") 詳解Netty高性能異步事件驅(qū)動的網(wǎng)絡(luò)框架
詳解Netty高性能異步事件驅(qū)動的網(wǎng)絡(luò)框架
大家好,今天我們來聊聊Netty的那些事兒,我們都知道Netty是一個高性能異步事件驅(qū)動的網(wǎng)絡(luò)框架。
它的設(shè)計(jì)異常優(yōu)雅簡潔,擴(kuò)展性高,穩(wěn)定性強(qiáng)。擁有非常詳細(xì)完整的用戶文檔。
同時內(nèi)置了很多非常有用的模塊基本上做到了開箱即用,用戶只需要編寫短短幾行代碼,就可以快速構(gòu)建出一個具有高吞吐,低延時,更少的資源消耗,高性能(非必要的內(nèi)存拷貝最小化)等特征的高并發(fā)網(wǎng)絡(luò)應(yīng)用程序。
本文我們來探討下支持Netty具有高吞吐,低延時特征的基石----netty的網(wǎng)絡(luò)IO模型。
由Netty的網(wǎng)絡(luò)IO模型開始,我們來正式揭開本系列Netty源碼解析的序幕:
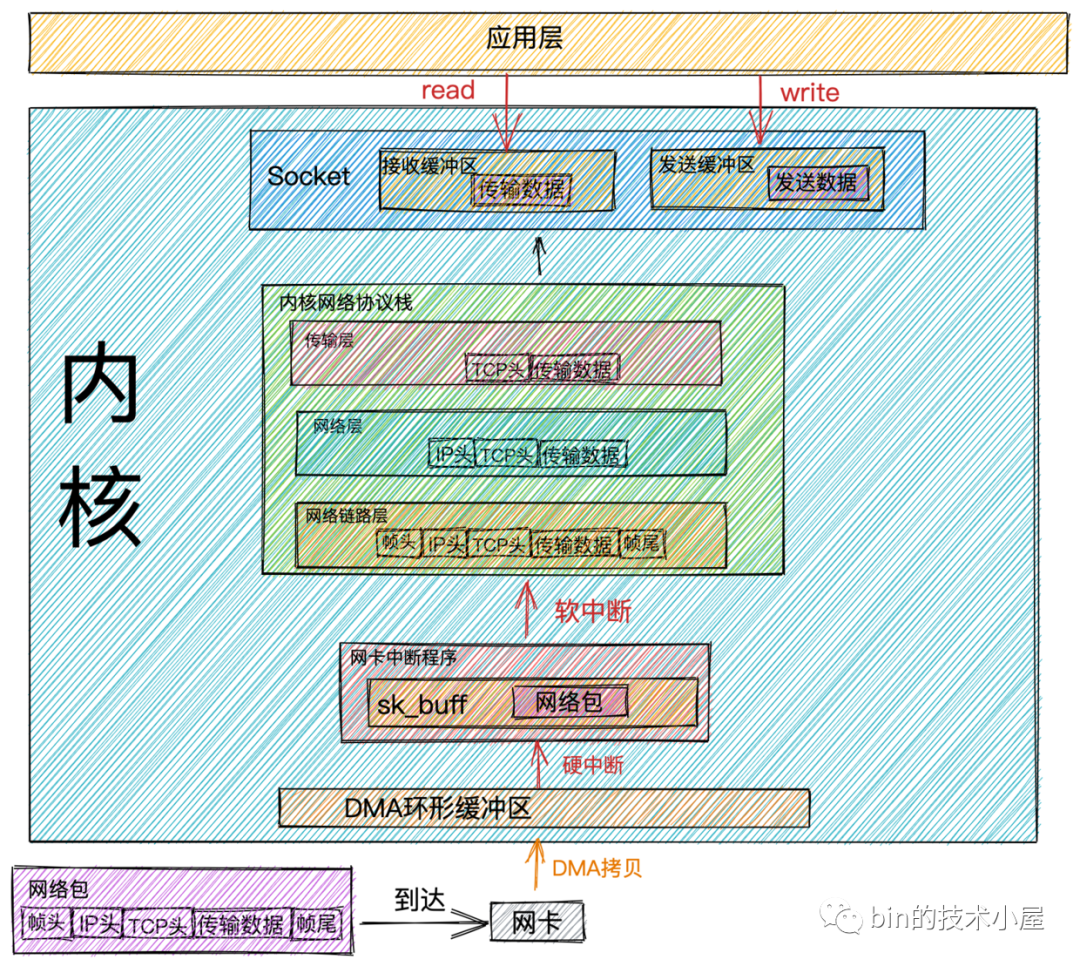
網(wǎng)絡(luò)包接收流程
 網(wǎng)絡(luò)包收發(fā)過程.png
網(wǎng)絡(luò)包收發(fā)過程.png-
當(dāng)
網(wǎng)絡(luò)數(shù)據(jù)幀通過網(wǎng)絡(luò)傳輸?shù)竭_(dá)網(wǎng)卡時,網(wǎng)卡會將網(wǎng)絡(luò)數(shù)據(jù)幀通過DMA的方式放到環(huán)形緩沖區(qū)RingBuffer中。
RingBuffer是網(wǎng)卡在啟動的時候分配和初始化的環(huán)形緩沖隊(duì)列。當(dāng)RingBuffer滿的時候,新來的數(shù)據(jù)包就會被丟棄。我們可以通過ifconfig命令查看網(wǎng)卡收發(fā)數(shù)據(jù)包的情況。其中overruns數(shù)據(jù)項(xiàng)表示當(dāng)RingBuffer滿時,被丟棄的數(shù)據(jù)包。如果發(fā)現(xiàn)出現(xiàn)丟包情況,可以通過ethtool命令來增大RingBuffer長度。
-
當(dāng)
DMA操作完成時,網(wǎng)卡會向CPU發(fā)起一個硬中斷,告訴CPU有網(wǎng)絡(luò)數(shù)據(jù)到達(dá)。CPU調(diào)用網(wǎng)卡驅(qū)動注冊的硬中斷響應(yīng)程序。網(wǎng)卡硬中斷響應(yīng)程序會為網(wǎng)絡(luò)數(shù)據(jù)幀創(chuàng)建內(nèi)核數(shù)據(jù)結(jié)構(gòu)sk_buffer,并將網(wǎng)絡(luò)數(shù)據(jù)幀拷貝到sk_buffer中。然后發(fā)起軟中斷請求,通知內(nèi)核有新的網(wǎng)絡(luò)數(shù)據(jù)幀到達(dá)。
sk_buff緩沖區(qū),是一個維護(hù)網(wǎng)絡(luò)幀結(jié)構(gòu)的雙向鏈表,鏈表中的每一個元素都是一個網(wǎng)絡(luò)幀。雖然 TCP/IP 協(xié)議棧分了好幾層,但上下不同層之間的傳遞,實(shí)際上只需要操作這個數(shù)據(jù)結(jié)構(gòu)中的指針,而無需進(jìn)行數(shù)據(jù)復(fù)制。
-
內(nèi)核線程
ksoftirqd發(fā)現(xiàn)有軟中斷請求到來,隨后調(diào)用網(wǎng)卡驅(qū)動注冊的poll函數(shù),poll函數(shù)將sk_buffer中的網(wǎng)絡(luò)數(shù)據(jù)包送到內(nèi)核協(xié)議棧中注冊的ip_rcv函數(shù)中。
每個CPU會綁定一個ksoftirqd內(nèi)核線程專門用來處理軟中斷響應(yīng)。2個 CPU 時,就會有ksoftirqd/0和ksoftirqd/1這兩個內(nèi)核線程。
這里有個事情需要注意下: 網(wǎng)卡接收到數(shù)據(jù)后,當(dāng)
DMA拷貝完成時,向CPU發(fā)出硬中斷,這時哪個CPU上響應(yīng)了這個硬中斷,那么在網(wǎng)卡硬中斷響應(yīng)程序中發(fā)出的軟中斷請求也會在這個CPU綁定的ksoftirqd線程中響應(yīng)。所以如果發(fā)現(xiàn)Linux軟中斷,CPU消耗都集中在一個核上的話,那么就需要調(diào)整硬中斷的CPU親和性,來將硬中斷打散到不通的CPU核上去。
-
在
ip_rcv函數(shù)中也就是上圖中的網(wǎng)絡(luò)層,取出數(shù)據(jù)包的IP頭,判斷該數(shù)據(jù)包下一跳的走向,如果數(shù)據(jù)包是發(fā)送給本機(jī)的,則取出傳輸層的協(xié)議類型(TCP或者UDP),并去掉數(shù)據(jù)包的IP頭,將數(shù)據(jù)包交給上圖中得傳輸層處理。
傳輸層的處理函數(shù):
TCP協(xié)議對應(yīng)內(nèi)核協(xié)議棧中注冊的tcp_rcv函數(shù),UDP協(xié)議對應(yīng)內(nèi)核協(xié)議棧中注冊的udp_rcv函數(shù)。
-
當(dāng)我們采用的是
TCP協(xié)議時,數(shù)據(jù)包到達(dá)傳輸層時,會在內(nèi)核協(xié)議棧中的tcp_rcv函數(shù)處理,在tcp_rcv函數(shù)中去掉TCP頭,根據(jù)四元組(源IP,源端口,目的IP,目的端口)查找對應(yīng)的Socket,如果找到對應(yīng)的Socket則將網(wǎng)絡(luò)數(shù)據(jù)包中的傳輸數(shù)據(jù)拷貝到Socket中的接收緩沖區(qū)中。如果沒有找到,則發(fā)送一個目標(biāo)不可達(dá)的icmp包。 -
內(nèi)核在接收網(wǎng)絡(luò)數(shù)據(jù)包時所做的工作我們就介紹完了,現(xiàn)在我們把視角放到應(yīng)用層,當(dāng)我們程序通過系統(tǒng)調(diào)用
read讀取Socket接收緩沖區(qū)中的數(shù)據(jù)時,如果接收緩沖區(qū)中沒有數(shù)據(jù),那么應(yīng)用程序就會在系統(tǒng)調(diào)用上阻塞,直到Socket接收緩沖區(qū)有數(shù)據(jù),然后CPU將內(nèi)核空間(Socket接收緩沖區(qū))的數(shù)據(jù)拷貝到用戶空間,最后系統(tǒng)調(diào)用read返回,應(yīng)用程序讀取數(shù)據(jù)。
性能開銷
從內(nèi)核處理網(wǎng)絡(luò)數(shù)據(jù)包接收的整個過程來看,內(nèi)核幫我們做了非常之多的工作,最終我們的應(yīng)用程序才能讀取到網(wǎng)絡(luò)數(shù)據(jù)。
隨著而來的也帶來了很多的性能開銷,結(jié)合前面介紹的網(wǎng)絡(luò)數(shù)據(jù)包接收過程我們來看下網(wǎng)絡(luò)數(shù)據(jù)包接收的過程中都有哪些性能開銷:
-
應(yīng)用程序通過
系統(tǒng)調(diào)用從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài)的開銷以及系統(tǒng)調(diào)用返回時從內(nèi)核態(tài)轉(zhuǎn)為用戶態(tài)的開銷。 -
網(wǎng)絡(luò)數(shù)據(jù)從
內(nèi)核空間通過CPU拷貝到用戶空間的開銷。 -
內(nèi)核線程
ksoftirqd響應(yīng)軟中斷的開銷。 -
CPU響應(yīng)硬中斷的開銷。 -
DMA拷貝網(wǎng)絡(luò)數(shù)據(jù)包到內(nèi)存中的開銷。
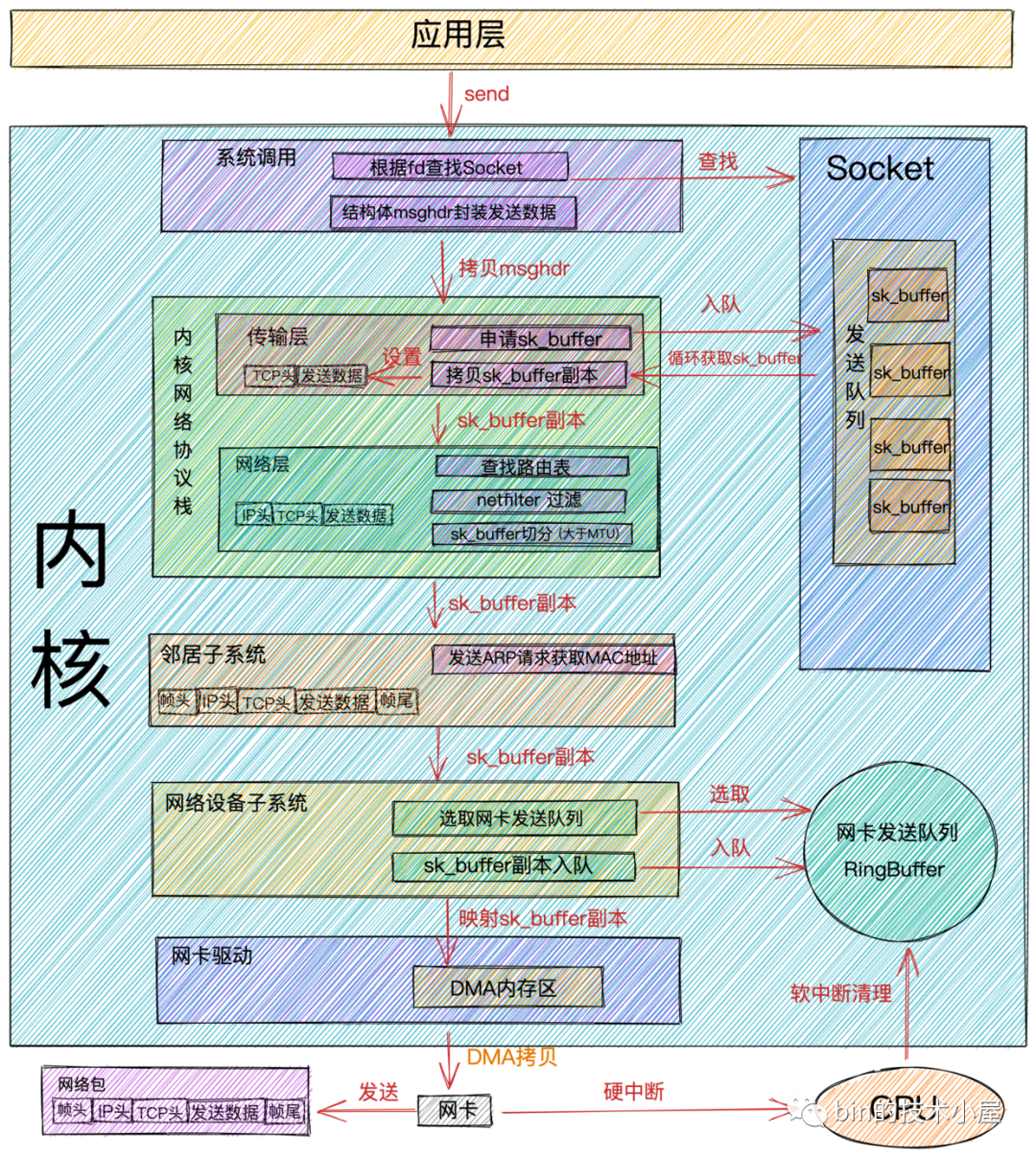
網(wǎng)絡(luò)包發(fā)送流程
網(wǎng)絡(luò)包發(fā)送過程.png-
當(dāng)我們在應(yīng)用程序中調(diào)用
send系統(tǒng)調(diào)用發(fā)送數(shù)據(jù)時,由于是系統(tǒng)調(diào)用所以線程會發(fā)生一次用戶態(tài)到內(nèi)核態(tài)的轉(zhuǎn)換,在內(nèi)核中首先根據(jù)fd將真正的Socket找出,這個Socket對象中記錄著各種協(xié)議棧的函數(shù)地址,然后構(gòu)造struct msghdr對象,將用戶需要發(fā)送的數(shù)據(jù)全部封裝在這個struct msghdr結(jié)構(gòu)體中。 -
調(diào)用內(nèi)核協(xié)議棧函數(shù)
inet_sendmsg,發(fā)送流程進(jìn)入內(nèi)核協(xié)議棧處理。在進(jìn)入到內(nèi)核協(xié)議棧之后,內(nèi)核會找到Socket上的具體協(xié)議的發(fā)送函數(shù)。
比如:我們使用的是
TCP協(xié)議,對應(yīng)的TCP協(xié)議發(fā)送函數(shù)是tcp_sendmsg,如果是UDP協(xié)議的話,對應(yīng)的發(fā)送函數(shù)為udp_sendmsg。
-
在
