 AI將如何重振摩爾定律的良性循環
AI將如何重振摩爾定律的良性循環
在這篇文章中,天數智芯首席技術官呂堅平(CP Lu)博士闡述了當今AI硬件淵源,跳脫過去芯片設計窠臼,以可微分GPU及可微分ISP為例,提倡以AI為本的可微分硬件理念。希望借此可重振軟硬件彼此加持的雄風,緩解甚至逆轉摩爾定律的衰退。
INNOVATIONS
人工智能將如何重振摩爾定律的良性循環
據報道,正值全球芯片短缺之際,臺積電提高了芯片價格并推遲了3nm制程的生產進程。無論這類新聞是否準確或預示著一種長期趨勢,它們都在提醒我們,摩爾定律的衰退將帶來越來越嚴重的影響,并迫使我們重新思考人工智能硬件——它會受到這種衰退的影響,還是會幫助扭轉這種趨勢?
如果我們希望恢復摩爾定律(Moore’s Law)的良性循環,這其中,軟件和硬件曾經相互加持,使一部現代智能手機比過去10年占據整個倉庫的超級計算機功能更強大。人們普遍接受后摩爾時代的良性循環是基于更大的數據迸發更大的模型并需要更強大的機器。但事實上,這樣的循環是不可持續的。
除非我們重新定義并行性,我們不能再指望縮小晶體管來制造越來越寬的并行處理器。我們也不能依賴于它,除非特定領域架構(DSA)有助于促進及適應軟件的發展。
與其搞清楚哪類硬件是用于 AI 這個不斷發展的移動目標,我們不如從AI以可微分編程為核心的角度來看待AI 硬件。這樣說,人工智能軟件程序是一個計算圖,由一起訓練實現端到端目標的計算節點組成。只要一個深度線程DSA硬件是可微的,它就可以作為一個計算節點。軟件程序員可以自由地將可微硬件插入計算圖中,以實現高性能和以創意解決問題,就像預構建的可定制軟件組件一樣。AI 硬件不應再有“血統純正度”審查,畢竟它現在可以包括各樣可微硬件。
但愿這樣,軟件和硬件將再次通過良性循環并行發展,就像摩爾定律盛行時那樣。
人工智能硬件架構師的苦惱
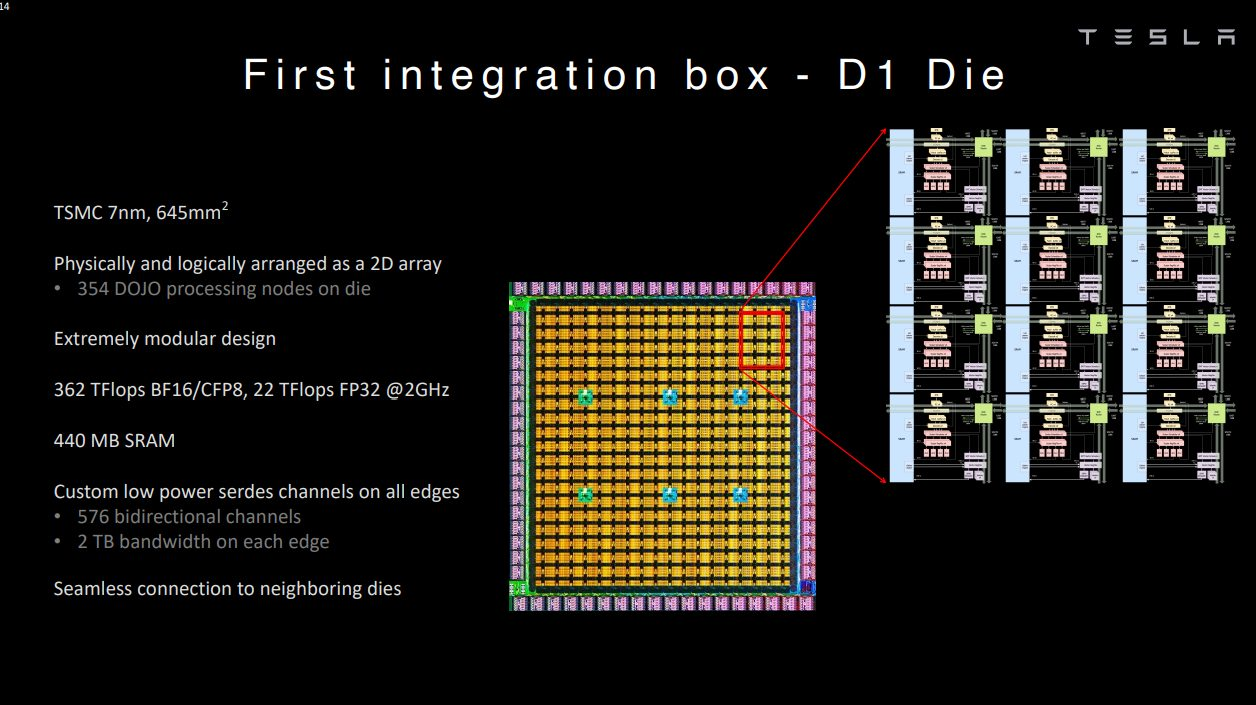
在人工智能市場的眾多GPU競爭者中,特斯拉推出了Dojo超級計算機。Dojo似乎是網絡、集成和可延展性方面的杰作。而另一方面,Dojo 的組件 D1 芯片則稱不上是架構上的突破。我們可以將GPU競爭者分為兩個陣營,Many-Core 和Many-MAC。D1是Many-Core陣營的一個例子,它是將多個CPU核心連接起來的“網格”。另一方面,特斯拉FSD或谷歌TPU是Many-MAC陣營的縮影,其特點是少量大型矩陣乘法(MM)加速器,每個都在一個“網格”中封裝許多乘累積(MAC)單元。正如我們所看到的,關于AI架構的爭論可以說是處于網格和GPU之間。
在制造芯片帶來的飛速增長的沖力下,AI硬件架構師面對著巨大壓力,總是膽戰心驚的看待媒體對基準測試和學術大會的報導。人工智能硬件常常跑不動基準測試和最新出爐的NN模型,而諷刺的是,這些模型在所謂“老掉牙”的GPU上,卻運行良好。如下圖所示,Many-Core和GPU本質上只是數據交換方式有所不同。前者通過一個互聯的網格傳遞數據,而后者通過一個存儲器層次結構共享數據。這種差異與人工智能沒有什么關系。Many-Core芯片(如D1芯片)是否最終會超過GPU,還有待觀察,稍后我將介紹Many-MAC 。
