 ntel I9的多核scalability是真的嗎
ntel I9的多核scalability是真的嗎
昨天我們用Intel I9的10核,每個核2個threads的機器跑了內核的編譯:
超線程SMT究竟可以快多少?
今天,我換一臺機器,采用AMD Ryzen。
默認情況16核,每個核2個threads,共32個CPUs:
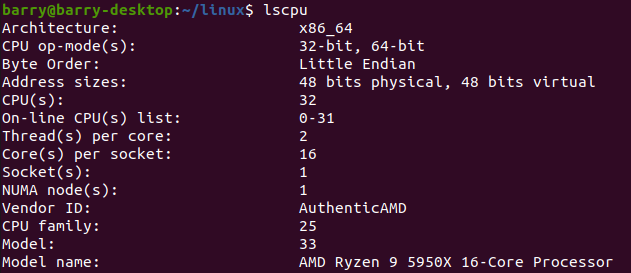
下面編譯內核:
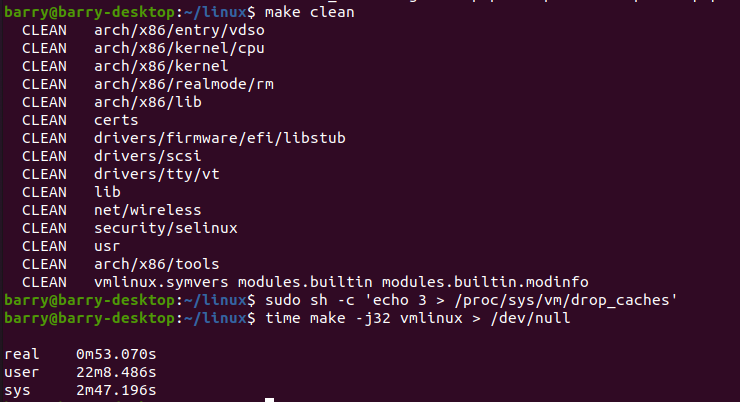
大約需要53秒。記得昨天用Intel I9 10核20線程需要2分鐘30秒左右。
再來一遍:

這說明make clean, drop_caches后時間也差不多。51秒,53秒左右的正常抖動范圍。
現在我們關閉smt,只保留16個CPU:
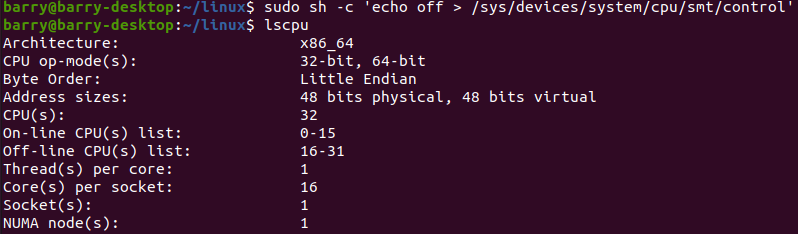
具體的關閉方法就是:
sudo sh -c ‘echo off 》 /sys/devices/system/cpu/smt/control’
這樣只剩下16個CPU,下面來編譯:

時間57秒,相對于51、53秒,速度下降不到10%。
這說明超線程SMT對編譯內核這個workload的性能的提升絕對沒有達到100%,甚至都沒有達到10%。
我們現在重新開啟超線程:
sudo sh -c ‘echo on 》 /sys/devices/system/cpu/smt/control
看一下哪個CPU和哪個CPU是thread sibling:

看起來CPU0和CPU16是一對,CPU1和CPU17是一對,依次類推。
剛才我們關閉SMT是把CPU16-CPU31全關了,只留下每對里面的1個CPU,也就是留下了CPU0-CPU15。
在開啟SMT的時候(假設藍色和紅色是一個CORE里面的兩個CPU):