TCP協(xié)議的發(fā)送函數(shù)tcp_sendmsg中,創(chuàng)建內(nèi)核數(shù)據(jù)結(jié)構(gòu)sk_buffer,將struct msghdr結(jié)構(gòu)體中的發(fā)送數(shù)據(jù)拷貝到sk_buffer中。調(diào)用tcp_write_queue_tail函數(shù)獲取Socket發(fā)送隊(duì)列中的隊(duì)尾元素,將新創(chuàng)建的sk_buffer添加到Socket發(fā)送隊(duì)列的尾部。
Socket的發(fā)送隊(duì)列是由sk_buffer組成的一個雙向鏈表。
發(fā)送流程走到這里,用戶要發(fā)送的數(shù)據(jù)總算是從
用戶空間拷貝到了內(nèi)核中,這時雖然發(fā)送數(shù)據(jù)已經(jīng)拷貝到了內(nèi)核Socket中的發(fā)送隊(duì)列中,但并不代表內(nèi)核會開始發(fā)送,因?yàn)?/span>TCP協(xié)議的流量控制和擁塞控制,用戶要發(fā)送的數(shù)據(jù)包并不一定會立馬被發(fā)送出去,需要符合TCP協(xié)議的發(fā)送條件。如果沒有達(dá)到發(fā)送條件,那么本次send系統(tǒng)調(diào)用就會直接返回。
-
如果符合發(fā)送條件,則開始調(diào)用
tcp_write_xmit內(nèi)核函數(shù)。在這個函數(shù)中,會循環(huán)獲取Socket發(fā)送隊(duì)列中待發(fā)送的sk_buffer,然后進(jìn)行擁塞控制以及滑動窗口的管理。 -
將從
Socket發(fā)送隊(duì)列中獲取到的sk_buffer重新拷貝一份,設(shè)置sk_buffer副本中的TCP HEADER。
sk_buffer內(nèi)部其實(shí)包含了網(wǎng)絡(luò)協(xié)議中所有的header。在設(shè)置TCP HEADER的時候,只是把指針指向sk_buffer的合適位置。后面再設(shè)置IP HEADER的時候,在把指針移動一下就行,避免頻繁的內(nèi)存申請和拷貝,效率很高。
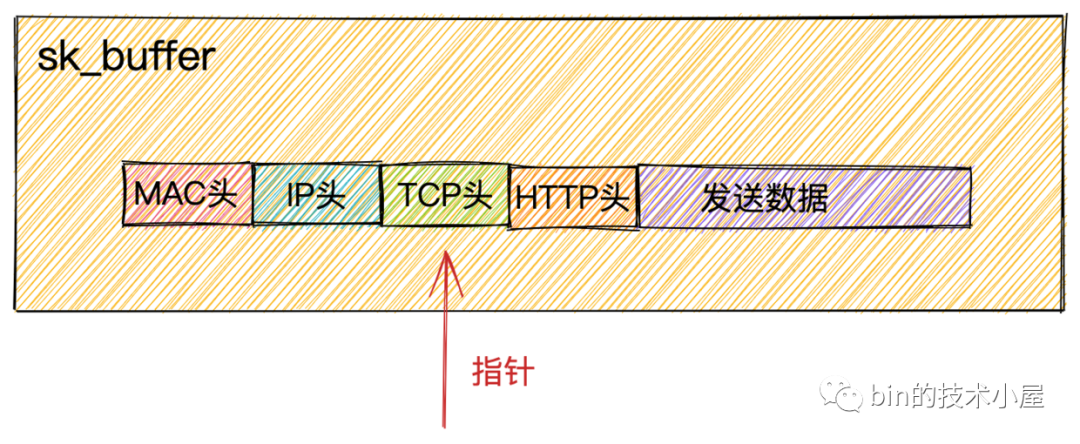 sk_buffer.png
sk_buffer.png為什么不直接使用
Socket發(fā)送隊(duì)列中的sk_buffer而是需要拷貝一份呢?因?yàn)?/span>TCP協(xié)議是支持丟包重傳的,在沒有收到對端的ACK之前,這個sk_buffer是不能刪除的。內(nèi)核每次調(diào)用網(wǎng)卡發(fā)送數(shù)據(jù)的時候,實(shí)際上傳遞的是sk_buffer的拷貝副本,當(dāng)網(wǎng)卡把數(shù)據(jù)發(fā)送出去后,sk_buffer拷貝副本會被釋放。當(dāng)收到對端的ACK之后,Socket發(fā)送隊(duì)列中的sk_buffer才會被真正刪除。
-
當(dāng)設(shè)置完
TCP頭后,內(nèi)核協(xié)議棧傳輸層的事情就做完了,下面通過調(diào)用ip_queue_xmit內(nèi)核函數(shù),正式來到內(nèi)核協(xié)議棧網(wǎng)絡(luò)層的處理。通過
route命令可以查看本機(jī)路由配置。如果你使用
iptables配置了一些規(guī)則,那么這里將檢測是否命中規(guī)則。如果你設(shè)置了非常復(fù)雜的 netfilter 規(guī)則,在這個函數(shù)里將會導(dǎo)致你的線程CPU 開銷會極大增加。-
將
sk_buffer中的指針移動到IP頭位置上,設(shè)置IP頭。 -
執(zhí)行
netfilters過濾。過濾通過之后,如果數(shù)據(jù)大于MTU的話,則執(zhí)行分片。 -
檢查
Socket中是否有緩存路由表,如果沒有的話,則查找路由項(xiàng),并緩存到Socket中。接著在把路由表設(shè)置到sk_buffer中。
-
-
內(nèi)核協(xié)議棧
網(wǎng)絡(luò)層的事情處理完后,現(xiàn)在發(fā)送流程進(jìn)入了到了鄰居子系統(tǒng),鄰居子系統(tǒng)位于內(nèi)核協(xié)議棧中的網(wǎng)絡(luò)層和網(wǎng)絡(luò)接口層之間,用于發(fā)送ARP請求獲取MAC地址,然后將sk_buffer中的指針移動到MAC頭位置,填充MAC頭。 -
經(jīng)過
鄰居子系統(tǒng)的處理,現(xiàn)在sk_buffer中已經(jīng)封裝了一個完整的數(shù)據(jù)幀,隨后內(nèi)核將sk_buffer交給網(wǎng)絡(luò)設(shè)備子系統(tǒng)進(jìn)行處理。網(wǎng)絡(luò)設(shè)備子系統(tǒng)主要做以下幾項(xiàng)事情:-
選擇發(fā)送隊(duì)列(
RingBuffer)。因?yàn)榫W(wǎng)卡擁有多個發(fā)送隊(duì)列,所以在發(fā)送前需要選擇一個發(fā)送隊(duì)列。 -
將
sk_buffer添加到發(fā)送隊(duì)列中。 -
循環(huán)從發(fā)送隊(duì)列(
RingBuffer)中取出sk_buffer,調(diào)用內(nèi)核函數(shù)sch_direct_xmit發(fā)送數(shù)據(jù),其中會調(diào)用網(wǎng)卡驅(qū)動程序來發(fā)送數(shù)據(jù)。
-
選擇發(fā)送隊(duì)列(
以上過程全部是用戶線程的內(nèi)核態(tài)在執(zhí)行,占用的CPU時間是系統(tǒng)態(tài)時間(
sy),當(dāng)分配給用戶線程的CPU quota用完的時候,會觸發(fā)NET_TX_SOFTIRQ類型的軟中斷,內(nèi)核線程ksoftirqd會響應(yīng)這個軟中斷,并執(zhí)行NET_TX_SOFTIRQ類型的軟中斷注冊的回調(diào)函數(shù)net_tx_action,在回調(diào)函數(shù)中會執(zhí)行到驅(qū)動程序函數(shù)dev_hard_start_xmit來發(fā)送數(shù)據(jù)。
注意:當(dāng)觸發(fā)
NET_TX_SOFTIRQ軟中斷來發(fā)送數(shù)據(jù)時,后邊消耗的 CPU 就都顯示在si這里了,不會消耗用戶進(jìn)程的系統(tǒng)態(tài)時間(sy)了。
從這里可以看到網(wǎng)絡(luò)包的發(fā)送過程和接受過程是不同的,在介紹網(wǎng)絡(luò)包的接受過程時,我們提到是通過觸發(fā)
NET_RX_SOFTIRQ類型的軟中斷在內(nèi)核線程ksoftirqd中執(zhí)行內(nèi)核網(wǎng)絡(luò)協(xié)議棧接受數(shù)據(jù)。而在網(wǎng)絡(luò)數(shù)據(jù)包的發(fā)送過程中是用戶線程的內(nèi)核態(tài)在執(zhí)行內(nèi)核網(wǎng)絡(luò)協(xié)議棧,只有當(dāng)線程的CPU quota用盡時,才觸發(fā)NET_TX_SOFTIRQ軟中斷來發(fā)送數(shù)據(jù)。
在整個網(wǎng)絡(luò)包的發(fā)送和接受過程中,
NET_TX_SOFTIRQ類型的軟中斷只會在發(fā)送網(wǎng)絡(luò)包時并且當(dāng)用戶線程的CPU quota用盡時,才會觸發(fā)。剩下的接受過程中觸發(fā)的軟中斷類型以及發(fā)送完數(shù)據(jù)觸發(fā)的軟中斷類型均為NET_RX_SOFTIRQ。所以這就是你在服務(wù)器上查看/proc/softirqs,一般NET_RX都要比NET_TX大很多的的原因。
-
現(xiàn)在發(fā)送流程終于到了網(wǎng)卡真實(shí)發(fā)送數(shù)據(jù)的階段,前邊我們講到無論是用戶線程的內(nèi)核態(tài)還是觸發(fā)
NET_TX_SOFTIRQ類型的軟中斷在發(fā)送數(shù)據(jù)的時候最終會調(diào)用到網(wǎng)卡的驅(qū)動程序函數(shù)dev_hard_start_xmit來發(fā)送數(shù)據(jù)。在網(wǎng)卡驅(qū)動程序函數(shù)dev_hard_start_xmit中會將sk_buffer映射到網(wǎng)卡可訪問的內(nèi)存 DMA 區(qū)域,最終網(wǎng)卡驅(qū)動程序通過DMA的方式將數(shù)據(jù)幀通過物理網(wǎng)卡發(fā)送出去。 -
當(dāng)數(shù)據(jù)發(fā)送完畢后,還有最后一項(xiàng)重要的工作,就是清理工作。數(shù)據(jù)發(fā)送完畢后,網(wǎng)卡設(shè)備會向
CPU發(fā)送一個硬中斷,CPU調(diào)用網(wǎng)卡驅(qū)動程序注冊的硬中斷響應(yīng)程序,在硬中斷響應(yīng)中觸發(fā)NET_RX_SOFTIRQ類型的軟中斷,在軟中斷的回調(diào)函數(shù)igb_poll中清理釋放sk_buffer,清理網(wǎng)卡發(fā)送隊(duì)列(RingBuffer),解除 DMA 映射。
無論
硬中斷是因?yàn)?/span>有數(shù)據(jù)要接收,還是說發(fā)送完成通知,從硬中斷觸發(fā)的軟中斷都是NET_RX_SOFTIRQ。
這里釋放清理的只是
