 SSI技術-從概念到現實
SSI技術-從概念到現實
Xilinx 3D IC技術簡介
跨Die約束?SLR?SSI?這些是使用UltraScale+/V7常見的概念,但是這些概念到底什么意思?有什么聯系?下面我們從根本上去解釋這些概念。
SSI技術-從概念到現實
SOC和NOC概念傳統的SoC現在很常見,現在用的手機CPU等都是采用這種方式,常見的架構如下:
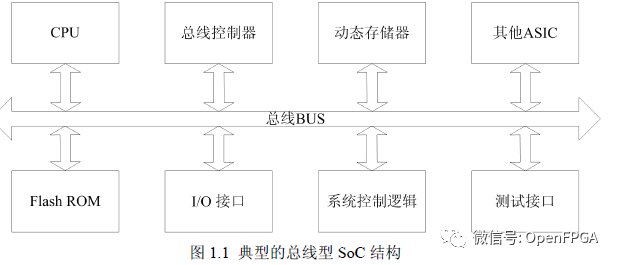
系統采用總線互連結構,多核間的通訊問題已經成為制約系統性能提升的主要瓶頸。
NOC的概念提出來很多年了,但是使用該總線的IC相對很少,但是最近幾年興起的RISC-V或許會在未來更多的應用這一總線。NoC是指在單芯片上集成大量的計算資源以及連接這些資源的片上通信網絡,如圖1所示。NoC包括計算和通信兩個子系統,計算子系統完成廣義的“計算”任務。
PE既可以是現有意義上的CPU、SoC,也可以是各種專用功能的IP核或存儲器陣列、可重構硬件等;通信子系統(圖中由Switch組成的子系統)負責連接PE,實現計算資源之間的高速通信。通信節點及其間的互連線所構成的網絡被稱為片上通信網絡(On-Chip Network, OCN),它借鑒了分布式計算系統的通信方式,用路由和分組交換技術替代傳統的片上總線來完成通信任務(參考:http://www.nxhydt.com/d.html)。
通過上面的兩個總線基礎,對于Xilinx采用的3D IC概念的理解就不是很難了。
介紹參考:WP380
隨著FPGA在系統設計中的地位越來越重要,設計變得越來越龐大和復雜,對邏輯容量和片上資源的要求也越來越高。到目前為止,FPGA主要依靠摩爾定律來滿足這一需求,每一代新工藝都能提供近兩倍的邏輯容量。然而,要跟上當今高端市場的需求,摩爾定律所能提供的還遠遠不夠。
FPGA技術最積極的使用者渴望采用每一代FPGA中容量最高、帶寬最高的器件。然而,供應商在產品生命周期的早期構建此類FPGA的挑戰可能會限制其提供客戶生產運行所需設備數量的能力。這是因為實現可重編程技術的電路開銷對最大的FPGA的可制造性產生了負面影響。在新工藝節點的早期階段,當缺陷密度較高時,隨著模具尺寸的增大,模具成品率急劇下降。隨著制造工藝的成熟,缺陷密度下降,大型模具的可制造性顯著提高。
因此,雖然最大的FPGA在產品推出時供不應求,但隨著時間的推移,它們的數量最終會滿足最終客戶的數量需求。為了應對可編程的需求,一些領先的客戶向Xilinx提出挑戰,要求Xilinx在產品推出后盡快用最大的fpga支持其批量生產需求。
例如,電信市場需要集成數十個串行收發器的FPGA,以提供高信號完整性。設備還需要提供廣泛的互連邏輯和塊RAM,用于數據處理和流量管理,同時保持當前的外形尺寸和電源。為了獲得先發制人的優勢,設備制造商希望盡快增加新產品的制造。
Xilinx以一種創新的方法響應了這些要求,構建了帶寬和容量等于或超過最大單片FPGA芯片的FPGA芯片,具有較小芯片的制造和上市時間優勢,以加快批量生產。SSI技術實現了這些優勢,它使用帶有微泵的無源硅插入器和通過硅通孔(TSV)將多個高度可制造的FPGA芯片片(稱為超級邏輯區(SLR))組合在一個封裝中。該技術還允許不同類型的芯片或硅工藝在插入器上互連。這種結構稱為異構FPGA。
互連多個FPGA的挑戰
SSI技術解決了先前阻礙將兩個或多個FPGA的互連邏輯結合起來以創建用于實現復雜設計的更大的“虛擬FPGA”的嘗試的挑戰。這些挑戰包括:
?可用的I/O數量不足以連接復雜的信號網絡,這些信號必須在分區設計的FPGA之間傳遞,也不足以將FPGA連接到系統的其余部分。
?信號在FPGA之間傳遞的延遲限制了性能。
?使用標準設備I/O在多個FPGA之間創建邏輯連接會增加功耗。
關鍵挑戰:有限的連通性
片上系統(SoC)設計由數百萬個門電路組成,這些門電路由多條總線、復雜的時鐘分配網絡和大量的控制信號組成。在多個FPGA之間成功地劃分SoC設計需要大量的I/O來實現跨越FPGA之間間隙的網絡。由于SoC設計包括1024位寬的總線,即使針對最高可用管腳數的FPGA封裝,工程師也必須使用數據緩沖和其他設計優化,這些優化對于實現高性能總線和其他關鍵路徑所需的數千個一對一連接效率較低。
封裝技術是造成這種I/O限制的關鍵因素之一。目前最先進的軟件包提供大約1200個I/O引腳,遠遠低于所需的I/O總數。
在芯片級,I/O技術還存在另一個限制,因為I/O資源的擴展速度與每個新進程節點的互連邏輯資源的擴展速度不同。當與用于在FPGA的核心構建可編程邏輯資源的晶體管相比時,構成器件I/O結構的晶體管必須大得多,以提供芯片到芯片I/O標準所需的電流和電壓。因此,增加芯片上標準I/o的數量對于提供用于組合多個FPGA芯片的連接來說不是一個可行的解決方案。
關鍵挑戰:延遲過大
延遲增加是多FPGA方法的另一個挑戰。對于跨多個FPGA的設計,標準設備I/O會施加管腳到管腳的延遲,從而降低整體電路性能。此外,在標準I/O上使用時域復用(TDM)通過在每個I/O上運行多個信號來增加虛擬管腳計數,這會帶來更大的延遲,從而使I/O速度降低4倍到32倍或更多。這些降低的速度對于ASIC原型設計和仿真來說通常是可以接受的,但是對于最終產品應用來說通常太慢。
關鍵挑戰:Power Penalty
TDM方法也會導致更高的功耗。當用于在多個FPGA之間的PCB線路上驅動數百個封裝到封裝的連接時,與在單片芯片上連接邏輯網絡相比,標準設備I/O引腳的功耗損失很大。
類似地,多芯片模塊(MCM)技術為在單個封裝中集成多個FPGA芯片提供了潛在的形狀因子縮減優勢。然而,MCM方法仍然受到限制I/O計數以及不期望的延遲和功耗特性的限制。
關鍵挑戰:高速串行連接的信號完整性
特別是在高速串行I/O連接很常見的通信應用中,信號完整性差可能成為實現設計關閉的主要瓶頸。FPGA必須提供適當的收發器信號保真度,否則必須花費無數的時間來優化I/O參數、修改PCB設計和執行通道優化以獲得設計成功。對于某些要求線速率超過25Gb/s的應用程序,提供足夠的信號完整性是一項非常重要的任務。
Xilinx SSI技術為了克服這些限制,Xilinx開發了一種新的方法,用于構建高容量和高性能fpga的生產量。新的解決方案通過提供更多的連接來實現多個芯片之間的高帶寬連接。與多FPGA或MCM方法相比,它還具有更低的延遲和顯著更低的功耗,同時能夠在單個封裝中集成大量的互連邏輯、收發器和片上資源。
在FPGA系列的密度范圍內,中密度器件代表了“最佳點”。也就是說,與上一代器件相比,它們在芯片尺寸上提供的容量和帶寬明顯更大,在FPGA產品生命周期中可以比同一系列中的最大器件更早交付。因此,通過在單個器件中組合多個這樣的芯片,可以匹配或超過最大的單片器件所提供的容量和帶寬,但是具有較小芯片的制造和體積比優勢。
