 當“大”模型遇上“小”數據
當“大”模型遇上“小”數據
“ 或許自上次N篇ACL事件后,不少人會突然發現我銷聲匿跡了。的確,我20年論文斷供整整一年。這一年我經歷了論文從量變到質變的痛苦蛻變過程,而今天這一篇論文就是在這個過程后的第一個我略微滿意的工作Child-Tuning,推薦給大家。”
自BERT火了以后,基本上現在所有NLP領域都all in Pre-training & Fine-tuning了吧?但當“大”規模預訓練模型遇上“小”規模標注數據時,往往直接Fine-tuning會存在過擬合現象,進一步會影響Fine-tune完后模型的Generalization能力。如何更好地應對這一問題呢?
我們提出的Child-Tuning給出了一種新的解法--在Fine-tuning過程中僅更新預訓練模型中部分網絡的參數(這部分網絡本文就叫做Child Network),這么簡單直接的做法卻效果奇贊,結果在GLUE上相較標準Fine-tune有0.5~8.6個點的效果提升,但卻只需要幾行代碼的修改,你不想試試嗎?目前,該論文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》已被EMNLP‘21接收。
01—
當“大”模型遇上“小”數據
自BERT提出以來,預訓練模型的參數量從最開始的3億,逐漸攀升到了GPT-2的15億,再到火出NLP圈的1750億參數的GPT-3。一方面模型越來越大,但另一方面,下游任務的標注數據量有些情況下卻很少。如果直接將“大”模型在下游“小”數據上進行標準的Fine-tune,將模型遷移到目標任務中去,會導致什么情況呢?
由于這種“大”與“小”的不匹配,往往容易出現過擬合的現象,導致模型在下游任務中的表現差、不穩定、泛化性能差等現象,從而影響我們對于預訓練模型的使用[1]。因此,越來越多工作開始聚焦于如何解決這種不匹配現象,緩解大規模預訓練模型在下游任務中的過擬合。
本文介紹的Child-Tuning圍繞這個問題進行探究,從backward參數更新的角度思考問題,提出一種新的Fine-tuning策略,在Fine-tuning過程中僅更新對應的Child Network,在不同下游任務中相比Vanilla Fine-tuning有明顯提高,如基于BERT模型在四個不同數據集中平均帶來1.5個點的提升,在ELETRA上甚至提升8.6個點。
02—
Child-Tuning 簡單有效的微調算法
在Fine-tuning過程中,我們一方面想利用大規模預訓練模型提供的強大知識,另一方面又想解決“海量參數”與“少量標注樣本”的不匹配問題,那么能否采用這樣的方式來解決問題呢?在forward的時候保持與正常Fine-tune一樣,利用整個模型的參數來編碼輸入樣本;在backward更新參數的時候,無需調整海量龐大的參數,而是僅僅其中中的一部分,即網絡中的一個Child Network。基于這個想法,本文提出一個新的Fine-tuning的策略——Child-Tuning。Child-Tuning的想法很簡單,做法也很簡單,概括性地講可以分為兩個步驟:
Step1:在預訓練模型中發現確認Child Network,并生成對應的Weights的Gradients 0-1 Mask;
Step2:在后向傳播計算完梯度之后,僅僅對Child Network中的參數進行更新,而其他參數保持不變。
在前面提到的Child-Tuning的兩個步驟中,Step2即僅對Child Network中的參數進行更新相對簡單。我們可以通過一個梯度掩碼(Gradients Mask)來實現,即在計算出各個參數位置的梯度之后將其乘以一個0-1矩陣的梯度掩碼,屬于Child Network中參數的位置對應為1,而不屬于的對應為0,之后再進行參數的更新。
那問題的關鍵就落到了,怎么識別Step1提到的Child Network呢?本文探索了兩種算法。一種是與下游任務無關的Child-Tuning_F方法,另一種則是與下游任務相關、能夠自適應感知下游任務特點的Child-Tuning_D,這兩種方式各有優缺點。