sk_buffer的副本,真正的sk_buffer現(xiàn)在還是存放在Socket的發(fā)送隊(duì)列中。前面在傳輸層處理的時候我們提到過,因?yàn)閭鬏攲有枰?/span>保證可靠性,所以sk_buffer其實(shí)還沒有刪除。它得等收到對方的 ACK 之后才會真正刪除。
性能開銷
前邊我們提到了在網(wǎng)絡(luò)包接收過程中涉及到的性能開銷,現(xiàn)在介紹完了網(wǎng)絡(luò)包的發(fā)送過程,我們來看下在數(shù)據(jù)包發(fā)送過程中的性能開銷:
-
和接收數(shù)據(jù)一樣,應(yīng)用程序在調(diào)用
系統(tǒng)調(diào)用send的時候會從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài)以及發(fā)送完數(shù)據(jù)后,系統(tǒng)調(diào)用返回時從內(nèi)核態(tài)轉(zhuǎn)為用戶態(tài)的開銷。 -
用戶線程內(nèi)核態(tài)
CPU quota用盡時觸發(fā)NET_TX_SOFTIRQ類型軟中斷,內(nèi)核響應(yīng)軟中斷的開銷。 -
網(wǎng)卡發(fā)送完數(shù)據(jù),向
CPU發(fā)送硬中斷,CPU響應(yīng)硬中斷的開銷。以及在硬中斷中發(fā)送NET_RX_SOFTIRQ軟中斷執(zhí)行具體的內(nèi)存清理動作。內(nèi)核響應(yīng)軟中斷的開銷。 -
內(nèi)存拷貝的開銷。我們來回顧下在數(shù)據(jù)包發(fā)送的過程中都發(fā)生了哪些內(nèi)存拷貝:
-
在內(nèi)核協(xié)議棧的傳輸層中,
TCP協(xié)議對應(yīng)的發(fā)送函數(shù)tcp_sendmsg會申請sk_buffer,將用戶要發(fā)送的數(shù)據(jù)拷貝到sk_buffer中。 -
在發(fā)送流程從傳輸層到網(wǎng)絡(luò)層的時候,會
拷貝一個sk_buffer副本出來,將這個sk_buffer副本向下傳遞。原始sk_buffer保留在Socket發(fā)送隊(duì)列中,等待網(wǎng)絡(luò)對端ACK,對端ACK后刪除Socket發(fā)送隊(duì)列中的sk_buffer。對端沒有發(fā)送ACK,則重新從Socket發(fā)送隊(duì)列中發(fā)送,實(shí)現(xiàn)TCP協(xié)議的可靠傳輸。 -
在網(wǎng)絡(luò)層,如果發(fā)現(xiàn)要發(fā)送的數(shù)據(jù)大于
MTU,則會進(jìn)行分片操作,申請額外的sk_buffer,并將原來的sk_buffer拷貝到多個小的sk_buffer中。
-
在內(nèi)核協(xié)議棧的傳輸層中,
再談(阻塞,非阻塞)與(同步,異步)
在我們聊完網(wǎng)絡(luò)數(shù)據(jù)的接收和發(fā)送過程后,我們來談下IO中特別容易混淆的概念:阻塞與同步,非阻塞與異步。
網(wǎng)上各種博文還有各種書籍中有大量的關(guān)于這兩個概念的解釋,但是筆者覺得還是不夠形象化,只是對概念的生硬解釋,如果硬套概念的話,其實(shí)感覺阻塞與同步,非阻塞與異步還是沒啥區(qū)別,時間長了,還是比較模糊容易混淆。
所以筆者在這里嘗試換一種更加形象化,更加容易理解記憶的方式來清晰地解釋下什么是阻塞與非阻塞,什么是同步與異步。
經(jīng)過前邊對網(wǎng)絡(luò)數(shù)據(jù)包接收流程的介紹,在這里我們可以將整個流程總結(jié)為兩個階段:
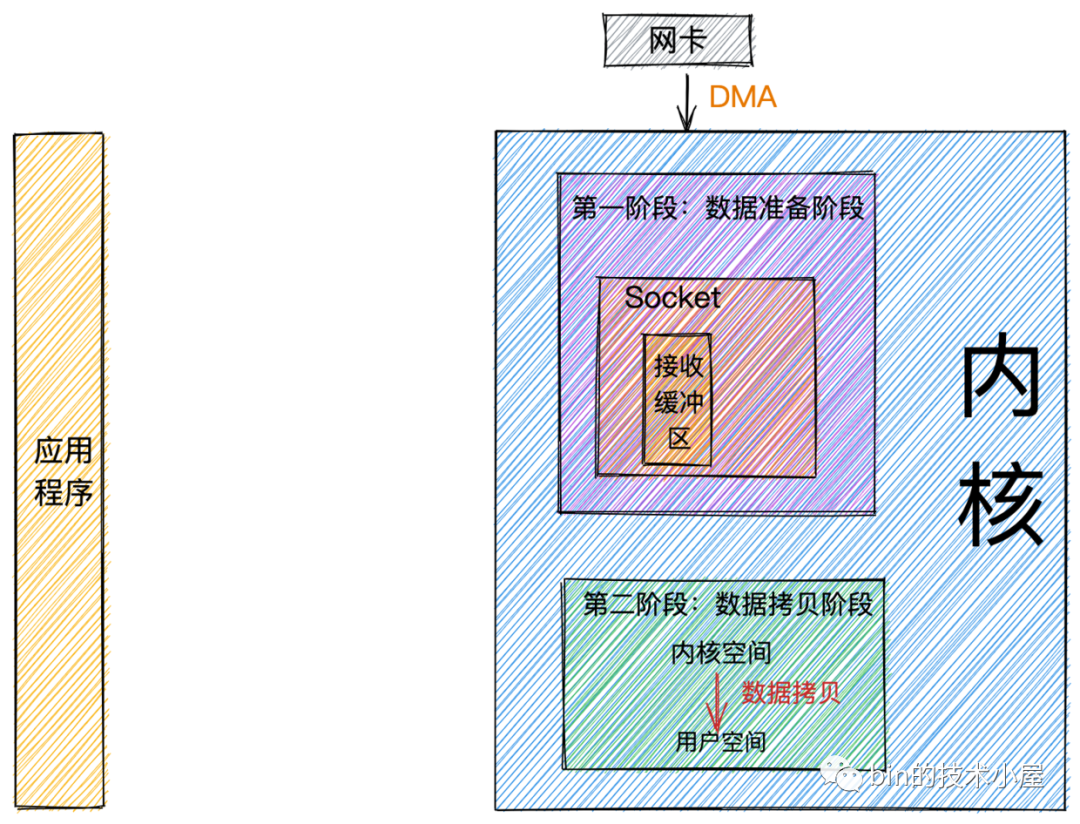 數(shù)據(jù)接收階段.png
數(shù)據(jù)接收階段.png-
數(shù)據(jù)準(zhǔn)備階段: 在這個階段,網(wǎng)絡(luò)數(shù)據(jù)包到達(dá)網(wǎng)卡,通過
DMA的方式將數(shù)據(jù)包拷貝到內(nèi)存中,然后經(jīng)過硬中斷,軟中斷,接著通過內(nèi)核線程ksoftirqd經(jīng)過內(nèi)核協(xié)議棧的處理,最終將數(shù)據(jù)發(fā)送到內(nèi)核Socket的接收緩沖區(qū)中。 -
數(shù)據(jù)拷貝階段: 當(dāng)數(shù)據(jù)到達(dá)
內(nèi)核Socket的接收緩沖區(qū)中時,此時數(shù)據(jù)存在于內(nèi)核空間中,需要將數(shù)據(jù)拷貝到用戶空間中,才能夠被應(yīng)用程序讀取。
阻塞與非阻塞
阻塞與非阻塞的區(qū)別主要發(fā)生在第一階段:數(shù)據(jù)準(zhǔn)備階段。
當(dāng)應(yīng)用程序發(fā)起系統(tǒng)調(diào)用read時,線程從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài),讀取內(nèi)核Socket的接收緩沖區(qū)中的網(wǎng)絡(luò)數(shù)據(jù)。
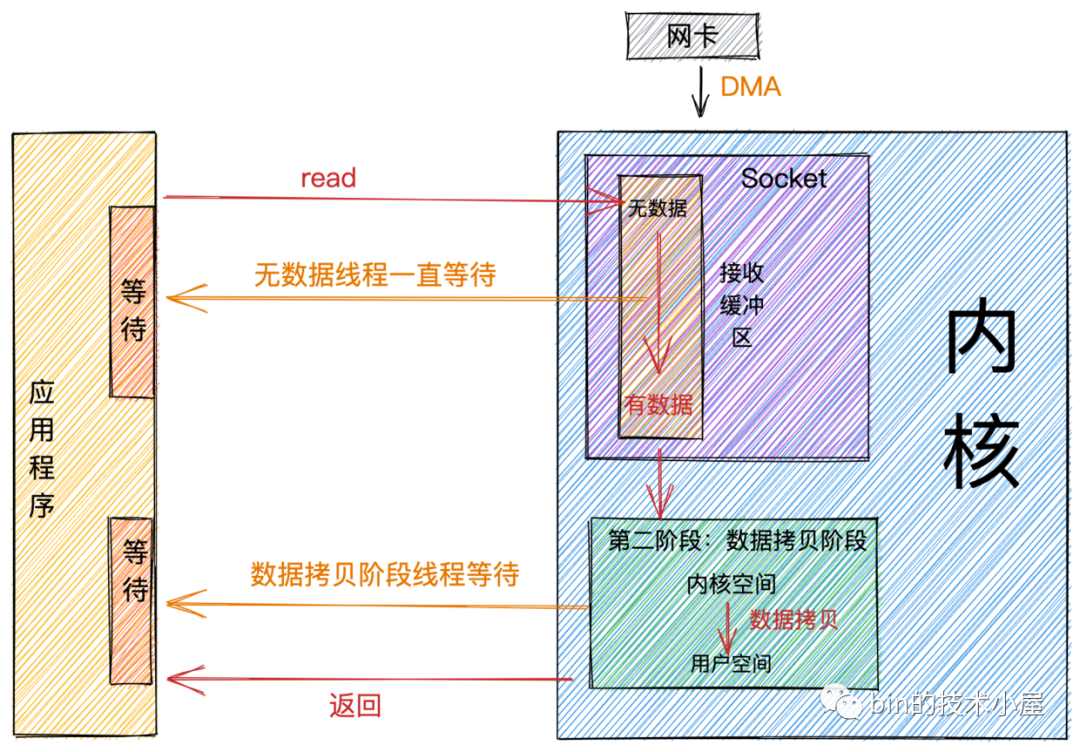
阻塞
如果這時內(nèi)核Socket的接收緩沖區(qū)沒有數(shù)據(jù),那么線程就會一直等待,直到Socket接收緩沖區(qū)有數(shù)據(jù)為止。隨后將數(shù)據(jù)從內(nèi)核空間拷貝到用戶空間,系統(tǒng)調(diào)用read返回。
 阻塞IO.png
阻塞IO.png
從圖中我們可以看出:阻塞的特點(diǎn)是在第一階段和第二階段都會等待。
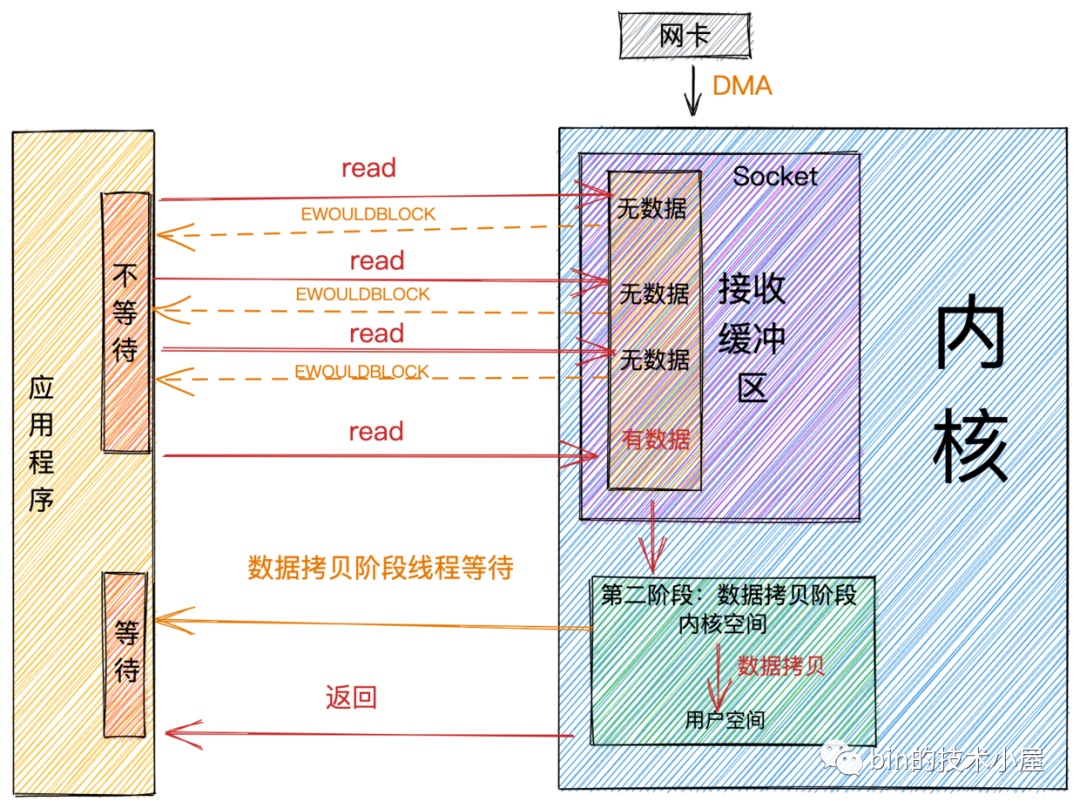
非阻塞
阻塞和非阻塞主要的區(qū)分是在第一階段:數(shù)據(jù)準(zhǔn)備階段。
-
在第一階段,當(dāng)
Socket的接收緩沖區(qū)中沒有數(shù)據(jù)的時候,阻塞模式下應(yīng)用線程會一直等待。非阻塞模式下應(yīng)用線程不會等待,系統(tǒng)調(diào)用直接返回錯誤標(biāo)志EWOULDBLOCK。 -
當(dāng)
Socket的接收緩沖區(qū)中有數(shù)據(jù)的時候,阻塞和非阻塞的表現(xiàn)是一樣的,都會進(jìn)入第二階段等待數(shù)據(jù)從內(nèi)核空間拷貝到用戶空間,然后系統(tǒng)調(diào)用返回。
 非阻塞IO.png
非阻塞IO.png
從上圖中,我們可以看出:非阻塞的特點(diǎn)是第一階段不會等待,但是在第二階段還是會等待。
同步與異步
同步與異步主要的區(qū)別發(fā)生在第二階段:數(shù)據(jù)拷貝階段。
前邊我們提到在數(shù)據(jù)拷貝階段主要是將數(shù)據(jù)從內(nèi)核空間拷貝到用戶空間。然后應(yīng)用程序才可以讀取數(shù)據(jù)。
當(dāng)內(nèi)核Socket的接收緩沖區(qū)有數(shù)據(jù)到達(dá)時,進(jìn)入第二階段。
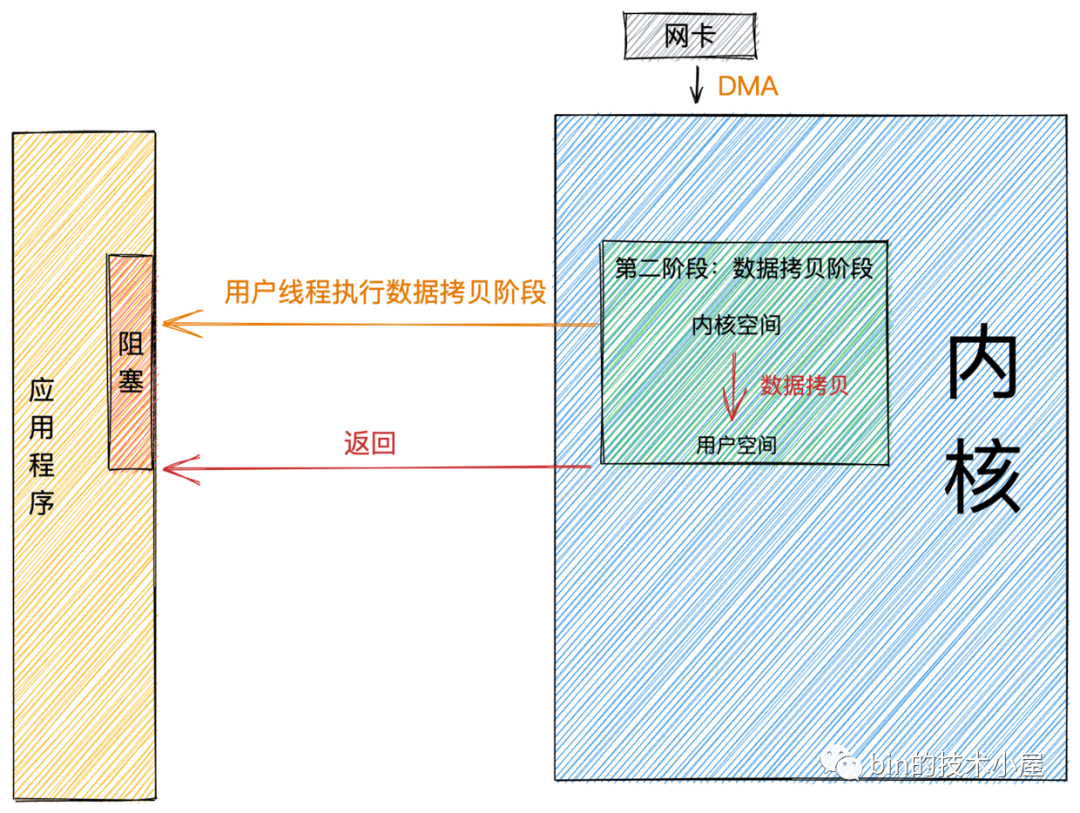
同步
同步模式在數(shù)據(jù)準(zhǔn)備好后,是由用戶線程的內(nèi)核態(tài)來執(zhí)行第二階段。所以應(yīng)用程序會在第二階段發(fā)生阻塞,直到數(shù)據(jù)從內(nèi)核空間拷貝到用戶空間,系統(tǒng)調(diào)用才會返回。
Linux下的 epoll和Mac 下的 kqueue都屬于同步 IO。
 同步IO.png
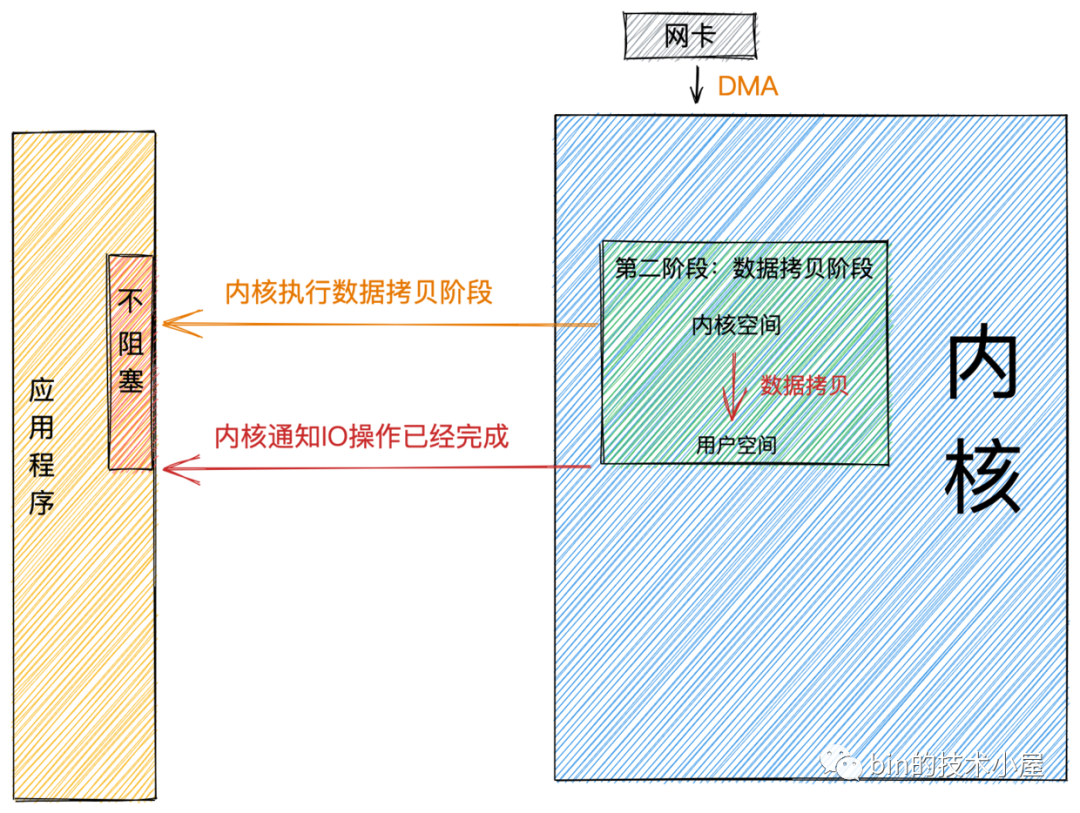
同步IO.png異步
異步模式下是由內(nèi)核來執(zhí)行第二階段的數(shù)據(jù)拷貝操作,當(dāng)內(nèi)核執(zhí)行完第二階段,會通知用戶線程IO操作已經(jīng)完成,并將數(shù)據(jù)回調(diào)給用戶線程。所以在異步模式下 數(shù)據(jù)準(zhǔn)備階段和數(shù)據(jù)拷貝階段均是由內(nèi)核來完成,不會對應(yīng)用程序造成任何阻塞。
基于以上特征,我們可以看到異步模式需要內(nèi)核的支持,比較依賴操作系統(tǒng)底層的支持。
在目前流行的操作系統(tǒng)中,只有Windows 中的 IOCP才真正屬于異步 IO,實(shí)現(xiàn)的也非常成熟。但Windows很少用來作為服務(wù)器使用。
而常用來作為服務(wù)器使用的Linux,異步IO機(jī)制實(shí)現(xiàn)的不夠成熟,與NIO相比性能提升的也不夠明顯。
但Linux kernel 在5.1版本由Facebook的大神Jens Axboe引入了新的異步IO庫io_uring 改善了原來Linux native AIO的一些性能問題。性能相比Epoll以及之前原生的AIO提高了不少,值得關(guān)注。
 異步IO.png
異步IO.pngIO模型
在進(jìn)行網(wǎng)絡(luò)IO操作時,用什么樣的IO模型來讀寫數(shù)據(jù)將在很大程度上決定了網(wǎng)絡(luò)框架的IO性能。所以IO模型的選擇是構(gòu)建一個高性能網(wǎng)絡(luò)框架的基礎(chǔ)。
在《UNIX 網(wǎng)絡(luò)編程》一書中介紹了五種IO模型:阻塞IO,非阻塞IO,IO多路復(fù)用,信號驅(qū)動IO,異步IO,每一種IO模型的出現(xiàn)都是對前一種的升級優(yōu)化。
下面我們就來分別介紹下這五種IO模型各自都解決了什么問題,適用于哪些場景,各自的優(yōu)缺點(diǎn)是什么?
