 RNN以及LSTM
RNN以及LSTM
熟悉深度學習的朋友知道,LSTM是一種RNN模型,可以方便地處理時間序列數據,在NLP等領域有廣泛應用。
在看了臺大李宏毅教授的深度學習視頻后,特別是介紹的第一部分RNN以及LSTM,整個人醍醐灌頂。
0. 從RNN說起
循環神經網絡(Recurrent Neural Network,RNN)是一種用于處理序列數據的神經網絡。相比一般的神經網絡來說,他能夠處理序列變化的數據。比如某個單詞的意思會因為上文提到的內容不同而有不同的含義,RNN就能夠很好地解決這類問題。
1. 普通RNN
先簡單介紹一下一般的RNN。其主要形式如下圖所示(圖片均來自臺大李宏毅教授的PPT):
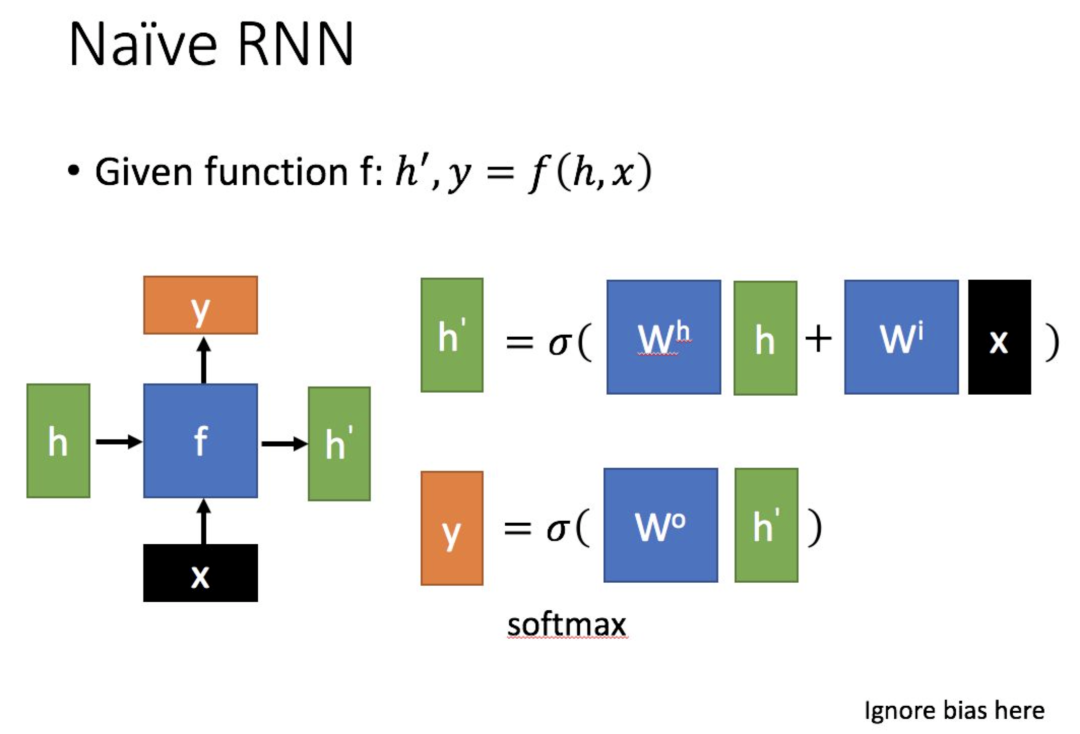
這里:
為當前狀態下數據的輸入,表示接收到的上一個節點的輸入。
為當前節點狀態下的輸出,而為傳遞到下一個節點的輸出。
通過上圖的公式可以看到,輸出 h'與 x 和 h 的值都相關。
而 y 則常常使用 h'投入到一個線性層(主要是進行維度映射)然后使用softmax進行分類得到需要的數據。
對這里的y如何通過 h'計算得到往往看具體模型的使用方式。
通過序列形式的輸入,我們能夠得到如下形式的RNN。
