 eBPF技術應用云原生網絡實踐系列之基于socket的service
eBPF技術應用云原生網絡實踐系列之基于socket的service
背景介紹
Kubernetes 中的網絡功能,主要包括 POD 網絡,service 網絡和網絡策略組成。其中 POD 網絡和網絡策略,都是規定了模型,沒有提供默認實現。而 service 網絡作為 Kubernetes 的特色部分,官方版本持續演進了多種實現:
service 實現說明
userspace 代理模式kube-proxy 負責 list/watch,規則設置,用戶態轉發。
iptables 代理模式kube-proxy 負責 list/watch,規則設置。IPtables 相關內核模塊負責轉發。
IPVS 代理模式kube-proxy 負責 list/watch,規則設置。IPVS 相關內核模塊負責轉發。
在 Kubernetes 中先后出現的幾種 Service 實現中,整體都是為了提供更高的性能和擴展性。
Service 網絡,本質上是一個分布式的服務器負載均衡,通過 daemonset 方式部署的 kube-proxy,監聽 endpoint 和 service 資源,并在 node 本地生成轉發表項。目前在生產環境中主要是 iptables 和 IPVS 方式,原理如下:
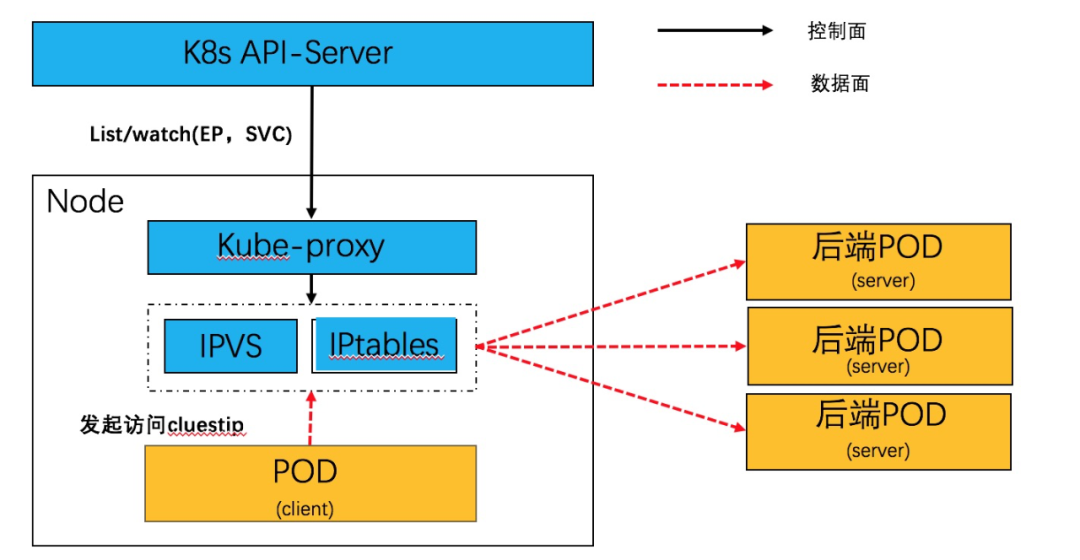
在本文中,介紹使用 socket eBPF 在 socket 層面完成負載均衡的邏輯,消除了逐報文 NAT 轉換處理,進一步提升 Service 網絡的轉發性能。
基于 socket eBPF 的數據面實現
socket eBPF 數據面簡介
無論 kube-proxy 采用 IPVS 還是 tc eBPF 服務網絡加速模式,每個從 pod 發出網絡請求都必然經過 IPVS 或者 tc eBPF,即 POD 《--》 Service 《--》 POD,隨著流量的增加必然會有性能開銷, 那么是否可以直接在連接中將 service的clusterIP 的地址直接換成對應的 pod ip。基于 Kube-proxy+IPVS 實現的 service 網絡服務,是基于逐報處理 +session 的方式來實現。
利用 socket eBPF,可以在不用直接處理報文和 NAT 轉換的前提下,實現了負載均衡邏輯。Service 網絡在同步上優化成 POD 《--》 POD,從而使Service 網絡性能基本等同于 POD 網絡。軟件結構如下:
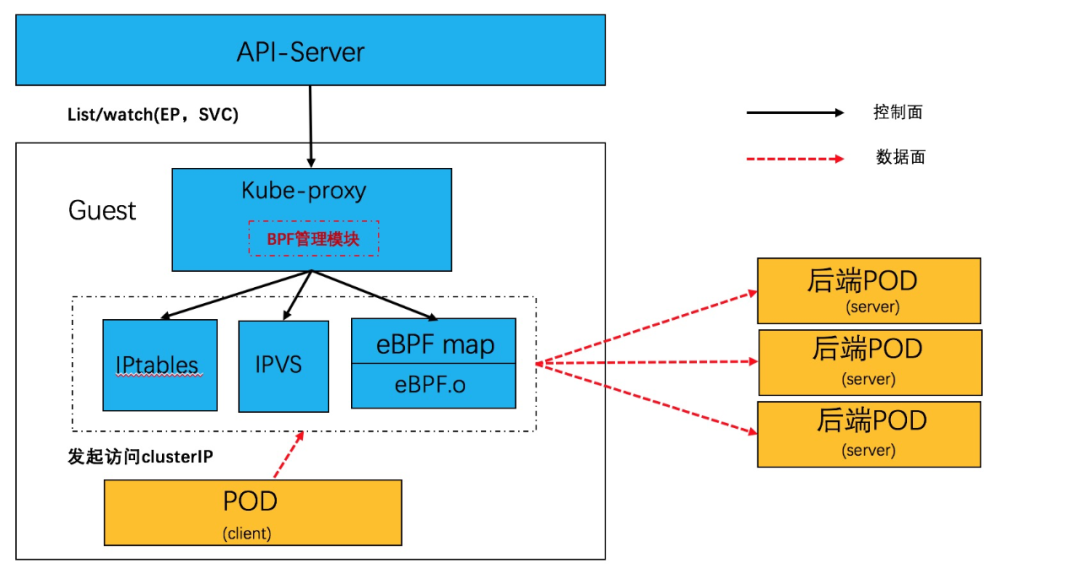
在 Linux 內核中,利用 BPF_PROG_TYPE_CGROUP_SOCK 類型的 eBPF hook 可以針對 socket 系統調用掛接 hook,插入必要的 EBPF 程序。
通過 attach 到特定的 cgroup 的文件描述符,可以控制 hook 接口的作用范圍。
利用 sock eBPF hook,我們可以在 socket 層面劫持特定的 socket 接口,來完成完成負載均衡邏輯。
POD-SVC-POD 的轉發行為轉換成 POD-POD 的轉發行為。
當前 Linux 內核中不斷完善相關的 hook,支持更多的 bpf_attach_type,部分距離如下:BPF_CGROUP_INET_SOCK_CREATEBPF_CGROUP_INET4_BINDBPF_CGROUP_INET4_CONNECTBPF_CGROUP_UDP4_SENDMSGBPF_CGROUP_UDP4_RECVMSGBPF_CGROUP_GETSOCKOPTBPF_CGROUP_INET4_GETPEERNAMEBPF_CGROUP_INET_SOCK_RELEASE
TCP 工作流程
TCP 由于是有基于連接的,所以實現非常簡明,只需要 hook connect 系統調用即可,如下所示:
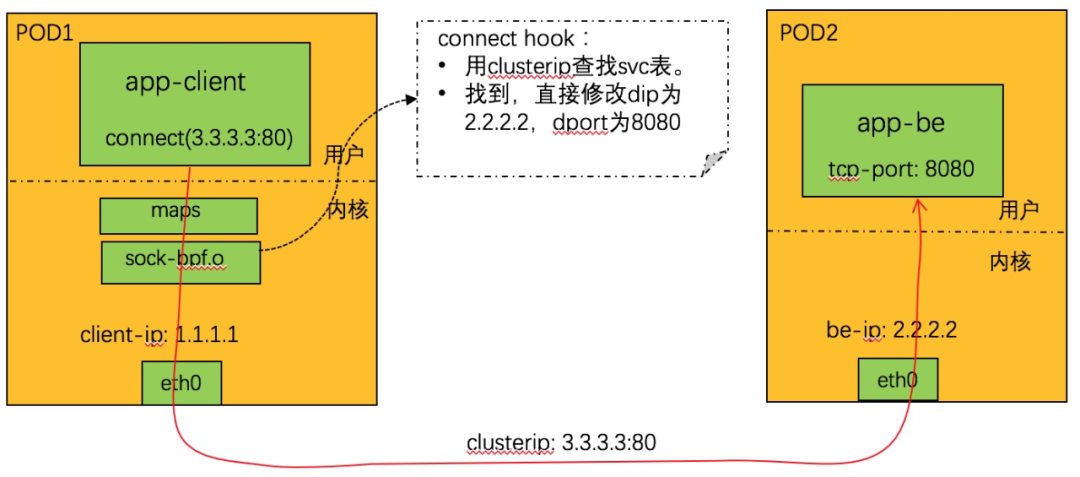
connect 系統調用劫持邏輯:
1. 從 connect 調用上下文中取 dip+dport,查找 svc 表。找不到則不處理返回。
2. 查找親和性會話,如果找到,得到 backend_id,轉 4。否則轉 3。
3. 隨機調度,分配一個 backend。
4. 根據 backend_id,查 be 表,得到 be 的 IP+ 端口。
5. 更新親和性信息。
6. 修改 connect 調用上下文中的 dip+dport 為 be 的 ip+port。
7. 完成。
在 socket 層面就完成了端口轉換,對于 TCP 的 clusterip 訪問,基本上可以等同于 POD 之間東西向的通信,將 clusterip 的開銷降到最低。
不需要逐包的 dnat 行為。
不需要逐包的查找 svc 的行為。
UDP 工作流程
UDP 由于是無連接的,實現要復雜一些,如下圖所示:
nat_sk 表的定義參見:LB4_REVERSE_NAT_SK_MAP
