 技術文章分享-基于FPGA及深度學習的人臉檢測系統設計
技術文章分享-基于FPGA及深度學習的人臉檢測系統設計
第一部分 設計概述
1.1 設計目的
新冠病毒的肆虐讓整個 2020 年籠罩在恐慌之中,戴口罩成了人們外出必備 的“新日常”。新冠病毒主要通過飛沫傳播和接觸傳播,正確選擇佩戴口罩,可有效阻隔病毒傳播。但在人流量龐大的商圈、車站等場所,仍有許多人拒絕佩戴口罩。若能在這些場所進行當前人群口罩檢測,則能有效避免冠狀病毒的傳播。
本作品是一種能實時檢測識別人臉口罩佩戴情況并進行語音播報的系統,準確度高達 95.2%,系統處理速度可達 25fps 左右。除此之外,本作品具備較高的可拓展性,稍加更改就可在更多的領域得到應用。
1.2 應用領域
基于深度學習的人臉捕獲及口罩檢測系統可以適用于人流量大的場所,實現 了人臉檢測與跟蹤以及人臉口罩識別的功能,并將識別結果進行播報,可以輔助疫情防控工作的開展。
除此之外,本系統的人臉檢測系統有著廣泛的應用范圍。
在智能家居領域,可以通過我們的系統實現人類闖入報警裝置,在攝像頭捕捉到的區域檢測到人臉后觸發報警;
在新冠疫情期間,我們的系統可以安裝在商圈、旅游景點,實時檢測人流密度,為實時限流措施提供參考。
1.3 主要技術特點
對密集人群進行口罩檢測,首先要在畫面中進行人臉檢測。在非深度學習階段的目標檢測算法都是針對特定目標提出的,比如 CVPR 2001 的 Viola-Jones (VJ)[1]是針對人臉檢測問題,CVPR 2005 的 HOG+SVM[2]是針 對行人檢測問題,TPAMI 2010 的 DPM[3]雖然可以檢測各類目標,但要用于多目標檢測,需要每個類別分別訓練模板。而強大的深度學習只要一個 CNN 就可以 搞定多類別檢測任務。雖然這些都是多類別方法,但它們也都可以用來解決單類別問題。
本作品是基于深度學習的人臉捕獲及口罩檢測系統,通過片外的圖像傳感器采集圖像到片上緩沖區,而后把圖像送到 FPGA 上的神經網絡加速器進行處理, 識別結果輸出到顯示器,在顯示器中框出人臉并顯示目標是否佩戴口罩,我們還使用語音模塊對畫面中的總人數和未戴口罩人數作出播報。
1.4 關鍵性能指標
本作品可以實時檢測識別人臉口罩佩戴情況,我們從幀率和精度兩個方面進行了分析。識別精度可達到 95.2%,而系統延遲僅僅 40ms 左右,可達到 25fps 的幀率。
1.5 主要創新點
神經網絡部分創新點
1、使用了一個輕量級 backbone,去除了 BN 層,在精度達到優秀的前提下極大提升了速度;
2、去掉了 FPN 結構,僅降低微小的精度卻大大提升了速度(20%);
3、在網絡的 head 部分對邊框回歸和類別預測做了不對稱設計,進一步提升性能。
系統框架創新點
1、為了加快系統設計,采用了 Xilinx 專用于卷積神經網絡的深度學習處理單元(DPU)。在設計系統過程中,可根據系統的具體情況配置 DPU 的參數,將該 IP 集成到所選器件 PL 中,通過 PS 端軟件控制,實現多種卷積神經網絡的加速。
2、利用 PYNQ 框架,可以在開發板上動態地加載比特流實現系統所需硬件電路,靈活方便。
3、利用 Vitis AI 編譯模型,將浮點模型轉換為定點模型,降低了計算復雜度,并且需要的內存帶寬更少,提高了模型速度。
第二部分 系統組成及功能說明
2.1 整體介紹
