生的,因?yàn)橐话銇碚f列式存儲(chǔ)是數(shù)據(jù)壓縮的前提。
按列存儲(chǔ)與按行存儲(chǔ)相比,前者可以有效減少查詢時(shí)所需掃描的數(shù)據(jù)量,這一點(diǎn)可以用一個(gè)示例簡(jiǎn)單說明。假設(shè)一張數(shù)據(jù)表A擁有50個(gè)字段A1~A50,以及100行數(shù)據(jù)。

按列存儲(chǔ)相比按行存儲(chǔ)的另一個(gè)優(yōu)勢(shì)是對(duì)數(shù)據(jù)壓縮的友好性。同樣可以用一個(gè)示例簡(jiǎn)單說明壓縮的本質(zhì)是什么。假設(shè)有兩個(gè)字符串a(chǎn)bcdefghi和bcdefghi,現(xiàn)在對(duì)它們進(jìn)行壓縮,如下所示:

壓縮前:abcdefghi_bcdefghi
壓縮后:abcdefghi_(9,8)
可以看到,壓縮的本質(zhì)是按照一定步長對(duì)數(shù)據(jù)進(jìn)行匹配掃描,當(dāng)發(fā)現(xiàn)重復(fù)部分的時(shí)候就進(jìn)行編碼轉(zhuǎn)換。例如上述示例中的(9,8),表示如果從下劃線開始向前移動(dòng)9個(gè)字節(jié),會(huì)匹配到8個(gè)字節(jié)長度的重復(fù)項(xiàng),即這里的bcdefghi。
真實(shí)的壓縮算法自然比這個(gè)示例更為復(fù)雜,但壓縮的實(shí)質(zhì)就是如此。數(shù)據(jù)中的重復(fù)項(xiàng)越多,則壓縮率越高;壓縮率越高,則數(shù)據(jù)體量越小;而數(shù)據(jù)體量越小,則數(shù)據(jù)在網(wǎng)絡(luò)中的傳輸越快,對(duì)網(wǎng)絡(luò)帶寬和磁盤IO的壓力也就越小。既然如此,那怎樣的數(shù)據(jù)最可能具備重復(fù)的特性呢?答案是屬于同一個(gè)列字段的數(shù)據(jù),因?yàn)樗鼈儞碛邢嗤臄?shù)據(jù)類型和現(xiàn)實(shí)語義,重復(fù)項(xiàng)的可能性自然就更高。
ClickHouse就是一款使用列式存儲(chǔ)的數(shù)據(jù)庫,數(shù)據(jù)按列進(jìn)行組織,屬于同一列的數(shù)據(jù)會(huì)被保存在一起,列與列之間也會(huì)由不同的文件分別保存(這里主要指MergeTree表引擎)。數(shù)據(jù)默認(rèn)使用LZ4算法壓縮,在Yandex.Metrica的生產(chǎn)環(huán)境中,數(shù)據(jù)總體的壓縮比可以達(dá)到8:1 (未壓縮前17PB,壓縮后2PB )。列式存儲(chǔ)除了降低IO和存儲(chǔ)的壓力之外,還為向量化執(zhí)行做好了鋪墊。
03向量化執(zhí)行引擎
坊間有句玩笑,即"能用錢解決的問題,千萬別花時(shí)間"。而業(yè)界也有種調(diào)侃如出一轍,即"能升級(jí)硬件解決的問題,千萬別優(yōu)化程序"。有時(shí)候,你千辛萬苦優(yōu)化程序邏輯帶來的性能提升,還不如直接升級(jí)硬件來得簡(jiǎn)單直接。這雖然只是一句玩笑不能當(dāng)真,但硬件層面的優(yōu)化確實(shí)是最直接、最高效的提升途徑之一。向量化執(zhí)行就是這種方式的典型代表,這項(xiàng)寄存器硬件層面的特性,為上層應(yīng)用程序的性能帶來了指數(shù)級(jí)的提升。
向量化執(zhí)行,可以簡(jiǎn)單地看作一項(xiàng)消除程序中循環(huán)的優(yōu)化。這里用一個(gè)形象的例子比喻。小胡經(jīng)營了一家果汁店,雖然店里的鮮榨蘋果汁深受大家喜愛,但客戶總是抱怨制作果汁的速度太慢。小胡的店里只有一臺(tái)榨汁機(jī),每次他都會(huì)從籃子里拿出一個(gè)蘋果,放到榨汁機(jī)內(nèi)等待出汁。如果有8個(gè)客戶,每個(gè)客戶都點(diǎn)了一杯蘋果汁,那么小胡需要重復(fù)循環(huán)8次上述的榨汁流程,才能榨出8杯蘋果汁。如果制作一杯果汁需要5分鐘,那么全部制作完畢則需要40分鐘。為了提升果汁的制作速度,小胡想出了一個(gè)辦法。他將榨汁機(jī)的數(shù)量從1臺(tái)增加到了8臺(tái),這么一來,他就可以從籃子里一次性拿出8個(gè)蘋果,分別放入8臺(tái)榨汁機(jī)同時(shí)榨汁。此時(shí),小胡只需要5分鐘就能夠制作出8杯蘋果汁。為了制作n杯果汁,非向量化執(zhí)行的方式是用1臺(tái)榨汁機(jī)重復(fù)循環(huán)制作n次,而向量化執(zhí)行的方式是用n臺(tái)榨汁機(jī)只執(zhí)行1次。
