 如何使用多模態信息做prompt
如何使用多模態信息做prompt
自多模態大火以來,井噴式地出現了許多工作,通過改造預訓練語言模型,用圖像信息來增強語義信息,但主要集中在幾個 NLU 任務上,在 NLG 上的研究比較少。
今天要介紹的這篇 paper Multimodal Conditionality for Natural Language Generation 研究的任務場景則是以多模態信息作為條件做 conditional 的 NLG任務。這種任務設置有許多實際的應用場景。比如,生成商品介紹文案時,僅僅基于該商品的文字標題是不夠的。如果能結合商品的圖片,必然能夠得到更貼切的文案。
這篇工作的模型基于 GPT2,而多模態信息則是以一種類似 prompt 的方式來使用。雖然方法比較簡單直觀,但具備一定通用性,未來或許有進一步挖掘的可能。
論文題目:
Multimodal Conditionality for Natural Language Generation
論文鏈接:
https://arxiv.org/pdf/2109.01229.pdf
原理作者的想法其實十分簡單,一切語言模型都是為了衡量一段文字序列的概率,即:
而如果引入了多模態的輸入,就相當于在生成時多了一個條件,即條件概率為:
其中為多模態輸入序列。
以文中生成商品文案的運用場景為例。
這里的Product Title和Product Images就是作為生成Product Description時的“條件”。
那么如何將多模態序列引入到自然語言生成模型呢?
本文使用了一個十分直觀的方法,稱作MANTIS,將作為條件的多模態序列作為前綴放置到decoder輸入序列的前面,進而中解碼過程中分享多模態信息。其中圖片輸入借助ResNet-152,將最后一層輸出用線性層映射到語言模型同一個空間中。而作為條件的文本輸入,即這里的product title,和生成序列一同進行編碼。
效果數據集采用FACAD,提供了商品的標題和圖片,目標是生成產品描述,效果如下:
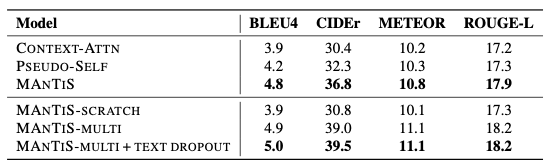

文中提出的模型在所有指標中都取得了最優結果,相比于baseline,將BLEU4提升了0.8,CIDEr提升了7.2,METEOR提升了0.8,ROUGE-L提升了1.0。同時,由于衡量生成文本質量具有主觀性,作者也進行了人工評分,結果表明MANTIS依然取得了最優結果。
從生成效果來看,生成的描述成功地結合了圖片信息,使得描述更加準確,而非籠統的介紹。
總結這篇文章方法十分直觀,但是結合最近火熱的 Prompt,似乎又有了更多的啟發。同樣是生成,同樣是加前綴,似乎給定條件的生成就是加上編碼好的前綴?那么多模態未來能不能成為一種新的prompt呢?作者認為他們的模型可以借助各種不同的多模態條件生成,然而不得不說本文的方法對模態融合的部分做的馬虎了些。本文只是單純借助解碼器進行融合,并沒有在編碼階段就分享跨模態的信息。
責任編輯:haq
-
信息
+關注
關注
0文章
405瀏覽量
35520 -
模型
+關注
關注
1文章
3174瀏覽量
48716
原文標題:用多模態信息做 prompt,解鎖 GPT 新玩法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用OpenVINO部署Qwen2多模態模型
Meta發布多模態LLAMA 3.2人工智能模型
云知聲推出山海多模態大模型
李未可科技正式推出WAKE-AI多模態AI大模型

AI機器人迎來多模態模型
谷歌推出多模態VLOGGER AI
機器人基于開源的多模態語言視覺大模型

什么是多模態?多模態的難題是什么?

如何從訓練集中生成候選prompt 三種生成候選prompt的方式
自動駕駛和多模態大語言模型的發展歷程

從Google多模態大模型看后續大模型應該具備哪些能力
語音識別技術最新進展:視聽融合的多模態交互成為主要演進方向

成都匯陽投資關于多模態驅動應用前景廣闊,上游算力迎機會!
人工智能領域多模態的概念和應用場景
大模型+多模態的3種實現方法






 工商網監
工商網監
評論