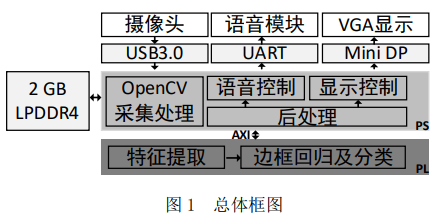
基于深度學習的人臉檢測系統由 PS 端、PL 端與外設及其接口組成。其中, 外設包括、攝像頭(通過 USB3.0 連接)、語音模塊(通過 UART 連接)和 VGA 顯示(通過 Mini DP 轉 VGA 連接),開發板內部還提供了 2GB 的 LPDDR4;PS 端包括 openCV 采集處理模塊、后處理模塊、語音控制模塊及顯示控制模塊;PL 端包括特征提取模塊和邊框回歸及分類模塊。
在 PS 端的模塊中,openCV 采集處理模塊的主要功能是控制攝像頭采集圖像,并對 LPDDR4 中的圖像進行預處理;后處理模塊的主要功能是使用非極大值抑制(Non-Maximum Suppression, NMS)算法對候選區域進行篩選,得到合適的區域信息并統計畫面中檢測到的人臉總數;
語音控制和顯示控制驅動語音模塊和攝像頭構成結果展示部分,語音控制模塊根據后處理模塊的結果播報當前畫面中的人臉數目,而顯示控制模塊根據 VGA 時序顯示拍攝畫面并框出人臉位置。PL 端中的特征提取模塊對預處理后的圖像進行計算,得到大小不同的區域,邊框回歸及分類模塊處理這些區域,給出邊框信息與分類結果。
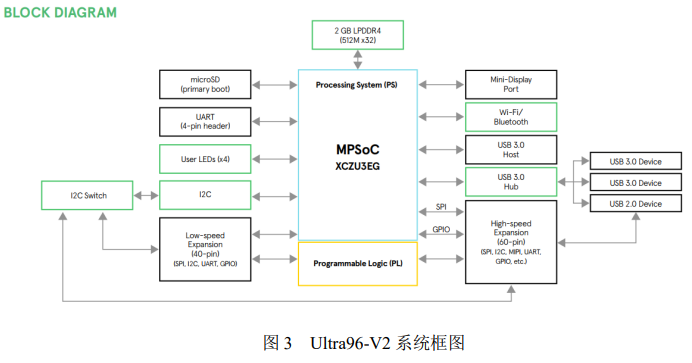
本系統的開發平臺為 Ultra96-V2 開發板,是基于 FPGA 的 Xilinx Zynq UltraScale +MPSoC 開發板,并基于 Linaro 96Boards Consumer Edition(CE)規范構建。
Ultra96-V2 開發板系統框圖如下圖所示:
2.2 各模塊介紹
OpenCV 采集處理
本系統采用的是超微 1601U 攝像頭上圖所示,輸出圖像大小為 1280×720, 最高幀率可達 30fps。該攝像頭通過 USB3.0 接口與開發板連接,輸出圖像的數據格式支持 MJPEG 和 YUV 格式。它還支持自動曝光控制 AEC 和自動白平衡 AEB,可以調節亮度、對比度、色飽和度、色調等基礎參數。
通過系統 PS 端的 OpenCV 來完成攝像頭相關參數的配置以及圖像幀的獲取, 之后對獲取的圖像進行resize等預處理再送到PL部分的深度學習處理單元(DPU)進行處理。
后處理
對于一幀圖像,該模塊接收到來自神經網絡檢測模塊的 3780 個候選框信息 (包括邊框坐標、識別標簽、置信度)。后處理模塊首先對這些候選框進行篩選, 留下置信度大于 0.6 的候選框。這一步可以減少無效候選框的處理時間。接著, 我們使用非極大值抑制算法對通過篩選的候選框進行處理,去除重復的候選框, 得到最優結果。最后將結果輸出給結果展示部分。
非極大值抑制,顧名思義就是抑制不是極大值的元素,可以理解為局部最大 搜索。這個局部代表的是一個鄰域,鄰域有兩個參數可變,一是鄰域的維數,二是鄰域的大小。例如在行人檢測中,滑動窗口經提取特征,經分類器分類識別后, 每個窗口都會得到一個分數。但是滑動窗口會導致很多窗口與其他窗口存在包含或者大部分交叉的情況。這時就需要用到 NMS 來選取那些鄰域里分數最高(是行人的概率最大),并且抑制那些分數低的窗口。
結果展示部分——語音控制
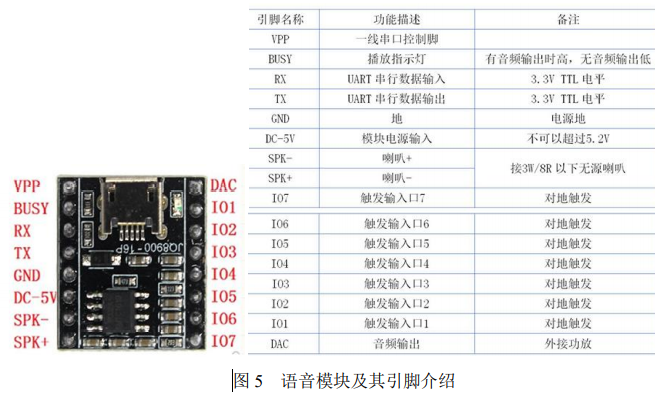
