 如何利用Prometheus+InfluxDB+Grafana打造高逼格監控平臺
如何利用Prometheus+InfluxDB+Grafana打造高逼格監控平臺
在本模塊中,我將把幾個常用的監控部分給梳理一下。前面我們提到過,在性能監控圖譜中,有操作系統、應用服務器、中間件、隊列、緩存、數據庫、網絡、前端、負載均衡、Web 服務器、存儲、代碼等很多需要監控的點。
顯然這些監控點不能在一個專欄中全部覆蓋并一一細化,我只能找最常用的幾個,做些邏輯思路的說明,同時也把具體的實現描述出來。如果你遇到了其他的組件,也需要一一實現這些監控。
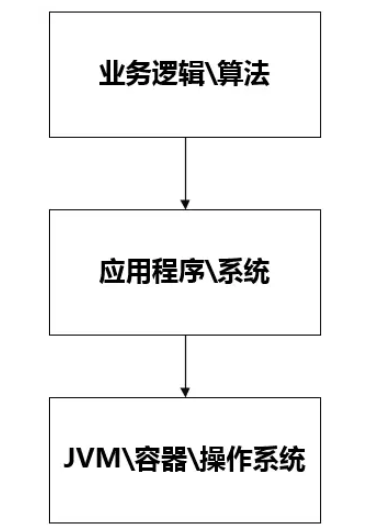
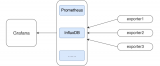
在本篇中,主要想說明白下圖的這個監控邏輯。
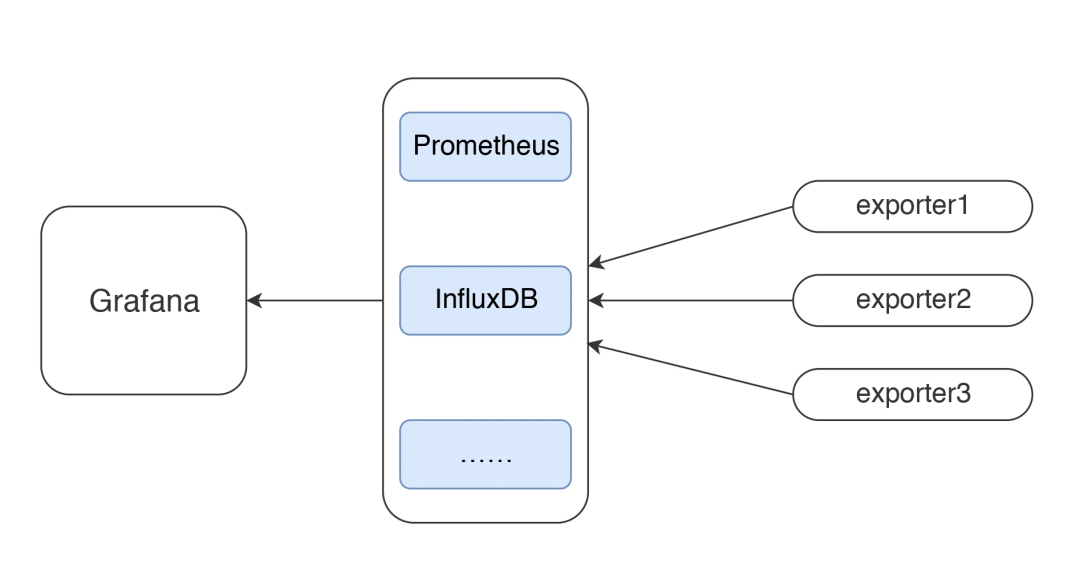
這應該是現在最流行的一套監控邏輯了吧。我今天把常見的使用 Grafana、Prometheus、InfluxDB、Exporters 的數據展示方式說一下,如果你剛進入性能測試領域,也能有一個感性的認識。
有測試工具,有監控工具,才能做后續的性能分析和瓶頸定位,所以有必要把這些工具的邏輯跟你擺一擺。
所有做性能的人都應該知道一點,不管數據以什么樣的形式展示,最要緊的還是看數據的來源和含義,以便做出正確的判斷。
我先說明一下 JMeter 和 node_exporter 到 Grafana 的數據展示邏輯。至于其他的 Exporter,我就不再解釋這個邏輯了,只說監控分析的部分。
JMeter+InfluxDB+Grafana 的數據展示邏輯
一般情況下,我們用 JMeter 做壓力測試時,都是使用 JMeter 的控制臺來查看結果。如下圖所示:
或者裝個插件來看結果:
或者用 JMeter 來生成 HTML:
這樣看都沒有問題,我們在前面也強調過,對于壓力工具來說,我們最多只關心三條曲線的數據:TPS(T 由測試目標定義)、響應時間、錯誤率。這里的錯誤率還只是輔助排查問題的曲線,沒有問題時,只看 TPS 和響應時間即可。
不過采取以上三種方式有幾個方面的問題。
整理結果時比較浪費時間。
在 GUI 用插件看曲線,做高并發時并不現實。
在場景運行時間比較長的時候,采用生成 HTML 的方式,會出現消耗內存過大的情況,而實際上,在生成的結果圖中,有很多生成的圖我們并不是那么關注。
生成的結果保存之后再查看比較麻煩,還要一個個去找。
那么如何解決這幾個問題呢?
用 JMeter 的 Backend Listener 幫我們實時發送數據到 InfluxDB 或 Graphite 可以解決這樣的問題。
Graphite Backend Listener 的支持是在 JMeter 2.13 版本,InfluxdDB Backend Listener 的支持是在 JMeter 3.3 的版本,它們都是用異步的方式把數據發送出來,以便查看。
其實有這個 JMeter 發送給 InfluxDB 的數據之后,我們不需要看上面的那些 HTML 數據,也可以直觀地看到系統性能的性能趨勢。
