 Uber是怎么做到減少大數據平臺成本的
Uber是怎么做到減少大數據平臺成本的
隨著 Uber 業務的擴張,為其提供支持的基礎數據呈指數級增長,因此處理成本也越來越高。當大數據成為我們最大的運營開支之一時,我們開始了一項降低數據平臺成本的舉措,該計劃將挑戰分為三部分:平臺效率、供應和需求。本文將討論我們為提高數據平臺效率和降低成本所做的努力。
大數據文件格式的優化
我們大部分 Apache Hadoop 文件系統 (HDFS) 空間都被 Apache Hive 表占用。這些表以 Apache Parquet 文件格式或 Apache ORC 文件格式存儲。盡管我們計劃在未來的某個時候整合到 Parquet,但由于許多特定要求,包括場景的兼容性和性能,我們還未能實現這一目標。
Parquet 和 ORC 文件格式都是基于塊的列格式(block-based columnar formats),這意味著文件包含許多塊,每個塊包含大量的行(假設為 10,000),這些行數據是拆分成列的數據存儲的。
我們花了很多時間研究 HDFS 上的文件,并決定進行以下優化,主要集中在 Parquet 格式:
? 列刪除:我們的許多 Hive 表,尤其是從 Apache Kafka 日志中提取的表,都包含許多列,其中一些是嵌套的。當我們查看這些列時,發現其中一些列沒有必要長期保留。這些例子包括調試每個 Kafka 消息的元數據以及由于合規性原因需要在一段時間后刪除的任何字段。對于列格式文件來說,在技術上可以刪除文件內的列,而無需解壓和重新壓縮其他列。這使得列刪除成為一種非常節省 CPU 的操作。我們在 Uber 實現了這樣一個功能,在我們的 Hive 表上廣泛使用它,并將代碼貢獻回 Apache Parquet,具體可以參見 #755。
? 壓縮算法:默認情況下,我們使用 GZIP Level 6 作為 Parquet 內部的壓縮算法。最近社區關于 Parquet 支持 Facebook 的 ZSTD 壓縮算法的 ISSUE 引起了我們的注意。在我們的實驗中,與基于 GZIP 的 Parquet 文件相比,ZSTD Level 9 和 Level 19 能夠將我們的 Parquet 文件大小分別減少 8% 和 12%。此外,ZSTD 9 級和 19 級的解壓速度都比 GZIP 6 級快。我們決定在 1 個月后采用 ZSTD 9 級重新壓縮我們的數據,并在 3 個月后采用 ZSTD 級 19 級進行壓縮。這是因為在我們的實驗中,ZSTD 9 級壓縮比 19 級快 3 倍。請注意,重新壓縮作業是后臺維護作業,可以使用無保證的計算資源運行。鑒于此類資源的豐富性,我們基本上可以將這些再壓縮作業視為無開銷的。
?重新排序行數據:行順序可以顯著影響 Parquet 文件的壓縮大小。這是由于 Parquet 格式使用 Run-Length Encoding 功能,以及壓縮算法利用局部重復的能力。我們檢查了 Uber 最大的那些 Hive 表,并手動執行了排序,這使表大小減少了 50% 以上。我們發現的一個常見模式是簡單地按用戶 ID 對行進行排序,然后是日志表的時間戳。大多數日志表都有用戶 ID 和時間戳這些列。這使我們能夠非常好地壓縮與用戶 ID 關聯的許多非規范化列。
?Delta 編碼(Delta Encoding):一旦我們開始按時間戳對行進行排序,我們很快注意到 Delta 編碼可以幫助進一步減少數據大小,因為與時間戳值本身相比,相鄰時間戳之間的差異非常小。在某些情況下,日志具有穩定的節奏,就像心跳一樣,因此差異是恒定的。但是,我們廣泛使用的 Apache Hive、Presto 和 Apache Spark 的環境中,在 Parquet 中啟用 Delta 編碼并不容易,正如 StackOverflow 這個問題中所述的。不過我們還在探索這個方向。
HDFS EC
糾刪碼(Erasure Coding)可以顯著降低 HDFS 文件的復制因子。由于潛在增加的 IOPS 工作負載,在 Uber,我們主要研究 3+2 和 6+3 方案,復制因子分別為 1.67 倍和 1.5 倍。鑒于默認的 HDFS 復制因子是 3x,我們可以將 HDD 空間需求減少近一半!