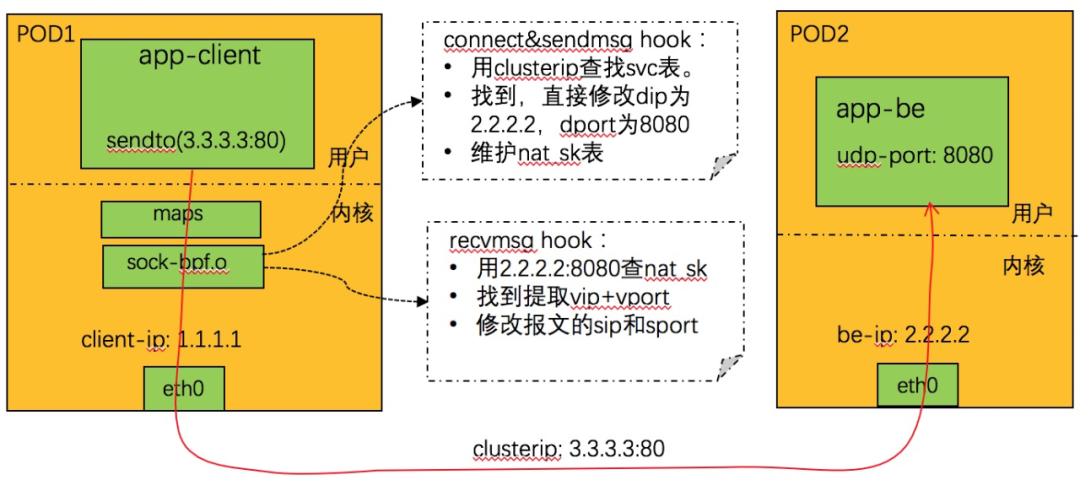
劫持 connect 和 sendmsg 系統調用:
1. 從系統調用調用上下文中取 dip+dport,查找 svc 表。找不到則不處理返回。
2. 查找親和性會話,如果找到,得到 backend_id,轉 4,否則轉 3。
3. 隨機調度,分配一個 backend。
4. 根據 backend_id,查 be 表,得到 be 的 IP+端口。
5. 更新親和性的相關表。
6. 更新 nat_sk 表,key 為 be 的 ip+port,value 為 svc的vip+vport。
7. 修改系統調用上下文中的 dip+dport 為 be 的 ip + port。
8. 完成。劫持 recvmsg 系統調用
1. 從系統調用上下文中遠端 IP+port,查找 NAT_SK 表,找不到則不處理返回。
2. 找到,取出其中的 IP+port,用來查找 svc 表,找不到,則刪除 nat_sk 對應表項,返回。
3. 使用 nat_sk 中找到的 ip+port,設置系統調用上下文中遠端的 IP+port。
4. 完成。關于地址修正問題
基于 socket eBPF 實現的 clusterIP,在上述基本轉發原理之外,還有一些特殊的細節需要考慮,其中一個需要特殊考慮就是 peer address 的問題。和 IPVS之類的實現不同,在 socket eBPF 的 clusterIP 上,client 是和直接和 backend 通信的,中間的 service 被旁路了。
此時,如果 client 上的 APP 調用 getpeername 之類的接口查詢 peer address,這個時候獲取到的地址和 connect 發起的地址是不一致的,如果 app對于 peeraddr 有判斷或者特殊用途,可能會有意外情況。
針對這種情況,我們同樣可以通過 eBPF 在 socket 層面來修正:
1、在guest kernel 上新增 bpf_attach_type,可以對 getpeername 和 getsockname 增加 hook 處理。
2、發起連接的時候,在相應的 socket hook 處理中,定義 map 記錄響應的VIP:VPort 和 RSIP:RSPort 的對用關系。
3、當 APP 要調用 getpeername/getsockname 接口的時候,利用 eBPF 程序修正返回的數據:修改上下文中的遠端的 IP+port為vip+vport。