并且這樣保存下來的數據,在測試結束后想再次查看也比較方便比對。
JMeter+InfluxDB+Grafana 的結構如下:
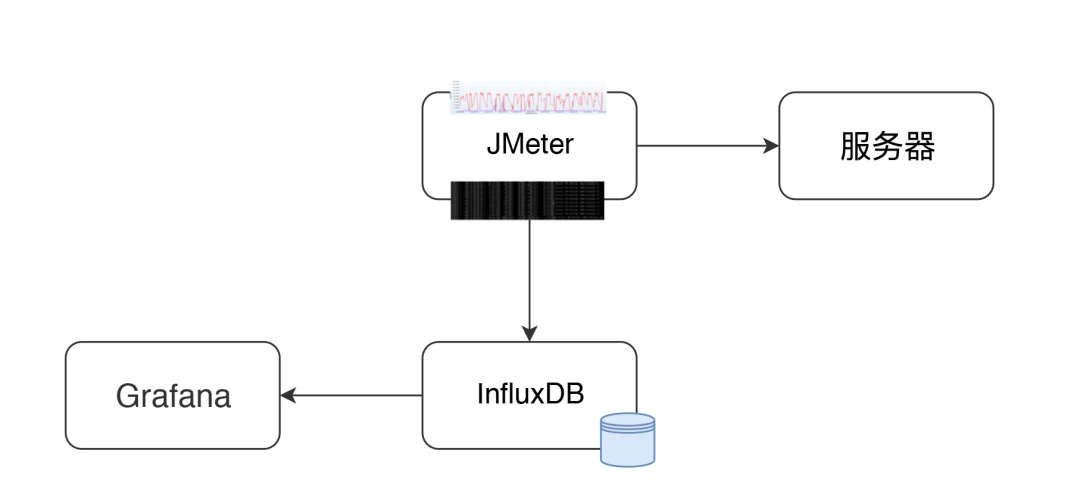
在這個結構中,JMeter 發送壓力到服務器的同時,統計下 TPS、響應時間、線程數、錯誤率等信息。默認每 30 秒在控制臺輸出一次結果(在 jmeter.properties 中有一個參數 #summariser.interval=30 可以控制)。
配置了 Backend Listener 之后,將統計出的結果異步發送到 InfluxDB 中。最后在 Grafana 中配置 InfluxDB 數據源和 JMeter 顯示模板。
然后就可以實時查看 JMeter 的測試結果了,這里看到的數據和控制臺的數據是一樣。
但如果這么簡單就說完了,這篇文章也就沒價值了。下面我們來說一下,數據的傳輸和展示邏輯。
JMeter 中 Backend Listener 的配置
下面我們就 InfluxDB 的 Backend Listener 做個說明。它的配置比較簡單,在腳本中加上即可。
我們先配置好 influxdb Url、application 等信息,application 這個配置可以看成是場景名。
那么 JMeter 如何將數據發給 InfluxDB 呢?請看源碼中的關鍵代碼,如下所示:
private void addMetrics(String transaction, SamplerMetric metric) {
// FOR ALL STATUS
addMetric(transaction, metric.getTotal(), metric.getSentBytes(), metric.getReceivedBytes(), TAG_ALL, metric.getAllMean(), metric.getAllMinTime(),
metric.getAllMaxTime(), allPercentiles.values(), metric::getAllPercentile);
// FOR OK STATUS
addMetric(transaction, metric.getSuccesses(), null, null, TAG_OK, metric.getOkMean(), metric.getOkMinTime(),
metric.getOkMaxTime(), okPercentiles.values(), metric::getOkPercentile);
// FOR KO STATUS
addMetric(transaction, metric.getFailures(), null, null, TAG_KO, metric.getKoMean(), metric.getKoMinTime(),
metric.getKoMaxTime(), koPercentiles.values(), metric::getKoPercentile);
metric.getErrors().forEach((error, count) -》 addErrorMetric(transaction, error.getResponseCode(),