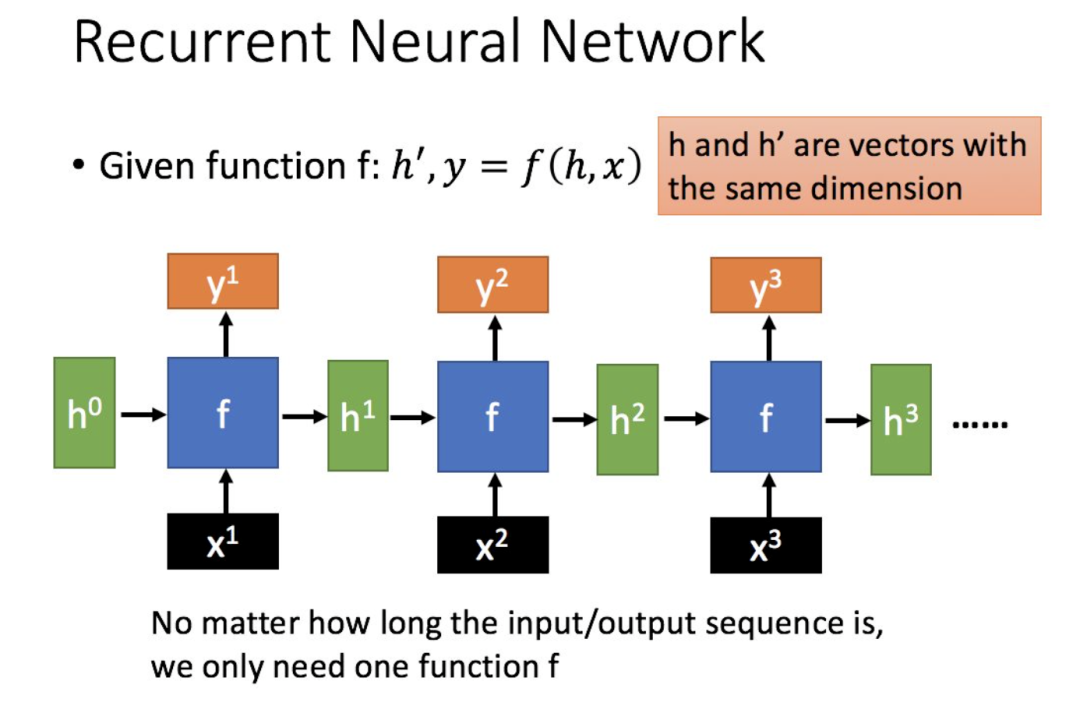
2. LSTM
2.1 什么是LSTM
長短期記憶(Long short-term memory, LSTM)是一種特殊的RNN,主要是為了解決長序列訓練過程中的梯度消失和梯度爆炸問題。簡單來說,就是相比普通的RNN,LSTM能夠在更長的序列中有更好的表現。
LSTM結構(圖右)和普通RNN的主要輸入輸出區別如下所示。
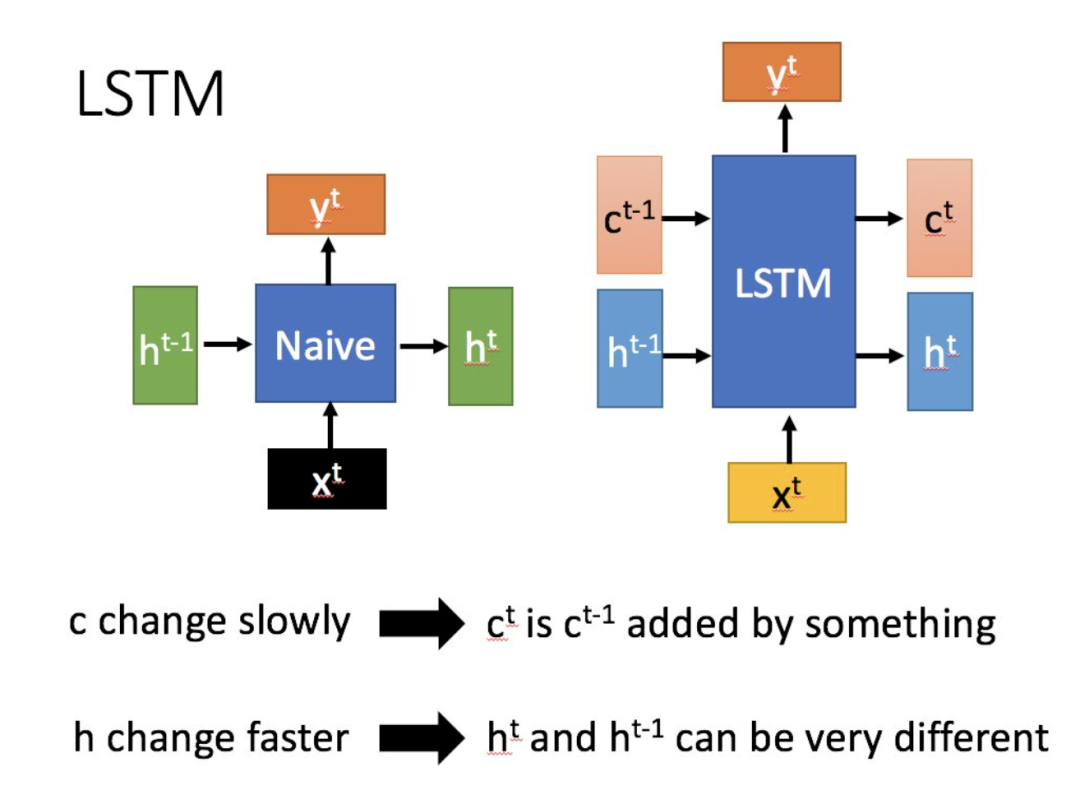
相比RNN只有一個傳遞狀態,LSTM有兩個傳輸狀態,一個(cell state),和一個(hidden state)。RNN中的等價于LSTM中的。
其中對于傳遞下去的改變得很慢,通常輸出的是上一個狀態傳過來的加上一些數值。
而則在不同節點下往往會有很大的區別。
2.2 深入LSTM結構
下面具體對LSTM的內部結構來進行剖析。
首先使用LSTM的當前輸入和上一個狀態傳遞下來的拼接訓練得到四個狀態。
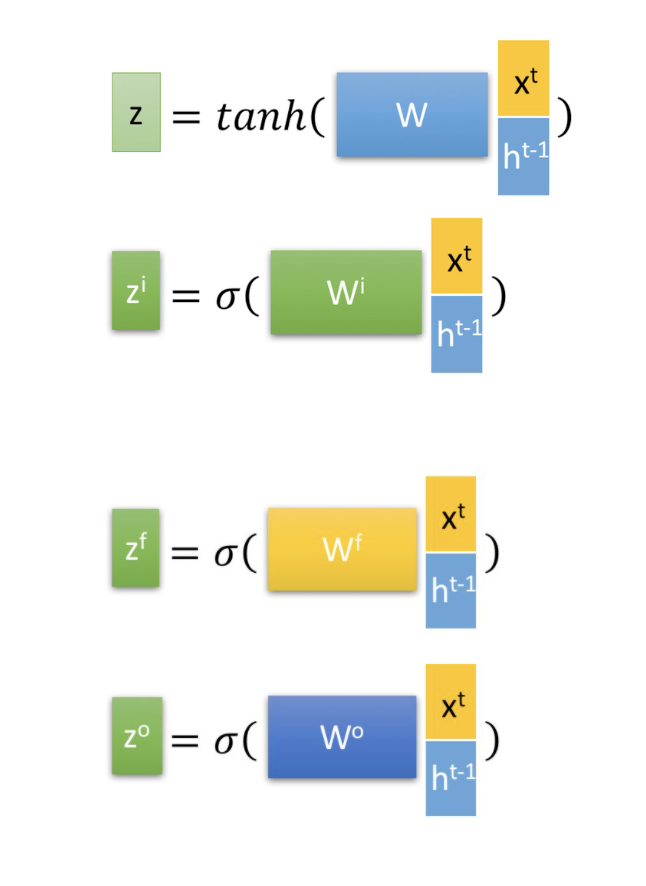
其中,,是由拼接向量乘以權重矩陣之后,再通過一個 sigmoid激活函數轉換成0到1之間的數值,來作為一種門控狀態。而則是將結果通過一個 tanh激活函數將轉換成-1到1之間的值(這里使用 tanh是因為這里是將其做為輸入數據,而不是門控信號)。