在關閉SMT的時候,等于每對里面只留1個CPU:
現在我們換一種關法,一對對關,只留下8對,也就是8個core:
指令如下:
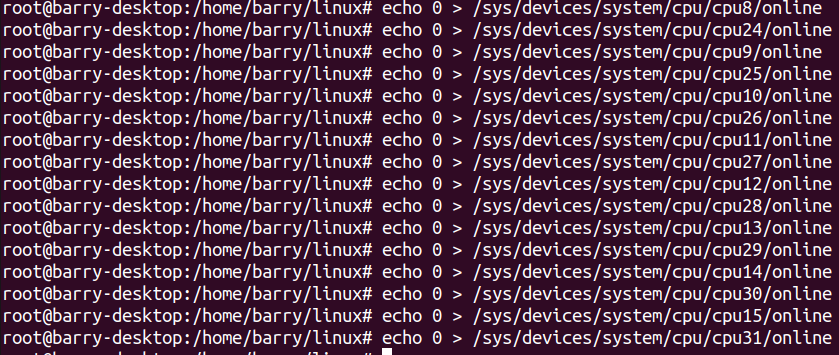
實現效果如下:
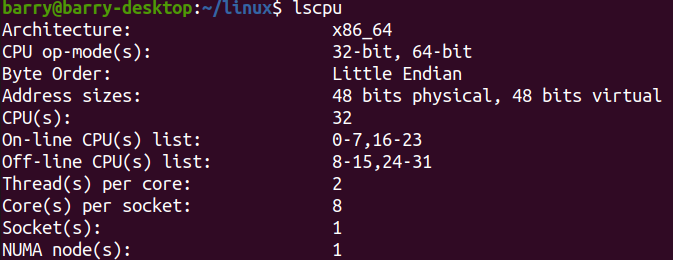
再重新編譯內核:

現在耗時是1分21秒,相對于所有CPU全開,下降了很多,時間增大了59%,當然沒有達到2倍。
再想想昨天的Intel I9,關閉5個完整核耗時是3分10秒,全開10核是2分30秒,Intel一半核工作和所有核同時工作的差距遠不如AMD那么明顯。
所以可以看出,就內核編譯這個workload而言,AMD的16core相對于8core,性能的scale會更加成正比。當然AMD開關SMT,對內核編譯這個workload而言,影響小于10%,而Intel I9的影響有14%。
很多童鞋昨天留言,說編譯內核有一定的IO bound,另外提到link階段是單線程,還有的童鞋說是Intel Turbo的影響,這些我們都認為是有一定道理的。但是,我始終堅信,profiling是檢驗猜想的唯一標準,后面有空再寫一篇文章來profiling一些究竟是為什么。
這到底是為什么?牙膏廠的多核scalability究竟是不是騙紙?還是按摩店的部分核沒有Intel部分核的威猛模式?「元芳,你怎么看?」
責任編輯:haq
-
amd
+關注
關注
25文章
5441瀏覽量
133936 -
內核
+關注
關注
3文章
1363瀏覽量
40228 -
intel
+關注
關注
19文章
3480瀏覽量
185750
原文標題:這到底是為什么?牙膏廠的多核scalability究竟是不是騙紙?還是按摩店的部分核沒有Intel部分核的威猛模式?「元芳,你怎么看?」
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多核CPU的優勢是什么
Intel 13/14代i9 K系列處理器不穩定,部分用戶轉向AMD
求助,關于ESP32多核使用問題求解答
TC3x多核使用與TC2x多核使用相比是否有任何限制?
risc-v多核芯片在AI方面的應用
13代及14代酷睿i9系列高端CPU游戲崩潰問題引發關注
兆芯開先KX-7000處理器現身Geekbench,多核性能接近8代i5
英特爾酷睿i9-14900KS確認發售,預購價較i9-14900K上漲27%
多核異構通信框架(RPMsg-Lite)


華碩天選5 Pro游戲本1月23日發布,搭載RTX4060獨顯,起售價8999元
首發i9-14900HX 華碩天選5 Pro詳細評測報告





 工商網監
工商網監
評論