本系統中語音模塊的功能是在系統檢測完畢且后處理模塊統計畫面人數后, 將檢測結果通過語音的方式播報給外界。語音模塊 JQ8900-16P 選用了 SoC 方案, 集成了一個 16 位的 MCU,能夠靈活更換 SPI-flash 內的語音內容,有一線串口控制模式和 RX232 串口控制模式可選。
由于開發板上有多個 USB 接口,我們采用 USB 轉串口的方式來控制語音模塊。具體控制方式為把檢測到的人數轉化為語音模塊的控制指令,通過串口發送到該模塊,語音模塊對指令進行解碼之后播報存放在該模塊內的相應音頻。
結果展示部分——顯示控制
經過神經網絡處理之后的圖像由開發板上的 Mini DP 接口外接 Mini DP 轉 VGA 轉接頭,連接到 VGA 顯示器進行顯示。
識別模塊
本系統中卷積神經網絡模塊的功能是對攝像頭采集圖像中的人臉進行檢測并判斷目標人臉上是否佩戴口罩,是系統的核心模塊。本小節將從數據集的制作、 特征提取模塊、軟件模型設計和硬件模型設計等四個方面介紹該模塊。
(1)數據集的制作
數據集主要來自于 WIDER Face 和 MAFA 數據集,加入了上百張戴口罩的 圖片(來源于網絡)。具體地,我們從 WIDER Face 中篩選出 7000 張,從 MAFA 中篩選出 2000 張,自己根據已有的戴口罩的數據集生成了 2000 張左右,最終分為訓練集 13000 張,測試集 300 張。值得一提的是,在我們自己生成的數據集圖片中,有許多是將有口罩的圖片與無口罩的圖片的組合,如圖 6 最右所示,因為在經典數據集中很難找到這樣的情況。
2)神經網絡模型的搭建和訓練
本系統采用的目標檢測算法為 anchor-base 的 one-stage 算法,整個網絡參考 了 RetinaNet[4]進行設計,可分為 backbone、neck、head 三大部分。其中,backbone 參考 BlazeFace[5]的設計去掉了 BN 層,這樣能在不影響準確率的前提下提高速度。
在 RetinaNet 的 neck 部分中,FPN[6]有很好的特征提取功能,引入 FPN 能解決較為復雜的問題。但由于 FPN 需要額外的卷積計算,它也在一定程度上降低了速度。由于本次應用只有兩個類別,有口罩和無口罩,識別困難度比較低,我們參考了 SSD[7]的結構,去掉 FPN 部分,僅用一個卷積層調整通道。對于 head 部分, 由于只有兩個類別,我們減少了 class 分支的卷積層,不再與 boxes 分支對稱。減少卷積層并沒有引起精度下降,但進一步提升了速度。
我們 anchor 設置如下:
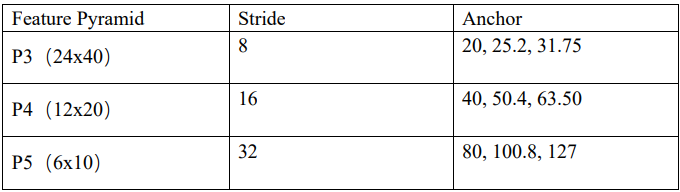
總共有(24×40+12×20+6×10)×3=3780 個 anchor,最小尺寸為 20,最大尺 寸為 127。
整體網絡框架如下所示:
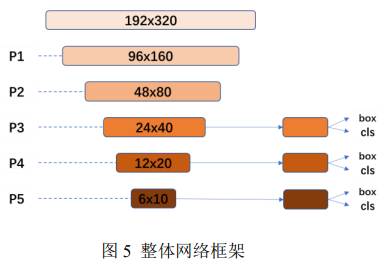
整體網絡可分為兩部分——特征提取模塊與邊框回歸及分類模塊。
對于特征提取模塊的處理如圖 6 所示。令輸入圖像為 P0,其尺寸為 192×320;P1 由 P0 經過一個卷積層和兩個 blaze_block 得到,P1 經過三個 blaze_block 得到 P2 ;P3 由 P2 經 過 三 個 double_blaze_block 得來, P4 由 P3 經過三個 double_blaze_block 得來,P5 由 P4 經過三個 double_blaze_block 得來。P3、P4 和 P5 是本模塊的輸出,即識別模塊的輸入。
