 細分模型探索性數據分析和預處理
細分模型探索性數據分析和預處理
導讀:今天給大家帶來了一個Python業務分析實戰項目——客戶細分模型的應用案例上篇,本文闡述比較詳細,包括代碼演示、可視化圖形展示、以及文字詳細分析。分析較淺,希望能夠給大家帶來些許幫助,歡迎交流學習!文章較長,建議收藏~
客戶細分模型是將整體會員劃分為不同的細分群體或類別,然后基于細分群體做管理、營銷和關懷。客戶細分模型常用于整體會員的宏觀性分析以及探索性分析,通過細分建立初步認知,為下一步的分析和應用提供基本認知。常用方法包括:基于屬性的方法、ABC分類法、聚類法
基于屬性方法
- 客戶地域 -- 如北京、上海
- 產品類別 -- 如家電、圖書
- 客戶類別 -- 大客戶、普通客戶、VIP客戶
- 客戶性別 -- 男、女
- 會員消費等級 -- 高、中、低價值會員
ABC分類法
Activity Based Classification 是根據事物的主要特征做分類排列,從而實現區別對待、區別管理的一種方法。ABC法則強調的是分清主次。具體做法,先將目標數據列倒序排序,然后做累積百分比統計,最后將得到的累積百分比按照下面的比例劃分為A、B、C三類。
- A類因素:主要影響,累積頻次為0%~80%
- B類因素:次要影響,累積頻次為80%~90%
- C類因素:一般影響,累積頻次為90%~100%
聚類法
常用的非監督方法,無須任何的先驗知識,只需要指定要劃分的群體數量即可。這里可以參見總結的常用聚類模型kmeans聚類
本文客戶細分方法
將使用電子商務用戶購買商品數據集,并嘗試開發一個模型,主要目的是完成以下兩個部分。
- 對客戶進行細分。
- 通過為新客戶分配適當的簇群,預測下一年新客戶將進行的購買行為。
本文主要內容
本次實戰項目共分為上下兩部分,上篇(本篇)包括探索性數據分析,產品類別分析兩部分;下篇將包括客戶細分和客戶行為分析與預測。本篇主要結構與內容思維導圖如下圖所示。
探索性數據分析和預處理
數據準備
df_initial=pd.read_csv('./data.csv')
print('Dataframe維度:',df_initial.shape)
df_initial['InvoiceDate']=pd.to_datetime(df_initial['InvoiceDate'])
df_initial.columns=['訂單編號','庫存代碼','描述','數量',
'訂單日期','單價','客戶ID','國家']
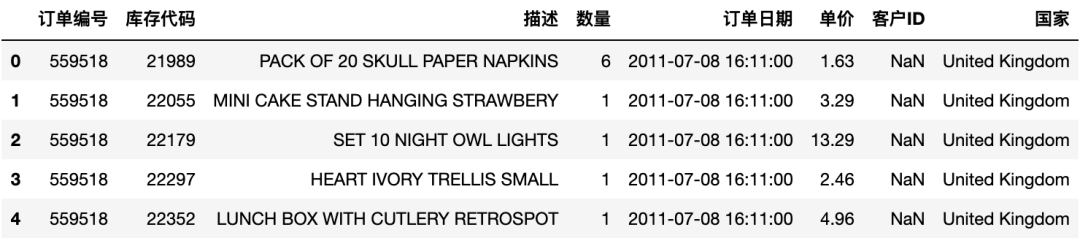
display(df_initial[:5])
Dataframe維度: (284709, 8)
缺失值分析
缺失值分析與處理是指對原始數據中缺失的數據項進行預處理,以免影響模型精度和穩定性。數據缺失值處理方法有不少,這里可以參見之前總結的缺失值處理,你真的會了嗎?