不過,擦除代碼有多種選擇:
?Apache Hadoop 3.0 HDFS Erasure Code:這是在 Apache Hadoop 3.0 中官方實現的糾刪碼。這個實現的好處是它既適用于大文件,又適用于小文件。缺點是 IO 效率不高,因為 Erasure Code 的塊非常碎片化。
?Client-side Erasure Code:這個 是 Facebook 在 HDFS-RAID 項目中首次實現的。這種方法的好處是它的 IO 效率非常高。當所有塊都可用時,讀取 IO 效率與三副本的方式基本相同。缺點是它不適用于小文件,因為每個塊都是糾刪碼計算的一個單位。
在咨詢了行業專家后,我們決定采用 Apache Hadoop 3.0 HDFS Erasure Code,因為這是社區的方向。我們仍處于 Apache Hadoop 3.0 HDFS 糾刪碼的評估階段,但我們相信這將對降低我們的 HDFS 成本產生巨大影響。
YARN 調度策略改進
在 Uber,我們使用 Apache YARN 來運行我們大部分的大數據計算工作負載(Presto 除外,Presto 是直接在專用服務器上運行)。就像許多其他公司一樣,我們從 YARN 中的標準容量調度(Capacity Scheduler)開始。Capacity Scheduler 允許我們為每個隊列配置具有 MIN 和 MAX 設置的分層隊列結構。我們創建了一個以組織為第一級的 2 級隊列結構,允許用戶根據子團隊、優先級或工作類型創建第二級隊列。
雖然容量調度為我們管理 YARN 隊列容量提供了一個良好的開端,但我們很快就開始面臨管理 YARN 集群容量的困境:
?高利用率:我們希望 YARN 集群的平均利用率(以分配的 CPU 和 Mem GB /集群的總 CPU 和 MemGB 容量衡量)盡可能高;
?滿足用戶期望:我們希望讓用戶清楚地知道他們希望從集群獲得多少資源 我們的許多用戶對 YARN 集群的資源需求有一些尖銳的但可以預測的需求。例如,一個隊列可能有一組日常作業,每個作業都在一天的特定時間開始,并在相同的時間內消耗相同數量的CPU/MemGB。
如果我們將隊列的 MIN 設置為白天的峰值使用量,那么集群利用率將非常低,因為隊列的平均資源需求遠低于 MIN。
如果我們將隊列的 MAX 設置為白天的高峰使用,那么隨著時間的推移,隊列可能會被濫用,不斷將資源接近 MAX,進而可能影響其他隊列中其他人的正常工作 。 我們如何捕捉用戶的資源需求并正確設定他們的期望?我們提出了以下想法,稱為 Dynamic MAX。Dynamic MAX 算法使用以下設置:
?設置隊列的 MIN 為隊列的平均使用率;
?將隊列的 MAX 的設置使用以下公式:Dynamic_MAX = max(MIN, MIN * 24 – Average_Usage_In_last_23_hours * 23)
Dynamic_MAX 在每小時開始時計算,并應用于該小時的隊列 MAX。