阻塞IO(BIO)
阻塞IO.png
經(jīng)過前一小節(jié)對阻塞這個概念的介紹,相信大家可以很容易理解阻塞IO的概念和過程。
既然這小節(jié)我們談的是IO,那么下邊我們來看下在阻塞IO模型下,網(wǎng)絡(luò)數(shù)據(jù)的讀寫過程。
阻塞讀
當(dāng)用戶線程發(fā)起read系統(tǒng)調(diào)用,用戶線程從用戶態(tài)切換到內(nèi)核態(tài),在內(nèi)核中去查看Socket接收緩沖區(qū)是否有數(shù)據(jù)到來。
-
Socket接收緩沖區(qū)中有數(shù)據(jù),則用戶線程在內(nèi)核態(tài)將內(nèi)核空間中的數(shù)據(jù)拷貝到用戶空間,系統(tǒng)IO調(diào)用返回。 -
Socket接收緩沖區(qū)中無數(shù)據(jù),則用戶線程讓出CPU,進(jìn)入阻塞狀態(tài)。當(dāng)數(shù)據(jù)到達(dá)Socket接收緩沖區(qū)后,內(nèi)核喚醒阻塞狀態(tài)中的用戶線程進(jìn)入就緒狀態(tài),隨后經(jīng)過CPU的調(diào)度獲取到CPU quota進(jìn)入運(yùn)行狀態(tài),將內(nèi)核空間的數(shù)據(jù)拷貝到用戶空間,隨后系統(tǒng)調(diào)用返回。
阻塞寫
當(dāng)用戶線程發(fā)起send系統(tǒng)調(diào)用時,用戶線程從用戶態(tài)切換到內(nèi)核態(tài),將發(fā)送數(shù)據(jù)從用戶空間拷貝到內(nèi)核空間中的Socket發(fā)送緩沖區(qū)中。
-
當(dāng)
Socket發(fā)送緩沖區(qū)能夠容納下發(fā)送數(shù)據(jù)時,用戶線程會將全部的發(fā)送數(shù)據(jù)寫入Socket緩沖區(qū),然后執(zhí)行在《網(wǎng)絡(luò)包發(fā)送流程》這小節(jié)介紹的后續(xù)流程,然后返回。 -
當(dāng)
Socket發(fā)送緩沖區(qū)空間不夠,無法容納下全部發(fā)送數(shù)據(jù)時,用戶線程讓出CPU,進(jìn)入阻塞狀態(tài),直到Socket發(fā)送緩沖區(qū)能夠容納下全部發(fā)送數(shù)據(jù)時,內(nèi)核喚醒用戶線程,執(zhí)行后續(xù)發(fā)送流程。
阻塞IO模型下的寫操作做事風(fēng)格比較硬剛,非得要把全部的發(fā)送數(shù)據(jù)寫入發(fā)送緩沖區(qū)才肯善罷甘休。
阻塞IO模型
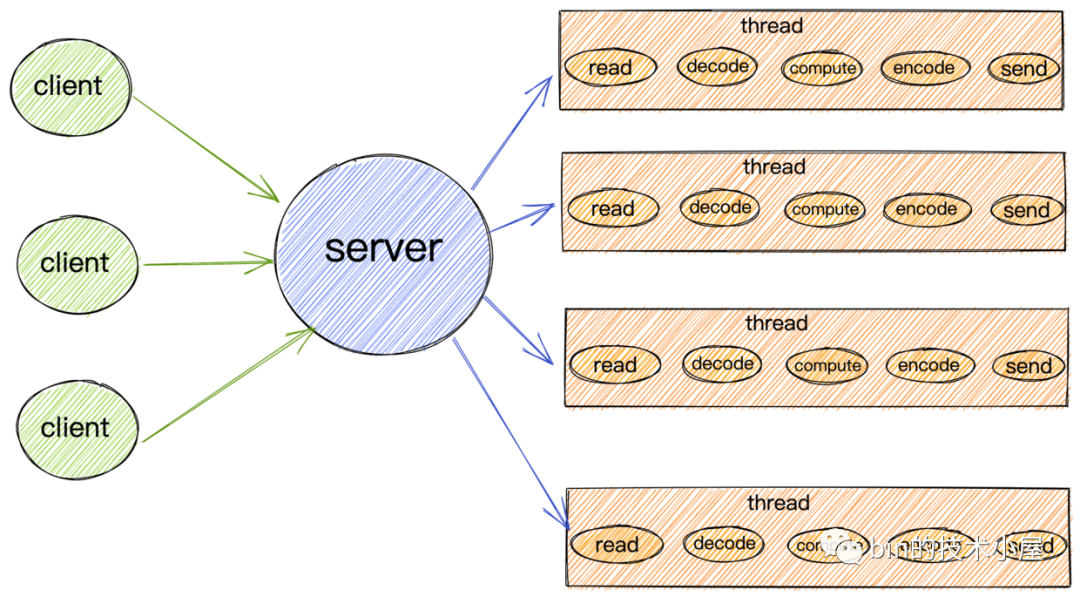 阻塞IO模型.png
阻塞IO模型.png
由于阻塞IO的讀寫特點(diǎn),所以導(dǎo)致在阻塞IO模型下,每個請求都需要被一個獨(dú)立的線程處理。一個線程在同一時刻只能與一個連接綁定。來一個請求,服務(wù)端就需要創(chuàng)建一個線程用來處理請求。
當(dāng)客戶端請求的并發(fā)量突然增大時,服務(wù)端在一瞬間就會創(chuàng)建出大量的線程,而創(chuàng)建線程是需要系統(tǒng)資源開銷的,這樣一來就會一瞬間占用大量的系統(tǒng)資源。
如果客戶端創(chuàng)建好連接后,但是一直不發(fā)數(shù)據(jù),通常大部分情況下,網(wǎng)絡(luò)連接也并不總是有數(shù)據(jù)可讀,那么在空閑的這段時間內(nèi),服務(wù)端線程就會一直處于阻塞狀態(tài),無法干其他的事情。CPU也無法得到充分的發(fā)揮,同時還會導(dǎo)致大量線程切換的開銷。
適用場景
基于以上阻塞IO模型的特點(diǎn),該模型只適用于連接數(shù)少,并發(fā)度低的業(yè)務(wù)場景。
比如公司內(nèi)部的一些管理系統(tǒng),通常請求數(shù)在100個左右,使用阻塞IO模型還是非常適合的。而且性能還不輸NIO。
該模型在C10K之前,是普遍被采用的一種IO模型。
非阻塞IO(NIO)
阻塞IO模型最大的問題就是一個線程只能處理一個連接,如果這個連接上沒有數(shù)據(jù)的話,那么這個線程就只能阻塞在系統(tǒng)IO調(diào)用上,不能干其他的事情。這對系統(tǒng)資源來說,是一種極大的浪費(fèi)。同時大量的線程上下文切換,也是一個巨大的系統(tǒng)開銷。
所以為了解決這個問題,我們就需要用盡可能少的線程去處理更多的連接。,網(wǎng)絡(luò)IO模型的演變也是根據(jù)這個需求來一步一步演進(jìn)的。
基于這個需求,第一種解決方案非阻塞IO就出現(xiàn)了。我們在上一小節(jié)中介紹了非阻塞的概念,現(xiàn)在我們來看下網(wǎng)絡(luò)讀寫操作在非阻塞IO下的特點(diǎn):
非阻塞IO.png非阻塞讀
當(dāng)用戶線程發(fā)起非阻塞read系統(tǒng)調(diào)用時,用戶線程從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài),在內(nèi)核中去查看Socket接收緩沖區(qū)是否有數(shù)據(jù)到來。
-
Socket接收緩沖區(qū)中無數(shù)據(jù),系統(tǒng)調(diào)用立馬返回,并帶有一個EWOULDBLOCK或EAGAIN錯誤,這個階段用戶線程不會阻塞,也不會讓出CPU,而是會繼續(xù)輪訓(xùn)直到Socket接收緩沖區(qū)中有數(shù)據(jù)為止。 -
Socket接收緩沖區(qū)中有數(shù)據(jù),用戶線程在內(nèi)核態(tài)會將內(nèi)核空間中的數(shù)據(jù)拷貝到用戶空間,注意這個數(shù)據(jù)拷貝階段,應(yīng)用程序是阻塞的,當(dāng)數(shù)據(jù)拷貝完成,系統(tǒng)調(diào)用返回。
非阻塞寫
前邊我們在介紹阻塞寫的時候提到阻塞寫的風(fēng)格特別的硬朗,頭比較鐵非要把全部發(fā)送數(shù)據(jù)一次性都寫到Socket的發(fā)送緩沖區(qū)中才返回,如果發(fā)送緩沖區(qū)中沒有足夠的空間容納,那么就一直阻塞死等,特別的剛。
相比較而言非阻塞寫的特點(diǎn)就比較佛系,當(dāng)發(fā)送緩沖區(qū)中沒有足夠的空間容納全部發(fā)送數(shù)據(jù)時,非阻塞寫的特點(diǎn)是能寫多少寫多少,寫不下了,就立即返回。并將寫入到發(fā)送緩沖區(qū)的字節(jié)數(shù)返回給應(yīng)用程序,方便用戶線程不斷的輪訓(xùn)嘗試將剩下的數(shù)據(jù)寫入發(fā)送緩沖區(qū)中。
非阻塞IO模型
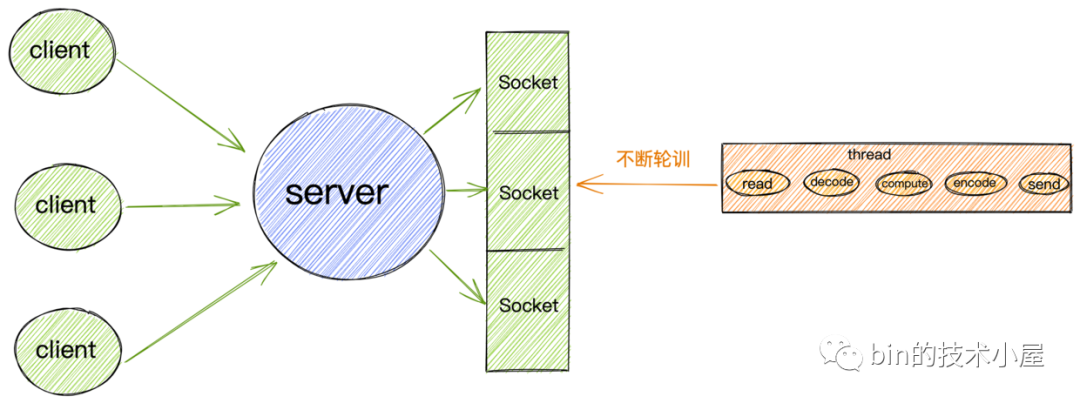 非阻塞IO模型.png
非阻塞IO模型.png
基于以上非阻塞IO的特點(diǎn),我們就不必像阻塞IO那樣為每個請求分配一個線程去處理連接上的讀寫了。
我們可以利用一個線程或者很少的線程,去不斷地輪詢每個Socket的接收緩沖區(qū)是否有數(shù)據(jù)到達(dá),如果沒有數(shù)據(jù),不必阻塞線程,而是接著去輪詢下一個Socket接收緩沖區(qū),直到輪詢到數(shù)據(jù)后,處理連接上的讀寫,或者交給業(yè)務(wù)線程池去處理,輪詢線程則繼續(xù)輪詢其他的Socket接收緩沖區(qū)。
這樣一個非阻塞IO模型就實(shí)現(xiàn)了我們在本小節(jié)開始提出的需求:我們需要用盡可能少的線程去處理更多的連接
適用場景
雖然非阻塞IO模型與阻塞IO模型相比,減少了很大一部分的資源消耗和系統(tǒng)開銷。
但是它仍然有很大的性能問題,因?yàn)樵?/span>非阻塞IO模型下,需要用戶線程去不斷地發(fā)起系統(tǒng)調(diào)用去輪訓(xùn)Socket接收緩沖區(qū),這就需要用戶線程不斷地從用戶態(tài)切換到內(nèi)核態(tài),內(nèi)核態(tài)切換到用戶態(tài)。隨著并發(fā)量的增大,這個上下文切換的開銷也是巨大的。
所以單純的非阻塞IO模型還是無法適用于高并發(fā)的場景。只能適用于C10K以下的場景。
IO多路復(fù)用
在非阻塞IO這一小節(jié)的開頭,我們提到網(wǎng)絡(luò)IO模型的演變都是圍繞著---如何用盡可能少的線程去處理更多的連接這個核心需求開始展開的。
本小節(jié)我們來談?wù)?/span>IO多路復(fù)用模型,那么什么是多路?,什么又是復(fù)用呢?
我們還是以這個核心需求來對這兩個概念展開闡述:
-
多路:我們的核心需求是要用盡可能少的線程來處理盡可能多的連接,這里的
多路指的就是我們需要處理的眾多連接。 -
復(fù)用:核心需求要求我們使用
盡可能少的線程,盡可能少的系統(tǒng)開銷去處理盡可能多的連接(多路),那么這里的復(fù)用指的就是用有限的資源,比如用一個線程或者固定數(shù)量的線程去處理眾多連接上的讀寫事件。換句話說,在阻塞IO模型中一個連接就需要分配一個獨(dú)立的線程去專門處理這個連接上的讀寫,到了IO多路復(fù)用模型中,多個連接可以復(fù)用這一個獨(dú)立的線程去處理這多個連接上的讀寫。
好了,IO多路復(fù)用模型的概念解釋清楚了,那么問題的關(guān)鍵是我們?nèi)绾稳?shí)現(xiàn)這個復(fù)用,也就是如何讓一個獨(dú)立的線程去處理眾多連接上的讀寫事件呢?
這個問題其實(shí)在非阻塞IO模型中已經(jīng)給出了它的答案,在非阻塞IO模型中,利用非阻塞的系統(tǒng)IO調(diào)用去不斷的輪詢眾多連接的Socket接收緩沖區(qū)看是否有數(shù)據(jù)到來,如果有則處理,如果沒有則繼續(xù)輪詢下一個Socket。這樣就達(dá)到了用一個線程去處理眾多連接上的讀寫事件了。
但是非阻塞IO模型最大的問題就是需要不斷的發(fā)起系統(tǒng)調(diào)用去輪詢各個Socket中的接收緩沖區(qū)是否有數(shù)據(jù)到來,頻繁的系統(tǒng)調(diào)用隨之帶來了大量的上下文切換開銷。隨著并發(fā)量的提升,這樣也會導(dǎo)致非常嚴(yán)重的性能問題。
那么如何避免頻繁的系統(tǒng)調(diào)用同時又可以實(shí)現(xiàn)我們的核心需求呢?