為了實(shí)現(xiàn)向量化執(zhí)行,需要利用CPU的SIMD指令。SIMD的全稱是Single Instruction Multiple Data,即用單條指令操作多條數(shù)據(jù)。現(xiàn)代計(jì)算機(jī)系統(tǒng)概念中,它是通過數(shù)據(jù)并行以提高性能的一種實(shí)現(xiàn)方式(其他的還有指令級(jí)并行和線程級(jí)并行),它的原理是在CPU寄存器層面實(shí)現(xiàn)數(shù)據(jù)的并行操作。
在計(jì)算機(jī)系統(tǒng)的體系結(jié)構(gòu)中,存儲(chǔ)系統(tǒng)是一種層次結(jié)構(gòu)。典型服務(wù)器計(jì)算機(jī)的存儲(chǔ)層次結(jié)構(gòu)如圖1所示。一個(gè)實(shí)用的經(jīng)驗(yàn)告訴我們,存儲(chǔ)媒介距離CPU越近,則訪問數(shù)據(jù)的速度越快。
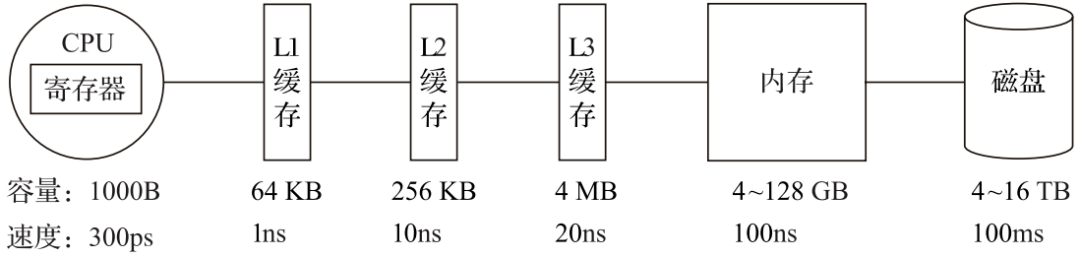
從上圖中可以看到,從左向右,距離CPU越遠(yuǎn),則數(shù)據(jù)的訪問速度越慢。從寄存器中訪問數(shù)據(jù)的速度,是從內(nèi)存訪問數(shù)據(jù)速度的300倍,是從磁盤中訪問數(shù)據(jù)速度的3000萬倍。所以利用CPU向量化執(zhí)行的特性,對(duì)于程序的性能提升意義非凡。
ClickHouse目前利用SSE4.2指令集實(shí)現(xiàn)向量化執(zhí)行。
04關(guān)系模型與SQL查詢
相比HBase和Redis這類NoSQL數(shù)據(jù)庫,ClickHouse使用關(guān)系模型描述數(shù)據(jù)并提供了傳統(tǒng)數(shù)據(jù)庫的概念(數(shù)據(jù)庫、表、視圖和函數(shù)等)。與此同時(shí),ClickHouse完全使用SQL作為查詢語言(支持GROUP BY、ORDER BY、JOIN、IN等大部分標(biāo)準(zhǔn)SQL ),這使得它平易近人,容易理解和學(xué)習(xí)。因?yàn)殛P(guān)系型數(shù)據(jù)庫和SQL語言,可以說是軟件領(lǐng)域發(fā)展至今應(yīng)用最為廣泛的技術(shù)之一,擁有極高的"群眾基礎(chǔ)"。也正因?yàn)镃lickHouse提供了標(biāo)準(zhǔn)協(xié)議的SQL查詢接口,使得現(xiàn)有的第三方分析可視化系統(tǒng)可以輕松與它集成對(duì)接。在SQL解析方面,ClickHouse是大小寫敏感的,這意味著SELECT a和SELECT A所代表的語義是不同的。
關(guān)系模型相比文檔和鍵值對(duì)等其他模型,擁有更好的描述能力,也能夠更加清晰地表述實(shí)體間的關(guān)系。更重要的是,在OLAP領(lǐng)域,已有的大量數(shù)據(jù)建模工作都是基于關(guān)系模型展開的(星型模型、雪花模型乃至寬表模型)。ClickHouse使用了關(guān)系模型,所以將構(gòu)建在傳統(tǒng)關(guān)系型數(shù)據(jù)庫或數(shù)據(jù)倉庫之上的系統(tǒng)遷移到ClickHouse的成本會(huì)變得更低,可以直接沿用之前的經(jīng)驗(yàn)成果。
05多樣化的表引擎
也許因?yàn)閅andex.Metrica的最初架構(gòu)是基于MySQL實(shí)現(xiàn)的,所以在ClickHouse的設(shè)計(jì)中,能夠察覺到一些MySQL的影子,表引擎的設(shè)計(jì)就是其中之一。與MySQL類似,ClickHouse也將存儲(chǔ)部分進(jìn)行了抽象,把存儲(chǔ)引擎作為一層獨(dú)立的接口。截至本書完稿時(shí),ClickHouse共擁有合并樹、內(nèi)存、文件、接口和其他6大類20多種表引擎。其中每一種表引擎都有著各自的特點(diǎn),用戶可以根據(jù)實(shí)際業(yè)務(wù)場(chǎng)景的要求,選擇合適的表引擎使用。
通常而言,一個(gè)通用系統(tǒng)意味著更廣泛的適用性,能夠適應(yīng)更多的場(chǎng)景。但通用的另一種解釋是平庸,因?yàn)樗鼰o法在所有場(chǎng)景內(nèi)都做到極致。