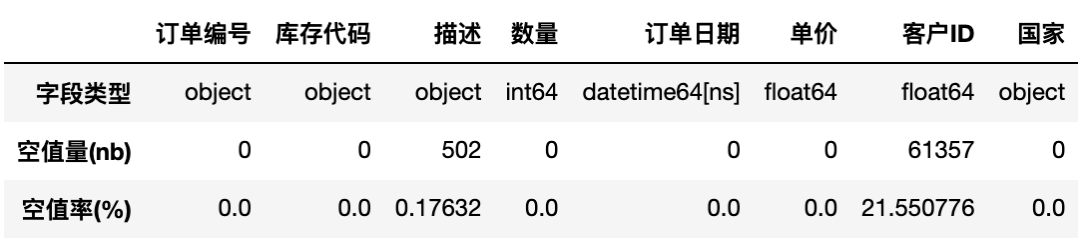
#提供有關列類型和空值數量的一些信息
tab_info=pd.DataFrame(df_initial.dtypes).T.rename(index={0:'字段類型'})
tab_info=tab_info.append(pd.DataFrame(
df_initial.isnull().sum()
).T.rename(index={0:'空值量(nb)'}))
tab_info=tab_info.append(pd.DataFrame(
df_initial.isnull().sum()/df_initial.shape[0]*100
).T.rename(index={0:'空值率(%)'}))
print('-'*10+"顯示有關列類型和空值數量的信息"+'-'*10)
display(tab_info)
------- 顯示有關列類型和空值數量的信息 -------
刪除缺失值
從上面缺失值分析結果看到,客戶ID約22%的數據記錄是空的,這意味著有約22%的數據記錄沒有分配給任何客戶。而我們不可能把這些記錄的值映射到任何客戶。所以這些對于目前是沒有用的,因此我們可以將其刪除。
df_initial.dropna(axis=0,
subset=['客戶ID'],
inplace=True)
刪除重復值
print('重復的數據條目:{}'.format(
df_initial.duplicated().sum()))
df_initial.drop_duplicates(inplace=True)
重復的數據條目: 3175
變量'國家'分析
temp=df_initial[['客戶ID','訂單編號','國家']].groupby(
['客戶ID','訂單編號','國家']).count()
temp=temp.reset_index(drop=False)
countries=temp['國家'].value_counts()
統計下來,共有32個國家。并根據每個國家的訂單量進行計數求和,排序后繪制國家--國家訂單量柱狀圖,如下所示。
變量'客戶和產品'分析
本數據包含約200,000條記錄。這些記錄中的用戶和產品數量分別是多少呢?
pd.DataFrame([{'產品':len(df_initial['庫存代碼'].value_counts()),
'交易':len(df_initial['訂單編號'].value_counts()),
'客戶':len(df_initial['客戶ID'].value_counts()),
}],
columns=['產品','交易','客戶'],
index=['數量'])
| 產品 | 交易 | 客戶 | |
|---|---|---|---|
| 數量 | 3182 | 11068 | 3341 |
可以看到,該數據集包含3341個用戶的記錄,這些用戶購買了3182種不同的商品。有約11000的交易被執行。現在我們需要了解每筆交易中購買的產品數量。
temp=df_initial.groupby(by=['客戶ID','訂單編號'],
as_index=False)['訂單日期'].count()
nb_products_per_basket=temp.rename(
columns={'訂單日期':'產品數量'})
nb_products_per_basket[:10].sort_values('客戶ID')
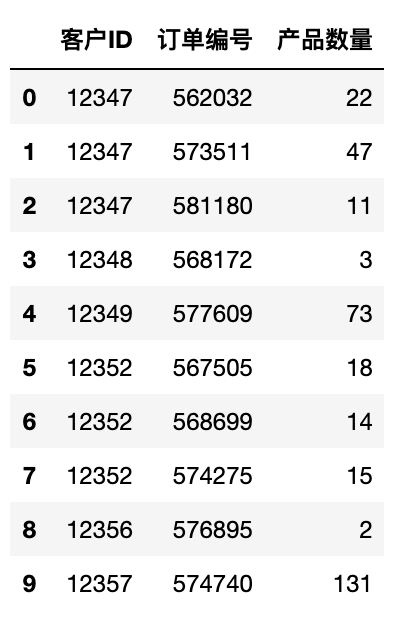
此處需注意的要點:
- 有一些用戶在電子商務平臺上只購買了一次,或只購買了一件商品。這類用戶如客戶ID為12371。
- 有一些用戶經常在每個訂單中購買大量商品。這類用戶如客戶ID為12347。
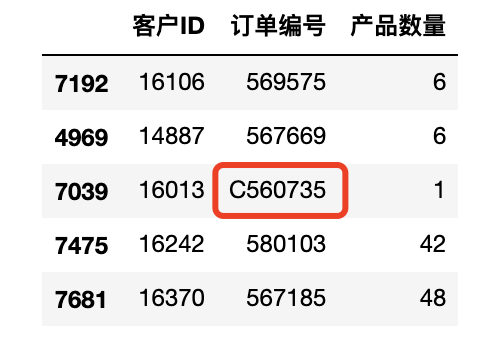
如果你仔細觀察訂單編號數據特征,那么你很容易就能發現有些訂單編號有個前綴C。這個C表示該訂單已經被取消。如下圖中C560735。下面就來具體分析下取消的訂單一些特征。
取消訂單分析
這里統計被取消訂單對應的交易數量。
nb_products_per_basket['取消訂單量']=nb_products_per_basket['訂單編號'].apply(
lambdax:int('C'inx))
display(nb_products_per_basket.query("取消訂單量!=0")[:5])
#計算取消訂單量的比例
n1=nb_products_per_basket['取消訂單量'].sum()
