 TFRT為ML模型提供更快、更便宜的執行
TFRT為ML模型提供更快、更便宜的執行
大約兩年前,我們發布了一項全新機器學習 (ML) 運行時工作:TFRT(TensorFlow 運行時的簡稱)。同時,我們提供了初始技術設計的深度教程,并將其代碼庫開源。
在 ML 生態系統趨勢的推動下——模型越來越大,ML 被部署到更多樣化的執行環境,以及跟上持續研究和模型創新的需求——我們啟動了 TFRT,希望可以實現以下目標:
為 ML 模型提供更快、更便宜的執行
實現更靈活的部署
提供更多模塊化的可擴展基礎架構,以促進 ML 基礎架構和建模方面的創新
本文,我們將分享截至目前所取得的進展、在過去兩年的開發過程中收獲的經驗和教訓,以及未來的規劃。
目前所取得的進展
過去兩年的開發主要集中于通過為用戶啟用 Google 最重要的內部工作負載(比如 Ads 和搜索),來實施和驗證我們的想法。迄今為止,我們已經在 Google 內部廣泛部署了 TFRT,用于各種訓練和推斷工作負載,并取得了很好的結果。
技術經驗
我們是如何實現上述目標的?除了原始設計中的經驗,我們還收獲了一些有趣的技術經驗:
首先,異步支持對于一些關鍵的工作負載(例如重疊計算和 I/O,以及驅動異構設備)十分重要,而快速同步執行對許多其他工作負載至關重要,包括小型“嵌入式”ML 模型。
我們花費了大量精力設計和改進 AsyncValue,這是 TFRT 中的一個關鍵低級抽象,它允許主機運行時異步驅動設備以及調用內核。由于它能夠在主機和設備間重疊更多的計算和通信,從而可以使設備利用率提高。例如,通過將模型拆分為多個階段并使用 TFRT 來將下一階段的變量傳輸與當前階段的 TPU 計算重疊,我們能夠以高性能在一個 TPU 芯片上成功運行 80B 參數模型的批量推理。
另一方面,在應用進程中(而不是通過 RPC/REST 調用)調用嵌入在應用服務器里的小型 CPU 模型,對 Google 的一些來自用戶的商業工作負載(例如 Ads)仍然十分重要。對于這些模型,TFRT 的異步優先內部設計一開始導致了性能和資源衰退。我們與 Ads 團隊合作,通過使用同步解釋器擴展 TFRT 設計以及實驗性內存規劃優化,成功解決了該問題,避免了內核執行期間的堆分配。我們正在努力將此擴展產品化。
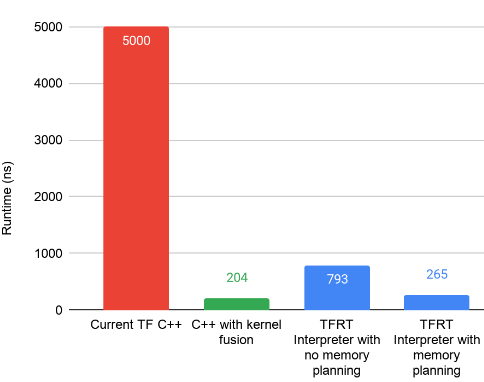
下圖展示了由此產生的 TFRT 設計對基準測試的影響,通過與在部署 TFRT 之前運行舊運行時的“當前 TF”對比。這個基準測試專注于執行微型 CPU 模型,其中大量的小型 matmul 按順序執行。值得注意的是,TFRT 中的優化執行 (265 ns) 正接近我們設置的最佳基線 (204 ns),它通過手寫 C++ 代碼執行,從而沒有任何 ML 運行時開銷。
其次,雖然更快的運行時執行很重要,但是優化輸入程序以降低執行復雜度也很重要。
請注意,雖然應盡可能在將 TF SavedModel 保存到磁盤時執行基于編譯器的圖優化,但也有一些重要的推理時編譯器優化只能在推理上下文中執行(例如,在訓練變量保持不變時)。
當我們將 ML 模型加入 TFRT 時,我們可以在執行之前深入檢查一些模型,并確定重寫和簡化程序的新方法。簡化的程序,以及計算圖程序中每個內核的更快速執行,在縮短執行延遲時間和減少資源成本方面產生了很好的復合效果。
例如,在下面左側的計算圖程序中,我們能夠提升標量算子歸一化計算(例如,將浮點值除以其域的最大值),這 18 個用于形成“concat”算子的輸入標量均相同,因而我們對串聯 1D 浮點張量啟用歸一化矢量執行。
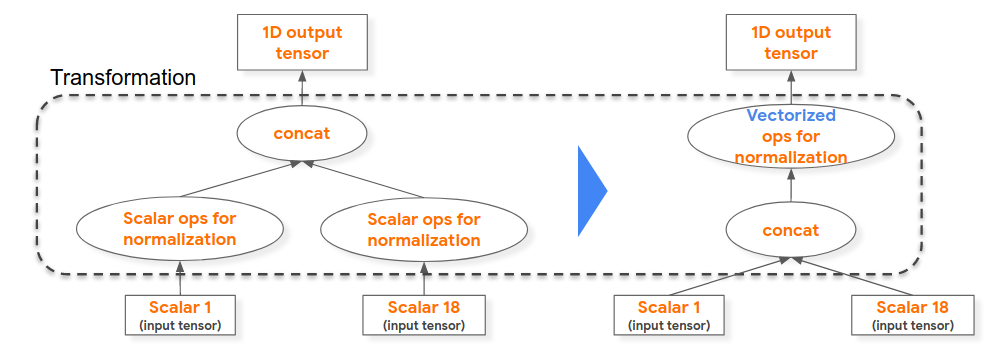
雖然也可以在模型訓練時執行此優化,但用于生成訓練模型的編譯器+運行時不包括此優化。
此外,我們還發現,盡可能將計算從模型執行時間提升到加載時間至關重要(例如,const 折疊)。
再者,基于成本的執行不僅僅適用于 SQL 查詢。
我們為 TF 算子內核開發了一個簡單的編譯時成本模型(類似于 SQL 查詢優化器的成本模型),并為 ML 模型執行應用了基于成本的優化(參見流分析),同時在一組線程池線程間實現了更好的內核執行負載平衡。相比之下,TF1 有一個基于運行時的成本模型,其中每個操作的運行時成本都被分析并用于指導該操作的調度。在 TFRT 中,我們將成本分析移至編譯時,從而消除了運行時成本。此外,我們的編譯器方法可以分析整個計算圖,從而產生在更全局范圍內最佳的調度決策。
有關數據和 ML 基礎架構之間的更多相似之處,請觀看此技術講座。
展望未來