這就需要操作系統(tǒng)的內(nèi)核來支持這樣的操作,我們可以把頻繁的輪詢操作交給操作系統(tǒng)內(nèi)核來替我們完成,這樣就避免了在用戶空間頻繁的去使用系統(tǒng)調(diào)用來輪詢所帶來的性能開銷。
正如我們所想,操作系統(tǒng)內(nèi)核也確實(shí)為我們提供了這樣的功能實(shí)現(xiàn),下面我們來一起看下操作系統(tǒng)對IO多路復(fù)用模型的實(shí)現(xiàn)。
select
select是操作系統(tǒng)內(nèi)核提供給我們使用的一個系統(tǒng)調(diào)用,它解決了在非阻塞IO模型中需要不斷的發(fā)起系統(tǒng)IO調(diào)用去輪詢各個連接上的Socket接收緩沖區(qū)所帶來的用戶空間與內(nèi)核空間不斷切換的系統(tǒng)開銷。
select系統(tǒng)調(diào)用將輪詢的操作交給了內(nèi)核來幫助我們完成,從而避免了在用戶空間不斷的發(fā)起輪詢所帶來的的系統(tǒng)性能開銷。
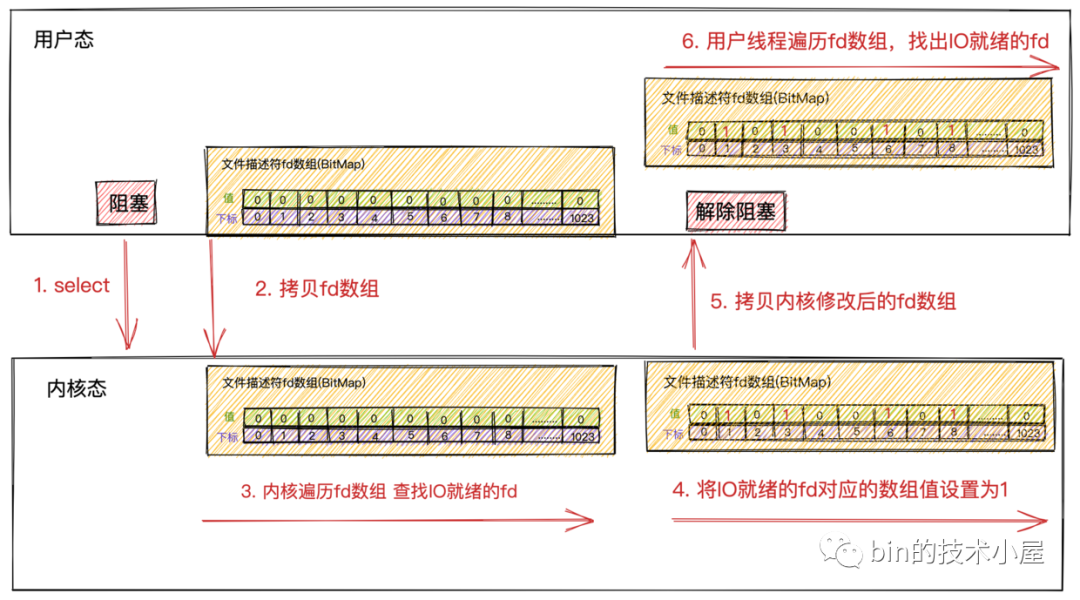 select.png
select.png-
首先用戶線程在發(fā)起
select系統(tǒng)調(diào)用的時候會阻塞在select系統(tǒng)調(diào)用上。此時,用戶線程從用戶態(tài)切換到了內(nèi)核態(tài)完成了一次上下文切換 -
用戶線程將需要監(jiān)聽的
Socket對應(yīng)的文件描述符fd數(shù)組通過select系統(tǒng)調(diào)用傳遞給內(nèi)核。此時,用戶線程將用戶空間中的文件描述符fd數(shù)組拷貝到內(nèi)核空間。
這里的文件描述符數(shù)組其實(shí)是一個BitMap,BitMap下標(biāo)為文件描述符fd,下標(biāo)對應(yīng)的值為:1表示該fd上有讀寫事件,0表示該fd上沒有讀寫事件。
 fd數(shù)組BitMap.png
fd數(shù)組BitMap.png
文件描述符fd其實(shí)就是一個整數(shù)值,在Linux中一切皆文件,Socket也是一個文件。描述進(jìn)程所有信息的數(shù)據(jù)結(jié)構(gòu)task_struct中有一個屬性struct files_struct *files,它最終指向了一個數(shù)組,數(shù)組里存放了進(jìn)程打開的所有文件列表,文件信息封裝在struct file結(jié)構(gòu)體中,這個數(shù)組存放的類型就是struct file結(jié)構(gòu)體,數(shù)組的下標(biāo)則是我們常說的文件描述符fd。
-
當(dāng)用戶線程調(diào)用完
select后開始進(jìn)入阻塞狀態(tài),內(nèi)核開始輪詢遍歷fd數(shù)組,查看fd對應(yīng)的Socket接收緩沖區(qū)中是否有數(shù)據(jù)到來。如果有數(shù)據(jù)到來,則將fd對應(yīng)BitMap的值設(shè)置為1。如果沒有數(shù)據(jù)到來,則保持值為0。
注意這里內(nèi)核會修改原始的
fd數(shù)組!!
-
內(nèi)核遍歷一遍
fd數(shù)組后,如果發(fā)現(xiàn)有些fd上有IO數(shù)據(jù)到來,則將修改后的fd數(shù)組返回給用戶線程。此時,會將fd數(shù)組從內(nèi)核空間拷貝到用戶空間。 -
當(dāng)內(nèi)核將修改后的
fd數(shù)組返回給用戶線程后,用戶線程解除阻塞,由用戶線程開始遍歷fd數(shù)組然后找出fd數(shù)組中值為1的Socket文件描述符。最后對這些Socket發(fā)起系統(tǒng)調(diào)用讀取數(shù)據(jù)。
select不會告訴用戶線程具體哪些fd上有IO數(shù)據(jù)到來,只是在IO活躍的fd上打上標(biāo)記,將打好標(biāo)記的完整fd數(shù)組返回給用戶線程,所以用戶線程還需要遍歷fd數(shù)組找出具體哪些fd上有IO數(shù)據(jù)到來。
-
由于內(nèi)核在遍歷的過程中已經(jīng)修改了
fd數(shù)組,所以在用戶線程遍歷完fd數(shù)組后獲取到IO就緒的Socket后,就需要重置fd數(shù)組,并重新調(diào)用select傳入重置后的fd數(shù)組,讓內(nèi)核發(fā)起新的一輪遍歷輪詢。
API介紹
當(dāng)我們熟悉了select的原理后,就很容易理解內(nèi)核給我們提供的select API了。
intselect(intmaxfdp1,fd_set*readset,fd_set*writeset,fd_set*exceptset,conststructtimeval*timeout)
從select API中我們可以看到,select系統(tǒng)調(diào)用是在規(guī)定的超時時間內(nèi),監(jiān)聽(輪詢)用戶感興趣的文件描述符集合上的可讀,可寫,異常三類事件。
-
maxfdp1 :select傳遞給內(nèi)核監(jiān)聽的文件描述符集合中數(shù)值最大的文件描述符+1,目的是用于限定內(nèi)核遍歷范圍。比如:select監(jiān)聽的文件描述符集合為{0,1,2,3,4},那么maxfdp1的值為5。 -
fd_set *readset:對可讀事件感興趣的文件描述符集合。 -
fd_set *writeset:對可寫事件感興趣的文件描述符集合。 -
fd_set *exceptset:對可寫事件感興趣的文件描述符集合。
這里的
fd_set就是我們前邊提到的文件描述符數(shù)組,是一個BitMap結(jié)構(gòu)。
-
const struct timeval *timeout:select系統(tǒng)調(diào)用超時時間,在這段時間內(nèi),內(nèi)核如果沒有發(fā)現(xiàn)有IO就緒的文件描述符,就直接返回。
上小節(jié)提到,在內(nèi)核遍歷完fd數(shù)組后,發(fā)現(xiàn)有IO就緒的fd,則會將該fd對應(yīng)的BitMap中的值設(shè)置為1,并將修改后的fd數(shù)組,返回給用戶線程。
在用戶線程中需要重新遍歷fd數(shù)組,找出IO就緒的fd出來,然后發(fā)起真正的讀寫調(diào)用。
下面介紹下在用戶線程中重新遍歷fd數(shù)組的過程中,我們需要用到的API:
-
void FD_ZERO(fd_set *fdset):清空指定的文件描述符集合,即讓fd_set中不在包含任何文件描述符。 -
void FD_SET(int fd, fd_set *fdset):將一個給定的文件描述符加入集合之中。
每次調(diào)用
select之前都要通過FD_ZERO和FD_SET重新設(shè)置文件描述符,因?yàn)槲募枋龇蠒?/span>內(nèi)核中被修改。
-
int FD_ISSET(int fd, fd_set *fdset):檢查集合中指定的文件描述符是否可以讀寫。用戶線程遍歷文件描述符集合,調(diào)用該方法檢查相應(yīng)的文件描述符是否IO就緒。 -
void FD_CLR(int fd, fd_set *fdset):將一個給定的文件描述符從集合中刪除
性能開銷
雖然select解決了非阻塞IO模型中頻繁發(fā)起系統(tǒng)調(diào)用的問題,但是在整個select工作過程中,我們還是看出了select有些不足的地方。
-
在發(fā)起
select系統(tǒng)調(diào)用以及返回時,用戶線程各發(fā)生了一次用戶態(tài)到內(nèi)核態(tài)以及內(nèi)核態(tài)到用戶態(tài)的上下文切換開銷。發(fā)生2次上下文切換 -
在發(fā)起
select系統(tǒng)調(diào)用以及返回時,用戶線程在內(nèi)核態(tài)需要將文件描述符集合從用戶空間拷貝到內(nèi)核空間。以及在內(nèi)核修改完文件描述符集合后,又要將它從內(nèi)核空間拷貝到用戶空間。發(fā)生2次文件描述符集合的拷貝 -
雖然由原來在
用戶空間發(fā)起輪詢優(yōu)化成了在內(nèi)核空間發(fā)起輪詢但select不會告訴用戶線程到底是哪些Socket上發(fā)生了IO就緒事件,只是對IO就緒的Socket作了標(biāo)記,用戶線程依然要遍歷文件描述符集合去查找具體IO就緒的Socket。時間復(fù)雜度依然為O(n)。
大部分情況下,網(wǎng)絡(luò)連接并不總是活躍的,如果
select監(jiān)聽了大量的客戶端連接,只有少數(shù)的連接活躍,然而使用輪詢的這種方式會隨著連接數(shù)的增大,效率會越來越低。
-
內(nèi)核會對原始的文件描述符集合進(jìn)行修改。導(dǎo)致每次在用戶空間重新發(fā)起select調(diào)用時,都需要對文件描述符集合進(jìn)行重置。 -
BitMap結(jié)構(gòu)的文件描述符集合,長度為固定的1024,所以只能監(jiān)聽0~1023的文件描述符。 -
select系統(tǒng)調(diào)用 不是線程安全的。
以上select的不足所產(chǎn)生的性能開銷都會隨著并發(fā)量的增大而線性增長。
很明顯select也不能解決C10K問題,只適用于1000個左右的并發(fā)連接場景。
poll
poll相當(dāng)于是改進(jìn)版的select,但是工作原理基本和select沒有本質(zhì)的區(qū)別。
intpoll(structpollfd*fds,unsignedintnfds,inttimeout)
structpollfd{
intfd;/*文件描述符*/
shortevents;/*需要監(jiān)聽的事件*/
shortrevents;/*實(shí)際發(fā)生的事件由內(nèi)核修改設(shè)置*/
};
select中使用的文件描述符集合是采用的固定長度為1024的BitMap結(jié)構(gòu)的fd_set,而poll換成了一個pollfd結(jié)構(gòu)沒有固定長度的數(shù)組,這樣就沒有了最大描述符數(shù)量的限制(當(dāng)然還會受到系統(tǒng)文件描述符限制)
poll只是改進(jìn)了select只能監(jiān)聽1024個文件描述符的數(shù)量限制,但是并沒有在性能方面做出改進(jìn)。和select上本質(zhì)并沒有多大差別。
-
同樣需要在
內(nèi)核空間和用戶空間中對文件描述符集合進(jìn)行輪詢,查找出IO就緒的Socket的時間復(fù)雜度依然為O(n)。 -
同樣需要將
包含大量文件描述符的集合整體在用戶空間和內(nèi)核空間之間來回復(fù)制,無論這些文件描述符是否就緒。他們的開銷都會隨著文件描述符數(shù)量的增加而線性增大。 -
select,poll在每次新增,刪除需要監(jiān)聽的socket時,都需要將整個新的socket集合全量傳至內(nèi)核。
poll同樣不適用高并發(fā)的場景。依然無法解決C10K問題。
epoll
通過上邊對select,poll核心原理的介紹,我們看到select,poll的性能瓶頸主要體現(xiàn)在下面三個地方:
-
因?yàn)閮?nèi)核不會保存我們要監(jiān)聽的
socket集合,所以在每次調(diào)用select,poll的時候都需要傳入,傳出全量的socket文件描述符集合。這導(dǎo)致了大量的文件描述符在用戶空間和內(nèi)核空間頻繁的來回復(fù)制。 -
由于內(nèi)核不會通知具體
IO就緒的socket,只是在這些IO就緒的socket上打好標(biāo)記,所以當(dāng)select系統(tǒng)調(diào)用返回時,在用戶空間還是需要完整遍歷一遍socket文件描述符集合來獲取具體IO就緒的socket。 -
在
內(nèi)核空間中也是通過遍歷的方式來得到IO就緒的socket。
下面我們來看下epoll是如何解決這些問題的。在介紹epoll的核心原理之前,我們需要介紹下理解epoll工作過程所需要的一些核心基礎(chǔ)知識。
Socket的創(chuàng)建
服務(wù)端線程調(diào)用accept系統(tǒng)調(diào)用后開始阻塞,當(dāng)有客戶端連接上來并完成TCP三次握手后,內(nèi)核會創(chuàng)建一個對應(yīng)的Socket作為服務(wù)端與客戶端通信的內(nèi)核接口。
在Linux內(nèi)核的角度看來,一切皆是文件,Socket也不例外,當(dāng)內(nèi)核創(chuàng)建出Socket之后,會將這個Socket放到當(dāng)前進(jìn)程所打開的文件列表中管理起來。
下面我們來看下進(jìn)程管理這些打開的文件列表相關(guān)的內(nèi)核數(shù)據(jù)結(jié)構(gòu)是什么樣的?在了解完這些數(shù)據(jù)結(jié)構(gòu)后,我們會更加清晰的理解Socket在內(nèi)核中所發(fā)揮的作用。并且對后面我們理解epoll的創(chuàng)建過程有很大的幫助。
進(jìn)程中管理文件列表結(jié)構(gòu)
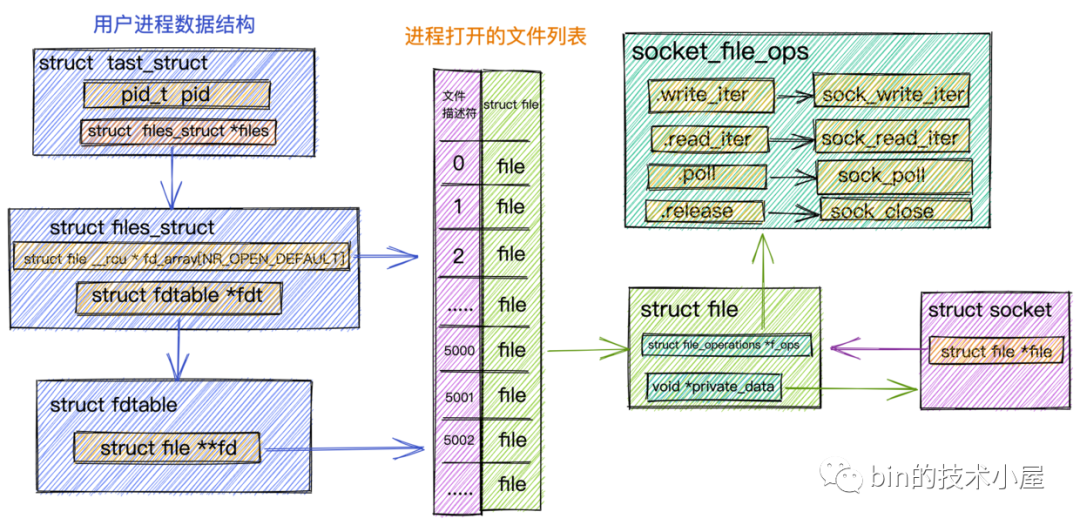 進(jìn)程中管理文件列表結(jié)構(gòu).png
進(jìn)程中管理文件列表結(jié)構(gòu).png