這里的 Dynamic MAX 算法背后的直覺是:
?如果隊列在過去 23 小時內根本沒有使用,我們允許隊列峰值最多達到其 MIN 的 24 倍。這通常足 以處理我們絕大多數的峰值工作負載;
?如果隊列在過去 23 小時內平均使用的資源為 MIN ,那么我們只允許隊列在下一個小時最多使用 MIN 的資源。有了這個規則,隊列在 24 小時內的平均使用量不會超過 MIN,從而避免了上面提到的濫用情況。
上面的 Dynamic MAX 算法很容易向用戶解釋:基本上他們的使用量最多可以飆升到他們隊列 MIN 的 24 倍,但是,為了集群的公平性,它們在24小時內的累計使用量不能超過 MIN 水平上的恒定使用量。
實際上,我們將 MIN 設置為隊列平均使用量的 125%,以解決高達 25% 的每日使用差異。這反過來意味著我們的 YARN 集群的平均利用率(以 CPU/MemGB 分配衡量)將在 80% 左右,這對于成本效率來說是一個相當不錯的利用率水平。
避開高峰時間
YARN 資源利用率的另一個問題是整個集群級別仍然存在定時任務。許多團隊決定在 0000 UTC 之間運行他們的 ETL 管道,因為據說那是日志準備好的時刻。這些管道可能會運行 1-2 個小時,這使得 YARN 集群在那些高峰時段非常忙碌。
我們計劃實施基于時間的速率(time-based rates),而不是向 YARN 集群添加更多機器,這會降低平均利用率并損害成本效率。基本上,當我們計算過去 23 小時的平均使用量時,我們會應用一個根據一天中的小時而不同的比例因子。例如,0-4 UTC 高峰時段的比例因子為 2 倍,其余時間為 0.8 倍。
集群聯邦
隨著 YARN 和 HDFS 集群不斷變大,我們開始注意到性能瓶頸。由于集群大小不斷增加,HDFS NameNode 和 YARN ResourceManager 都開始變慢。雖然這主要是一個可擴展性挑戰,但它也極大地影響了我們的成本效率目標。
為了解決這個問題,擺在我們面前的戰略選擇有兩個:
?A. 繼續提升單節點性能:比如我們可以使用更多 CPU vCores 和 Memory 的機器。我們還可以運行堆棧跟蹤和火焰圖來找出性能瓶頸并逐個進行優化。
?B. 集群聯邦:我們可以創建一個由許多集群組成的虛擬集群。每個底層集群的大小都適合 HDFS 和 YARN 的最佳性能。上面的虛擬集群將處理所有工作負載路由邏輯。我們選擇 B 方案的原因如下:
?世界上大多數 HDFS 和 YARN 集群都比我們在 Uber 需要的要小。如果我們運行超大規模的集群,我們很可能會遇到在較小規模的集群中不會出現的未知bugs。
?為了使 HDFS 和 YARN 能夠擴展到 Uber 的集群規模,我們可能需要更改源代碼以在性能和復雜功能之間做出不同的權衡。例如,我們發現容量調度器有一些復雜的邏輯會減慢任務分配的速度。但是,為擺脫這些而進行的代碼更改將無法合并到 Apache Hadoop 主干中,因為其他公司可能需要這些復雜的功能。