在軟件的世界中,并不會(huì)存在一個(gè)能夠適用任何場(chǎng)景的通用系統(tǒng),為了突出某項(xiàng)特性,勢(shì)必會(huì)在別處有所取舍。其實(shí)世間萬物都遵循著這樣的道理,就像信天翁和蜂鳥,雖然都屬于鳥類,但它們各自的特點(diǎn)卻鑄就了完全不同的體貌特征。信天翁擅長遠(yuǎn)距離飛行,環(huán)繞地球一周只需要1至2個(gè)月的時(shí)間。因?yàn)樗軌蜷L時(shí)間處于滑行狀態(tài),5天才需要扇動(dòng)一次翅膀,心率能夠保持在每分鐘100至200次之間。而蜂鳥能夠垂直懸停飛行,每秒可以揮動(dòng)翅膀70~100次,飛行時(shí)的心率能夠達(dá)到每分鐘1000次。如果用數(shù)據(jù)庫的場(chǎng)景類比信天翁和蜂鳥的特點(diǎn),那么信天翁代表的可能是使用普通硬件就能實(shí)現(xiàn)高性能的設(shè)計(jì)思路,數(shù)據(jù)按粗粒度處理,通過批處理的方式執(zhí)行;而蜂鳥代表的可能是按細(xì)粒度處理數(shù)據(jù)的設(shè)計(jì)思路,需要高性能硬件的支持。
將表引擎獨(dú)立設(shè)計(jì)的好處是顯而易見的,通過特定的表引擎支撐特定的場(chǎng)景,十分靈活。對(duì)于簡(jiǎn)單的場(chǎng)景,可直接使用簡(jiǎn)單的引擎降低成本,而復(fù)雜的場(chǎng)景也有合適的選擇。
06多線程與分布式
ClickHouse幾乎具備現(xiàn)代化高性能數(shù)據(jù)庫的所有典型特征,對(duì)于可以提升性能的手段可謂是一一用盡,對(duì)于多線程和分布式這類被廣泛使用的技術(shù),自然更是不在話下。
如果說向量化執(zhí)行是通過數(shù)據(jù)級(jí)并行的方式提升了性能,那么多線程處理就是通過線程級(jí)并行的方式實(shí)現(xiàn)了性能的提升。相比基于底層硬件實(shí)現(xiàn)的向量化執(zhí)行SIMD,線程級(jí)并行通常由更高層次的軟件層面控制。現(xiàn)代計(jì)算機(jī)系統(tǒng)早已普及了多處理器架構(gòu),所以現(xiàn)今市面上的服務(wù)器都具備良好的多核心多線程處理能力。由于SIMD不適合用于帶有較多分支判斷的場(chǎng)景,ClickHouse也大量使用了多線程技術(shù)以實(shí)現(xiàn)提速,以此和向量化執(zhí)行形成互補(bǔ)。
如果一個(gè)籃子裝不下所有的雞蛋,那么就多用幾個(gè)籃子來裝,這就是分布式設(shè)計(jì)中分而治之的基本思想。同理,如果一臺(tái)服務(wù)器性能吃緊,那么就利用多臺(tái)服務(wù)的資源協(xié)同處理。為了實(shí)現(xiàn)這一目標(biāo),首先需要在數(shù)據(jù)層面實(shí)現(xiàn)數(shù)據(jù)的分布式。因?yàn)樵诜植际筋I(lǐng)域,存在一條金科玉律—計(jì)算移動(dòng)比數(shù)據(jù)移動(dòng)更加劃算。在各服務(wù)器之間,通過網(wǎng)絡(luò)傳輸數(shù)據(jù)的成本是高昂的,所以相比移動(dòng)數(shù)據(jù),更為聰明的做法是預(yù)先將數(shù)據(jù)分布到各臺(tái)服務(wù)器,將數(shù)據(jù)的計(jì)算查詢直接下推到數(shù)據(jù)所在的服務(wù)器。ClickHouse在數(shù)據(jù)存取方面,既支持分區(qū)(縱向擴(kuò)展,利用多線程原理),也支持分片(橫向擴(kuò)展,利用分布式原理),可以說是將多線程和分布式的技術(shù)應(yīng)用到了極致。
07多主架構(gòu)
HDFS、Spark、HBase和Elasticsearch這類分布式系統(tǒng),都采用了Master-Slave主從架構(gòu),由一個(gè)管控節(jié)點(diǎn)作為Leader統(tǒng)籌全局。而ClickHouse則采用Multi-Master多主架構(gòu),集群中的每個(gè)節(jié)點(diǎn)角色對(duì)等,客戶端訪問任意一個(gè)節(jié)點(diǎn)都能得到相同的效果。這種多主的架構(gòu)有許多優(yōu)勢(shì),例如對(duì)等的角色使系統(tǒng)架構(gòu)變得更加簡(jiǎn)單,不用再區(qū)分主控節(jié)點(diǎn)、數(shù)據(jù)節(jié)點(diǎn)和計(jì)算節(jié)點(diǎn),集群中的所有節(jié)點(diǎn)功能相同。所以它天然規(guī)避了單點(diǎn)故障的問題,非常適合用于多數(shù)據(jù)中心、異地多活的場(chǎng)景。