struct tast_struct是內(nèi)核中用來表示進(jìn)程的一個數(shù)據(jù)結(jié)構(gòu),它包含了進(jìn)程的所有信息。本小節(jié)我們只列出和文件管理相關(guān)的屬性。
其中進(jìn)程內(nèi)打開的所有文件是通過一個數(shù)組fd_array來進(jìn)行組織管理,數(shù)組的下標(biāo)即為我們常提到的文件描述符,數(shù)組中存放的是對應(yīng)的文件數(shù)據(jù)結(jié)構(gòu)struct file。每打開一個文件,內(nèi)核都會創(chuàng)建一個struct file與之對應(yīng),并在fd_array中找到一個空閑位置分配給它,數(shù)組中對應(yīng)的下標(biāo),就是我們在用戶空間用到的文件描述符。
對于任何一個進(jìn)程,默認(rèn)情況下,文件描述符
0表示stdin 標(biāo)準(zhǔn)輸入,文件描述符1表示stdout 標(biāo)準(zhǔn)輸出,文件描述符2表示stderr 標(biāo)準(zhǔn)錯誤輸出。
進(jìn)程中打開的文件列表fd_array定義在內(nèi)核數(shù)據(jù)結(jié)構(gòu)struct files_struct中,在struct fdtable結(jié)構(gòu)中有一個指針struct fd **fd指向fd_array。
由于本小節(jié)討論的是內(nèi)核網(wǎng)絡(luò)系統(tǒng)部分的數(shù)據(jù)結(jié)構(gòu),所以這里拿Socket文件類型來舉例說明:
用于封裝文件元信息的內(nèi)核數(shù)據(jù)結(jié)構(gòu)struct file中的private_data指針指向具體的Socket結(jié)構(gòu)。
struct file中的file_operations屬性定義了文件的操作函數(shù),不同的文件類型,對應(yīng)的file_operations是不同的,針對Socket文件類型,這里的file_operations指向socket_file_ops。
我們在
用戶空間對Socket發(fā)起的讀寫等系統(tǒng)調(diào)用,進(jìn)入內(nèi)核首先會調(diào)用的是Socket對應(yīng)的struct file中指向的socket_file_ops。比如:對Socket發(fā)起write寫操作,在內(nèi)核中首先被調(diào)用的就是socket_file_ops中定義的sock_write_iter。Socket發(fā)起read讀操作內(nèi)核中對應(yīng)的則是sock_read_iter。
staticconststructfile_operationssocket_file_ops={
.owner=THIS_MODULE,
.llseek=no_llseek,
.read_iter=sock_read_iter,
.write_iter=sock_write_iter,
.poll=sock_poll,
.unlocked_ioctl=sock_ioctl,
.mmap=sock_mmap,
.release=sock_close,
.fasync=sock_fasync,
.sendpage=sock_sendpage,
.splice_write=generic_splice_sendpage,
.splice_read=sock_splice_read,
};
Socket內(nèi)核結(jié)構(gòu)
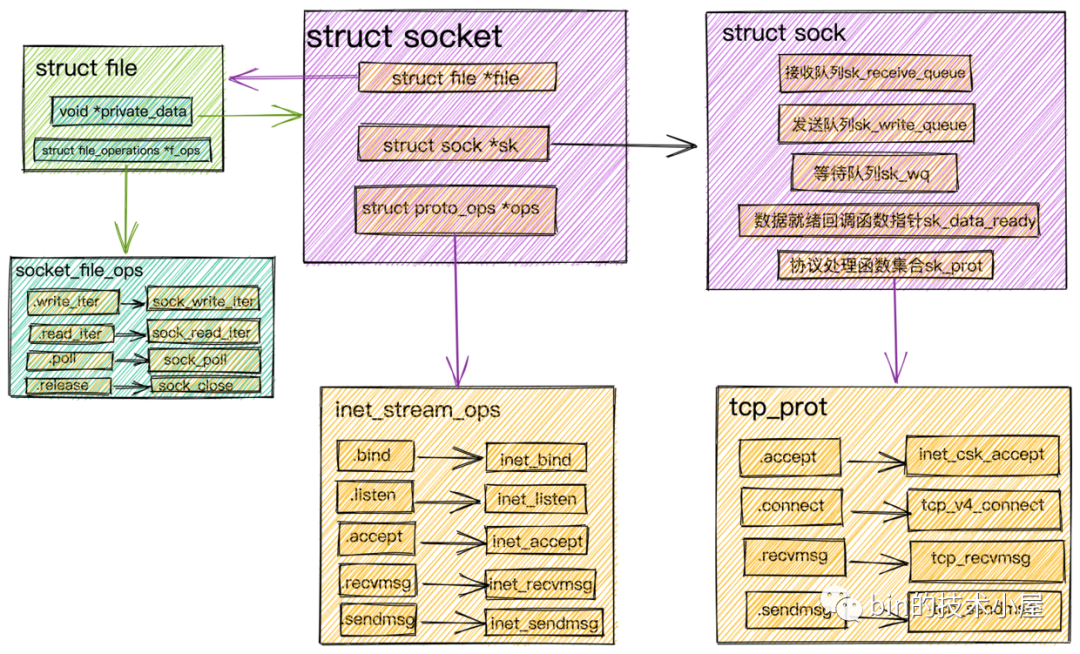 Socket內(nèi)核結(jié)構(gòu).png
Socket內(nèi)核結(jié)構(gòu).png
在我們進(jìn)行網(wǎng)絡(luò)程序的編寫時會首先創(chuàng)建一個Socket,然后基于這個Socket進(jìn)行bind,listen,我們先將這個Socket稱作為監(jiān)聽Socket。
-
當(dāng)我們調(diào)用
accept后,內(nèi)核會基于監(jiān)聽Socket創(chuàng)建出來一個新的Socket專門用于與客戶端之間的網(wǎng)絡(luò)通信。并將監(jiān)聽Socket中的Socket操作函數(shù)集合(inet_stream_ops)ops賦值到新的Socket的ops屬性中。
conststructproto_opsinet_stream_ops={
.bind=inet_bind,
.connect=inet_stream_connect,
.accept=inet_accept,
.poll=tcp_poll,
.listen=inet_listen,
.sendmsg=inet_sendmsg,
.recvmsg=inet_recvmsg,
......
}
這里需要注意的是,
監(jiān)聽的 socket和真正用來網(wǎng)絡(luò)通信的Socket,是兩個 Socket,一個叫作監(jiān)聽 Socket,一個叫作已連接的Socket。
-
接著內(nèi)核會為
已連接的Socket創(chuàng)建struct file并初始化,并把Socket文件操作函數(shù)集合(socket_file_ops)賦值給struct file中的f_ops指針。然后將struct socket中的file指針指向這個新分配申請的struct file結(jié)構(gòu)體。
內(nèi)核會維護(hù)兩個隊(duì)列:
- 一個是已經(jīng)完成
TCP三次握手,連接狀態(tài)處于established的連接隊(duì)列。內(nèi)核中為icsk_accept_queue。- 一個是還沒有完成
TCP三次握手,連接狀態(tài)處于syn_rcvd的半連接隊(duì)列。
-
然后調(diào)用
socket->ops->accept,從Socket內(nèi)核結(jié)構(gòu)圖中我們可以看到其實(shí)調(diào)用的是inet_accept,該函數(shù)會在icsk_accept_queue中查找是否有已經(jīng)建立好的連接,如果有的話,直接從icsk_accept_queue中獲取已經(jīng)創(chuàng)建好的struct sock。并將這個struct sock對象賦值給struct socket中的sock指針。
struct sock在struct socket中是一個非常核心的內(nèi)核對象,正是在這里定義了我們在介紹網(wǎng)絡(luò)包的接收發(fā)送流程中提到的接收隊(duì)列,發(fā)送隊(duì)列,等待隊(duì)列,數(shù)據(jù)就緒回調(diào)函數(shù)指針,內(nèi)核協(xié)議棧操作函數(shù)集合
-
根據(jù)創(chuàng)建
Socket時發(fā)起的系統(tǒng)調(diào)用sock_create中的protocol參數(shù)(對于TCP協(xié)議這里的參數(shù)值為SOCK_STREAM)查找到對于 tcp 定義的操作方法實(shí)現(xiàn)集合inet_stream_ops和tcp_prot。并把它們分別設(shè)置到socket->ops和sock->sk_prot上。
這里可以回看下本小節(jié)開頭的《Socket內(nèi)核結(jié)構(gòu)圖》捋一下他們之間的關(guān)系。
socket相關(guān)的操作接口定義在inet_stream_ops函數(shù)集合中,負(fù)責(zé)對上給用戶提供接口。而socket與內(nèi)核協(xié)議棧之間的操作接口定義在struct sock中的sk_prot指針上,這里指向tcp_prot協(xié)議操作函數(shù)集合。
structprototcp_prot={
.name="TCP",
.owner=THIS_MODULE,
.close=tcp_close,
.connect=tcp_v4_connect,
.disconnect=tcp_disconnect,
.accept=inet_csk_accept,
.keepalive=tcp_set_keepalive,
.recvmsg=tcp_recvmsg,
.sendmsg=tcp_sendmsg,
.backlog_rcv=tcp_v4_do_rcv,
......
}
之前提到的對
Socket發(fā)起的系統(tǒng)IO調(diào)用,在內(nèi)核中首先會調(diào)用Socket的文件結(jié)構(gòu)struct file中的file_operations文件操作集合,然后調(diào)用struct socket中的ops指向的inet_stream_opssocket操作函數(shù),最終調(diào)用到struct sock中sk_prot指針指向的tcp_prot內(nèi)核協(xié)議棧操作函數(shù)接口集合。
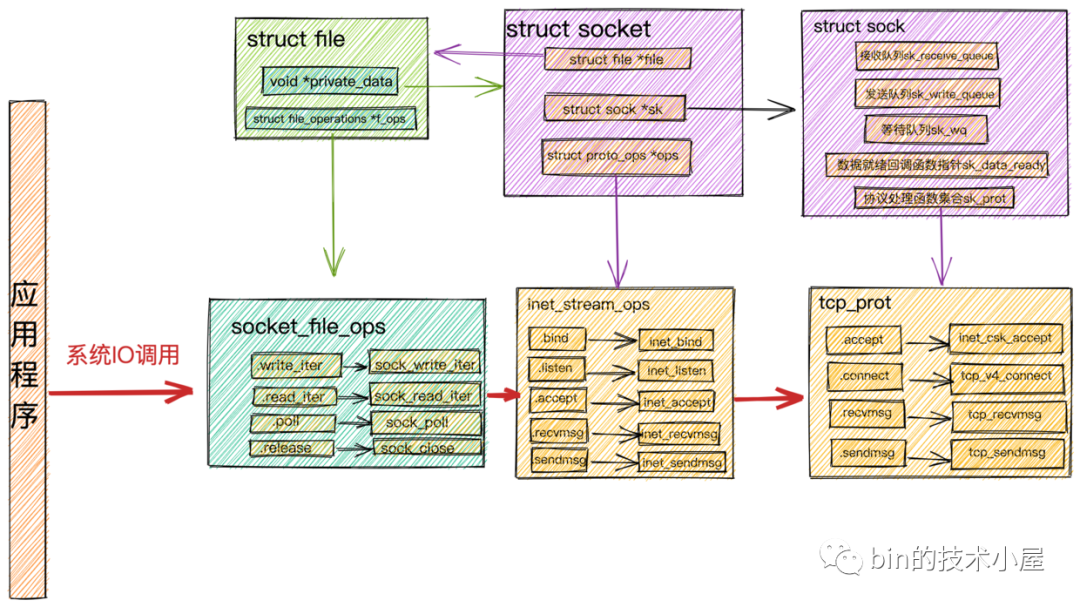 系統(tǒng)IO調(diào)用結(jié)構(gòu).png
系統(tǒng)IO調(diào)用結(jié)構(gòu).png-
將
struct sock對象中的sk_data_ready函數(shù)指針設(shè)置為sock_def_readable,在Socket數(shù)據(jù)就緒的時候內(nèi)核會回調(diào)該函數(shù)。 -
struct sock中的等待隊(duì)列中存放的是系統(tǒng)IO調(diào)用發(fā)生阻塞的進(jìn)程fd,以及相應(yīng)的回調(diào)函數(shù)。記住這個地方,后邊介紹epoll的時候我們還會提到!
-
當(dāng)
struct file,struct socket,struct sock這些核心的內(nèi)核對象創(chuàng)建好之后,最后就是把socket對象對應(yīng)的struct file放到進(jìn)程打開的文件列表fd_array中。隨后系統(tǒng)調(diào)用accept返回socket的文件描述符fd給用戶程序。
阻塞IO中用戶進(jìn)程阻塞以及喚醒原理
在前邊小節(jié)我們介紹阻塞IO的時候提到,當(dāng)用戶進(jìn)程發(fā)起系統(tǒng)IO調(diào)用時,這里我們拿read舉例,用戶進(jìn)程會在內(nèi)核態(tài)查看對應(yīng)Socket接收緩沖區(qū)是否有數(shù)據(jù)到來。
-
Socket接收緩沖區(qū)有數(shù)據(jù),則拷貝數(shù)據(jù)到用戶空間,系統(tǒng)調(diào)用返回。 -
Socket接收緩沖區(qū)沒有數(shù)據(jù),則用戶進(jìn)程讓出CPU進(jìn)入阻塞狀態(tài),當(dāng)數(shù)據(jù)到達(dá)接收緩沖區(qū)時,用戶進(jìn)程會被喚醒,從阻塞狀態(tài)進(jìn)入就緒狀態(tài),等待CPU調(diào)度。
本小節(jié)我們就來看下用戶進(jìn)程是如何阻塞在Socket上,又是如何在Socket上被喚醒的。理解這個過程很重要,對我們理解epoll的事件通知過程很有幫助
-
首先我們在用戶進(jìn)程中對
Socket進(jìn)行read系統(tǒng)調(diào)用時,用戶進(jìn)程會從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài)。 -
在進(jìn)程的
struct task_struct結(jié)構(gòu)找到fd_array,并根據(jù)Socket的文件描述符fd找到對應(yīng)的struct file,調(diào)用struct file中的文件操作函數(shù)結(jié)合file_operations,read系統(tǒng)調(diào)用對應(yīng)的是sock_read_iter。 -
在
sock_read_iter函數(shù)中找到struct file指向的struct socket,并調(diào)用socket->ops->recvmsg,這里我們知道調(diào)用的是inet_stream_ops集合中定義的inet_recvmsg。 -
在
inet_recvmsg中會找到struct sock,并調(diào)用sock->skprot->recvmsg,這里調(diào)用的是tcp_prot集合中定義的tcp_recvmsg函數(shù)。
整個調(diào)用過程可以參考上邊的《系統(tǒng)IO調(diào)用結(jié)構(gòu)圖》
熟悉了內(nèi)核函數(shù)調(diào)用棧后,我們來看下系統(tǒng)IO調(diào)用在tcp_recvmsg內(nèi)核函數(shù)中是如何將用戶進(jìn)程給阻塞掉的
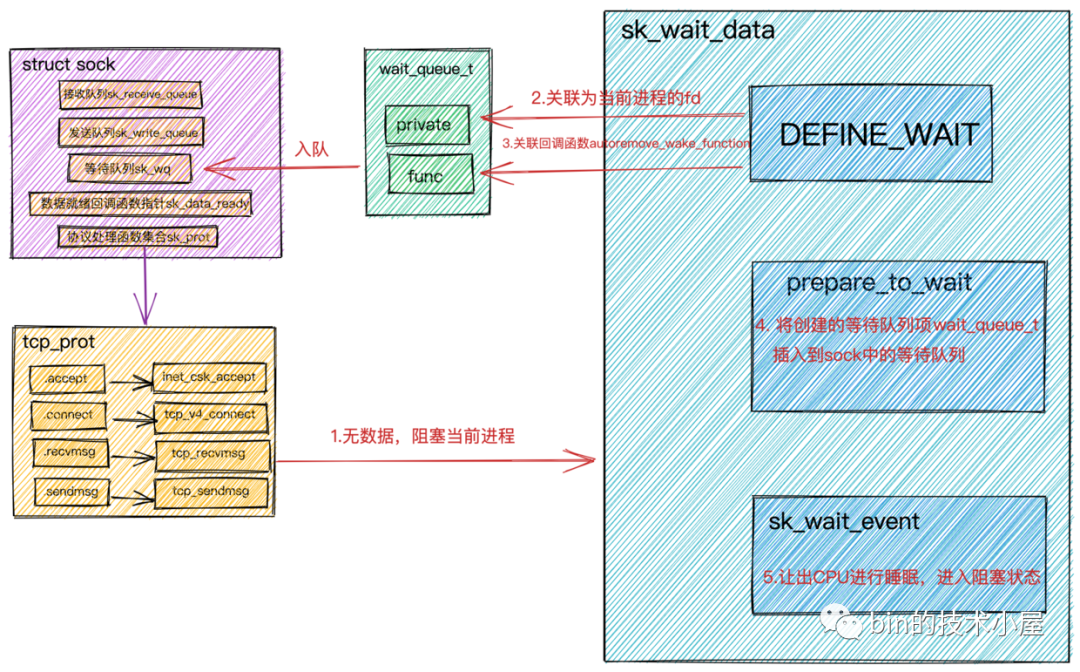 系統(tǒng)IO調(diào)用阻塞原理.png
系統(tǒng)IO調(diào)用阻塞原理.png
inttcp_recvmsg(structkiocb*iocb,structsock*sk,structmsghdr*msg,
size_tlen,intnonblock,intflags,int*addr_len)
{
.................省略非核心代碼...............