Xilinx以創新的方式應用了幾種成熟的技術,從而實現了這樣一種解決方案。通過將TSV和微泵技術與其創新的ASMBL相結合,體系結構方面,Xilinx正在構建一種新的FPGA,它提供滿足可編程需求所需的容量、性能、能力和功率特性。通過無源插入器,Xilinx SSI技術結合了多個FPGA。插入器提供數萬個芯片到芯片的連接,以實現超高的互連帶寬,功耗低得多,延遲為標準I/O的五分之一。
硅插入層最初是為各種芯片堆疊設計方法而開發的,它提供了模塊化設計靈活性和高性能集成,適用于廣泛的應用。硅插入器作為基于硅制造工藝(例如,65 nm或45 nm工藝)的互連載體,在該工藝上多個芯片并排設置并互連。SSI技術避免了由于將多個FPGA芯片堆疊在彼此或MCM上而導致的功耗和可靠性問題。
與有機或陶瓷基板相比,在mcm中,硅插入層提供了更精細的互連幾何結構(約20倍密集的線間距)以提供設備級互連層次結構,支持10000多個管芯到管芯的連接。
用微泵制作用于疊層硅集成的FPGA芯片片Xilinx SSI技術的基礎是公司專有的ASBL體系結構,一種模塊化結構,包括以實現可配置邏輯塊(CLB)、塊RAM、DSP片、SelectIO等關鍵功能的瓷磚形式的Xilinx FPGA構建塊。SelectIO和串行收發器。
這些資源被組織成列,然后組合起來創建一個FPGA。通過改變柱的高度和排列,可以創建各種各樣的設備來滿足不同的市場需求(圖2)。FPGA包含用于生成時鐘信號和用位流數據編程SRAM單元的附加塊,位流數據配置設備以實現最終用戶期望的功能。
從基本的ASMBL體系結構構造開始,Xilinx引入了三個關鍵的修改,它們支持堆疊硅集成。首先,每個芯片片接收自己的時鐘和配置電路。然后對布線結構進行了修改,使其能夠繞過傳統的并行和串行I/O電路,通過芯片表面的鈍化直接連接到FPGA邏輯陣列中的布線資源。
最后,每個單反相機都要經過額外的加工步驟來制造微泵,將芯片連接到硅襯底上。正是這一創新使得連接的數量大大增加,延遲大大降低,功耗也大大低于使用傳統I/O(每瓦特的SLR到SLR連接帶寬是標準I/O的100倍)。
帶TSV的硅插入器無源硅插入器將多個FPGA SLR互連在一起。它是建立在一個低風險,高產量的65nm工藝,并提供四層金屬化建設數以萬計的記錄道,連接多個FPGA芯片的邏輯區域。
組裝好的芯片組的“X射線視圖”的概念。它包含一個由四個FPGA單反并排安裝在無源硅插入器上的堆棧(底視圖)。插入器被顯示為透明的,以便能夠看到由硅插入器上的記錄道連接的FPGA SLR(不按比例)。
TSV與可控折疊芯片連接(C4)焊點相結合,使Xilinx能夠使用倒裝芯片組裝技術將FPGA/插入器堆棧安裝在高性能封裝基板上(見圖1)。粗間距TSV提供了封裝和FPGA之間的連接,用于并行和串行I/O、電源/接地、時鐘、配置信號等。
這項SSI技術包括許多正在申請專利,通過10000多個設備規模的連接,提供每秒數TB的芯片間帶寬,足以滿足最復雜的多模設計。Xilinx正在使用這項新技術來支持Virtex-7 fpga家族的幾個成員。
異種模具的SSI技術除了在硅插入器上集成同質單反外,SSI技術還可以集成不同類型的芯片。在圖6中,Virtex-7 H870T FPGA通過硅插入器將三個SLR以及單獨的28G收發電路連接在一起。由于SLR和28Gb/s收發器電路代表不同的硅工藝和功能,Virtex-7HT FPGA是世界上第一個異構體系結構,它是由異構芯片并排放置組成的FPGA,可以作為一個集成設備運行。