n2=nb_products_per_basket.shape[0]
percentage=(n1/n2)*100
print('取消訂單數量:{}/{}({:.2f}%)'.format(n1,n2,percentage))
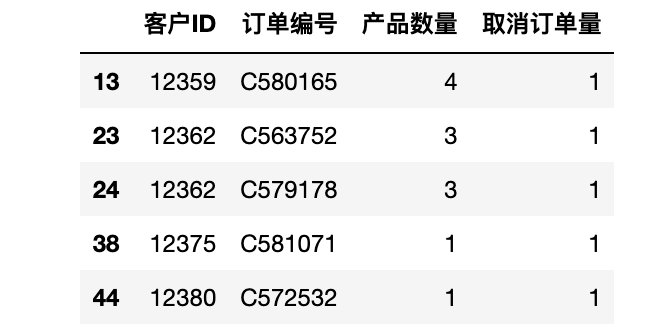
取消訂單數量: 1686/11068 (15.23%)
得到結果已取消的交易數目相當大(約占交易總數的15%)。這里,仔細觀察數據集,尤其是取消的訂單,可以想到,當一個訂單被取消時,在數據集中可能會存在另一條對應的記錄,該記錄除了數量和訂單日期變量之外,其他變量內容基本相同。下面檢查一下是否所有的記錄都是這樣的。具體做法是:
- 先篩選出負數數量的記錄,并在所有數據中檢查是否有一個具有相同數量(但為正)的訂單,其它屬性都相同(客戶ID,描述和單價)
- 有些取消訂單中,描述列會標注"Discount",因此將包含該特征的記錄篩除后尋找。

df_check=df_initial[(df_initial['數量']'描述']!='Discount')][
['客戶ID','數量','庫存代碼','描述','單價']]
forindex,colindf_check.iterrows():
ifdf_initial[(df_initial['客戶ID']==col[0]
)&(df_initial['數量']==-col[1])
&(df_initial['描述']==col[2])].shape[0]==0:
print(index,df_check.loc[index])
print(25*'-'+'>'+'假設不成立')
break
279 客戶ID 14808.0
數量 -1
庫存代碼 22655
描述 VINTAGE RED KITCHEN CABINET
單價 125.0
Name: 279, dtype: object
-----------------------------> 假設不成立
沒有得到理想的結果,說明取消訂單不一定與事先已下的訂單相對應。此時,可以在數據表中創建一個新變量,用于指示是否取消了部分訂單。而對于其中沒有對應購買訂單的取消訂單記錄,可能是由于購買訂單是在錄入數據庫之前執行的。下面對取消的訂單進行了一次普查,并檢查是否有對應購買訂單存在。
df_cleaned=df_initial.copy(deep=True)
df_cleaned['取消訂單數量']=0
entry_to_remove=[];doubtfull_entry=[]
forindex,colindf_initial.iterrows():#全表掃描
if(col['數量']>0)orcol['描述']=='Discount':continue
df_test=df_initial[(df_initial['客戶ID']==col['客戶ID'])&
(df_initial['庫存代碼']==col['庫存代碼'])&
(df_initial['訂單日期']'訂單日期'])&
(df_initial['數量']>0)].copy()
#沒有對應項的取消訂單
if(df_test.shape[0]==0):
doubtfull_entry.append(index)
#有對應項的取消訂單
elif(df_test.shape[0]==1):
index_order=df_test.index[0]
df_cleaned.loc[index_order,'取消訂單數量']=-col['數量']
entry_to_remove.append(index)
#不同的對應項是按順序存在的:我們刪除最后一個
elif(df_test.shape[0]>1):
df_test.sort_index(axis=0,ascending=False,inplace=True)
forind,valindf_test.iterrows():
ifval['數量']'數量']:continue
df_cleaned.loc[ind,'取消訂單數量']=-col['數量']
entry_to_remove.append(index)
break
沒有對應購買記錄的取消訂單和有對應購買記錄的取消訂單分別存儲在'doubtfull_entry和entry_to_remove列表,他們的個數分別為1672和3435,而這部分數據我們也需要將其刪除。
庫存代碼分析
從上面分析內容中看到,庫存代碼變量的一些值表示一個特定的交易(D代表Discount)。下面通過正則表達式尋找只包含字母的代碼集,統計出這個變量都有哪些值。
