 受控文本生成模型的一般架構及故事生成任務等方面的具體應用
受控文本生成模型的一般架構及故事生成任務等方面的具體應用
來自:哈工大訊飛聯合實驗室
本期導讀:本文是對受控文本生成任務的一個簡單的介紹。首先,本文介紹了受控文本生成模型的一般架構,點明了受控文本生成模型的特點。然后,本文介紹了受控文本生成技術在故事生成任務和常識生成任務上的具體應用,指出了受控文本生成技術在具體應用場景下的改進方向。
0. 什么是受控文本生成
文本生成任務是自然語言處理領域十分重要的一類任務。文本摘要、語法糾錯、人機對話等很多自然語言處理任務都可以被視為文本生成任務。GPT-2、BART、T5等文本生成相關的技術也在這些任務上取得了較好的效果。
受控文本生成任務與常規的文本生成任務有一些不同。常規的文本生成任務對生成文本的內容(Content)通常沒有強制性的約束,而受控文本生成任務會要求生成文本的內容必須滿足一些既定的約束條件,如風格(Style)、主題(Topic)等。
例如,文本風格轉換(Text Style Transfer)就是一類十分經典的受控文本生成任務,該任務要求生成文本的內容在語義上需要與轉換前保持一致,在風格上需要轉換為預定義好的目標風格。從應用的角度來看,受控文本生成技術更有希望構建出場景適配的、用戶可接受的文本生成系統。因此,受控文本生成技術已經被越來越多的研究者關注。
1. 受控文本生成模型的一般架構
CMU的一些研究者們發表在COLING 2020的一篇論文對受控文本生成模型的一般架構(見圖1)進行了比較細致的描述。受控文本生成模型在生成受控文本時可以通過5個子模塊對生成文本進行控制。
第一個模塊稱為額外輸入模塊(External Input module),該模塊負責提供生成受控文本時的初始信號。
第二個模塊稱為序列輸入模塊(Sequential Input module),該模塊負責提供生成受控文本時每個時間步上的輸入。
第三個模塊稱為生成操作模塊(Generator Operations module),該模塊決定每個時間步向量表示的計算方式,即是使用RNN計算,還是使用Transformer計算,亦或是使用其他計算方式。
第四個模塊稱為輸出模塊(Output module),該模塊負責將每個時間步的向量表示映射為輸出結果。
第五個模塊稱為訓練目標模塊(Training Objective module),該模塊負責損失函數的計算。
其中額外輸入模塊,是受控文本生成模型中比較特殊且重要的一個模塊,該模塊通常會提供一個與控制目標相關的向量表示作為受控文本生成的初始信號,從而保證生成的文本滿足預定義的控制目標。另外,輸出模塊也是受控文本生成模型致力于改進的一個模塊。常規的文本生成任務只需要將每個時間步的向量表示映射為詞表分布作為輸出空間即可,而在受控文本生成模型中就需要通過某種方式改變輸出空間的分布去獲得期望的輸出結果。
2. 受控文本生成技術在故事生成任務上的應用
本節介紹一個發表在EMNLP 2020上的利用受控文本生成技術改進故事生成的工作。該工作使用的數據集為ROCStories dataset(該數據集中的每個故事都由5個句子組成),其任務設定為給定故事的第一個句子,機器自動生成后面的句子。
如果不使用受控文本生成技術,該任務就是一個簡單的語言模型式的文本生成任務,直接使用GPT-2就可以完成。但是,直接使用GPT-2生成的故事很難保證生成的結果是語義連貫且邏輯自洽的。因此,將受控文本生成技術引入到故事生成任務中就有可能控制故事生成的內容,從而改進故事生成的效果。
該工作首先使用一個基于GPT-2的關鍵詞預測模型預測出與下一句相關的關鍵詞,然后使用這些關鍵詞去大規模的知識庫中檢索出與這些關鍵詞相關的三元組,這些三元組會通過一些模板被轉化為句子。
由于這些由三元組轉化的句子數量較多且可能存在大量的噪音,因此,還需要一個與下一句信息相關聯的基于BERT的排序模型對這些句子進行排序,從而選擇出與下一句信息最相關的TopN個句子。在獲得這些來源于知識庫的句子后,我們就可以將這些句子作為控制信息并與當前句進行拼接一起作為GPT-2的輸入去生成下一句。上述流程需要循環進行直到生成故事中所有的句子。圖2是該工作整體的流程圖。