將數字FPGA與收發器物理分離的關鍵好處之一是噪聲隔離。這確保了盡可能低的抖動和噪聲,以簡化設計關閉和降低電路板成本。
將28G收發器與SLR分離是異構體系結構如何為特定應用實現最佳結果的一個示例。因為收發器是復雜的模擬電路,在單片設備上實現它們需要更復雜的設計方法。作為一個單獨的片,28G電路是為最大可能的容量和最佳可能的性能和功率,而不損害數字邏輯的功能。
異構體系結構的另一個好處是能夠為傳統的FPGA資源提供不同比率的收發器。Virtex-7 HT FPGA具有多達16個28G收發器,實現了前所未有的集成,處于高帶寬設計的前沿。
Virtex-7系列表1所示的支持SSI的設備提供了前所未有的FPGA功能。這些設備提供多達:2000000個邏輯單元;68 Mb塊RAM;5335gmacs的DSP性能;1200個SelectIO引腳,支持1.6Gb/s LVDS并行接口;2784Gb/s聚合雙向帶寬。
表1:Virtex-7 FPGA
FPGAsPart Numbers
Virtex-7 TXC7V585T、XC7V2000T
Virtex-7 XTXC7VX330T、XC7VX415T、XC7VX485T、XC7VX550T、XC7VX690T、XC7VX1140T
Virtex-7 HTXC7VH580T、XC7VH870T
基于SSI技術的FPGA設計利用SSI技術,設計人員創建和管理單個設計項目。這是一個非常重要的優勢,因為跨多個FPGA劃分大型設計會帶來許多復雜的設計挑戰,這些挑戰不適用于單片實現。
單片FPGA設計流程中的典型步驟包括:
?創建高級描述
?綜合成與硬件資源匹配的RTL描述
?執行物理位置和路線
?估計時間并調整時間結束的設計
?生成bit流以編程FPGA
當使用多個FPGA時,設計人員(或設計團隊)必須在整個FPGA中劃分網絡表。使用多個網表意味著打開和管理多個項目,每個項目都有自己的設計文件、IP庫、約束文件、打包信息等。
多個FPGA設計的時序關閉也可能是非常具有挑戰性的。
計算和調整通過板到其他FPGA的傳播延遲帶來了新的復雜問題。同樣地,在多個FPGA中通過多個部分網表調試設計可能是極其復雜和困難的。
相比之下,SSI技術路由對用戶是透明的。用戶使用一個標準的合成和定時閉包流執行單個設計的啟動和調試。為了加速集成和實現這種容量的設備(超過200萬個邏輯單元),Xilinx引入了Vivado 設計套件-一個開發環境,旨在支持當前和未來的高容量設備。
應用采用SSI技術的Xilinx-Virtex-7型FPGA突破了單片FPGA的局限性,在一些最苛刻的應用中擴展了其價值。例如,Virtex-7系列是下一代電信和網絡系統的理想選擇,在下一代電信和網絡系統中,數十個串行收發器被用來實現靈活的,
單個FPGA解決方案。這些設備也非常適合在ASIC原型中使用,可以作為預生產和/或初始生產ASIC的替代品。Virtex-7系列還為科學、石油和天然氣、金融、航空航天和國防以及生命科學應用提供靈活、可擴展、定制的高性能計算解決方案。
FPGA架構中固有的并行性非常適合于高吞吐量處理和軟件加速。對多種高速并行和串行連接標準的支持使計算和通信系統得以融合。在航空航天和國防領域,采用SSI技術的FPGA提供的高收發信機數量和數千個DSP處理元件使先進的雷達實現成為可能。
SSI技術-從概念到現實Xilinx在創建SSI技術時采用的開發策略始于廣泛的建模和隨后創建的一系列測試設備或測試車輛,用于設計支持、可制造性和可靠性驗證。
