 一文匯總并發http請求最快的幾種實現方式用
一文匯總并發http請求最快的幾種實現方式用
假如有一個文件,里面有 10 萬個 url,需要對每個 url 發送 http 請求,并打印請求結果的狀態碼,如何編寫代碼盡可能快的完成這些任務呢?
Python 并發編程有很多方法,多線程的標準庫 threading,concurrency,協程 asyncio,當然還有 grequests 這種異步庫,每一個都可以實現上述需求,下面一一用代碼實現一下,本文的代碼可以直接運行,給你以后的并發編程作為參考:
隊列+多線程定義一個大小為 400 的隊列,然后開啟 200 個線程,每個線程都是不斷的從隊列中獲取 url 并訪問。
主線程讀取文件中的 url 放入隊列中,然后等待隊列中所有的元素都被接收和處理完畢。代碼如下:
fromthreadingimportThread
importsys
fromqueueimportQueue
importrequests
concurrent=200
defdoWork():
whileTrue:
url=q.get()
status,url=getStatus(url)
doSomethingWithResult(status,url)
q.task_done()
defgetStatus(ourl):
try:
res=requests.get(ourl)
returnres.status_code,ourl
except:
return"error",ourl
defdoSomethingWithResult(status,url):
print(status,url)
q=Queue(concurrent*2)
foriinrange(concurrent):
t=Thread(target=doWork)
t.daemon=True
t.start()
try:
forurlinopen("urllist.txt"):
q.put(url.strip())
q.join()
exceptKeyboardInterrupt:
sys.exit(1)
運行結果如下:

有沒有 get 到新技能?
線程池
如果你使用線程池,推薦使用更高級的 concurrent.futures 庫:
importconcurrent.futures
importrequests
out=[]
CONNECTIONS=100
TIMEOUT=5
urls=[]
withopen("urllist.txt")asreader:
forurlinreader:
urls.append(url.strip())
defload_url(url,timeout):
ans=requests.get(url,timeout=timeout)
returnans.status_code
withconcurrent.futures.ThreadPoolExecutor(max_workers=CONNECTIONS)asexecutor:
future_to_url=(executor.submit(load_url,url,TIMEOUT)forurlinurls)
forfutureinconcurrent.futures.as_completed(future_to_url):
try:
data=future.result()
exceptExceptionasexc:
data=str(type(exc))
finally:
out.append(data)
print(data)
協程 + aiohttp
協程也是并發非常常用的工具了:
importasyncio
fromaiohttpimportClientSession,ClientConnectorError
asyncdeffetch_html(url:str,session:ClientSession,**kwargs)->tuple:
try:
resp=awaitsession.request(method="GET",url=url,**kwargs)
exceptClientConnectorError:
return(url,404)
return(url,resp.status)
asyncdefmake_requests(urls:set,**kwargs)->None:
asyncwithClientSession()assession:
tasks=[]
forurlinurls:
tasks.append(
fetch_html(url=url,session=session,**kwargs)
)
results=awaitasyncio.gather(*tasks)
forresultinresults:
print(f'{result[1]}-{str(result[0])}')
if__name__=="__main__":
importsys
assertsys.version_info>=(3,7),"ScriptrequiresPython3.7+."
withopen("urllist.txt")asinfile:
urls=set(map(str.strip,infile))
asyncio.run(make_requests(urls=urls))
grequests[1]
這是個第三方庫,目前有 3.8K 個星,就是 Requests + Gevent[2],讓異步 http 請求變得更加簡單。Gevent 的本質還是協程。
使用前:
pipinstallgrequests
使用起來那是相當的簡單:
importgrequests
urls=[]
withopen("urllist.txt")asreader:
forurlinreader:
urls.append(url.strip())
rs=(grequests.get(u)foruinurls)
forresultingrequests.map(rs):
print(result.status_code,result.url)
注意 grequests.map(rs) 是并發執行的。運行結果如下:
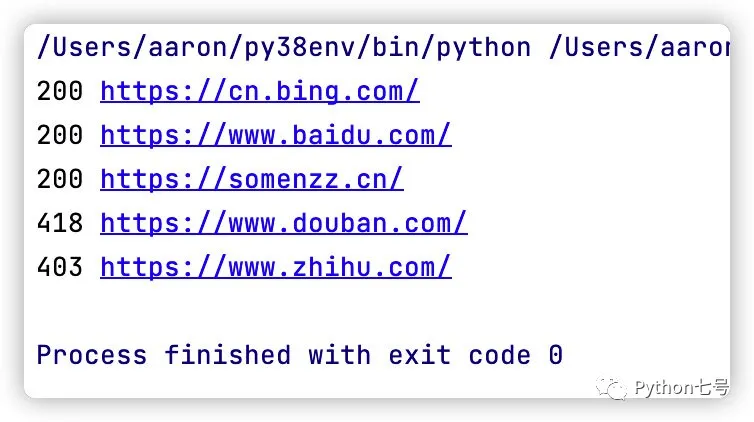
也可以加入異常處理:
>>>defexception_handler(request,exception):
...print("Requestfailed")
>>>reqs=[
...grequests.get('http://httpbin.org/delay/1',timeout=0.001),
...grequests.get('http://fakedomain/'),
...grequests.get('http://httpbin.org/status/500')]
>>>grequests.map(reqs,exception_handler=exception_handler)
Requestfailed
Requestfailed
[None,None,500]>]
最后的話
今天分享了并發 http 請求的幾種實現方式,有人說異步(協程)性能比多線程好,其實要分場景看的,沒有一種方法適用所有的場景,筆者就曾做過一個實驗,也是請求 url,當并發數量超過 500 時,協程明顯變慢。
-
編程
+關注
關注
88文章
3595瀏覽量
93601 -
HTTP
+關注
關注
0文章
501瀏覽量
31065 -
URL
+關注
關注
0文章
139瀏覽量
15312 -
python
+關注
關注
56文章
4782瀏覽量
84461
原文標題:如何用最快的方式發送 10 萬個 http 請求?
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HTTP相關返回值異常如何解決(上篇)

高并發物聯網云平臺是什么
請問如何使用HTTP請求獲取本地時間?
如何使用RTOS SDK 2.1.0從esp8266發送http請求?
stm32cube配置lwip,http下發請求后為什么沒有反饋ACK?
手把手教學!HLK-LD2410B/C新手必看攻略!測試教程、模塊調參一文詳解~

鴻蒙OS開發實戰:【網絡管理HTTP數據請求】
鴻蒙原生應用開發-網絡管理HTTP數據請求
鴻蒙OS開發實例:【工具類封裝-http請求】





 工商網監
工商網監
評論