現在,讓我們快速回顧一下網格和GPU在高性能計算(HPC)中的共同根源。
HPC的傳承
HPC用于解決計算密集的如軍事研究、科學發現、油氣勘探等問題。超級計算機(簡稱超算)一直是高性能計算的關鍵硬件解決方案。與處理指針豐富的數據結構(如樹和鏈表)的通用程序相比,HPC程序主要花時間在“回圈”中重復數據并行計算。
矢量超算的興衰
在20世紀70年代和90年代,矢量超算,通過將數據并行回圈展開成矢量來加速高性能計算程序,主導了高性能計算市場。在那期間,矢量超算等同于超級計算機。
在 1990 年代,正當摩爾定律鼎盛之時,通過將許多現成的 CPU 排列在網格或某種類似的拓撲結構中來構建超級計算機變得可行。這種趨勢導致了分布式超算的出現。尚未接受分布式超算的HPC 社區抗拒地將其稱為 The Attack of the Killer Micros,其中“Micro”意味著微處理器。這種觀點源于一個芯片上的CPU在早期被稱之為微處理器,而“CPU”通常是一個由分立組件組成的系統。最終,分布式超算取代了矢量超算,成為今天超級計算機的代名詞。
矢量超算以GPGPU的身份王者再臨
在21世紀初,摩爾定律開始呈現老化,導致CPU時鐘速度競賽戛然而止。然而CPU時鐘速度曾是單晶片計算性能的主要來源。業界的回應是在一個芯片上安裝多個CPU核,期望并行性成為新的主要性能來源。這一趨勢帶來雙核、四核以及最終的多核,有效地形成了分布式超算集于一芯,將多個CPU核心排列在一個網格中。Many-Core的例子包括英特爾在市場上挑戰GPU的兩次挫敗,Larrabee在3D市場,以及Larrabee的后代Xeon Phi系列在HPC。
GPU傳統上對頂點、三角形和像素等圖形單元上展開“回圈”。GPU架構師將這種能力擴展到HPC應用中的回圈,使GPU有效地成為矢量超算集于“一芯”。然后他們將GPU在HPC中的使用命名為通用GPU (即GPGPU)。當矢量超算在HPC市場讓位給分布式超算時,它就化身為GPU來報復它的競爭對手。我們可以看到GPU在頂級超算機上的商業成功,比如橡樹嶺國家實驗室的Titan超算機和瑞士國家超算中心的Piz Daint。
簡而言之
——分布式超算機將矢量超算機從HPC市場踢出局
——Many-Core是分布式超算“集于一芯”
GPU是將高性能計算的矢量超算“集于一芯”
矩陣乘法(MM)和AI
網格,計算機架構中的“舊錘子”,如何自我升級改造視人工智能為“新釘子”?
MM和HPC