list_special_codes=df_cleaned[df_cleaned['庫存代碼'
].str.contains('^[a-zA-Z]+',
regex=True)]['庫存代碼'].unique()
#并通過對應"描述"變量來尋找每個代碼的具體解釋。
forcodeinlist_special_codes:
print("{:<15}?->{:<30}".format(
code,df_cleaned[df_cleaned['庫存代碼']==code]['描述'].unique()[0]))
M -> Manual
POST -> POSTAGE
C2 -> CARRIAGE
PADS -> PADS TO MATCH ALL CUSHIONS
DOT -> DOTCOM POSTAGE
BANK CHARGES -> Bank Charges
我們看到有幾種特殊的交易類型,如與港口費或銀行費有關。
購物車價格分析
接下來是衍生變量:每次購買的總價 = 單價 * (訂單數量 - 取消訂單數量)
df_cleaned['總價']=df_cleaned['單價']*
(df_cleaned['數量']-df_cleaned['取消訂單數量'])
df_cleaned.sort_values('客戶ID')[:5]

數據集中的每一條記錄都表示一種產品的價格。而一條訂單可以被分成幾條記錄。因此需要將一條訂單中所有價格匯總求和,得到每一個訂單總價。
- 以客戶ID和訂單編號作為聚合對象,對總價進行求和。
- 訂單日期處理,現將訂單日期轉換為整數類型,聚合后求平均值,在轉換為日期型。
- 最后篩選出購物車價格大于0的重要記錄。
#購物車訂單總價
temp=df_cleaned.groupby(by=['客戶ID','訂單編號'],
as_index=False)['總價'].sum()
basket_price=temp.rename(columns={'總價':'購物車價格'})
#處理訂單日期
df_cleaned['訂單日期_int']=df_cleaned['訂單日期'].astype('int64')
temp=df_cleaned.groupby(by=['客戶ID','訂單編號'],
as_index=False)['訂單日期_int'].mean()
df_cleaned.drop('訂單日期_int',axis=1,inplace=True)
basket_price.loc[:,'訂單日期']=pd.to_datetime(temp['訂單日期_int'])
#重要記錄選擇
basket_price=basket_price[basket_price['購物車價格']>0]
basket_price.sort_values('客戶ID')[:6]
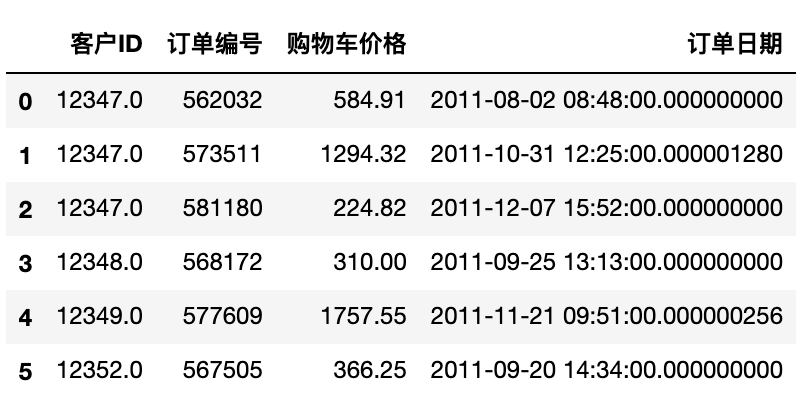
接下來將購物車總價進行離散化處理,并匯總可視化得到如下圖所示的結果。
可以看出,絕大多數訂單購買價格相對較大的,約有65%的采購超過了200英鎊的價格。
產品類別分析
在數據集中,產品是通過變量庫存代碼唯一標識的。產品的簡短描述在變量描述中給出。在這里計劃使用后一個變量的內容,即變量描述,以便將產品分組到不同的類別中。因此這里就涉及到自然語言處理,需要先將簡短描述分詞后再統計。由于數據集使用的是純英文數據集,因此這里選用nltk庫進行處理。
產品描述
首先從描述變量中提取有用的信息。因此這里定義了一個函數。
keywords_inventory(dataframe,colonne='描述')
這個函數以dataframe作為輸入,分析描述列的內容,執行如下操作:
- 提取產品描述中出現的名稱(適當的,常見的)
- 對于每個名稱,提取單詞的根,并聚合與這個特定根相關的名稱集
- 每個根出現在數據集中的次數計數
- 當幾個單詞被列出為同一個詞根時,我認為與這個詞根相關的關鍵字是最短的名字(當有單數/復數變體時,系統地選擇單數)
這個函數的執行返回四個變量:
-
' keywords '
提取的關鍵字列表
['lunch',
'bag',
'design',
'suki',]
-
' keywords_roots '
一個字典,其中鍵是關鍵字的根,值是與這些根相關聯的單詞列表
{'lunch':{'lunch'},
'bag':{'bag','bags'},
'design':{'design','designs'},
'suki':{'suki'},}
-
' count_keywords '
字典中列出每個單詞使用的次數
{'lunch':24,