//訪問sock對象中定義的接收隊(duì)列
skb_queue_walk(&sk->sk_receive_queue,skb){
.................省略非核心代碼...............
//沒有收到足夠數(shù)據(jù),調(diào)用sk_wait_data阻塞當(dāng)前進(jìn)程
sk_wait_data(sk,&timeo);
}
intsk_wait_data(structsock*sk,long*timeo)
{
//創(chuàng)建structsock中等待隊(duì)列上的元素wait_queue_t
//將進(jìn)程描述符和回調(diào)函數(shù)autoremove_wake_function關(guān)聯(lián)到wait_queue_t中
DEFINE_WAIT(wait);
//調(diào)用sk_sleep獲取sock對象下的等待隊(duì)列的頭指針wait_queue_head_t
//調(diào)用prepare_to_wait將新創(chuàng)建的等待項(xiàng)wait_queue_t插入到等待隊(duì)列中,并將進(jìn)程狀態(tài)設(shè)置為可打斷INTERRUPTIBLE
prepare_to_wait(sk_sleep(sk),&wait,TASK_INTERRUPTIBLE);
set_bit(SOCK_ASYNC_WAITDATA,&sk->sk_socket->flags);
//通過調(diào)用schedule_timeout讓出CPU,然后進(jìn)行睡眠,導(dǎo)致一次上下文切換
rc=sk_wait_event(sk,timeo,!skb_queue_empty(&sk->sk_receive_queue));
...
-
首先會在
DEFINE_WAIT中創(chuàng)建struct sock中等待隊(duì)列上的等待類型wait_queue_t。
#defineDEFINE_WAIT(name)DEFINE_WAIT_FUNC(name,autoremove_wake_function)
#defineDEFINE_WAIT_FUNC(name,function)
wait_queue_tname={
.private=current,
.func=function,
.task_list=LIST_HEAD_INIT((name).task_list),
}
等待類型wait_queue_t中的private用來關(guān)聯(lián)阻塞在當(dāng)前socket上的用戶進(jìn)程fd。func用來關(guān)聯(lián)等待項(xiàng)上注冊的回調(diào)函數(shù)。這里注冊的是autoremove_wake_function。
-
調(diào)用
sk_sleep(sk)獲取struct sock對象中的等待隊(duì)列頭指針wait_queue_head_t。 -
調(diào)用
prepare_to_wait將新創(chuàng)建的等待項(xiàng)wait_queue_t插入到等待隊(duì)列中,并將進(jìn)程設(shè)置為可打斷INTERRUPTIBL。 -
調(diào)用
sk_wait_event讓出CPU,進(jìn)程進(jìn)入睡眠狀態(tài)。
用戶進(jìn)程的阻塞過程我們就介紹完了,關(guān)鍵是要理解記住struct sock中定義的等待隊(duì)列上的等待類型wait_queue_t的結(jié)構(gòu)。后面epoll的介紹中我們還會用到它。
下面我們接著介紹當(dāng)數(shù)據(jù)就緒后,用戶進(jìn)程是如何被喚醒的
在本文開始介紹《網(wǎng)絡(luò)包接收過程》這一小節(jié)中我們提到:
-
當(dāng)網(wǎng)絡(luò)數(shù)據(jù)包到達(dá)網(wǎng)卡時,網(wǎng)卡通過
DMA的方式將數(shù)據(jù)放到RingBuffer中。 -
然后向CPU發(fā)起硬中斷,在硬中斷響應(yīng)程序中創(chuàng)建
sk_buffer,并將網(wǎng)絡(luò)數(shù)據(jù)拷貝至sk_buffer中。 -
隨后發(fā)起軟中斷,內(nèi)核線程
ksoftirqd響應(yīng)軟中斷,調(diào)用poll函數(shù)將sk_buffer送往內(nèi)核協(xié)議棧做層層協(xié)議處理。 -
在傳輸層
tcp_rcv 函數(shù)中,去掉TCP頭,根據(jù)四元組(源IP,源端口,目的IP,目的端口)查找對應(yīng)的Socket。 -
最后將
sk_buffer放到Socket中的接收隊(duì)列里。
上邊這些過程是內(nèi)核接收網(wǎng)絡(luò)數(shù)據(jù)的完整過程,下邊我們來看下,當(dāng)數(shù)據(jù)包接收完畢后,用戶進(jìn)程是如何被喚醒的。
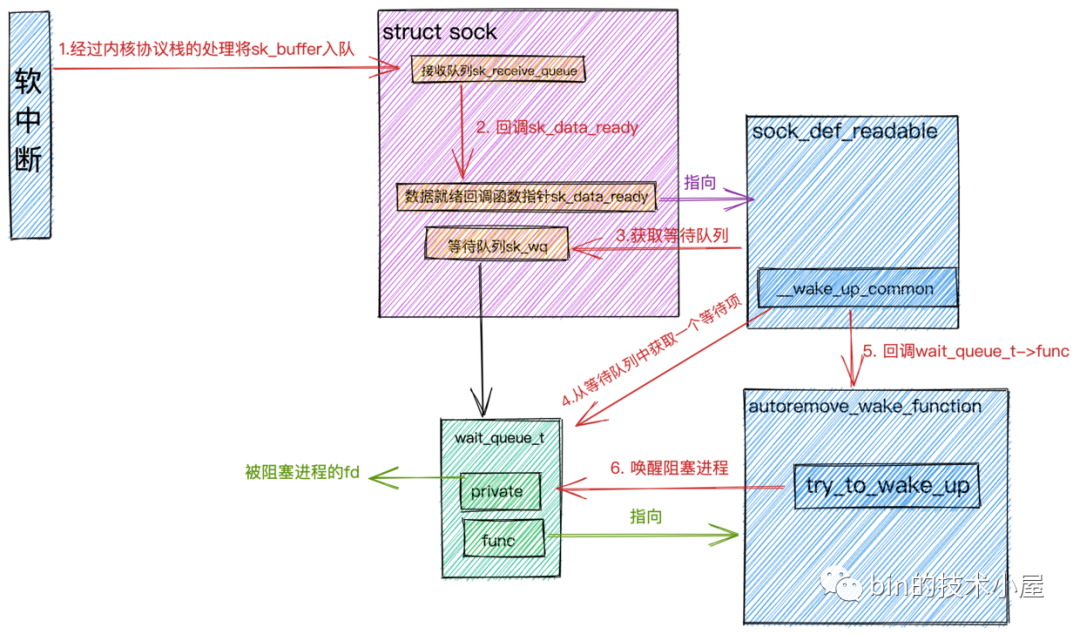 系統(tǒng)IO調(diào)用喚醒原理.png
系統(tǒng)IO調(diào)用喚醒原理.png-
當(dāng)軟中斷將
sk_buffer放到Socket的接收隊(duì)列上時,接著就會調(diào)用數(shù)據(jù)就緒函數(shù)回調(diào)指針sk_data_ready,前邊我們提到,這個函數(shù)指針在初始化的時候指向了sock_def_readable函數(shù)。 -
在
sock_def_readable函數(shù)中會去獲取socket->sock->sk_wq等待隊(duì)列。在wake_up_common函數(shù)中從等待隊(duì)列sk_wq中找出一個等待項(xiàng)wait_queue_t,回調(diào)注冊在該等待項(xiàng)上的func回調(diào)函數(shù)(wait_queue_t->func),創(chuàng)建等待項(xiàng)wait_queue_t是我們提到,這里注冊的回調(diào)函數(shù)是autoremove_wake_function。
即使是有多個進(jìn)程都阻塞在同一個 socket 上,也只喚醒 1 個進(jìn)程。其作用是為了避免驚群。
-
在
autoremove_wake_function函數(shù)中,根據(jù)等待項(xiàng)wait_queue_t上的private關(guān)聯(lián)的阻塞進(jìn)程fd調(diào)用try_to_wake_up喚醒阻塞在該Socket上的進(jìn)程。
記住
wait_queue_t中的func函數(shù)指針,在epoll中這里會注冊epoll的回調(diào)函數(shù)。
現(xiàn)在理解epoll所需要的基礎(chǔ)知識我們就介紹完了,嘮叨了這么多,下面終于正式進(jìn)入本小節(jié)的主題epoll了。
epoll_create創(chuàng)建epoll對象
epoll_create是內(nèi)核提供給我們創(chuàng)建epoll對象的一個系統(tǒng)調(diào)用,當(dāng)我們在用戶進(jìn)程中調(diào)用epoll_create時,內(nèi)核會為我們創(chuàng)建一個struct eventpoll對象,并且也有相應(yīng)的struct file與之關(guān)聯(lián),同樣需要把這個struct eventpoll對象所關(guān)聯(lián)的struct file放入進(jìn)程打開的文件列表fd_array中管理。
熟悉了
Socket的創(chuàng)建邏輯,epoll的創(chuàng)建邏輯也就不難理解了。
struct eventpoll對象關(guān)聯(lián)的struct file中的file_operations 指針指向的是eventpoll_fops操作函數(shù)集合。
staticconststructfile_operationseventpoll_fops={
.release=ep_eventpoll_release;
.poll=ep_eventpoll_poll,
}
 eopll在進(jìn)程中的整體結(jié)構(gòu).png
eopll在進(jìn)程中的整體結(jié)構(gòu).png
structeventpoll{
//等待隊(duì)列,阻塞在epoll上的進(jìn)程會放在這里
wait_queue_head_twq;
//就緒隊(duì)列,IO就緒的socket連接會放在這里
structlist_headrdllist;
//紅黑樹用來管理所有監(jiān)聽的socket連接
structrb_rootrbr;
......
}
-
wait_queue_head_t wq:epoll中的等待隊(duì)列,隊(duì)列里存放的是阻塞在epoll上的用戶進(jìn)程。在IO就緒的時候epoll可以通過這個隊(duì)列找到這些阻塞的進(jìn)程并喚醒它們,從而執(zhí)行IO調(diào)用讀寫Socket上的數(shù)據(jù)。
這里注意與
Socket中的等待隊(duì)列區(qū)分!!!
-
struct list_head rdllist:epoll中的就緒隊(duì)列,隊(duì)列里存放的是都是IO就緒的Socket,被喚醒的用戶進(jìn)程可以直接讀取這個隊(duì)列獲取IO活躍的Socket。無需再次遍歷整個Socket集合。
這里正是
epoll比select ,poll高效之處,select ,poll返回的是全部的socket連接,我們需要在用戶空間再次遍歷找出真正IO活躍的Socket連接。而epoll只是返回IO活躍的Socket連接。用戶進(jìn)程可以直接進(jìn)行IO操作。
-
struct rb_root rbr :由于紅黑樹在查找,插入,刪除等綜合性能方面是最優(yōu)的,所以epoll內(nèi)部使用一顆紅黑樹來管理海量的Socket連接。
select用數(shù)組管理連接,poll用鏈表管理連接。
epoll_ctl向epoll對象中添加監(jiān)聽的Socket
當(dāng)我們調(diào)用epoll_create在內(nèi)核中創(chuàng)建出epoll對象struct eventpoll后,我們就可以利用epoll_ctl向epoll中添加我們需要管理的Socket連接了。
-
首先要在epoll內(nèi)核中創(chuàng)建一個表示
Socket連接的數(shù)據(jù)結(jié)構(gòu)struct epitem,而在epoll中為了綜合性能的考慮,采用一顆紅黑樹來管理這些海量socket連接。所以struct epitem是一個紅黑樹節(jié)點(diǎn)。
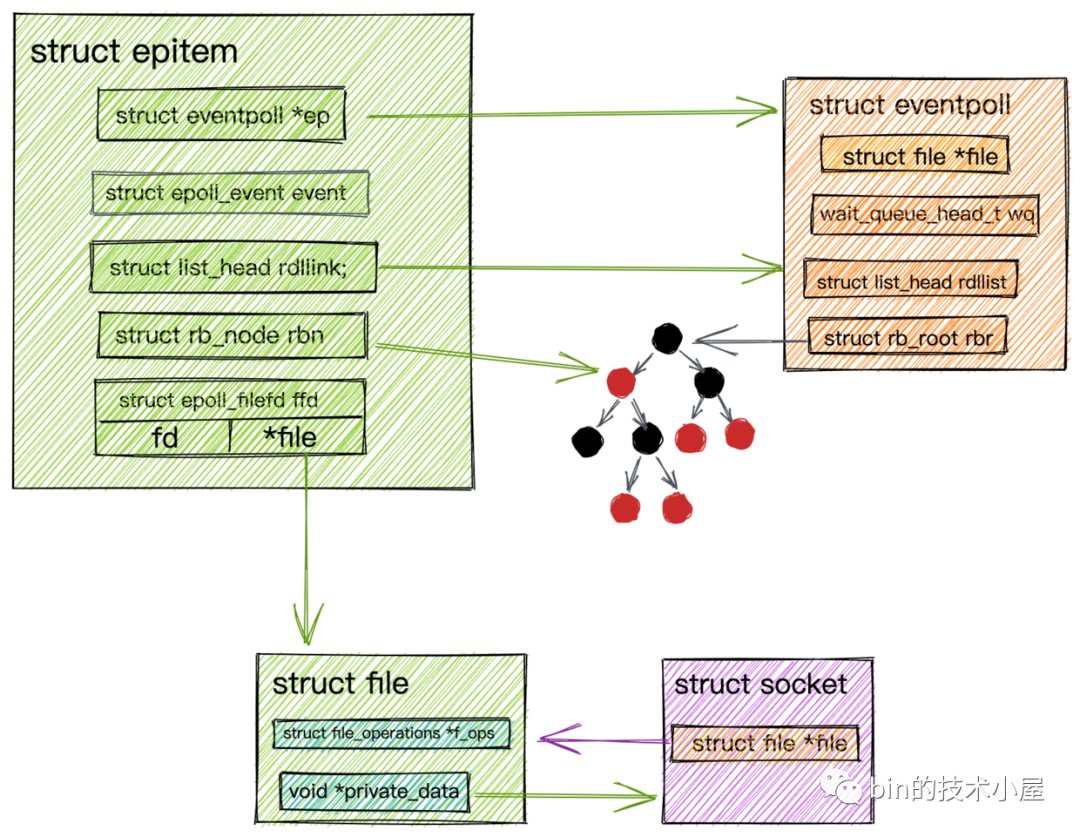 struct epitem.png
struct epitem.png
structepitem
{
//指向所屬epoll對象
structeventpoll*ep;
//注冊的感興趣的事件,也就是用戶空間的epoll_event
structepoll_eventevent;
//指向epoll對象中的就緒隊(duì)列
structlist_headrdllink;
//指向epoll中對應(yīng)的紅黑樹節(jié)點(diǎn)
structrb_noderbn;
//指向epitem所表示的socket->file結(jié)構(gòu)以及對應(yīng)的fd
structepoll_filefdffd;
}
這里重點(diǎn)記住
struct epitem結(jié)構(gòu)中的rdllink以及epoll_filefd成員,后面我們會用到。
-
在內(nèi)核中創(chuàng)建完表示
Socket連接的數(shù)據(jù)結(jié)構(gòu)struct epitem后,我們就需要在Socket中的等待隊(duì)列上創(chuàng)建等待項(xiàng)wait_queue_t并且注冊epoll的回調(diào)函數(shù)ep_poll_callback。
通過《阻塞IO中用戶進(jìn)程阻塞以及喚醒原理》小節(jié)的鋪墊,我想大家已經(jīng)猜到這一步的意義所在了吧!當(dāng)時在等待項(xiàng)wait_queue_t中注冊的是autoremove_wake_function回調(diào)函數(shù)。還記得嗎?
epoll的回調(diào)函數(shù)
ep_poll_callback正是epoll同步IO事件通知機(jī)制的核心所在,也是區(qū)別于select,poll采用內(nèi)核輪詢方式的根本性能差異所在。
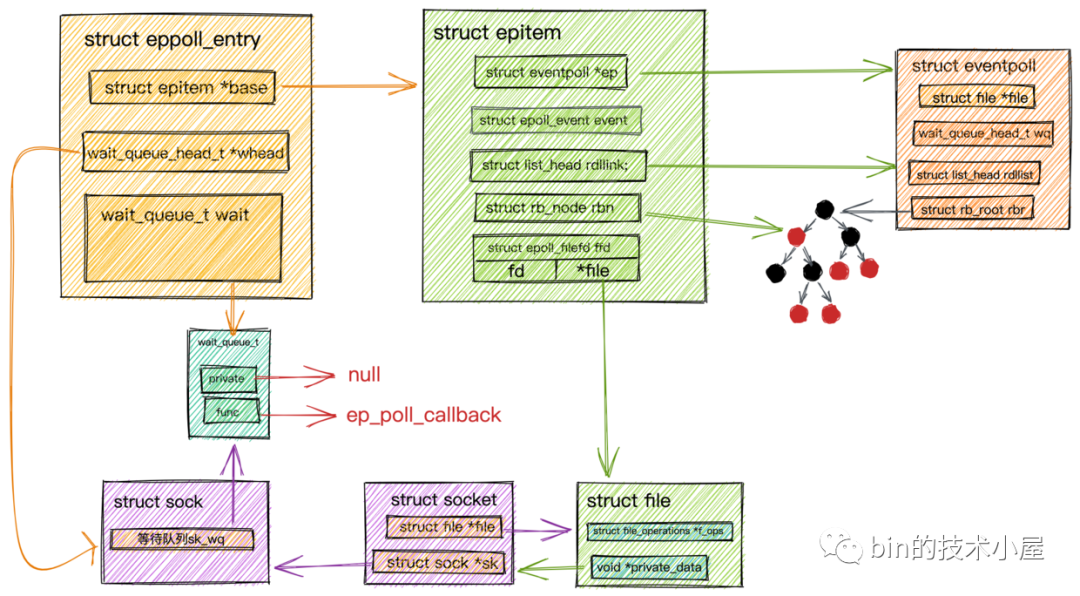 epitem創(chuàng)建等待項(xiàng).png
epitem創(chuàng)建等待項(xiàng).png
這里又出現(xiàn)了一個新的數(shù)據(jù)結(jié)構(gòu)struct eppoll_entry,那它的作用是干什么的呢?大家可以結(jié)合上圖先猜測下它的作用!