計算機體系結構中的一條永恒規則是,搬動數據比計算數據更昂貴,這就要求計算機架構在較少的數據上進行更多的計算。幸運的是, HPC社區從幾十年的實戰經驗中學到,他們可以用MM來表達大多數 HPC問題,大致說來,MM在數據上的操作具有很高的計算-通信比。如果運用得當,使用MM解決問題可以通過隱藏數據傳輸來實現高性能。因此,HPC程序員只需要超算機供應商提供的一個健全的MM程序庫。當計算MM時,今天的分布式超級計算可以充分利用分布在數十萬平方英尺上的數十萬節點,有效地令每個單個節點都忙于計算。
矩陣乘法(MM)在AI中的崛起
運用基于神經網絡(NN)的機器學習(ML)是現代人工智能的特征。神經網絡模型由多層ML核心程序組成。在卷積神經網絡(CNN)之前,最流行的神經網絡(NN)是多層感知器(MLP)。MLP的基本ML核心程序是矩陣矢量乘法(MVM),它對數據進行粗略的MAC操作,幾乎沒有數據重用。另一方面,CNN目前主要的運作元是張量卷積(Tensor Convolution, TC)。正如我在我的文章“All Tensors Secretly Wish to Be Themselves”中解釋的那樣,在數據搬動和共享方面,MM和TC在結構上是等價的,所以我們經常可以互換使用張量和矩陣。
將MM作為運作元給HPC和人工智能帶來了突破。CNN主要使用了MM,引發了計算機視覺領域人工智能的突破。Transformer也廣泛使用了MM,點燃了人工智能在自然語言理解(NLP)方面的突破。
多虧了人工智能及其對MM的大量使用,計算機體系結構社區才有了一個世紀一遇的機會,能夠聚焦在優化MM這單純的目標,而又能同時對計算產生廣泛的影響——等于是事半功倍。
Many-Core 可以運行與分布式超算相同的MM算法。從某種意義上說,從事人工智能的Many-Core 可以說是歸宗到HPC。
Many-MAC的浪潮
1982年,脈動陣列被引入加速MM和其他應用。如果當年在人工智能的背景下加速MM像今天一樣酷,那么脈動陣列的研究人員就不會為MM之外應用而費心了。脈動陣列是一種比CPU內核更密集地封裝MAC單元的機制。缺點是,我們不能在其他地方使用MM MAC單元。由于缺乏通用性,直到因為AI成為MM的殺手級應用,谷歌在TPU上采用脈動陣列作為MM加速器,脈動陣列才被市場接受。從那時起,市場上就出現了許多改進原作的版本。在這里,我將原始的脈動陣列及其變體稱為Many-MAC。為了處理非MM操作,Many-MAC增加了配套處理器。
另一方面,Many-Core 中的 CPU 核心,例如 D1 芯片或GPU 的著色器核心,可以使用更小的 Many-MAC,從而有效地成為 Many-MAC 容器。
簡而言之
—— AI和HPC因為使用大量MM而命運交匯。
—— Many-Core 和 Many-MAC基本上不比GPU更適配AI。
領域轉移和領域特定的并行性
暗硅和功耗墻