'bag':136,
'design':116,
'suki':7,}
-
'keywords_select'
字典中列出每個單詞詞根<->關鍵字間的關聯關系
{'lunch':'lunch',
'bag':'bag',
'design':'design',
'suki':'suki',
'regenc':'regency'}
接下來先對所有產品描述進行去重處理,再運用上面定義的函數進行詞根提取并統計.
df_produits=pd.DataFrame(df_initial['描述'].unique()
).rename(columns={0:'描述'})
keywords,keywords_roots,keywords_select,
count_keywords=keywords_inventory(df_produits)
從結果看,變量中關鍵字'描述'的數量共 1347個。此時,將其中一個結果' count_keywords '字典轉換為一個列表,根據關鍵詞的出現情況對它們進行排序。
因為字體有點小,不過不影響我們理解實操邏輯。你也可以通過繪制橫向柱狀圖,調大軸標簽大小,來自己探究每個詞根。大家可以自己嘗試。
定義產品類別
上面結果中,我們獲得的列表中包含1400多個關鍵詞,而最頻繁的關鍵詞出現在200多種產品中。然而,在仔細檢查列表中內容時發現,有很多名稱是無用的,不攜帶任何有用的信息,比如顏色、標簽等。因此,接下來需要將這些詞從數據集中刪除。另外,為了更加便捷有效地分析數據,我決定只考慮那些出現超過13次的詞。
list_products=[]
fork,vincount_keywords.items():
word=keywords_select[k]
ifwordin['pink','blue','tag','green','orange']:continue
iflen(word)continue
if('+'inword)or('/'inword):continue
list_products.append([word,v])
list_products.sort(key=lambdax:x[1],reverse=True)
print('保留詞:',len(list_products))
從結果看,共保留了164個關鍵詞。分完詞并處理后 ,還沒有結束,還需要將文字轉化為數字,這個過程就是數據編碼過程。
數據編碼
首先定義編碼規則,將使用上面得到的關鍵字創建產品組。將矩陣定義如下,其中,如果產品的描述包含單詞,則系數為1,否則為0。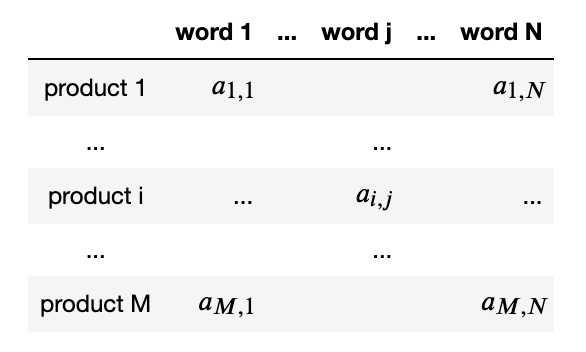
liste_produits=df_cleaned['描述'].unique()
X=pd.DataFrame()
forkey,occurenceinlist_products:
X.loc[:,key]=list(map(lambdax:int(key.upper()inx),liste_produits))
- 矩陣表示產品描述中包含的單詞,使用獨熱編碼原則。
-
這里使用的是逐條處理,還有
pd.get_dummies()函數直接處理,這里就不做詳細介紹,有興趣的小伙伴可以研究研究。 - 在實踐中發現,若使用價格范圍來劃分分組,這會使每個組中元素更加均衡。
因此,在這個矩陣上增加6列以表示產品的價格范圍。
threshold=[0,1,2,3,5,10]
label_col=[]
#首先定義labels
foriinrange(len(threshold)):
ifi==len(threshold)-1:
col='.>{}'.format(threshold[i])
else:
col='{}<.<{}'.format(threshold[i],threshold[i+1])
label_col.append(col)
X.loc[:,col]=0#每個labels的初始值設為0
fori,prodinenumerate(liste_produits):
prix=df_cleaned[df_cleaned['描述']==prod]['單價'].mean()
j=0
whileprix>threshold[j]:
j+=1
ifj==len(threshold):break
X.loc[i,label_col[j-1]]=1
為了選擇合適的范圍,我檢查了不同組別的產品數量,如果組內數量嚴重不均衡,則需要調整邊界點。下面是本次劃分的范圍,可見該邊界范圍還算均衡。
范圍 產品數量
--------------------
0<.<1 890
1<.<2 817