為了讓我們能夠在不分叉的情況下利用開源 Hadoop 生態系統,我們決定構建我們的聯邦集群。特別是,我們使用基于路由器的 HDFS 聯邦和 YARN 聯邦。它們都來自開源 Apache Hadoop。截至目前,我們已經建立了數十個 HDFS 集群和少數 YARN 集群。HDFS Router-based Federation 一直是我們大數據可擴展性工作的基石,它也提高了成本效率。
通用的負載均衡
在本節中,我們將討論通用的負載均衡解決方案,它適用于 HDFS 和 YARN,方法如下:
?HDFS DataNode 磁盤空間利用率平衡:每個 DataNode 可能有不同的磁盤空間利用率比率。在每個 DataNode 中,每個 HDD 可能具有不同的磁盤空間利用率。所有這些都需要平衡,以實現較高的平均磁盤空間利用率。
?YARN NodeManager 利用率平衡:在任何時間點,YARN 中的每臺機器都可以有不同級別的 CPU 和 MemGB 分配和利用率。同樣,我們需要平衡分配和利用率,以允許較高的平均利用率。
上述解決方案之間的相似性導致了廣義負載平衡(generalized load balancing)思想,它適用于我們大數據平臺內外的更多用例,例如 微服務負載均衡和主存儲負載均衡。所有這些之間的共同聯系是,目標始終是縮小 P99 與平均值之間的差距。
查詢引擎
我們在 Uber 的大數據生態系統中使用了幾個查詢引擎:Hive-on-Spark、Spark 和 Presto。這些查詢引擎與文件格式(Parquet 和 ORC)相結合,為我們的成本效率工作創建了一個有趣的權衡矩陣。包括 SparkSQL 和 Hive-on-Tez 在內的其他選項使決策變得更加復雜。
以下是我們查詢引擎提高成本效率的主要工作點:
?專注于 Parquet 文件格式:Parquet 和 ORC 文件格式共享一些共同的設計原則,如行組、列存儲、塊級和文件級統計信息。但是,它們的實現是完全獨立的,并且與我們在 Uber 使用的其他專有系統具有不同的兼容性。隨著時間的推移,我們發現 Spark 中對 Parquet 文件有更好的支持,在 Presto 中對 ORC 文件有更好的支持。鑒于對文件格式添加功能的需求不斷增長,我們必須決定一種主要的文件格式,我們選擇了 Parquet。單一的主要文件格式使我們能夠將精力集中在一個單一的代碼庫中,并隨著時間的推移積累專業知識。
?嵌套列裁剪(Nested Column Pruning):Uber 的大數據表具有驚人的高度嵌套數據。這部分是因為我們的許多上游數據集都以 JSON 格式存儲,并且我們在這些數據集上強制使用 Avro 模式。因此,對嵌套列裁剪的支持是 Uber 查詢引擎的一個關鍵特性,否則深度嵌套的數據將需要從 Parquet 文件中完全讀出,即使我們只需要嵌套結構中的單個字段 。 我們為 Spark 和 Presto 添加了嵌套列裁剪功能。這些顯著提高了我們的整體查詢性能,這些功能已經回饋了開源社區。