在2010年之后,業界意識雖然理論上來說,并行度加倍是計算性能的主要來源,然而擁有兩倍的CPU核心,不可能保持這種良性循環。這是因為每個 CPU 核無法將其功耗降低一半,或每瓦并行度翻倍。在幾次迭代的核加倍后,我們會看到大多數核在相同的功率預算下無法被供電,從而產生了暗硅,或者更準確地說,是暗核。如下圖的概念圖所示,當我們從 2 核變為 4 核時,4 個核中只有 3 個可以供電,而當我們從 4 核變為 8 核時,只能為 4 個核供電。最后,16 個內核中只有 4 個可以供電,因此從 8 核變為 16 核沒有任何好處。我們將這種現象稱為“功耗撞墻(hitting the Power Wall)”。
由于這個原因,相當一部分計算機架構社區成員疏遠并行化。此外,悲觀主義者傾向于將并行度低、指針豐富的計算作為主流,并將具有并行性的HPC視為一個小眾市場。他們認為,良性循環將過早止于阿姆達爾上限,也就是并行運算的極致。
人工智能的及時救援
巧合的是,在這種悲觀情緒中出現了人工智能。根據斯坦福 AI 指數報告,人工智能一直不斷進步,就好像功耗墻不存在一樣!
關鍵在于主流軟件可能會發生領域轉移,導致不同并行模式。如下面的概念圖所示,當主流軟件從多指針計算轉向數據并行計算時,它將一個并行度重新定義為單指令多數據(Single-Instruction-Multiple-Data, SIMD)的一條通道而不是一個CPU核。我們看到一條比CPU核曲線更高的曲線(標記為SIMD lanes for data-parallel)。接下來,當主流軟件進入著重于MM的AI領域時,添加了更高的曲線(標記為MM MACs for MM-heavy),一個MM MAC代表一個并行度。正如我們所看到的,通過探索更有效的領域特定并行模式和提高阿姆達爾定律的上限,計算性能在功耗墻之內繼續增長。
順帶一句,著重于MM的AI 有自己的阿姆達爾上限。AI 應用程序需要有回圈前端,將 MM 操作分配到并行計算資源,以及回圈后端收集計算結果進行串行操作(如歸一化或 softmax)的結果。當有足夠多的 MM MAC 來加速 MM 時,阿姆達爾定律就會發揮作用,從而使回圈前端和后端成為瓶頸。
此外,隨著摩爾定律的衰落越來越嚴重,制造更寬的加速MM的機器是否能維持AI的良性循環就成了問題。為了解決這個問題,進一步提高阿姆達爾的上限,我們需要轉移到更新的領域并探索新的領域特定并行性。換句話說,我們要考慮是否需要在下面的概念圖中添加一條新的曲線。
簡而言之
——通過將指針豐富的領域轉移到數據并行,進而到重于MM的計算,我們不斷在功耗墻內提升性能。
下一個領域轉移
可微分編程
英特爾的 Raja Koduri 表示,“神經網絡是新的應用程序。我們看到的是,每個插槽,[無論是] CPU、GPU 還是 IPU,都將具有矩陣加速功能。”
特斯拉的Ganesh Venkataramanan將他們的D1芯片描述為“純正”ML機器,專門運行“ML核心程序”,無需傳統硬件。或許,他在暗示GPU不像D1那樣血統純正,因為它的圖形專用硬件在AI處理過程中處于閑置狀態。
以上兩種觀點引出了兩個問題——人工智能的領域轉移應該止于加速矩陣乘法嗎? 傳統領域特定的設計是否該被排除在人工智能硬件之外?