總結
和TC-EBPF/IPVS性能對比
測試環境:4vcpu + 8G mem 的安全容器實例,單 client + 單 clusterip + 12 backend。socket BPF:基于 socket ebpf 的 service 實現。tc eBPF:基于 cls-bpf 的 service 實現,目前已經在 ack 服務中應用。IPVS-raw:去掉所有安全組規則和 veth 之類開銷,只有 IPVS 轉發邏輯的 service 實現。socket BPF 在所有性能指標上,均有不同程度提升。大量并發的短連接,基本上吞吐提升 15%,時延降低 20%。
繼續演進eBPF does to Linux what JavaScript does to HTML.-- Brendan Gregg
基于 socket eBPF 實現的 service,大大簡化了負載均衡的邏輯實現,充分體現了 eBPF 靈活、小巧的特點。eBPF 的這些特點也很契合云原生場景,目前,該技術已在阿里云展開實踐,加速了 kubernetes 服務網絡。我們會繼續探索和完善更多的 eBPF 的應用案例,比如 IPv6、network policy 等。
編輯:jq
-
數據
+關注
關注
8文章
6898瀏覽量
88836 -
Linux
+關注
關注
87文章
11230瀏覽量
208933 -
服務器
+關注
關注
12文章
9024瀏覽量
85186 -
IPv6
+關注
關注
6文章
683瀏覽量
59327 -
TCP
+關注
關注
8文章
1351瀏覽量
78989
原文標題:eBPF技術應用云原生網絡實踐系列之基于socket的service | 龍蜥技術
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
k8s微服務架構就是云原生嗎?兩者是什么關系
云原生和非云原生哪個好?六大區別詳細對比
中科馭數分析DPU在云原生網絡與智算網絡中的實際應用
京東云原生安全產品重磅發布
從積木式到裝配式云原生安全
基于DPU與SmartNic的云原生SDN解決方案
云原生轉型中從理念到實踐的探索與挑戰
eBPF動手實踐系列三:基于原生libbpf庫的eBPF編程改進方案簡析

Mavenir為捷克T-Mobile部署云原生網絡設施
米哈游大數據云原生實踐

云原生技術前沿落地實踐分論壇圓滿舉辦






 工商網監
工商網監
評論