error.getResponseMessage(), count));
}
從這段代碼可以看出,站在全局統計的視角來看,這里把 JMeter 運行的統計結果,比如事務的 Total 請求、發送接收字節、平均值、最大值、最小值等,都加到 metric 中,同時也會把成功和失敗的事務信息添加到 metric 中去。
在源碼中,還有更多的添加 metric 的步驟,你有興趣的話,也可以看一下 JMeter 源碼中的InfluxdbBackendListenerClient.java。
保存了 metric 之后,再使用 InfluxdbMetricsSender 發送到 Influxdb 中去。發送關鍵代碼如下:
@Override
public void writeAndSendMetrics() {
。。。。。。。。
if (!copyMetrics.isEmpty()) {
try {
if(httpRequest == null) {
httpRequest = createRequest(url);
}
StringBuilder sb = new StringBuilder(copyMetrics.size()*35);
for (MetricTuple metric : copyMetrics) {
// Add TimeStamp in nanosecond from epoch ( default in InfluxDB )
sb.append(metric.measurement)
.append(metric.tag)
.append(“ ”) //$NON-NLS-1$
.append(metric.field)
.append(“ ”)
.append(metric.timestamp+“000000”)
.append(“
”); //$NON-NLS-1$
}
StringEntity entity = new StringEntity(sb.toString(), StandardCharsets.UTF_8);
httpRequest.setEntity(entity);
lastRequest = httpClient.execute(httpRequest, new FutureCallback《HttpResponse》() {
@Override
public void completed(final HttpResponse response) {
int code = response.getStatusLine().getStatusCode();
/*
* HTTP response summary 2xx: If your write request received
* HTTP 204 No Content, it was a success! 4xx: InfluxDB
* could not understand the request. 5xx: The system is
* overloaded or significantly impaired.