任務無關算法Child-Tuning_F對于下游任務無關算法Child-Tuning_F(F for Task-Free) ,其最大的優點是簡單有效,在Fine-tune的過程中,只需要在每一步更新的迭代中,從伯努利分布中采樣得到一個Gradients Mask (M_t)即可,相當于在對網絡參數更新的時候隨機地將一部分梯度丟棄。
盡管方式簡單,我們從理論上證明(詳細見原論文)這種方法可以有效提高模型更新量的方差,有利于模型逃離局部最優點,最終收斂于一個相對比較平坦的損失曲面上,從而提高模型的泛化能力。任務相關算法Child-Tuning_D然而對于下游任務無關微調算法Child-Tuning_F,也有一個缺點,就是它對于不同的下游任務的策略都是一樣的,對于模型中的不同參數也都平等對待。
為此,我們提出了一個任務相關的Child-Tuning_D (D for Task-Driven ),讓選取Child Network的策略能夠針對不同的下游任務自適應地進行調整,選擇出與下游任務最相關最重要的參數來充當Child Network。具體的,我們引入Fisher Information Matrix(FIM)[2] 來估計每個參數對于下游任務的重要性程度,并與前人工作一致近似采用FIM的對角矩陣(即假設參數之間互相獨立)來計算各個參數相對下游任務的重要性分數[3],之后選擇分數最高的那部分參數作為我們的Child-Network。
盡管Child-Tuning_D擁有感知下游任務特性的能力,但同時計算Fisher Information也降低了方法的效率,我們不可能在每次迭代的時候都重新計算估計一次Child Network。
因此,我們采用的策略是在Fine-tuning一開始的時候識別出Child Network,并在接下來的迭代中都保持不變,也就是整個Fine-tuning過程只有這部分參數會被更新,我們的實驗證明了這種近似手段同樣可以取得不錯的效果(我們曾經嘗試過在每個epoch之后重新估計一次,但是效果反而不如自始自終保持一致的這種方式)。
02—
Child-Tuning 實現僅需幾行代碼
總的來說,(在基于Adam優化器下的)Child-Tuning的偽代碼如圖4所示,最關鍵的部分在于紅框內的內容,即發現Child Network,以及根據Child Network生成梯度掩模,從而實現僅對Child Network中的參數進行更新。
具體到代碼實現層面,就只需要在原來optimizer里加入簡單幾行代碼:
for p in model.parameters(): grad = p.grad.data
## Child-Tuning_F Begin
## reserve_p = 0.2 # the ratio of gradients that are reserved. grad_mask = Bernoulli(grad.new_full(size=grad.size(), fill_value=reserve_p))grad *= grad_mask.sample() / reserve_p
## Child-Tuning_F End ## # the followings are the original code of optimizer 。。..Child-Tuning代碼已開源到阿里預訓練體系AliceMind,關于實現的更多細節可以參看:https://github.com/alibaba/AliceMind/tree/main/ChildTuning。
03—
實驗結果
我們做的實驗主要探究了微調后模型的效果和泛化性能(更多有趣實驗可以參見論文:https://arxiv.org/pdf/2109.05687.pdf):
下游任務效果
我們選取了BERT-large, XLNet-large,RoBERTa-large和ELECTRA-large四個不同的預訓練模型,并在四個GLUE基準集上的任務,即CoLA,RTE,MRPC跟STS-B上進行實驗。從下表中可以看到,相比傳統微調算法(Vanilla Fine-tuning),使用Child-Tuning的兩個不同版本(Task-Free和Task-Driven)都能帶來提高,BERT平均提升+1.5,ELETRA平均提升+8.6。