08在線查詢
ClickHouse經(jīng)常會(huì)被拿來與其他的分析型數(shù)據(jù)庫作對(duì)比,比如Vertica、SparkSQL、Hive和Elasticsearch等,它與這些數(shù)據(jù)庫確實(shí)存在許多相似之處。例如,它們都可以支撐海量數(shù)據(jù)的查詢場(chǎng)景,都擁有分布式架構(gòu),都支持列存、數(shù)據(jù)分片、計(jì)算下推等特性。這其實(shí)也側(cè)面說明了ClickHouse在設(shè)計(jì)上確實(shí)吸取了各路奇技淫巧。與其他數(shù)據(jù)庫相比,ClickHouse也擁有明顯的優(yōu)勢(shì)。例如,Vertica這類商用軟件價(jià)格高昂;SparkSQL與Hive這類系統(tǒng)無法保障90%的查詢?cè)?秒內(nèi)返回,在大數(shù)據(jù)量下的復(fù)雜查詢可能會(huì)需要分鐘級(jí)的響應(yīng)時(shí)間;而Elasticsearch這類搜索引擎在處理億級(jí)數(shù)據(jù)聚合查詢時(shí)則顯得捉襟見肘。
正如ClickHouse的"廣告詞"所言,其他的開源系統(tǒng)太慢,商用的系統(tǒng)太貴,只有Clickouse在成本與性能之間做到了良好平衡,即又快又開源。ClickHouse當(dāng)之無愧地闡釋了"在線"二字的含義,即便是在復(fù)雜查詢的場(chǎng)景下,它也能夠做到極快響應(yīng),且無須對(duì)數(shù)據(jù)進(jìn)行任何預(yù)處理加工。
09Leetcode超級(jí)會(huì)員數(shù)據(jù)分片與分布式查詢
數(shù)據(jù)分片是將數(shù)據(jù)進(jìn)行橫向切分,這是一種在面對(duì)海量數(shù)據(jù)的場(chǎng)景下,解決存儲(chǔ)和查詢瓶頸的有效手段,是一種分治思想的體現(xiàn)。ClickHouse支持分片,而分片則依賴集群。每個(gè)集群由1到多個(gè)分片組成,而每個(gè)分片則對(duì)應(yīng)了ClickHouse的1個(gè)服務(wù)節(jié)點(diǎn)。分片的數(shù)量上限取決于節(jié)點(diǎn)數(shù)量( 1個(gè)分片只能對(duì)應(yīng)1個(gè)服務(wù)節(jié)點(diǎn))。
ClickHouse并不像其他分布式系統(tǒng)那樣,擁有高度自動(dòng)化的分片功能。ClickHouse提供了本地表( Local Table )與分布式表( Distributed Table )的概念。一張本地表等同于一份數(shù)據(jù)的分片。而分布式表本身不存儲(chǔ)任何數(shù)據(jù),它是本地表的訪問代理,其作用類似分庫中間件。借助分布式表,能夠代理訪問多個(gè)數(shù)據(jù)分片,從而實(shí)現(xiàn)分布式查詢。
這種設(shè)計(jì)類似數(shù)據(jù)庫的分庫和分表,十分靈活。例如在業(yè)務(wù)系統(tǒng)上線的初期,數(shù)據(jù)體量并不高,此時(shí)數(shù)據(jù)表并不需要多個(gè)分片。所以使用單個(gè)節(jié)點(diǎn)的本地表(單個(gè)數(shù)據(jù)分片)即可滿足業(yè)務(wù)需求,待到業(yè)務(wù)增長、數(shù)據(jù)量增大的時(shí)候,再通過新增數(shù)據(jù)分片的方式分流數(shù)據(jù),并通過分布式表實(shí)現(xiàn)分布式查詢。這就好比一輛手動(dòng)擋賽車,它將所有的選擇權(quán)都交到了使用者的手中。
云原生概念的誕生ClickHouse存儲(chǔ)層
ClickHouse從OLAP場(chǎng)景需求出發(fā),定制開發(fā)了一套全新的高效列式存儲(chǔ)引擎,并且實(shí)現(xiàn)了數(shù)據(jù)有序存儲(chǔ)、主鍵索引、稀疏索引、數(shù)據(jù)Sharding、數(shù)據(jù)Partitioning、TTL、主備復(fù)制等豐富功能。以上功能共同為ClickHouse極速的分析性能奠定了基礎(chǔ)。