*/
if (MetricUtils.isSuccessCode(code)) {
if(log.isDebugEnabled()) {
log.debug(“Success, number of metrics written: {}”, copyMetrics.size());
}
} else {
log.error(“Error writing metrics to influxDB Url: {}, responseCode: {}, responseBody: {}”, url, code, getBody(response));
}
}
@Override
public void failed(final Exception ex) {
log.error(“failed to send data to influxDB server : {}”, ex.getMessage());
}
@Override
public void cancelled() {
log.warn(“Request to influxDB server was cancelled”);
}
});
。。。。。。。。
}
}
}
通過 writeAndSendMetrics,就將所有保存的 metrics 都發給了 InfluxDB。
InfluxDB 中的存儲結構
然后我們再來看下 InfluxDB 中如何存儲:
》 show databases
name: databases
name
----
_internal
jmeter
》 use jmeter
Using database jmeter
》
》 show MEASUREMENTS
name: measurements
name
----
events
jmeter
》 select * from events where application=‘7ddemo’
name: events
time application text title
---- ----------- ---- -----
1575255462806000000 7ddemo Test Cycle1 started ApacheJMeter
1575256463820000000 7ddemo Test Cycle1 ended ApacheJMeter
。。。。。。。。。。。。。。
n》 select * from jmeter where application=‘7ddemo’ limit 10
name: jmeter
time application avg count countError endedT hit max maxAT meanAT min minAT pct90.0 pct95.0 pct99.0 rb responseCode responseMessage sb startedT statut transaction
---- ----------- --- ----- ---------- ------ --- --- ----- ------ --- ----- ------- ------- ------- -- ------------ --------------- -- -------- ------ -----------
1575255462821000000 7ddemo 0 0 0 0 0 internal
1575255467818000000 7ddemo 232.82352941176472 17 0 17 849 122 384.9999999999996 849 849 0 0 all all
1575255467824000000 7ddemo 232.82352941176472 17 849 122 384.9999999999996 849 849 0 0 all 0_openIndexPage
1575255467826000000 7ddemo 232.82352941176472 17 849 122 384.9999999999996 849 849 ok 0_openIndexPage
