") 解決算力需求的主流方法?數(shù)據(jù)流架構(gòu)讓AI芯片利用率提升10倍以上
解決算力需求的主流方法?數(shù)據(jù)流架構(gòu)讓AI芯片利用率提升10倍以上
電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)現(xiàn)在各種應(yīng)用場(chǎng)景對(duì)算力的需求越來越大,為了滿足需求,各廠商不斷提升AI芯片的峰值算力,而傳統(tǒng)指令集架構(gòu)的芯片利用率卻難以提升,大多數(shù)在10-40%,這讓芯片的實(shí)測(cè)性能大打折扣,那么如何突破呢?
與指令集架構(gòu)不同,數(shù)據(jù)流架構(gòu)的顯著特點(diǎn)就是依托數(shù)據(jù)流的流動(dòng)次序控制計(jì)算執(zhí)行次序,而非指令執(zhí)行次序,因此把它用在AI上可以讓芯片利用率大幅提升,芯片利用率直至逼近100%。
數(shù)據(jù)流架構(gòu)如何提升芯片利用率
目前市場(chǎng)上的芯片主要有兩種架構(gòu)形式:一種是大家熟知的指令集架構(gòu),主要包括X86架構(gòu)、ARM架構(gòu)、精簡指令集運(yùn)算RISC-V開源架構(gòu),以及SIMD架構(gòu);另外一種就是數(shù)據(jù)流架構(gòu)。
指令集架構(gòu)采用馮諾依曼計(jì)算方式,通過指令執(zhí)行次序控制計(jì)算順序,并通過分離數(shù)據(jù)搬運(yùn)與數(shù)據(jù)計(jì)算提供計(jì)算通用性。數(shù)據(jù)流架構(gòu)采用數(shù)據(jù)流引擎計(jì)算,它允許編譯器同時(shí)調(diào)度多個(gè)順序循環(huán)和功能,具有更高的吞吐量和更低的延遲,顯著特點(diǎn)是能夠大幅提升芯片利用率。
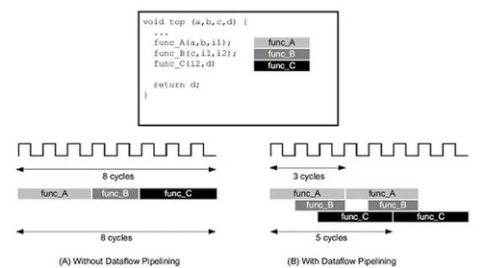
如下圖左側(cè),指令集架構(gòu)首先執(zhí)行函數(shù)A,完成之后再執(zhí)行函數(shù)B,依次類推直至執(zhí)行完所有程序。下圖右側(cè),在數(shù)據(jù)流架構(gòu)的情形下,編譯器可以安排每個(gè)函數(shù)在數(shù)據(jù)可用時(shí)立即執(zhí)行,這樣可以大大縮短等待和間隔的時(shí)間。
雖然數(shù)據(jù)流架構(gòu)沒有指令集架構(gòu)那么廣為人知,然而不可忽視的是,目前數(shù)據(jù)流架構(gòu)已經(jīng)在專用硬件中成功應(yīng)用,比如數(shù)字信號(hào)處理、網(wǎng)絡(luò)路由、圖形處理、遙感檢測(cè)、以及數(shù)據(jù)庫處理等,在許多軟件體系結(jié)構(gòu)中,包括數(shù)據(jù)庫引擎設(shè)計(jì)和并行計(jì)算框架,它也占據(jù)重要地位。
1994年,帝國理工學(xué)院教授、英國皇家工程院院士、鯤云科技聯(lián)合創(chuàng)始人和首席科學(xué)家Wayne Luk陸永青院士率先將數(shù)據(jù)流架構(gòu)定制化并運(yùn)用到AI領(lǐng)域。如今國內(nèi)外對(duì)數(shù)據(jù)流技術(shù)的關(guān)注日益增多,包括國外的SambaNova、Groq、Wave computing,以及國內(nèi)的鯤云科技。鯤云科技已經(jīng)于去年量產(chǎn)了全球首款數(shù)據(jù)流AI芯片CAISA,脫胎于斯坦福大學(xué)的SambaNova,產(chǎn)品處于小規(guī)模試用階段,而前谷歌TPU核心團(tuán)隊(duì)創(chuàng)辦的Groq,現(xiàn)在還未推出產(chǎn)品。