列式存儲(chǔ)
與行存將每一行的數(shù)據(jù)連續(xù)存儲(chǔ)不同,列存將每一列的數(shù)據(jù)連續(xù)存儲(chǔ)。示例圖如下:
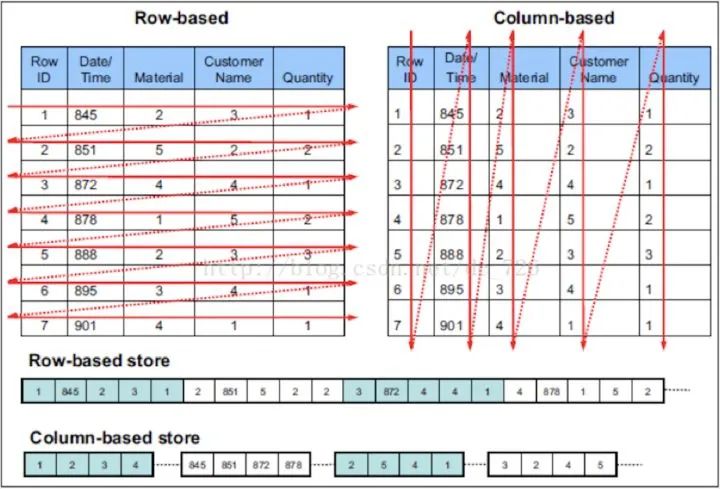
相比于行式存儲(chǔ),列式存儲(chǔ)在分析場(chǎng)景下有著許多優(yōu)良的特性。
1)如前所述,分析場(chǎng)景中往往需要讀大量行但是少數(shù)幾個(gè)列。在行存模式下,數(shù)據(jù)按行連續(xù)存儲(chǔ),所有列的數(shù)據(jù)都存儲(chǔ)在一個(gè)block中,不參與計(jì)算的列在IO時(shí)也要全部讀出,讀取操作被嚴(yán)重放大。而列存模式下,只需要讀取參與計(jì)算的列即可,極大的減低了IO cost,加速了查詢。
2)同一列中的數(shù)據(jù)屬于同一類型,壓縮效果顯著。列存往往有著高達(dá)十倍甚至更高的壓縮比,節(jié)省了大量的存儲(chǔ)空間,降低了存儲(chǔ)成本。
3)更高的壓縮比意味著更小的data size,從磁盤中讀取相應(yīng)數(shù)據(jù)耗時(shí)更短。
4)自由的壓縮算法選擇。不同列的數(shù)據(jù)具有不同的數(shù)據(jù)類型,適用的壓縮算法也就不盡相同。可以針對(duì)不同列類型,選擇最合適的壓縮算法。
5)高壓縮比,意味著同等大小的內(nèi)存能夠存放更多數(shù)據(jù),系統(tǒng)cache效果更好。
數(shù)據(jù)有序存儲(chǔ)
ClickHouse支持在建表時(shí),指定將數(shù)據(jù)按照某些列進(jìn)行sort by。
排序后,保證了相同sort key的數(shù)據(jù)在磁盤上連續(xù)存儲(chǔ),且有序擺放。在進(jìn)行等值、范圍查詢時(shí),where條件命中的數(shù)據(jù)都緊密存儲(chǔ)在一個(gè)或若干個(gè)連續(xù)的Block中,而不是分散的存儲(chǔ)在任意多個(gè)Block, 大幅減少需要IO的block數(shù)量。另外,連續(xù)IO也能夠充分利用操作系統(tǒng)page cache的預(yù)取能力,減少page fault。
主鍵索引
ClickHouse支持主鍵索引,它將每列數(shù)據(jù)按照index granularity(默認(rèn)8192行)進(jìn)行劃分,每個(gè)index granularity的開頭第一行被稱為一個(gè)mark行。主鍵索引存儲(chǔ)該mark行對(duì)應(yīng)的primary key的值。
對(duì)于where條件中含有primary key的查詢,通過對(duì)主鍵索引進(jìn)行二分查找,能夠直接定位到對(duì)應(yīng)的index granularity,避免了全表掃描從而加速查詢。
但是值得注意的是:ClickHouse的主鍵索引與MySQL等數(shù)據(jù)庫不同,它并不用于去重,即便primary key相同的行,也可以同時(shí)存在于數(shù)據(jù)庫中。要想實(shí)現(xiàn)去重效果,需要結(jié)合具體的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree實(shí)現(xiàn),我們會(huì)在未來的文章系列中再進(jìn)行詳細(xì)解讀。
數(shù)據(jù)插入、更新、刪除
Clickhouse是個(gè)分析型數(shù)據(jù)庫。這種場(chǎng)景下,數(shù)據(jù)一般是不變的,因此Clickhouse對(duì)update、delete的支持是比較弱的,實(shí)際上并不支持標(biāo)準(zhǔn)的update、delete操作。
Clickhouse通過alter方式實(shí)現(xiàn)更新、刪除,它把update、delete操作叫做mutation(突變)。
標(biāo)準(zhǔn)SQL的更新、刪除操作是同步的,即客戶端要等服務(wù)端反回執(zhí)行結(jié)果(通常是int值);而Clickhouse的update、delete是通過異步方式實(shí)現(xiàn)的,當(dāng)執(zhí)行update語句時(shí),服務(wù)端立即反回,但是實(shí)際上此時(shí)數(shù)據(jù)還沒變,而是排隊(duì)等著。