這些測試車輛和應力模擬模型顯示了疊層硅技術的另一個優勢。與單片解決方案相比,硅插入器起到了緩沖作用,降低了低K介電應力,提高了C4凸點可靠性。
對芯片堆熱影響的大量模擬和研究表明,采用SSI技術的器件的熱性能與單片器件相當。
經過近六年的廣泛研究和開發,Xilinx于2011年9月推出了世界上容量最高的FPGA,Virtex-7 2000T器件,該器件采用SSI技術。2012年5月,Xilinx發布了世界上第一款異構設備Virtex-7 H580T,該設備采用28G收發器,針對Nx100G有線通信應用(見Xilinx新聞稿:http://press.xilinx.com/phoenix.zhtml?c=212763&p=RssLanding&cat=news&id=17 00586)。
跨SLR處理跨SLR的長線數量是有限的,需要從一個SLR的特殊的地方有入口,需要先打拍從邏輯的FF在SLR內部走線到SLR的入口附近的FF,然后過這個長線到接收FF,然后再走線到真實的接收邏輯(群內大佬指點)。
所以跨SLR處理需要一個專門的寄存器打拍,每個SLR之間有一個專門用來跨die用的寄存器。
總結作為唯一一家將SSI技術應用于超大容量和收發帶寬FPGA的FPGA制造商,Xilinx在系統級集成領域取得了重大突破。SSI技術使Xilinx能夠提供最高的邏輯密度、帶寬和片上資源,并在每個進程節點以最快的速度實現批量生產。
使用SSI技術實現的FPGA進行設計要比另一種設計簡單得多。靈活的工具流支持設計閉包自動化,同時允許用戶交互以實現更高的性能。
Xilinx目前正在運送世界上容量最高的FPGA-Virtex-7 2000T設備,以及世界上第一個異構FPGA-Virtex-7 H580T,兩者均采用SSI技術。有關更多信息,請訪問www.xilinx.com/virtex7。
參考資料https://www.xilinx.com/products/silicon-devices/3dic.html
https://www.xilinx.com/publications/white-papers/3d-ic-in-3d-fpgas.pdf
對于IC工藝上一些概念深入不多,如有問題,歡迎指正。
編輯:jq
-
FPGA
+關注
關注
1626文章
21671瀏覽量
601900 -
收發器
+關注
關注
10文章
3399瀏覽量
105865 -
SSI
+關注
關注
0文章
38瀏覽量
19212
原文標題:【科普】Xilinx 3D IC技術簡介
文章出處:【微信號:gh_339470469b7d,微信公眾號:FPGA與數據通信】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
5G五年:從概念到現實,5G-A套餐引領新變革
數字化TPM:從概念到實踐的飛躍之旅
數字化PMC:從概念到實踐的飛躍
愛立信推動自智網絡從概念到落地
虛擬現實技術和增強現實技術區別與聯系
增強現實技術(AR)和虛擬現實技術(VR)的區別?
濾波器的作用與分類詳解:從基本概念到實際應用!

英飛凌推出全新SSI系列固態隔離器
高性能計算的原理與實踐:從基本概念到架構解析

EMC技術:基礎概念到應用的解讀?|深圳比創達電子.

SOLIDWORKS 2024:簡化和加快從概念到制造的產品開發流程





 工商網監
工商網監
評論