數(shù)據(jù)流架構(gòu)如何提升芯片利用率?我們通過全球唯一量產(chǎn)數(shù)據(jù)流AI芯片的公司鯤云科技來看一下,鯤云的核心技術(shù)就是他們的定制數(shù)據(jù)流CAISA架構(gòu),這是一款為深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)定制的高性能AI計(jì)算架構(gòu)。CAISA架構(gòu)通過數(shù)據(jù)流流動(dòng)次序來控制計(jì)算順序,消除指令操作導(dǎo)致的額外時(shí)間開銷,讓CNN網(wǎng)絡(luò)的算子級(jí)數(shù)據(jù)流圖可以實(shí)現(xiàn)高效流水線運(yùn)算。同時(shí)CAISA可并行執(zhí)行數(shù)據(jù)訪問和數(shù)據(jù)計(jì)算,進(jìn)一步減少計(jì)算單元的空閑時(shí)間,最大化地利用芯片的計(jì)算資源,從而提供更高的實(shí)測(cè)算力。
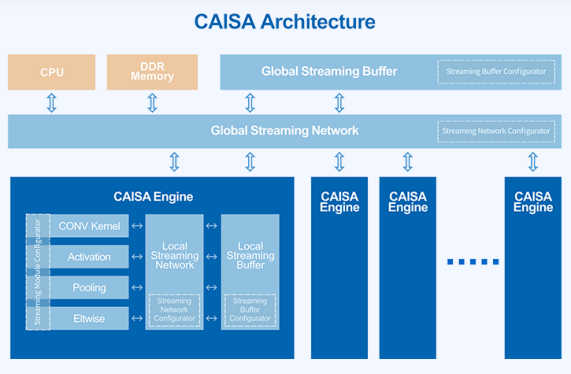
圖片來自鯤云科技官網(wǎng)
鯤云科技合伙人、首席運(yùn)營官王少軍博士在接受電子發(fā)燒友網(wǎng)采訪時(shí)表示,之所以投身于定制數(shù)據(jù)流架構(gòu)芯片的研發(fā),首先是鯤云科技有數(shù)據(jù)流架構(gòu)技術(shù)研發(fā)基礎(chǔ),公司創(chuàng)始團(tuán)隊(duì)來自數(shù)據(jù)流技術(shù)的源頭實(shí)驗(yàn)室,該實(shí)驗(yàn)室是全球三大定制計(jì)算實(shí)驗(yàn)室之一,從90年代開始就深耕數(shù)據(jù)流架構(gòu)與不同領(lǐng)域的領(lǐng)域?qū)S眉軜?gòu)研發(fā),具備深厚的研發(fā)和迭代積累。
其次更為重要的是底層芯片技術(shù)存在算力瓶頸,隨著摩爾定律發(fā)展,依靠摩爾定律提升芯片性能的成本越來越高,比如一款5nm芯片的研發(fā)成本就高達(dá)數(shù)億美元,針對(duì)特定領(lǐng)域?qū)崿F(xiàn)領(lǐng)域?qū)S眉軜?gòu)的性能獲益會(huì)越來越高,直到大幅領(lǐng)先通用計(jì)算芯片,鯤云科技認(rèn)為在算力猛增的時(shí)代,行業(yè)需要一顆高算力性價(jià)比的人工智能專用芯片,數(shù)據(jù)流架構(gòu)的重大意義在于它突破了傳統(tǒng)芯片架構(gòu)對(duì)芯片利用率的約束,最大化發(fā)揮芯片本身的峰值性能。
因此鯤云科技在早期數(shù)據(jù)流架構(gòu)技術(shù)的積累下,針對(duì)人工智能領(lǐng)域開發(fā)出CAISA架構(gòu),并最終實(shí)現(xiàn)從0到1完成首顆數(shù)據(jù)流AI芯片量產(chǎn)。
鯤云CAISA芯片利用率高達(dá)95.4%
