 一篇關于CVPR‘21使用RL做點云圖像配準
一篇關于CVPR‘21使用RL做點云圖像配準
深度強化學習(Deep RL)可以通過序列決策式的方式,在很多方面得到應用。這里我們主要介紹一篇CVPR‘21使用RL做點云圖像配準的文章:ReAgent: Point Cloud Registration using Imitation and Reinforcement Learninghttps://arxiv.org/abs/2103.15231
總體上而言,ReAgent是通過訓練了一個Policy網絡,狀態是Source點云和Target點云,輸出一系列動作(旋轉、平移Source點云),使得Source點云最終和Target點云在相同的地方重合。那么我們現在深入其中的細節,其實針對RL的應用文章,最需要關注的點是以下4個方面:
狀態(State)設計
動作(Action)設計
獎勵(Reward)設計
算法實現
一般來說RL的應用文章在算法上無非使用的是較為廣泛使用的算法模型,如DQN、PPO、SAC等。
State
這里的State是將Source和Targe點云通過一個PointNet類似的結構,從高維點云信息Embedding到一個特征空間后,兩者Concatenate得到State的表征信息。這里從上圖中可以比較好的理解。
Action
這里Action的選擇就比較直觀,我們需要通過一些操作來旋轉、平移Source點云。那么Action就直接設置為旋轉、平移相關的動作。這篇文章在實現上,使用離散的動作集,比如x方向的平移為[0.0033,0.01,0.03,0.09,0.27],當然是有正有負。
Reward
Reward的設計就更為直觀,就是在執行動作后,看是否Source和Target之間更加接近了。這里使用的是Chamfer Distance(CD)來衡量,下面給出Reward的設計:
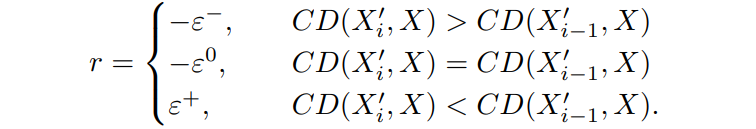
這里的Reward也很直觀,就是加入執行動作之后,是否變得更好?如果變好了就給一個正的獎勵,如果變差了就給一個負的獎勵。
算法實現
文章采用了PPO。那么ReAgent的總體框架就如下圖:
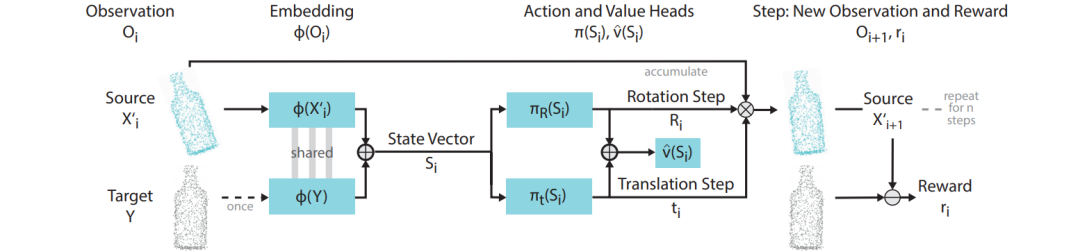
如果理解了這個問題中的State、Action的設計,還是相當直觀的框架。同時筆者也跑通了ReAgent的代碼,實際看下其效果如何,主要是觀察其序列動作過程
可以看到ReAgent的動作還是相當“絲滑“”且準確的。也希望更多的讀者能夠探索RL的各種應用,做到像人一樣“絲滑”~
—版權聲明—
來源:強化學習技術前沿
僅用于學術分享,版權屬于原作者。
若有侵權,請聯系微信號: 刪除或修改!
編輯:jq
-
代碼
+關注
關注
30文章
4750瀏覽量
68357 -
深度強化學習
+關注
關注
0文章
14瀏覽量
2295
原文標題:深度強化學習點云配準——ReAgent技術詳解
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用語義線索增強局部特征匹配

為什么在水文計算中廣泛采用配線法
Labview實現自定義四維云圖(三維曲面圖像)可視化顯示
何謂準直器,準直器有什么作用
OpenCV攜Orbbec 3D相機亮相CVPR 2024,加速AI視覺創新
OpenCV攜奧比中光3D相機亮相CVPR 2024
機器人3D視覺引導系統框架介紹
如何提取、匹配圖像特征點
基于大模型的遙感圖像變化檢測新網絡
RL究竟是如何與LLM做結合的?

配網故障定位裝置|讓電力系統的故障無處遁形!







 工商網監
工商網監
評論