 應用于任意預訓練模型的prompt learning模型—LM-BFF
應用于任意預訓練模型的prompt learning模型—LM-BFF
最近又出了個比較吸引人眼球的Prompt Learning,甚至該方法還被稱之為NLP的“第四范式”,具體有哪幾項請參考以下鏈接:
綜述文章:https://arxiv.org/pdf/2107.13586.pdf
相關資源:http://pretrain.nlpedia.ai
Part1什么是Prompt Learning
從BERT誕生開始,使用下游任務數據微調預訓練語言模型 (LM)已成為 NLP 領域的通用做法。直到GPT-3模型首先將自然語言的提示信息(prompt)和任務示例(demonstration)作為上下文輸入給GPT-3,使得GPT-3只需要少數的幾個樣本,不需要訓練底層的參數便能夠處理任務。應該是受到這一做法的啟發,目前很多研究聚焦在Prompt Learning上,只為了更好的激發語言模型的潛能。
在了解Prompt Learning之前,首先我們要知道什么是prompt。prompt是提示的意思,也就是說需要提示模型我們想讓它干什么。通常在GPT-3中,我們輸入一段描述,再加上“翻譯”或者“問答”的prompt,那么GPT-3會生成相應的結果。
最近該玩法在NLU中也得到了應用,比如情感分類任務,給定一句話“I missed the bus today.”,在其之后添加一個prompt:“I felt so __”,之后讓語言模型用一個情感類的詞進行完型填空,再將填空的詞語映射到標簽,這樣一來就能夠解決分類任務了。
大家發現沒有,這樣一來減少了訓練和測試階段之間的gap,因為我們在預訓練的時候使用的MLM任務就是一個完型填空任務,通常使用分類任務fine-tuning模型的時候需要加一個hidden_size * label_size的FFN,還得專門去訓練這個FFN的參數。但是如果使用Prompt Learning的方式,就省略了這一步了。這樣一來豈不是不用花大力氣訓練模型了?哈哈是的,很多研究證明Prompt Learning在小樣本(few-shot)場景下很有效。
Part2Few-shot Learner
論文標題:Making Pre-trained Language Models Better Few-shot Learners
論文來源:ACL2021
論文鏈接:https://arxiv.org/pdf/2012.15723.pdf
論文代碼:https://github.com/princeton-nlp/LM-BFF
本文主要有兩個貢獻點:
(1)基于提示(prompt)進行微調,關鍵是如何自動化生成提示模板;
(2)將樣本示例以上下文的形式添加到每個輸入中,關鍵是如何對示例進行采樣;
1prompt-based fine-tuning
之前說過GPT-3模型基于prompt生成文本。受到該啟發本文提出了一種可以應用于任意預訓練模型的prompt learning模型——LM-BFF(小樣本微調預訓練模型)。
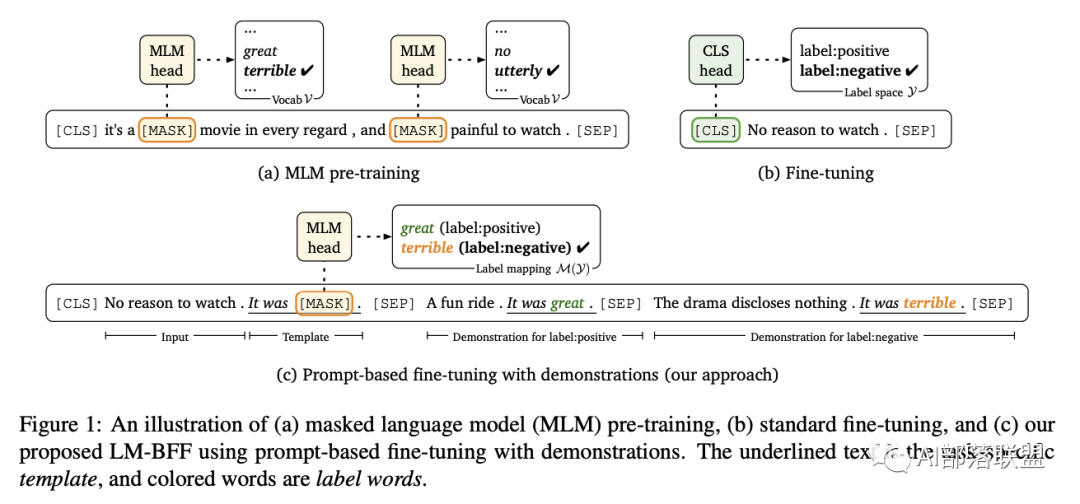
從上圖可以看出在預訓練的時候使用的MLM任務就是一個完型填空任務,在分類任務中微調的時候需要加一個hidden_size * label_size的FFN,微調的過程需要訓練這個FFN的參數。在使用Prompt Learning的方式的時候省略了這一步。這樣一來就不用花大力氣訓練模型了,而且該方法減少了訓練和測試階段之間的gap,在小樣本(few-shot)場景下很有效。