Mutation具體過程
首先,使用where條件找到需要修改的分區(qū);然后,重建每個(gè)分區(qū),用新的分區(qū)替換舊的,分區(qū)一旦被替換,就不可回退;對(duì)于每個(gè)分區(qū),可以認(rèn)為是原子性的;但對(duì)于整個(gè)mutation,如果涉及多個(gè)分區(qū),則不是原子性的。
? 更新功能不支持更新有關(guān)主鍵或分區(qū)鍵的列。
? 更新操作沒有原子性,即在更新過程中select結(jié)果很可能是一部分變了,一部分沒變,從上邊的具體過程就可以知道。
? 更新是按提交的順序執(zhí)行的。
? 更新一旦提交,不能撤銷,即使重啟Clickhouse服務(wù),也會(huì)繼續(xù)按照system.mutations的順序繼續(xù)執(zhí)行。
? 已完成更新的條目不會(huì)立即刪除,保留條目的數(shù)量由finished_mutations_to_keep存儲(chǔ)引擎參數(shù)確定。超過數(shù)據(jù)量時(shí)舊的條目會(huì)被刪除。
? 更新可能會(huì)卡住,比如update intvalue='abc’這種類型錯(cuò)誤的更新語句執(zhí)行不過去,那么會(huì)一直卡在這里,此時(shí),可以使用KILL MUTATION來取消。
使用建議
按照官方的說明,update/delete的使用場(chǎng)景是一次更新大量數(shù)據(jù),也就是where條件篩選的結(jié)果應(yīng)該是一大片數(shù)據(jù)。
舉例:alter table test update status=1 where status=0 and day='2020-04-01',一次更新一天的數(shù)據(jù)。
那么,能否一次只更新一條數(shù)據(jù)呢?例如:alter table test update pv=110 where id=100當(dāng)然也可以,但頻繁的這種操作,可能會(huì)對(duì)服務(wù)造成壓力。這很容易理解,如上文提到,更新的單位是分區(qū),如果只更新一條數(shù)據(jù),那么需要重建一個(gè)分區(qū);如果更新100條數(shù)據(jù),而這100條可能落在3個(gè)分區(qū)上,則需重建3個(gè)分區(qū);相對(duì)來說一次更新一批數(shù)據(jù)的整體效率遠(yuǎn)高于一次更新一行。對(duì)于頻繁單條更新的這種場(chǎng)景,建議使用ReplacingMergeTree引擎來變相解決。具體如何使用,以后有時(shí)間再整理。
Hbase隨機(jī)讀寫,但是Hbase的update操作不是真的update,它的實(shí)際操作是insert一條新的數(shù)據(jù),打上不同的timestamp,而老的數(shù)據(jù)會(huì)在有效期之后自動(dòng)刪除。而Clickhouse干脆就不支持update和delete。
ClickHouse核心涉及模塊
1. Column與Field
Column和Field是ClickHouse數(shù)據(jù)最基礎(chǔ)的映射單元。作為一款百分之百的列式存儲(chǔ)數(shù)據(jù)庫,ClickHouse按列存儲(chǔ)數(shù)據(jù),內(nèi)存中的一列數(shù)據(jù)由一個(gè)Column對(duì)象表示。Column對(duì)象分為接口和實(shí)現(xiàn)兩個(gè)部分,在IColumn接口對(duì)象中,定義了對(duì)數(shù)據(jù)進(jìn)行各種關(guān)系運(yùn)算的方法,例如插入數(shù)據(jù)的insertRangeFrom和insertFrom方法、用于分頁的cut,以及用于過濾的filter方法等。而這些方法的具體實(shí)現(xiàn)對(duì)象則根據(jù)數(shù)據(jù)類型的不同,由相應(yīng)的對(duì)象實(shí)現(xiàn),例如ColumnString、ColumnArray和ColumnTuple等。在大多數(shù)場(chǎng)合,ClickHouse都會(huì)以整列的方式操作數(shù)據(jù),但凡事也有例外。如果需要操作單個(gè)具體的數(shù)值(也就是單列中的一行數(shù)據(jù)),則需要使用Field對(duì)象,F(xiàn)ield對(duì)象代表一個(gè)單值。與Column對(duì)象的泛化設(shè)計(jì)思路不同,F(xiàn)ield對(duì)象使用了聚合的設(shè)計(jì)模式。在Field對(duì)象內(nèi)部聚合了Null、UInt64、String和Array等13種數(shù)據(jù)類型及相應(yīng)的處理邏輯。