現在,我們從AI的核心是可微編程(DP)的角度來探索AI硬件的不同觀點。AI軟件程序是一個計算圖,如下圖所示,由參數化計算節點組成,每個節點將上游節點的輸出作為輸入,并將計算輸出提供給下游節點。我們通過“訓練”決定所有計算節點的參數,訓練程序首先計算用到最終輸出的端到端損耗,然后計算該損耗的輸出梯度。沿著用于計算輸出的相反方向,它進一步使用標準的微積分鏈規則重復計算中間梯度。
DP只要求任一個計算節點是可微的,使得它可以與所有其他節點共同優化,通過梯度下降最小化端到端損失。計算節點的可微性使其能夠維持一條從下游到上游的反饋路徑,最終完成一個端到端的反饋回圈。在DP下,計算節點不一定是傳統的“ML核心程序”。計算圖可以是異構的,包括非ML軟件和硬件節點,只要它們滿足可微性要求。
一個計算節點,使用參數w 及輸入x計算輸出y, 同時計算并記住用于計算輸入梯度的輸出/輸入微分。反饋路徑將輸入梯度傳播到上游節點,如藍色虛線所示。如果有必要,它計算并記住輸出/參數微分,以計算參數梯度來調整參數。讓我們來看一些例子。
回圈中的可微分圖形硬件
越來越多的神經網絡模型具有異構計算節點,符合可微分編程的定義。很好的例子是那些解決逆向圖形問題的例子。與正向圖形(從三維場景參數生成二維圖像)不同,逆向圖形從二維圖像恢復場景參數。新興的基于人工智能的逆向圖形解決方案通常包括一個不同于傳統的可微分圖形渲染器。它將梯度逆向傳播到上游節點,參與梯度下降以最小化端到端損失。具有可微身處回圈圖形的逆圖形線程的強大功能在于使逆圖形“自我監督”化,如下圖所示。
重建神經網絡從真實圖像中獲取場景參數,可微圖形根據場景參數繪制虛擬圖像。兩個共享下游NN處理好真實世界和虛擬世界的圖像來計算它們之間的端到端損失。假設回圈中沒有可微圖形,我們必須為場景參數準備3D的基本事實。相反,真實世界的圖像有效地充當虛擬世界圖像的基本事實,使過程自我監督化。
目前的可微分渲染器,如Soft Rasterizer, DIB-R,以及那些在AI框架中使用的渲染器,如PyTorch3D, TensorFlow Graphics,都是不使用特定于圖形硬件的軟件渲染器。這種軟件實現不像典型的ML核那樣著重MM,因此不能利用MM加速。
另一方面,GPU架構師用足夠深的線程設計和提供特定于圖形的硬件,以便它們速度快,很少成為瓶頸。現在,假設我們制作了這樣一個線程“可微硬件”。軟件程序員可以在計算圖中有效地使用可微硬件,類似于使用預構建的軟件組件。由于圖形專用硬件的深層線程并行性,這種循環中的硬件圖形應該比其軟件對應物快得多。
回圈中的可微分ISP
除了使用微分硬件作為預構建的軟件組件外,我們還可以通過梯度下降調整其參數來“編程”,就像我們“訓練”ML核心程序一樣。例如,圖像信號處理器(ISP)通過鏡頭捕獲圖像,并線上對其進行處理,以生成供人類觀賞或下游圖像理解(IU)任務(如物件偵測或語義分割)使用的圖像。傳統的ISP有充足的參數空間,但需要專家對其進行調整,以滿足人類的需求。目前為止,人類專家沒有能力針對下游IU神經網絡模型,調整該參數空間。相反,ISP在特定參數設置下預捕獲和預處理的圖像被用來訓練神經網絡模型。此外,捕獲圖像的透鏡系統在制造和操作期間可能存在缺陷。如果沒有與ISP的聯合優化和設備調整,IU NN模型將無法令人滿意地執行任務。
目前已經有很多提議用 NN 模型替換某些 ISP 處理階段,這在具有特定功率和實時要求的場景中不一定實用或更好。另一方面,已經有新興研究試圖利用 ISP 的未開發的參數空間。這里有些例子:
回圈中的不可微ISP硬件,用于非ML優化的參數自動調整。
經過訓練的 NN 模型模仿 ISP的可微代理, 用 于基于ML 的參數自動調整。
上述研究表明,通過為特定 IU 任務設置端到端目標,自動調整的 ISP 優于沒有自動調整的 ISP。
第一種方法,不可微ISP不能與其他神經網絡模型聯合優化。另一方面,雖然使用可微代理的第二種方法有助于訓練,但其缺點是我們需要在仔細控制的環境中單獨訓練此代理。
現在,想象一下使ISP可微。我們可以在回圈中使用ISP組成一個自適應傳感線程,如下圖所示。它可以在具有ISP前和ISP后NN模型的設備上聯合調整自身,以適應操作環境和特定UI任務。請注意,我們不固定ISP前和ISP后NN模型,就像GPU架構師不指定圖形著色器一樣(請參閱我的文章《GPU將成為計算機體系結構黃金時代的明星》)。
結論
我們使用回圈中的圖形硬件和回圈中的ISP 的例子介紹了可微分硬件的概念。更進一步,假設我們已經在芯片上同時擁有可微分 ISP 和可微分 GPU,并且我們還需要自監督逆向圖形和自適應傳感。如下所示,我們可以通過連接回圈中的圖形硬件和回圈線程中的ISP組成一個新線程。
我們可以看到,一個可微分硬件單元在以下三個方面看,是可編程的:
1.AI程序員可以在計算圖中使用它,因相當于他們在軟件開發中使用預構建和可定制的軟件組件。
2.AI程序員可以使用用于訓練NN模型的相同ML框架自動調整此可微硬件單元的參數。
3.AI程序員可以自由選擇各種NN模型來搭配這種可微硬件單元,就像圖形編程人員可以自由編程不同類型的著色器一樣。
AI 已將主流軟件的領域轉移到著重MM的計算。軟件程序員可以將廣泛的應用程序簡化為 ML 核心程序。為了重振摩爾定律的良性循環,我們需要另一個領域轉移。與其搞清楚哪些硬件是用于 AI 這個不斷發展的移動目標,我們應該遵循 AI 的精神——可微分編程,改變我們設計和使用計算硬件的方式。不再對 AI 硬件進行“血統純度”審查,因為它可以包括可微分硬件。
如此一來,硬件有望在創新軟件中延長其生命周期,軟件可以利用硬件作為預構建和可定制的組件。希望雙方都能加持彼此進入一個新的良性循環,就像摩爾定律鼎盛時那樣。
責任編輯:haq
-
芯片
+關注
關注
453文章
50396瀏覽量
421791 -
AI
+關注
關注
87文章
30122瀏覽量
268407 -
人工智能
+關注
關注
1791文章
46853瀏覽量
237544
原文標題:人工智能將如何重振摩爾定律的良性循環
文章出處:【微信號:IluvatarCoreX,微信公眾號:天數智芯】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
擊碎摩爾定律!英偉達和AMD將一年一款新品,均提及HBM和先進封裝

AI時代的存儲墻,哪種存算方案才能打破?
高算力AI芯片主張“超越摩爾”,Chiplet與先進封裝技術迎百家爭鳴時代

“自我實現的預言”摩爾定律,如何繼續引領創新
封裝技術會成為摩爾定律的未來嗎?

電源解決方案跟摩爾定律有何關系?它如何跟上摩爾定律的步伐?

功能密度定律是否能替代摩爾定律?摩爾定律和功能密度定律比較
摩爾定律的終結:芯片產業的下一個勝者法則是什么?

墨芯人工智能CEO王維:需要重新定義和設計AI計算機
中國團隊公開“Big Chip”架構能終結摩爾定律?





 工商網監
工商網監
評論