其中 blaze_block 由 DepthwiseConv2D + Conv2D + MaxPool2D + Add 組成,double_blaze_block 由 DepthwiseConv2D + Conv2D + DepthwiseConv2D + Conv2D + MaxPool2D + Conv2D + Add 組成。各層 參數詳見本文附錄中軟件模型的源代碼。
邊框回歸及分類模塊對 P3、P4、P5 進行分析。RetinaNet 類別分支和邊框分 支分別采用了四個卷積層,本設計采用了 RetinaNet 的 head 設計思想,但是進行 了改進:我們減少了卷積層的數量,邊框分支采用三個卷積層,類別分支采用兩個卷積層。因為只有兩個類別,所以我們的類別分支和邊框分支采用了不對稱設計,將類別分支的卷積層進一步減少。減少類別分支的卷積層對準確率幾乎沒有影響,但提升了速度。
(3)硬件部分
該部分利用支持 PYNQ 框架的開發板鏡像。首先通過在開發板上加載帶 Xilinx 的 DPU IP 的比特流文件,把 DPU 燒寫到開發板的 PL 端;再通過安裝在開發板鏡像上的 DPU 驅動,調用相應的 API 把經過 Vitis AI 編譯過的模型部署到 DPU 中;最后啟動 DPU 讀取預處理之后的圖像進行檢測和分類,DPU 運算完之后取出運算結果,對運算結果進行解析之后得到人臉框的坐標以及是否佩戴口罩的分類結果。
第三部分 完成情況及性能參數
3.1 完成情況
本系統目前可以實現:
實時檢測并跟蹤人臉位置,人臉位置被框出;
人臉檢測框上方給出目標是否戴口罩 mask/nomask 以及置信度;
定時對當前人數與未佩戴口罩人數進行語音播報。
3.2 人臉檢測性能指標
本系統基于人臉捕捉及口罩識別的應用對 RetinaNet 進行優化,并利用硬件加速,大大提升了處理速度。目前該系統可對 192×320 大小的三通道彩色視頻進行實時處理,幀率可達 25fps,精度可達 95.2%。
第四部分 總結
可擴展之處
目前系統圖像采集時間占總體時間的比例比較大,后期可探索更多軟硬件優化的方法對圖像采集部分進行優化,提升系統幀率。除此之外,目前我們的應用是進行口罩(人臉)的檢測,未來可在此基礎上進行拓展加入識別模型,識別模型可以精確識別出是哪一個人,這樣可將應用范圍進一步拓展,比如說門禁的人臉識別、簽到、智能監控等等。
作品來源:Xilinx開源社區,已授權,作者:韋社年、朱庭威、張華蕾。
編輯:jq
-
FPGA
+關注
關注
1626文章
21678瀏覽量
602018 -
人臉檢測
+關注
關注
0文章
80瀏覽量
16443 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998
原文標題:基于 FPGA 及深度學習的人臉檢測系統設計
文章出處:【微信號:HXSLH1010101010,微信公眾號:FPGA技術江湖】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何用OpenCV的相機捕捉視頻進行人臉檢測--基于米爾NXP i.MX93開發板
深度偽造人臉檢測項目






 工商網監
工商網監
評論