2. DataType
數(shù)據(jù)的序列化和反序列化工作由DataType負(fù)責(zé)。IDataType接口定義了許多正反序列化的方法,它們成對(duì)出現(xiàn),例如serializeBinary和deserializeBinary、serializeTextJSON和deserializeTextJSON等,涵蓋了常用的二進(jìn)制、文本、JSON、XML、CSV和Protobuf等多種格式類型。IDataType也使用了泛化的設(shè)計(jì)模式,具體方法的實(shí)現(xiàn)邏輯由對(duì)應(yīng)數(shù)據(jù)類型的實(shí)例承載,例如DataTypeString、DataTypeArray及DataTypeTuple等。
DataType雖然負(fù)責(zé)序列化相關(guān)工作,但它并不直接負(fù)責(zé)數(shù)據(jù)的讀取,而是轉(zhuǎn)由從Column或Field對(duì)象獲取。在DataType的實(shí)現(xiàn)類中,聚合了相應(yīng)數(shù)據(jù)類型的Column對(duì)象和Field對(duì)象。例如,DataTypeString會(huì)引用字符串類型的ColumnString,而DataTypeArray則會(huì)引用數(shù)組類型的ColumnArray,以此類推。
3. Block與Block流
ClickHouse內(nèi)部的數(shù)據(jù)操作是面向Block對(duì)象進(jìn)行的,并且采用了流的形式。雖然Column和Filed組成了數(shù)據(jù)的基本映射單元,但對(duì)應(yīng)到實(shí)際操作,它們還缺少了一些必要的信息,比如數(shù)據(jù)的類型及列的名稱。于是ClickHouse設(shè)計(jì)了Block對(duì)象,Block對(duì)象可以看作數(shù)據(jù)表的子集。Block對(duì)象的本質(zhì)是由數(shù)據(jù)對(duì)象、數(shù)據(jù)類型和列名稱組成的三元組,即Column、DataType及列名稱字符串。Column提供了數(shù)據(jù)的讀取能力,而DataType知道如何正反序列化,所以Block在這些對(duì)象的基礎(chǔ)之上實(shí)現(xiàn)了進(jìn)一步的抽象和封裝,從而簡(jiǎn)化了整個(gè)使用的過程,僅通過Block對(duì)象就能完成一系列的數(shù)據(jù)操作。在具體的實(shí)現(xiàn)過程中,Block并沒有直接聚合Column和DataType對(duì)象,而是通過ColumnWithTypeAndName對(duì)象進(jìn)行間接引用。
有了Block對(duì)象這一層封裝之后,對(duì)Block流的設(shè)計(jì)就是水到渠成的事情了。流操作有兩組頂層接口:IBlockInputStream負(fù)責(zé)數(shù)據(jù)的讀取和關(guān)系運(yùn)算,IBlockOutputStream負(fù)責(zé)將數(shù)據(jù)輸出到下一環(huán)節(jié)。Block流也使用了泛化的設(shè)計(jì)模式,對(duì)數(shù)據(jù)的各種操作最終都會(huì)轉(zhuǎn)換成其中一種流的實(shí)現(xiàn)。IBlockInputStream接口定義了讀取數(shù)據(jù)的若干個(gè)read虛方法,而具體的實(shí)現(xiàn)邏輯則交由它的實(shí)現(xiàn)類來填充。