?常見查詢模式優化:在我們的工作負載中看到接近一千行的 SQL 查詢并不少見。雖然我們使用的查詢引擎都有一個查詢優化器,但它們并沒有專門處理 Uber 常見的查詢場景。其中一個例子是使用 SQL constructs,如“RANK() OVER PARTITION”和“WHERE rank = 1”,目的是提取另一列值處于最大值的行中某一列的值,或用數學術語來說是 “ARGMAX” 。當查詢被重寫為使用內置函數“MAX_BY”時,像 Presto 這樣的引擎可以運行得更快。
根據我們的經驗,很難預測哪個引擎最適合特定的 SQL 查詢。Hive-on-Spark 通常對于大量 shuffle 數據具有很高的可擴展性。反過來,對于涉及少量數據的查詢,Presto 通常非常快。我們正在積極關注開源大數據查詢引擎的改進,并將繼續在這些查詢引擎之間切換我們的工作負載以優化成本效率。
Apache Hudi
我們在大數據平臺中最大的成本效益之一是高效的增量處理。我們的許多事實數據集可能會延遲到達或被更改。例如,在許多情況下,乘客直到他或她準備要求下一次行程時才會對上次行程的司機進行評分。信用卡對旅行的退款有時可能需要一個月的時間來處理。
如果沒有高效的增量處理框架,我們的大數據用戶必須每天掃描許多天的舊數據,才能使他們的查詢結果保持新鮮。一種更有效的方法是每天只處理增量更改。這就是 Hudi 項目的意義所在。
我們在 2016 年啟動了 Hudi 項目,并于 2019 年將其提交給 Apache Incubator Project。Apache Hudi 現在是一個 Apache 頂級項目(Top-Level Project),我們在 HDFS 上的大部分大數據都是 Hudi 格式。這大大降低了 Uber 的計算能力需求。
下一步和挑戰
大數據和在線服務同主機托管
雖然我們決定讓大數據工作負載在在線服務不需要對應主機時使用在線服務的主機,但讓兩個工作負載在同一主機上運行會帶來許多額外的挑戰。
關于托管對性能的影響這一領域有很多研究論文。我們方法的主要區別在于,我們計劃為大數據工作負載提供非常低的優先級,以盡量減少其對在線服務的影響。
在線和分析存儲的融合
我們的很多數據集都存儲在在線存儲系統(比如 MySQL 數據庫中)和分析存儲系統(比如 Hive 表)中。此外,為了實現即時查詢速度,我們還使用了 Pinot 等存儲引擎。所有這些都導致了相同邏輯數據的許多副本,盡管以不同的格式存儲。
是否可能有一個統一的存儲系統,既能處理在線查詢,又能處理分析查詢?這將大大降低存儲成本。
Project HydroElectricity:利用維護工作來“存儲”額外的計算能力
集群中的計算能力與電力供應非常相似。它通常在供應方面是固定的,并且在需求激增或不一致的情況下會受到影響。
抽水蓄能水力發電(Pumped-Storage hydroelectricity)可以將多余的電力以水的重力勢能的形式儲存起來,然后在需求高峰時將其轉換回電力。