鯤云科技于去年6月正式量產(chǎn)了全球首款數(shù)據(jù)流AI芯片CAISA,芯片利用率達(dá)到95.4%,面向數(shù)據(jù)中心和邊緣端AI推斷應(yīng)用,該芯片采用28nm工藝,這個(gè)制程并不高,不過因?yàn)樾酒寐矢撸词乖诒容^低的制程情況下,CAISA芯片也可以帶來很高的實(shí)測(cè)性能。

同時(shí)鯤云科技還基于CAISA芯片推出三款高性能計(jì)算平臺(tái),包括面向邊緣端的星空X3加速卡、面向數(shù)據(jù)中心的星空X9加速卡、面向邊緣AI應(yīng)用的星空X6A邊緣小站。星空X3加速卡面向8-16路視頻實(shí)時(shí)結(jié)構(gòu)化分析,星空X6A邊緣小站面向8路視頻處理應(yīng)用。
目前CAISA芯片及加速卡產(chǎn)品已在多領(lǐng)域?qū)崿F(xiàn)應(yīng)用,包括智慧安監(jiān)、智能制造、智慧電力、智慧城市等。王少軍博士認(rèn)為,對(duì)于這些場(chǎng)景,特別是國民生產(chǎn)支柱行業(yè)而言,“降本增效”是剛需,比如在油田的應(yīng)用場(chǎng)景,傳統(tǒng)的安防監(jiān)控系統(tǒng)已經(jīng)比較成熟,端側(cè)的攝像頭監(jiān)控系統(tǒng)基本部署完成,但視頻結(jié)構(gòu)化利用率低,單純依靠人工巡檢,作業(yè)區(qū)域廣,環(huán)境復(fù)雜,耗時(shí)長,數(shù)據(jù)采集維度單一,人工識(shí)別難度大,而且預(yù)警不及時(shí),漏報(bào)概率高,事后取證難。
針對(duì)這些行業(yè)痛點(diǎn),鯤云科技提供算法算力平臺(tái)一體化方案,基于數(shù)據(jù)流AI芯片的底層算力優(yōu)勢(shì),以及算力和算法聯(lián)合優(yōu)化的技術(shù)優(yōu)勢(shì),對(duì)現(xiàn)場(chǎng)接入的500路視頻進(jìn)行數(shù)據(jù)處理,對(duì)漏油、安全帽、工服、抽煙、打電話、人員闖入和采油設(shè)備運(yùn)行狀態(tài)進(jìn)行識(shí)別,可以做到從視頻流獲取到輸出報(bào)警時(shí)間為1s,為油區(qū)的生產(chǎn)情況提供更可靠的安全保障。在油田智能化升級(jí)過程中,數(shù)據(jù)流AI芯片就凸顯出了其市場(chǎng)價(jià)值,可以充分利舊、快速部署、控制成本。
未來解決算力需求的主流方法
數(shù)據(jù)流AI芯片的商用落地,證實(shí)了數(shù)據(jù)流和深度學(xué)習(xí)融合的價(jià)值,王少軍博士認(rèn)為數(shù)據(jù)流架構(gòu)具備成為下一代計(jì)算平臺(tái)的潛力。他談到,在計(jì)算平臺(tái)的演進(jìn)過程中,十倍核心性能指標(biāo)的提升,是計(jì)算架構(gòu)代際更替的主要指標(biāo),比如,從X86到RISC計(jì)算平臺(tái),能效比提升了10倍以上;從X86到CUDA計(jì)算平臺(tái),峰值算力也提升了超過10倍。
從歷史脈絡(luò)來看,相對(duì)上一代主流算力平臺(tái),新的算力平臺(tái)在某個(gè)指標(biāo)上需要高出10倍,才能實(shí)現(xiàn)實(shí)測(cè)性能的大幅提升,隨著摩爾定律的放緩,業(yè)界越來越關(guān)注下一代芯片應(yīng)該如何發(fā)展,而底層架構(gòu)創(chuàng)新是這幾年業(yè)界的共識(shí),行業(yè)需要新的技術(shù)路線來實(shí)現(xiàn)底層算力的突破。