在具體的實驗過程中,作者發現使用不同的模板或不同的標簽詞進行微調得到的效果是不同的,如下圖所示:
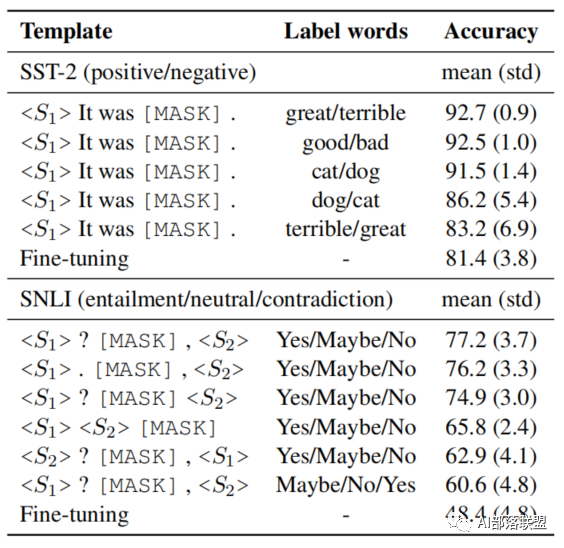
比如對于同一個標簽詞,如果使用的prompt的模板不同(替換了某個單詞或者刪除某一個標點符號),得到的結果會有較大的波動;而且當選擇不同的標簽詞時,對預測的結果也會產生影響。這是由于人工設計模板和標簽詞時候和模型本身具有的gap帶來的缺陷。因此作者提出一種自動創建模板的方法。
2Automatic Prompt Generation
Prompt的自動生成又分為了兩個部分(label的生成和模板的生成):
Label Generation
這個部分主要分成3步:
(1)首先在訓練集中,針對未經過微調的語言模型,對于每個label都找到使其條件概率最大Topk個單詞;
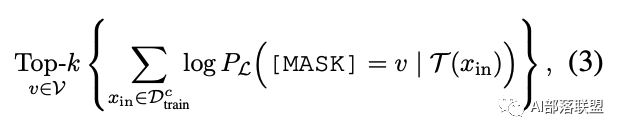
(2)綜合每個類別下的候選標簽詞,然后找出使得訓練集正確率最大的top-n個分配方式;
(3)使用dev集對模型進行微調,從n個分配方式中選擇最佳的一個標簽詞,構建標簽映射關系M。
Prompt Generation
模板的生成則是使用的T5模型,固定標簽詞,生成固定模板。
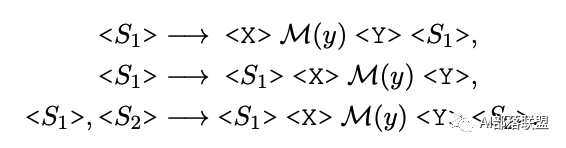
整體過程如下所示:
Fine-tuning with Demonstration
在GPT-3中,微調的時候從訓練集中隨機抽取32個示例,以上下文的形式添加到每個輸入中;
這種方式的缺陷在于:樣本示例的數量會受到模型最大輸入長度的限制;不同類型的大量隨機示例混雜在一起,會產生很長的上下文,不利于模型學習。
LM-BFF采用2種簡單的方式進行了改進:
對于每個輸入,從每個類別中隨機采樣一個樣本示例,最終將所有類別下的采樣示例進行拼接輸入;
對于每個輸入,在每個類別中,通過與Sentence-BERT進行相似度計算、并從排序得分的top50%中隨機選擇一個樣本示例。
Results
本文提出了一種簡單而又有效的小樣本微調方法——LM-BFF。主要包括2部分:
采用提示自動構建方式來進行「基于模板的微調方法」。
動態選擇樣本示例,作為輸入的上下文。但LM-BFF也有以下缺陷:
LM-BFF仍落后基于全量標注數據的標準微調方法(PS:廢話,數據目前還是越多好~)
LM-BFF自動構建提示的方法雖然有效,但擴展搜索空間在現實應用中仍是一個巨大挑戰;
LM-BFF僅支持幾種特定的任務:1)能自然轉化為「空白填空」問題,如結構化預測的NER任務可能就不適合;2)句子輸入不要太長;3)不要包含過多的類別;其中2)和3)可以在長距離語言模型中進行改善。
編輯:jq
-
GPT
+關注
關注
0文章
351瀏覽量
15315 -
nlp
+關注
關注
1文章
487瀏覽量
22011
原文標題:Prompt Learning-使用模板激發語言模型潛能
文章出處:【微信號:NLP_lover,微信公眾號:自然語言處理愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

如何訓練自己的LLM模型
直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論