1575255467829000000 7ddemo 0 1 1 1 1 internal
1575255472811000000 7ddemo 205.4418604651163 26 0 26 849 122 252.6 271.4 849 0 0 all all
1575255472812000000 7ddemo 0 1 1 1 1 internal
1575255472812000000 7ddemo 205.4418604651163 26 849 122 252.6 271.4 849 ok 0_openIndexPage
1575255472812000000 7ddemo 205.4418604651163 26 849 122 252.6 271.4 849 0 0 all 0_openIndexPage
1575255477811000000 7ddemo 198.2142857142857 27 0 27 849 117 263.79999999999995 292.3500000000001 849 0 0 all all
這段代碼也就是說,在 InfluxDB 中,創建了兩個 MEASUREMENTS,分別是 events 和 jmeter。這兩個各自存了數據,我們在界面中配置的 testtile 和 eventTags 放在了 events 這個 MEASUREMENTS 中。在模板中這兩個值暫時都是不用的。
在 jmeter 這個 MEASUREMENTS 中,我們可以看到 application 和事務的統計信息,這些值和控制臺一致。在 Grafana 中顯示的時候,就是從這個表中取出的數據,根據時序做的曲線。
Grafana 中的配置
有了 JMeter 發送到 InfluxDB 中的數據,下面就來配置一下 Grafana 中的展示。首先,要配置一個 InfluxDB 數據源。如下所示:

在這里配置好 URL、Database、User、Password 之后,直接點擊保存即可。
然后添加一個 JMeter dashboard,我們常用的 dashboard 是 Grafana 官方 ID 為 5496 的模板。導入進來后,選擇好對應的數據源。
然后就看到界面了。
這時還沒有數據,我們稍后做個示例,看下 JMeter 中的數據怎么和這個界面的數據對應起來。我們先看下圖中兩個重要的數據查詢語句吧。
TPS 曲線:
SELECT last(“count”) / $send_interval FROM “$measurement_name” WHERE (“transaction” =~ /^$transaction$/ AND “statut” = ‘ok’) AND $timeFilter GROUP BY time($__interval)
上面這個就是 Total TPS 了,在這里稱為 throughput。
關于這個概念,我在第一篇中就已經有了說明,這里再次提醒,概念的使用在團隊中要有統一的認識,不要受行業內一些傳統信息的誤導。
這里取的數據來自 MEASUREMENTS 中成功狀態的所有事務。
響應時間曲線:
SELECT mean(“pct95.0”) FROM “$measurement_name” WHERE (“application” =~ /^$application$/) AND $timeFilter GROUP BY “transaction”, time($__interval) fill(null)
這里是用 95 pct 內的響應時間畫出來的曲線。
整體展示出來的效果如下:
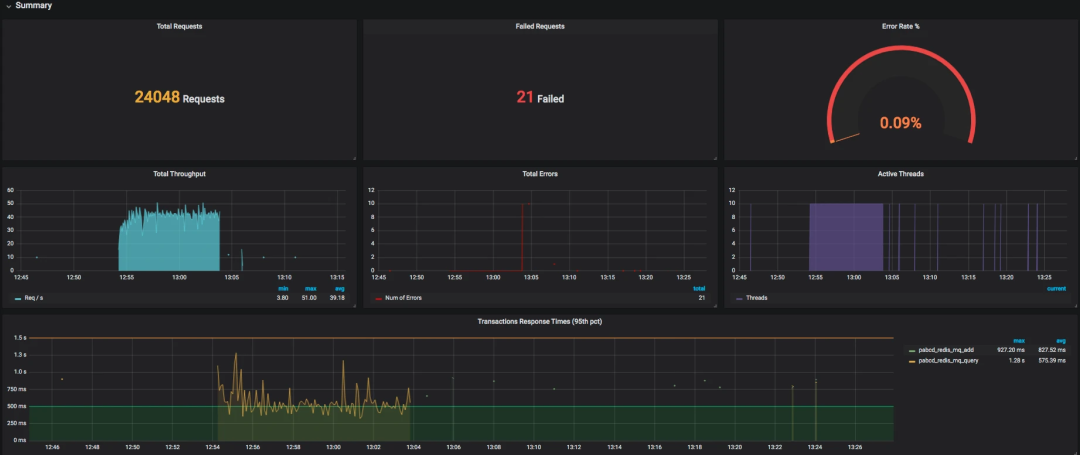
數據比對
首先,我們在 JMeter 中配置一個簡單的場景。10 個線程,每個線程迭代 10 次,以及兩個 HTTP 請求。
也就是說,這時會產生 10x10x2=200 次請求。我們用 JMeter 跑起來看一下。

看到了吧,這個請求數和我們預想的一樣。下面我們看一下 Grafana 中展示出來的結果。
還有針對每個事務的統計情況。