王少軍博士認(rèn)為,下一代有望帶來10倍以上突破的指標(biāo)就是芯片利用率,這可能是未來解決算力需求的主流方法,而數(shù)據(jù)流架構(gòu)可以實(shí)現(xiàn)這一點(diǎn),鯤云科技認(rèn)為未來會(huì)有更多新興AI芯片廠商加入到數(shù)據(jù)流AI技術(shù)路線中。對(duì)于現(xiàn)有芯片廠商來說,技術(shù)路線的選擇是公司的一大核心戰(zhàn)略,而其已有的開發(fā)生態(tài)和技術(shù)積累使其很難轉(zhuǎn)換賽道,但有些玩家也看到了數(shù)據(jù)流技術(shù)的價(jià)值,比如英偉達(dá)就推出了TensorCore,在指令集架構(gòu)的基礎(chǔ)上,該模塊采用了數(shù)據(jù)流技術(shù)的原理,來提升其在特定領(lǐng)域的芯片利用效率。
總結(jié)
整體來說,數(shù)據(jù)流架構(gòu)可以大幅提升芯片利用率,鯤云定制數(shù)據(jù)流CAISA新芯片的量產(chǎn)商用,也證實(shí)了數(shù)據(jù)流與深度學(xué)習(xí)融合的價(jià)值,給AI帶來了一個(gè)新的技術(shù)研究方向,相信未來會(huì)有更多AI芯片廠商加入到數(shù)據(jù)流架構(gòu)技術(shù)的研究中。
現(xiàn)在AI芯片在很多場(chǎng)景都有落地剛需,尤其在邊緣端,很多場(chǎng)景還存在“碎片化”需求,因此廠商除了考慮提升芯片利用率,做到更高算力性價(jià)比之外,還需要思考如何提升更通用、軟件易用性等,全面提升芯片性能,促進(jìn)專用AI芯片規(guī)模化量產(chǎn),賦能各產(chǎn)業(yè)智能化升級(jí)。
-
鯤云科技
+關(guān)注
關(guān)注
0文章
29瀏覽量
3810 -
算力
+關(guān)注
關(guān)注
1文章
936瀏覽量
14750
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
理解ECU數(shù)據(jù)流的分析方法
華納云:什么是負(fù)載均衡?優(yōu)化資源利用率的策略
交換機(jī)內(nèi)存利用率過高會(huì)是什么問題
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析
今日看點(diǎn)丨小鵬自研芯片流片!算力是同行三倍;加拿大將對(duì)中國電動(dòng)汽車征收100%關(guān)稅

異構(gòu)混訓(xùn)整合不同架構(gòu)芯片資源,提高算力利用率
DC/AC電源模塊:提升光伏發(fā)電系統(tǒng)的能源利用率

NAND Flash供應(yīng)商產(chǎn)能利用率提升,今年有望盈利
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發(fā)效率提升10倍
臺(tái)積電晶圓廠產(chǎn)能利用率將全面提高
產(chǎn)能利用率降至四成!電池行業(yè)迎深度洗牌
淺談為AI大算力而生的存算-體芯片

產(chǎn)能利用率低迷,傳臺(tái)積電7nm將降價(jià)10%!
SPWM與SVPWM—調(diào)制比與電壓利用率






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論