下面開始進一步介紹這四個狀態在LSTM內部的使用(敲黑板)
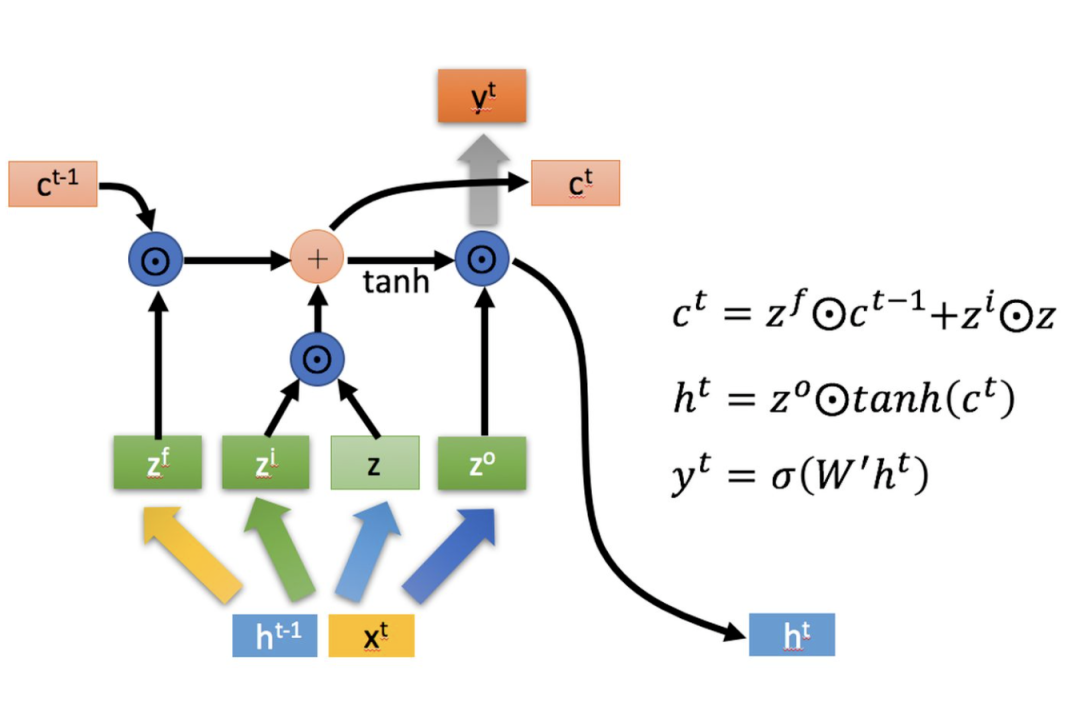
是Hadamard Product,也就是操作矩陣中對應的元素相乘,因此要求兩個相乘矩陣是同型的。則代表進行矩陣加法。
LSTM內部主要有三個階段:
1. 忘記階段。這個階段主要是對上一個節點傳進來的輸入進行選擇性忘記。簡單來說就是會 “忘記不重要的,記住重要的”。
具體來說是通過計算得到的(f表示forget)來作為忘記門控,來控制上一個狀態的哪些需要留哪些需要忘。
2. 選擇記憶階段。這個階段將這個階段的輸入有選擇性地進行“記憶”。主要是會對輸入進行選擇記憶。哪些重要則著重記錄下來,哪些不重要,則少記一些。當前的輸入內容由前面計算得到的表示。而選擇的門控信號則是由(i代表information)來進行控制。
將上面兩步得到的結果相加,即可得到傳輸給下一個狀態的。也就是上圖中的第一個公式。
3. 輸出階段。這個階段將決定哪些將會被當成當前狀態的輸出。主要是通過來進行控制的。并且還對上一階段得到的進行了放縮(通過一個tanh激活函數進行變化)。
與普通RNN類似,輸出往往最終也是通過變化得到。
3. 總結
以上,就是LSTM的內部結構。通過門控狀態來控制傳輸狀態,記住需要長時間記憶的,忘記不重要的信息;而不像普通的RNN那樣只能夠“呆萌”地僅有一種記憶疊加方式。對很多需要“長期記憶”的任務來說,尤其好用。
但也因為引入了很多內容,導致參數變多,也使得訓練難度加大了很多。因此很多時候我們往往會使用效果和LSTM相當但參數更少的GRU來構建大訓練量的模型。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100541 -
LSTM
+關注
關注
0文章
59瀏覽量
3738
原文標題:人人都能看懂的LSTM
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA也能做RNN
放棄 RNN 和 LSTM 吧,它們真的不好用
RNN及其變體LSTM和GRU
循環神經網絡(RNN)和(LSTM)初學者指南
一種具有強記憶力的 E3D-LSTM網絡,強化了LSTM的長時記憶能力

循環神經網絡LSTM為何如此有效?
深度分析RNN的模型結構,優缺點以及RNN模型的幾種應用





 工商網監
工商網監
評論