微調后模型的泛化性能
我們通過兩種不同的方式來探究模型的泛化能力:域遷移實驗(Domain Transfer)和任務遷移實驗(Task Transfer),如果模型的泛化能力更好,產生的編碼表示更具有泛化性,那么在相應的遷移實驗里邊將會在目標任務中取得更好的效果。對于域遷移實驗(Domain Transfer),我們在一個NLI數據集上Fine-tune模型,之后直接將其在其他不同的NLI數據集上進行測試。
下表展現的是在源數據集MNLI跟SNLI(為模擬少樣本情況,均降采樣到5k)遷移到其他目標數據集上的結果。可以看到,相比Vanilla Fine-tuning,Child-Tuning在目標數據集上都擁有更好的效果,這說明了使用Child-Tuning能夠有效提高模型泛化能力,防止在源數據集上過擬合。
類似地我們還進行了任務遷移實驗(Task Transfer),即在一個源任務上進行Fine-tune,之后將預訓練模型的參數凍結住,并遷移到另一個目標任務上,僅僅Fine-tune與目標任務相關的最頂層的線性分類器。下圖展示了在以MRPC為源任務,遷移到CoLA,STS-B,QNLI和QQP任務上的實驗結果,Child-Tuning相比Vanilla Fine-tuning在任務遷移實驗上同樣具有明顯的優勢,說明模型通過Child-Tuning的方法有效提高了泛化能力。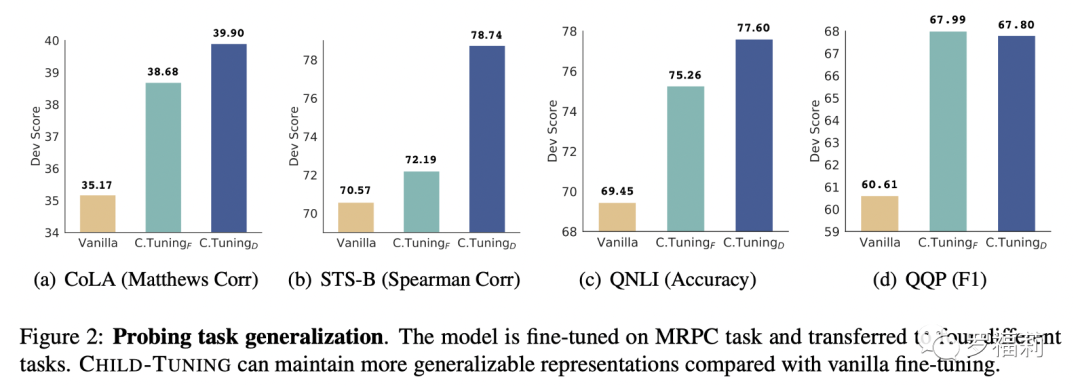
04—
小彩蛋:關于Rebuttal
這篇論文一開始的分數是4/4/3.5,經過rebuttal之后總共提高了1.5分,變成了4.5/4.5/4(滿分5分)。Reviewer主要關心的點就是本文與相關工作的區分度,比如Adapter[4],以及DIff-Pruning[5]等工作的對比。其實Child-Tuning跟這些工作還是就是有較大不同的,主要體現在:
a) 動機不同:這些工作主要聚焦于微調盡量少的參數而模型效果不會損失太多(所謂的paramter efficient learning),而Child-Tuning主要關注如何更好的提高模型的效果與泛化性能;
b) 方法不同:Adapter引入了額外的參數模塊,Diff-pruning則通過L0范數約束參數更新量,而Child-Tuning不需要額外的新模塊,只需要在模型內識別確定Child Network即可;
c) 效果不同:Adapter跟Diff-pruning僅僅取得的效果與原模型相當/可比,而Child-Tuning則明顯提升了模型在下游任務中的表現。
點評:分別從“動機-》方法-》結果”這三個方面闡釋清楚文章的貢獻的這個模板大家可以沿用到reviewer “質疑你文章novelty” 或者 “跟xxx文章很相似” 的評審意見中。From:羅福莉
當我們從這三方面做了非常詳細的clarify,充分解答了reviewer的最大疑惑之后,reviewer對我們的評價也就相應地提高了。所以,rebuttal的時候抓住reviewer最關心的(而不是回復全部的問題),才更有可能影響reviewer提分哦~
ps:文章的最后感謝本文共一的實習生 潤昕,看到你的飛速成長,比我自己發了論文還開心!期待以及相信你有更好的未來~
責任編輯:haq
-
數據
+關注
關注
8文章
6909瀏覽量
88850 -
模型
+關注
關注
1文章
3178瀏覽量
48731 -
代碼
+關注
關注
30文章
4753瀏覽量
68368
原文標題:極簡單但賊有效的Fine-tuning算法,幾行代碼最高漲點8%
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用AI大模型進行數據分析的技巧
當PLC遇上IOT網關可以解決什么問題


LLM模型和LMM模型的區別
當消費遇上AI:大模型如何成為行業“網紅”?






 工商網監
工商網監
評論