2<.<3 553
3<.<5 520
5<.<10 395
.>10 123
創建產品集群
將把產品分組到不同的類中。在二進制編碼矩陣的情況下,計算距離最合適的度量是漢明度量。而我們本次使用的也是常用的sklearn的Kmeans方法使用的是歐幾里德距離,但在分類變量的情況下,它不是最佳選擇。其實可以使用kmodes包以使用漢明度量,小伙伴們可以自行研究。
matrix=X.values
forn_clustersinrange(3,10):
kmeans=KMeans(init='k-means++',n_clusters=n_clusters,n_init=30)
kmeans.fit(matrix)
clusters=kmeans.predict(matrix)
silhouette_avg=silhouette_score(matrix,clusters)
print("Forn_clusters=",n_clusters,"Theaveragesilhouette_scoreis:",silhouette_avg)
For n_clusters = 3 The average silhouette_score is : 0.11062930220266365
For n_clusters = 4 The average silhouette_score is : 0.13680035318514175
For n_clusters = 5 The average silhouette_score is : 0.15722360950670058
For n_clusters = 6 The average silhouette_score is : 0.1593958217011667
For n_clusters = 7 The average silhouette_score is : 0.15524717712994918
For n_clusters = 8 The average silhouette_score is : 0.16532400447658901
For n_clusters = 9 The average silhouette_score is : 0.16082298271895967
實際上,以上所得的分數可視為相等,因為根據運行情況,所有具有'n_clusters' 3的簇獲得的分數約為(第一個簇的分數略低)。另一方面,發現當超過5個簇時,有些簇所包含的元素非常少。
因此,最終選擇將數據集劃分為5個簇。為了確保每次運行notebook都能很好地進行分類,我反復迭代,直到我們獲得可能的最佳輪廓系數,在目前的情況下,輪廓系數約為0.15。
n_clusters=5
silhouette_avg=-1
whilesilhouette_avg'k-means++',n_clusters=n_clusters,n_init=30)
kmeans.fit(matrix)
clusters=kmeans.predict(matrix)
silhouette_avg=silhouette_score(matrix,clusters)
#使用kmodes模塊進行聚類
#km=kmodes.KModes(n_clusters=n_clusters,init='Huang',n_init=2,verbose=0)
#clusters=km.fit_predict(matrix)
#silhouette_avg=silhouette_score(matrix,clusters)
print("Forn_clusters=",n_clusters,"Theaveragesilhouette_scoreis:",silhouette_avg)
For n_clusters = 5 The average silhouette_score is : 0.15722360950670058
描述集群的內容
上面對所有訂單數據進行了Kmeans聚類,并檢查每個類中的元素數量。
pd.Series(clusters).value_counts()
2 890
0 817
4 553
1 520
3 518
dtype: int64
輪廓系數看聚類效果
為了深入了解聚類的效果,常用輪廓系數評價聚類算法模型效果。通過下圖可視化地表現聚類效果,參考自sklearn documentation。
#定義輪廓系數得分
sample_silhouette_values=silhouette_samples(matrix,clusters)
#然后畫個圖