雖然我們確實取得了一些不錯的進展,尤其是在我們的第一個目標,即追求更快更經濟的執行上,但我們承認,在實現更模塊化的設計和通過硬件集成實現更靈活的部署方面,仍道阻且長。
在模塊化方面,隨著 JAX 采用 TFRT 設備運行時(例如 CPU)等初始集成成功,我們將繼續探索 TFRT 可以如何支持 TensorFlow 之外的工作負載。我們希望部分 TFRT 組件未來也將有利于 PyTorch/XLA 工作負載的發展。
此外,我們成功集成了 CPU 和 TPU(下一步是集成到 Cloud TPU 中),即 Google 用于 ML 計算的兩種最重要的設備類型,NVIDIA GPU 集成也正在進行中。
在訓練工作負載方面,TFRT 已被用作 Google 大規模分布式訓練框架的基本模塊,目前正在積極開發中。
展望未來,我們的組織一直在探索與 Pixel 的硬件 SOC 設備(例如 Google Tensor)的集成。此外,由于 TFRT 已被成功證明可用于 Google 的內部工作負載,它也被集成到 GCP 的 Vertex AI 和 Waymo 等新場景。
特別致謝
TFRT 團隊非常享受致力于在這個新基礎架構項目上的工作。它讓人感覺像是在引導一家新的初創公司。在此,我們想向在這非凡的 2 年旅程中為 TFRT 提供建議、作出貢獻和給予支持的每個人高聲致謝:
(按字母順序)Adi Agrawal、Andrew Bernard、Andrew Leaver、Andy Selle、Ayush Dubey、Bangda Zhou、Bramandia Ramadhana、Catherine Payne、Ce Zheng、Chiachen Chou、Chao Xie、Christina Sorokin、Chuanhao Zhuge、Dan Hurt、Dong Lin、Eugene Zhulenev、Ewa Matejska、Hadi Hashemi、Haoliang Zhang、HanBin Yoon、Haoyu Zhang、Hongmin Fan、Jacques Pienaar、Jeff Dean、Jeremy Lau、Jordan Soyke、Jing Dong、Juanli Shen、Kemal El Moujahid、Kuangyuan Chen、Mehdi Amini、Ning Niu、Peter Gavin、Phil Sun、Pulkit Bhuwalka、Qiao Zhang、Raziel Alvarez、Russell Power、Sanjoy Das、Shengqi Zhu、Smit Hinsu、Tatiana Shpeisman、Tianrun Li、Tim Davis、Tom Black、Victor Akabutu、Vilobh Meshram、Xiao Yu、Xiaodan Song、Yiming Zhang、YC Ling、Youlong Chen 和 Zhuoran Liu。
我們還要特別感謝 Chris Lattner 在引導這個項目上提供的初始技術領導、Martin Wicke 在第一年對 TFRT 的支持、Alex Zaks 在第二年對 TFRT 的支持以及見證其有效地登陸 Google 的 ML 服務工作負載。
原文標題:TFRT 進展與更新
文章出處:【微信公眾號:谷歌開發者】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
嵌入式
+關注
關注
5046文章
18821瀏覽量
298594 -
Google
+關注
關注
5文章
1748瀏覽量
57189 -
cpu
+關注
關注
68文章
10702瀏覽量
209390
原文標題:TFRT 進展與更新
文章出處:【微信號:Google_Developers,微信公眾號:谷歌開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
更快更便宜,5G更適合物聯網應用
如何讓包含嵌入式軟件的復雜電子設備更便宜更可靠?
eIQ軟件對ML模型有何作用
介紹一種Arm ML嵌入式評估套件
新型電池技術為電子、混合動力車帶來更便宜的能源(圖)
如何讓嵌入式軟件的復雜電子設備更便宜更可靠?
雷蛇發布更便宜的靈刃15,稱價格無法拒絕
松下擬最早2021年試生產特斯拉更便宜的新型電池
TFRT的開源代碼分析

NVIDIA創建physics-ML模型
OpenAI推出更快更便宜的大語言模型GPT-4o
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜






 工商網監
工商網監
評論