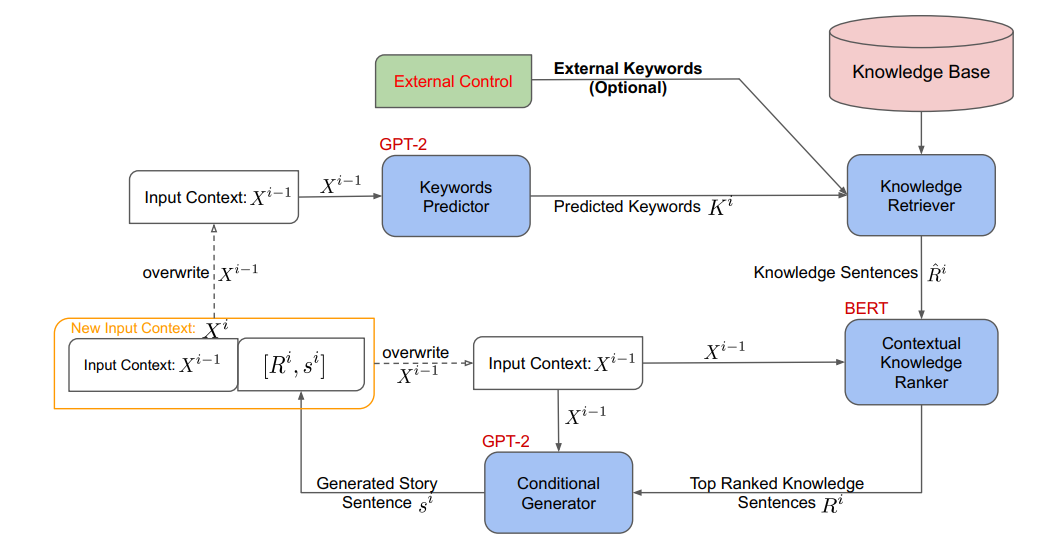
圖2 基于知識庫信息控制的故事生成流程圖
這個工作雖然沒有對受控文本生成模型進行改進,但是從大規模知識庫中獲取控制信息進行文本生成的思路還是有一定借鑒意義的。
3. 受控文本生成技術在常識生成任務上的應用
本節介紹一個發表在ACL 2021上將受控文本生成技術應用在常識生成任務上的工作。常識生成任務是一項比較新穎的文本生成任務。該任務的設定為給定一個概念集合,機器需要自動生成一個能夠描述這個概念集合的句子,并且生成的句子不能違背常識。例如,給定一個概念集合{apple, bag, put},理想情況下機器應該生成“A girl puts an apple in her bag”這樣的句子。如果機器生成了“A girl eats an apple”或者“A girl puts a bag in her apple”,都不能算是一個合格的生成結果。因此,要想獲得一個較好的生成結果,我們首先需要保證的就是概念集合里的概念都要出現在輸出結果中。
本節介紹的工作提出了一種名為“Mention Flags”的方法,通過在解碼端引入一個提及標記矩陣(Mention Flag Matrix)來標記輸入項與輸出項的提及關系,從而控制每個時間步解碼時的輸出。提及標記矩陣中的元素共有3種不同的取值,取0時表示該輸入項不是控制項,取1時表示該輸入項是控制項,但在輸出項中未出現。取2時表示該輸入項是控制項,并已經在輸出項中出現。以輸入為{apple, bag, put},輸出為“A girl puts an apple in her bag”為例。
在訓練時,提及標記矩陣可以通過輸入與輸出的對齊數據直接轉換得到。在推理時,我們只需要在每個時間步遞增式地擴充提及標記矩陣的每一列即可。
最后是如何將提及標記矩陣融入到模型中的問題。由于該工作使用的是基于Transformer的文本生成模型,其作者將提及標記矩陣視為輸入項與輸出項的相對位置(Relative Position),在計算輸出項與輸入項的交叉注意力(Cross Attention)時將相對位置信息融入到模型計算中。
4. 小結
本文簡單介紹了受控文本生成與常規文本生成任務的區別,并對受控文本生成模型的一般架構進行了闡述。受控文本生成的特殊點主要在于受控信息的獲取以及對輸出結果的控制。因此,要想獲得一個較好的受控文本生成系統,就可以從這兩點上對文本生成的模型或方案進行改進。另外,文本還介紹了受控文本生成技術在故事生成任務和常識生成任務上的應用,這些方法和思想同樣可以借鑒到其他受控文本生成任務中。
編輯:jq
-
CMU
+關注
關注
0文章
21瀏覽量
15233 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
GPT
+關注
關注
0文章
352瀏覽量
15315 -
nlp
+關注
關注
1文章
487瀏覽量
22015
原文標題:受控文本生成任務簡述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出全新生成式AI模型Fugatto
如何訓練自己的LLM模型
如何使用 Llama 3 進行文本生成
如何評估AI大模型的效果
AI大模型在自然語言處理中的應用
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
llm模型和chatGPT的區別
如何用C++創建簡單的生成式AI模型
生成式AI的基本原理和應用領域
OpenVINO?協同Semantic Kernel:優化大模型應用性能新路徑
OpenAI新年開出王炸,視頻生成模型Sora問世
高級檢索增強生成技術(RAG)全面指南





 工商網監
工商網監
評論