我們可以將相同的想法應用于計算能力嗎?我們可以!這里要介紹的關鍵思想是維護作業(maintenance jobs),它們是可以在第二天甚至一周內隨時發生的后臺任務。典型的維護工作包括 LSM 壓縮、compression、二級索引構建、數據清理、糾刪碼修復和快照維護。幾乎所有沒有嚴格 SLA 的低優先級作業都可以視為維護作業。
在我們的大多數系統中,我們沒有明確拆分維護和前臺工作。例如,我們的 Big Data Ingestion 系統寫入使用 ZSTD 壓縮的 Parquet 文件中,這會占用大量 CPU 資源并生成非常緊湊的文件。除了這樣做之外,我們還可以讓 Ingestion 編寫輕度壓縮的 Parquet 文件,這些文件占用更多磁盤空間但 CPU 更少。然后我們有一個維護作業,它會晚一點時間運行以重新壓縮文件。通過這種方式,我們可以顯著減少前臺 CPU 的需求。
維護作業可能需要非保證的計算能力才能運行。正如我們之前所描述的,我們有足夠的資源用于此目的。
Big Data Usage 的定價機制
考慮到在多租戶的大數據平臺中,我們經常處于很難滿足每個客戶的資源需求的情況下。我們如何優化有限的硬件預算的總效用?帶有高峰時間乘數的 Dynamic_MAX 是最佳選擇嗎?
事實上,我們相信還有更好的解決方案。然而,這需要我們想出一個更微妙的定價機制。我們想要考慮的例子包括每個團隊可以花在我們集群上的假錢(fake money),用戶可以用來提高他們工作優先級的積分等。
總結
在這篇博文中,我們分享了在提高 Uber 大數據平臺效率方面的努力和想法,包括文件格式改進、HDFS 糾刪碼、YARN 調度策略改進、負載均衡、查詢引擎和 Apache Hudi。這些改進帶來了顯著的成本減少。此外,我們探索了一些開放性的挑戰,例如分析和在線托管以及定價機制。然而,正如我們之前文章中概述的框架所建立的那樣,平臺效率的提升并不能保證高效的運行。控制數據的供應和需求同樣重要,我們將在下一篇文章中討論。
本文翻譯自:https://eng.uber.com/cost-efficient-big-data-platform/
責任編輯:haq
-
文件
+關注
關注
1文章
548瀏覽量
24533 -
大數據
+關注
關注
64文章
8789瀏覽量
136934 -
Uber
+關注
關注
0文章
408瀏覽量
36118
原文標題:Uber 是如何減少大數據平臺的成本
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
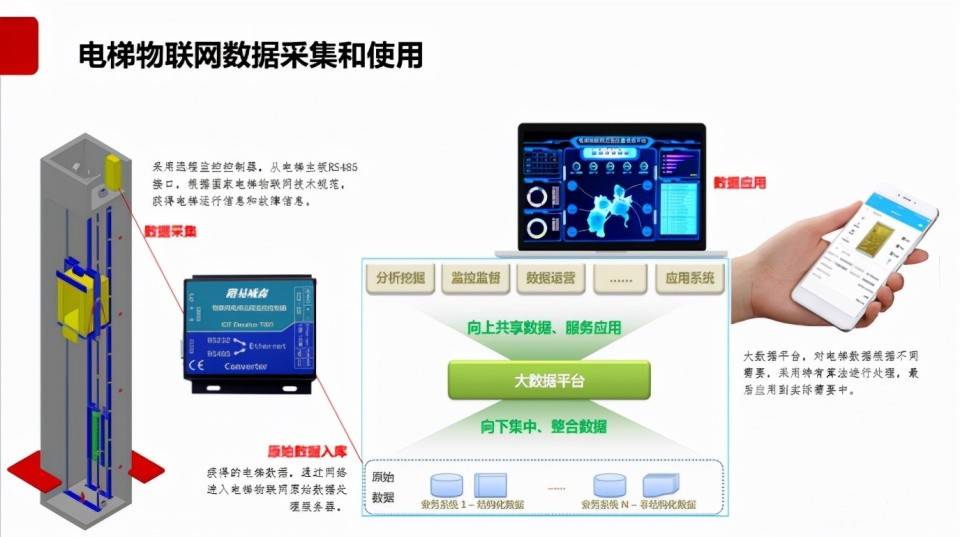
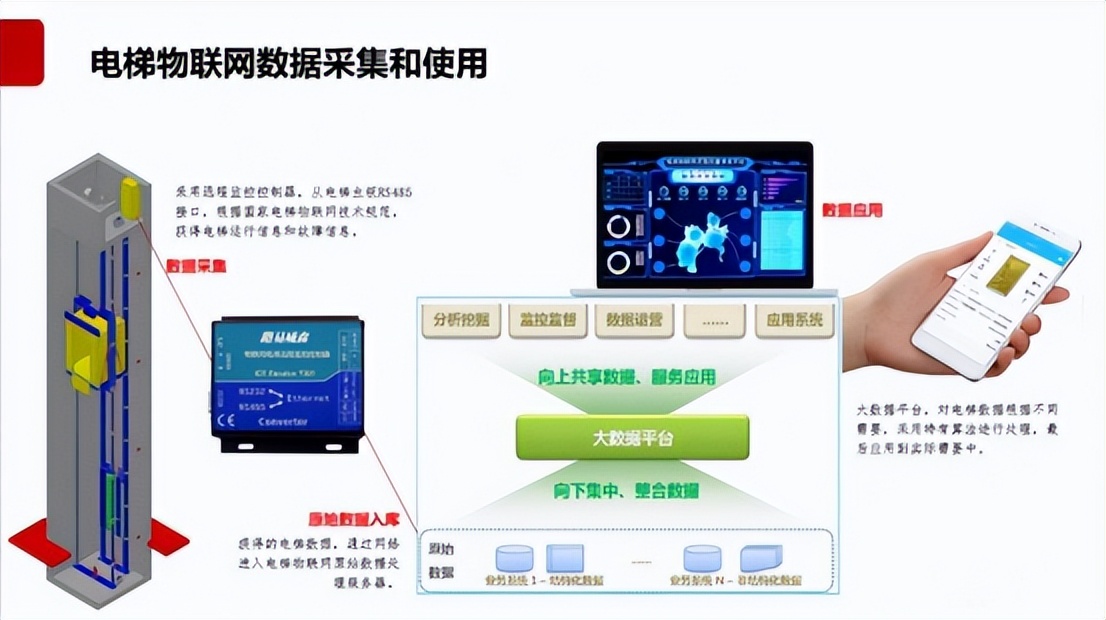
梯云物聯 智慧電梯數據先行:電梯大數據平臺構建安全生態
解鎖電梯大數據平臺的商業價值與未來展望






 工商網監
工商網監
評論