graph_component_silhouette(n_clusters,[-0.07,0.33],len(X),sample_silhouette_values,clusters)
解讀此圖,不同顏色代表不同的簇,每個簇橫坐標表示簇內樣本點的輪廓系數,按照大小排序并繪制橫向條形圖,縱坐標表示樣本量大小。
詞云圖看聚類結果
現在我們可以看看每個簇群代表的對象類型。為了獲得其內容的全局視圖,用每個關鍵詞中最常見的關鍵詞繪制詞云圖。先統計關鍵詞出現的頻次。
liste=pd.DataFrame(liste_produits)
liste_words=[wordfor(word,occurence)inlist_products]
occurence=[dict()for_inrange(n_clusters)]
foriinrange(n_clusters):
liste_cluster=liste.loc[clusters==i]
forwordinliste_words:
#同之前的一樣,篩選掉顏色等無用的詞語
ifwordin['art','set','heart','pink','blue','tag']:continue
occurence[i][word]=sum(liste_cluster.loc[:,0].str.contains(word.upper()))
定義繪制詞云圖函數,并繪制詞云圖。
fig=plt.figure(1,figsize=(14,14))
color=[0,160,130,95,280,40,330,110,25]
foriinrange(n_clusters):
list_cluster_occurences=occurence[i]
tone=color[i]#定義詞的顏色
liste=[]
forkey,valueinlist_cluster_occurences.items():
liste.append([key,value])
liste.sort(key=lambdax:x[1],reverse=True)
make_wordcloud(liste,i+1)
從這個詞云圖結果中我們可以看到,其中一個簇群中包含與禮物相關的對象(關鍵字:圣誕節Christmas、包裝packaging、卡片 card等)。
另一簇則傾向于包含奢侈品和珠寶(關鍵詞:項鏈necklace、手鐲bracelet、蕾絲lace、銀silver)。但也可以觀察到,許多詞出現在不同的簇群中,因此很難清楚地區分它們。
PCA主成分分析
為了使得聚類后的結果能夠真正做到有效區分,將含有大量變量的初始矩陣數據,我準備使用PCA主成分分析對其進行處理。
pca=PCA()
pca.fit(matrix)
pca_samples=pca.transform(matrix)
我們看到解釋數據所需的維度數量是極其重要的:我們需要超過100個維度來解釋數據的90%的方差。在實踐中,我決定只保留有限數量的維度。我們以50個維度來做降維處理。
pca=PCA(n_components=50)
matrix_9D=pca.fit_transform(matrix)
mat=pd.DataFrame(matrix_9D)
mat['cluster']=pd.Series(clusters)

為了更加直觀地觀察PCA降維度后效果,下面用帶顏色的散點圖可視化的方法展示,橫縱軸分別代表不同的維度變量,顏色代表不同的簇,如下圖所示,這里只繪制其中的部分維度數據。
由圖可看出,第一主成分已經較好地將幾個類別分開了,說明此次降維效果還算可以。
寫在最后
到目前為止,已經將本次案例前半部分演示完畢,包括數據探索性數據分析,缺失值等處理。各個關鍵變量的分析。最后重要的是通過聚類方法,將產品進行聚類分類,并通過詞云圖和主成分分析各個類別聚類分離效果。
-
數據
+關注
關注
8文章
6896瀏覽量
88832 -
模型
+關注
關注
1文章
3173瀏覽量
48715
原文標題:一個企業級數據挖掘實戰項目|客戶細分模型(上)
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LLM在數據分析中的作用
eda分析中的數據清洗步驟
eda中常用的數據處理方法
eda與傳統數據分析的區別
如何進行有效的eda分析
云計算在大數據分析中的應用
使用AI大模型進行數據分析的技巧
機器學習中的數據預處理與特征工程
數據分析的工具有哪些
數據分析有哪些分析方法
機器學習在數據分析中的應用
【大語言模型:原理與工程實踐】大語言模型的預訓練
基于振弦采集儀的工程監測數據分析方法研究






 工商網監
工商網監
評論