IBlockInputStream接口總共有60多個(gè)實(shí)現(xiàn)類,它們涵蓋了ClickHouse數(shù)據(jù)攝取的方方面面。這些實(shí)現(xiàn)類大致可以分為三類:第一類用于處理數(shù)據(jù)定義的DDL操作,例如DDLQueryStatusInputStream等;第二類用于處理關(guān)系運(yùn)算的相關(guān)操作,例如LimitBlockInput-Stream、JoinBlockInputStream及AggregatingBlockInputStream等;第三類則是與表引擎呼應(yīng),每一種表引擎都擁有與之對(duì)應(yīng)的BlockInputStream實(shí)現(xiàn),例如MergeTreeBaseSelect-BlockInputStream ( MergeTree表引擎)、TinyLogBlockInputStream ( TinyLog表引擎)及KafkaBlockInputStream ( Kafka表引擎)等。
IBlockOutputStream的設(shè)計(jì)與IBlockInputStream如出一轍。IBlockOutputStream接口同樣也定義了若干寫入數(shù)據(jù)的write虛方法。它的實(shí)現(xiàn)類比IBlockInputStream要少許多,一共只有20多種。這些實(shí)現(xiàn)類基本用于表引擎的相關(guān)處理,負(fù)責(zé)將數(shù)據(jù)寫入下一環(huán)節(jié)或者最終目的地,例如MergeTreeBlockOutputStream、TinyLogBlockOutputStream及StorageFileBlock-OutputStream等。
4. Table
在數(shù)據(jù)表的底層設(shè)計(jì)中并沒有所謂的Table對(duì)象,它直接使用IStorage接口指代數(shù)據(jù)表。表引擎是ClickHouse的一個(gè)顯著特性,不同的表引擎由不同的子類實(shí)現(xiàn),例如IStorageSystemOneBlock (系統(tǒng)表)、StorageMergeTree (合并樹表引擎)和StorageTinyLog (日志表引擎)等。IStorage接口定義了DDL (如ALTER、RENAME、OPTIMIZE和DROP等)、read和write方法,它們分別負(fù)責(zé)數(shù)據(jù)的定義、查詢與寫入。在數(shù)據(jù)查詢時(shí),IStorage負(fù)責(zé)根據(jù)AST查詢語句的指示要求,返回指定列的原始數(shù)據(jù)。后續(xù)對(duì)數(shù)據(jù)的進(jìn)一步加工、計(jì)算和過濾,則會(huì)統(tǒng)一交由Interpreter解釋器對(duì)象處理。對(duì)Table發(fā)起的一次操作通常都會(huì)經(jīng)歷這樣的過程,接收AST查詢語句,根據(jù)AST返回指定列的數(shù)據(jù),之后再將數(shù)據(jù)交由Interpreter做進(jìn)一步處理。
文章出處:【微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】
責(zé)任編輯:gt
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7430瀏覽量
87733 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9029瀏覽量
85207 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3767瀏覽量
64280
原文標(biāo)題:ClickHouse 特性及底層存儲(chǔ)原理
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—通過拼接數(shù)據(jù)庫碎片恢復(fù)SQLserver數(shù)據(jù)庫

云數(shù)據(jù)庫可以租用嗎?完整租用流程來了
基于分布式存儲(chǔ)WDS的金融信創(chuàng)云承載數(shù)據(jù)庫類關(guān)鍵應(yīng)用
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—SqlServer數(shù)據(jù)庫底層File Record被截?cái)酁?的數(shù)據(jù)恢復(fù)案例
大型數(shù)據(jù)庫可選擇WDS作為其數(shù)據(jù)庫一體機(jī)產(chǎn)品存儲(chǔ)底座

數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—raid5陣列上層Sql Server數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論