至此,JMeter 到 Grafana 的展示過程就完成了。以后我們就不用再保存 JMeter 的執行結果了,也不用等著 JMeter 輸出 HTML 了。
node_exporter+Prometheus+Grafana 的數據展示邏輯
對性能測試來說,在常用的 Grafana+Prometheus+Exporter 的邏輯中,第一步要看的就是操作系統資源了。所以在這一篇中,我們將以 node_exporter 為例來說明一下操作系統抽取數據的邏輯,以便知道監控數據的來源,至于數據的含義,我們將在后續的文章中繼續描述。
首先,我們還是要畫一個圖。
現在 node_exporter 可以支持很多個操作系統了。官方列表如下:
當然不是說只支持這些,你也可以擴展自己的 Exporter。
配置 node_exporter
node_exporter 目錄如下:
[root@7dgroup2 node_exporter-0.18.1.linux-amd64]# ll
total 16524
-rw-r--r-- 1 3434 3434 11357 Jun 5 00:50 LICENSE
-rwxr-xr-x 1 3434 3434 16878582 Jun 5 00:41 node_exporter
-rw-r--r-- 1 3434 3434 463 Jun 5 00:50 NOTICE
啟動:
[root@7dgroup2 node_exporter-0.18.1.linux-amd64]#./node_exporter --web.listen-address=:9200 &
是不是很簡潔?如果想看更多的功能 ,可以查看下它的幫助。
配置 Prometheus
先下載 Prometheus:
[root@7dgroup2 data]# wget -c https://github.com/prometheus/prometheus/releases/download/v2.14.0/prometheus-2.14.0.linux-amd64.tar.gz
。。。。。。。。。。
100%[=============================================================================================》] 58,625,125 465KB/s in 6m 4s
2019-11-29 15:40:16 (157 KB/s) - ‘prometheus-2.14.0.linux-amd64.tar.gz’ saved [58625125/58625125]
[root@7dgroup2 data]
解壓之后,我們可以看到目錄結構如下:
[root@7dgroup2 prometheus-2.11.1.linux-amd64]# ll
total 120288
drwxr-xr-x. 2 3434 3434 4096 Jul 10 23:26 console_libraries
drwxr-xr-x. 2 3434 3434 4096 Jul 10 23:26 consoles
drwxr-xr-x. 3 root root 4096 Nov 30 12:55 data
-rw-r--r--。 1 3434 3434 11357 Jul 10 23:26 LICENSE
-rw-r--r--。 1 root root 35 Aug 7 23:19 node.yml
-rw-r--r--。 1 3434 3434 2770 Jul 10 23:26 NOTICE
-rwxr-xr-x. 1 3434 3434 76328852 Jul 10 21:53 prometheus
-rw-r--r-- 1 3434 3434 1864 Sep 21 09:36 prometheus.yml
-rwxr-xr-x. 1 3434 3434 46672881 Jul 10 21:54 promtool
[root@7dgroup2 prometheus-2.11.1.linux-amd64]#
再配置一個 node_exporter 的模板,比如我這里選擇了官方模板(ID:11074),展示如下:
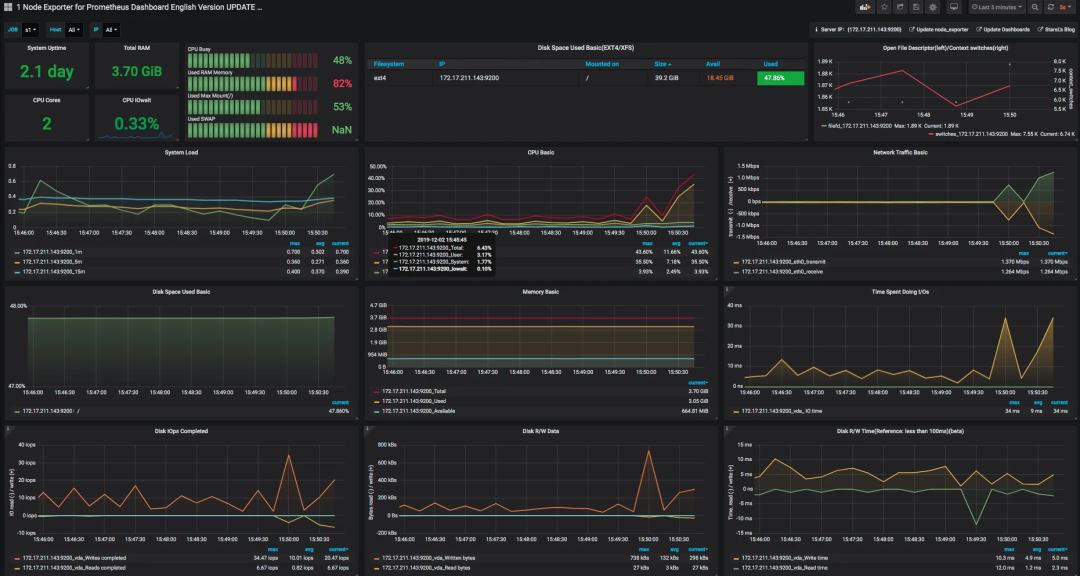
數據邏輯說明
說明完上面的過程之后,對我們做性能測試和分析的人來說,最重要的,就是要知道數據的來源和含義了。
拿上面圖中的 CPU 使用率來說吧(因為 CPU 使用率是非常重要的一個計數器,所以我們今天先拿它來開刀)。
我們先點一下 title 上的 edit,看一下它的 query 語句。
avg(irate(node_cpu_seconds_total{instance=~“$node”,mode=“system”}[30m])) by (instance)
avg(irate(node_cpu_seconds_total{instance=~“$node”,mode=“user”}[30m])) by (instance)
avg(irate(node_cpu_seconds_total{instance=~“$node”,mode=“iowait”}[30m])) by (instance)
1 - avg(irate(node_cpu_seconds_total{instance=~“$node”,mode=“idle”}[30m])) by (instance)
這些都是從 Prometheus 中取出來的數據,查詢語句讀了 Prometheus 中node_cpu_seconds_total的不同的模塊數據。
下面我們來看一下,node_exporter暴露出來的計數器。
這些值和 top 一樣,都來自于/proc/目錄。
到此,我們就了解到了操作系統中監控數據的取值邏輯了,也就是從操作系統本身的計數器中取出值來,然后傳給 Prometheus,再由 Grafana 中的 query 語句查出相應的數據,最后由 Grafana 展示在界面上。
總結
為什么要解釋數據的邏輯呢?因為最近在工作中遇到一些情況,有人覺得有了 Prometheus+Grafana+Exportor 這樣的組合工具之后,基本上都不再用手工執行什么命令了。但我們要了解的是。
對于監控平臺來說,它取的所有的數據必然是被監控者可以提供的數據,像 node_exporter 這樣小巧的監控收集器,它可以獲取的監控數據,并不是整個系統全部的性能數據,只是取到了常見的計數器而已。
這些計數器不管是用命令查看,還是用這樣炫酷的工具查看,它的值本身都不會變。所以不管是在監控平臺上看到的數據,還是在命令行中看到的數據,我們最重要的是要知道含義以及這些值的變化對性能測試和分析的下一步驟的影響。
編輯:jq
-
數據
+關注
關注
8文章
6909瀏覽量
88849 -
服務器
+關注
關注
12文章
9029瀏覽量
85205 -
計數器
+關注
關注
32文章
2254瀏覽量
94371 -
TPS
+關注
關注
0文章
83瀏覽量
36189 -
GUI
+關注
關注
3文章
650瀏覽量
39553
原文標題:Prometheus+InfluxDB+Grafana 打造高逼格監控平臺
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Prometheus的架構原理從“監控”談起
阿里云容器Kubernetes監控(二) - 使用Grafana展現Pod監控數據
最簡單的設備,也能拍攝高逼格的照片
云棲深度干貨 | 打造“云邊一體化”,時序時空數據庫TSDB技術原理深度解密
prometheus做監控服務的整個流程介紹
NodeMCU+Influxdb+Grafana主要由哪幾部分構成
簡述linux-arm64 UOS安裝開源Grafana的步驟
Prometheus、InfluxDB與Grafana打造監控平臺怎么樣
influxdb+grafana+nodemcu

使用Thanos+Prometheus+Grafana構建監控系統
SpringBoot+Prometheus+Grafana實現自定義監控
prometheus下載安裝教程
Grafana 9泰酷了吧
基于kube-prometheus的大數據平臺監控系統設計
基于Prometheus開源的完整監控解決方案






 工商網監
工商網監
評論