我們知道socket->sock->sk_wq等待隊(duì)列中的類型是wait_queue_t,我們需要在struct epitem所表示的socket的等待隊(duì)列上注冊epoll回調(diào)函數(shù)ep_poll_callback。
這樣當(dāng)數(shù)據(jù)到達(dá)socket中的接收隊(duì)列時,內(nèi)核會回調(diào)sk_data_ready,在阻塞IO中用戶進(jìn)程阻塞以及喚醒原理這一小節(jié)中,我們知道這個sk_data_ready函數(shù)指針會指向sk_def_readable函數(shù),在sk_def_readable中會回調(diào)注冊在等待隊(duì)列里的等待項(xiàng)wait_queue_t -> func回調(diào)函數(shù)ep_poll_callback。在ep_poll_callback中需要找到epitem,將IO就緒的epitem放入epoll中的就緒隊(duì)列中。
而socket等待隊(duì)列中類型是wait_queue_t無法關(guān)聯(lián)到epitem。所以就出現(xiàn)了struct eppoll_entry結(jié)構(gòu)體,它的作用就是關(guān)聯(lián)Socket等待隊(duì)列中的等待項(xiàng)wait_queue_t和epitem。
structeppoll_entry{
//指向關(guān)聯(lián)的epitem
structepitem*base;
//關(guān)聯(lián)監(jiān)聽socket中等待隊(duì)列中的等待項(xiàng)(private=nullfunc=ep_poll_callback)
wait_queue_twait;
//監(jiān)聽socket中等待隊(duì)列頭指針
wait_queue_head_t*whead;
.........
};
這樣在ep_poll_callback回調(diào)函數(shù)中就可以根據(jù)Socket等待隊(duì)列中的等待項(xiàng)wait,通過container_of宏找到eppoll_entry,繼而找到epitem了。
container_of在Linux內(nèi)核中是一個常用的宏,用于從包含在某個結(jié)構(gòu)中的指針獲得結(jié)構(gòu)本身的指針,通俗地講就是通過結(jié)構(gòu)體變量中某個成員的首地址進(jìn)而獲得整個結(jié)構(gòu)體變量的首地址。
這里需要注意下這次等待項(xiàng)
wait_queue_t中的private設(shè)置的是null,因?yàn)檫@里Socket是交給epoll來管理的,阻塞在Socket上的進(jìn)程是也由epoll來喚醒。在等待項(xiàng)wait_queue_t注冊的func是ep_poll_callback而不是autoremove_wake_function,阻塞進(jìn)程并不需要autoremove_wake_function來喚醒,所以這里設(shè)置private為null
-
當(dāng)在
Socket的等待隊(duì)列中創(chuàng)建好等待項(xiàng)wait_queue_t并且注冊了epoll的回調(diào)函數(shù)ep_poll_callback,然后又通過eppoll_entry關(guān)聯(lián)了epitem后。剩下要做的就是將epitem插入到epoll中的紅黑樹struct rb_root rbr中。
這里可以看到
epoll另一個優(yōu)化的地方,epoll將所有的socket連接通過內(nèi)核中的紅黑樹來集中管理。每次添加或者刪除socket連接都是增量添加刪除,而不是像select,poll那樣每次調(diào)用都是全量socket連接集合傳入內(nèi)核。避免了頻繁大量的內(nèi)存拷貝。
epoll_wait同步阻塞獲取IO就緒的Socket
-
用戶程序調(diào)用
epoll_wait后,內(nèi)核首先會查找epoll中的就緒隊(duì)列eventpoll->rdllist是否有IO就緒的epitem。epitem里封裝了socket的信息。如果就緒隊(duì)列中有就緒的epitem,就將就緒的socket信息封裝到epoll_event返回。 -
如果
eventpoll->rdllist就緒隊(duì)列中沒有IO就緒的epitem,則會創(chuàng)建等待項(xiàng)wait_queue_t,將用戶進(jìn)程的fd關(guān)聯(lián)到wait_queue_t->private上,并在等待項(xiàng)wait_queue_t->func上注冊回調(diào)函數(shù)default_wake_function。最后將等待項(xiàng)添加到epoll中的等待隊(duì)列中。用戶進(jìn)程讓出CPU,進(jìn)入阻塞狀態(tài)。
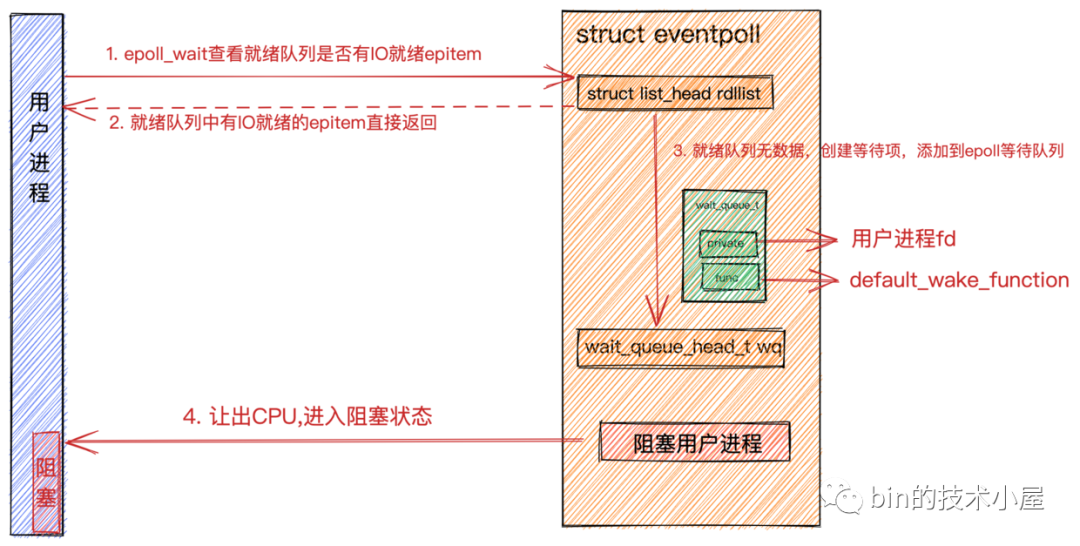 epoll_wait同步獲取數(shù)據(jù).png
epoll_wait同步獲取數(shù)據(jù).png這里和
阻塞IO模型中的阻塞原理是一樣的,只不過在阻塞IO模型中注冊到等待項(xiàng)wait_queue_t->func上的是autoremove_wake_function,并將等待項(xiàng)添加到socket中的等待隊(duì)列中。這里注冊的是default_wake_function,將等待項(xiàng)添加到epoll中的等待隊(duì)列上。
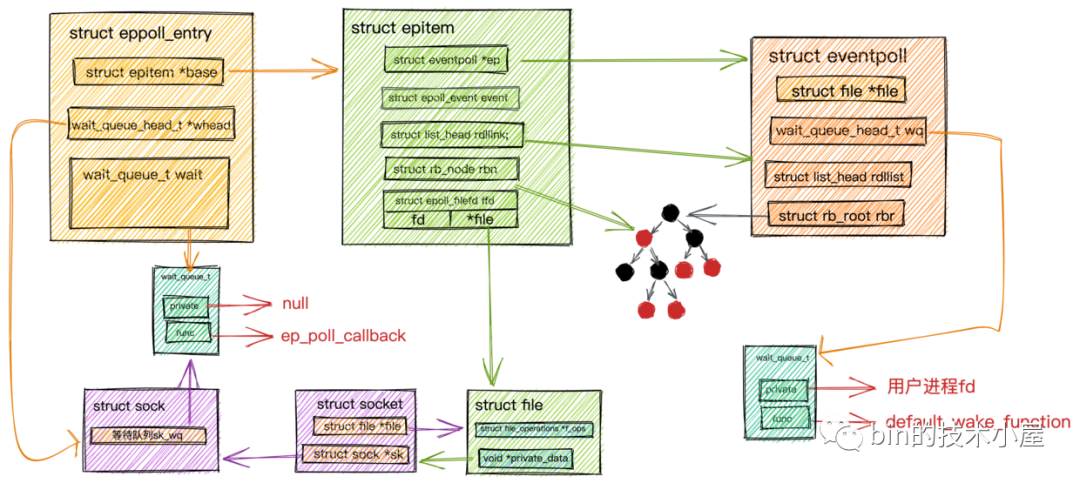 數(shù)據(jù)到來epoll_wait流程.png
數(shù)據(jù)到來epoll_wait流程.png-
前邊做了那么多的知識鋪墊,下面終于到了
epoll的整個工作流程了:
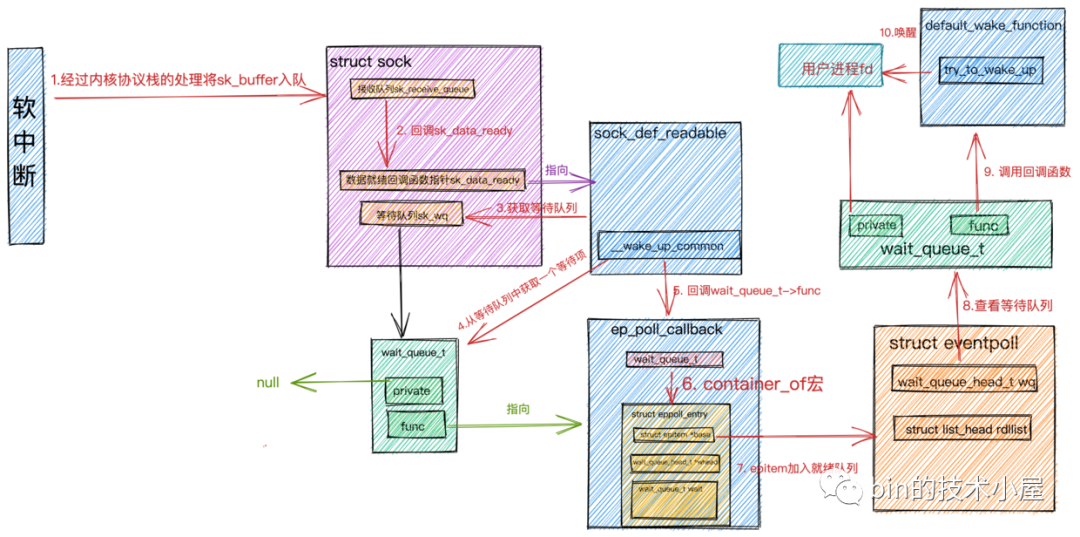 epoll_wait處理過程.png
epoll_wait處理過程.png-
當(dāng)網(wǎng)絡(luò)數(shù)據(jù)包在軟中斷中經(jīng)過內(nèi)核協(xié)議棧的處理到達(dá)
socket的接收緩沖區(qū)時,緊接著會調(diào)用socket的數(shù)據(jù)就緒回調(diào)指針sk_data_ready,回調(diào)函數(shù)為sock_def_readable。在socket的等待隊(duì)列中找出等待項(xiàng),其中等待項(xiàng)中注冊的回調(diào)函數(shù)為ep_poll_callback。 -
在回調(diào)函數(shù)
ep_poll_callback中,根據(jù)struct eppoll_entry中的struct wait_queue_t wait通過container_of宏找到eppoll_entry對象并通過它的base指針找到封裝socket的數(shù)據(jù)結(jié)構(gòu)struct epitem,并將它加入到epoll中的就緒隊(duì)列rdllist中。 -
隨后查看
epoll中的等待隊(duì)列中是否有等待項(xiàng),也就是說查看是否有進(jìn)程阻塞在epoll_wait上等待IO就緒的socket。如果沒有等待項(xiàng),則軟中斷處理完成。 -
如果有等待項(xiàng),則回到注冊在等待項(xiàng)中的回調(diào)函數(shù)
default_wake_function,在回調(diào)函數(shù)中喚醒阻塞進(jìn)程,并將就緒隊(duì)列rdllist中的epitem的IO就緒socket信息封裝到struct epoll_event中返回。 -
用戶進(jìn)程拿到
epoll_event獲取IO就緒的socket,發(fā)起系統(tǒng)IO調(diào)用讀取數(shù)據(jù)。
再談水平觸發(fā)和邊緣觸發(fā)
網(wǎng)上有大量的關(guān)于這兩種模式的講解,大部分講的比較模糊,感覺只是強(qiáng)行從概念上進(jìn)行描述,看完讓人難以理解。所以在這里,筆者想結(jié)合上邊epoll的工作過程,再次對這兩種模式做下自己的解讀,力求清晰的解釋出這兩種工作模式的異同。
經(jīng)過上邊對epoll工作過程的詳細(xì)解讀,我們知道,當(dāng)我們監(jiān)聽的socket上有數(shù)據(jù)到來時,軟中斷會執(zhí)行epoll的回調(diào)函數(shù)ep_poll_callback,在回調(diào)函數(shù)中會將epoll中描述socket信息的數(shù)據(jù)結(jié)構(gòu)epitem插入到epoll中的就緒隊(duì)列rdllist中。隨后用戶進(jìn)程從epoll的等待隊(duì)列中被喚醒,epoll_wait將IO就緒的socket返回給用戶進(jìn)程,隨即epoll_wait會清空rdllist。
水平觸發(fā)和邊緣觸發(fā)最關(guān)鍵的區(qū)別就在于當(dāng)socket中的接收緩沖區(qū)還有數(shù)據(jù)可讀時。epoll_wait是否會清空rdllist。
-
水平觸發(fā):在這種模式下,用戶線程調(diào)用
epoll_wait獲取到IO就緒的socket后,對Socket進(jìn)行系統(tǒng)IO調(diào)用讀取數(shù)據(jù),假設(shè)socket中的數(shù)據(jù)只讀了一部分沒有全部讀完,這時再次調(diào)用epoll_wait,epoll_wait會檢查這些Socket中的接收緩沖區(qū)是否還有數(shù)據(jù)可讀,如果還有數(shù)據(jù)可讀,就將socket重新放回rdllist。所以當(dāng)socket上的IO沒有被處理完時,再次調(diào)用epoll_wait依然可以獲得這些socket,用戶進(jìn)程可以接著處理socket上的IO事件。 -
邊緣觸發(fā): 在這種模式下,
epoll_wait就會直接清空rdllist,不管socket上是否還有數(shù)據(jù)可讀。所以在邊緣觸發(fā)模式下,當(dāng)你沒有來得及處理socket接收緩沖區(qū)的剩下可讀數(shù)據(jù)時,再次調(diào)用epoll_wait,因?yàn)檫@時rdlist已經(jīng)被清空了,socket不會再次從epoll_wait中返回,所以用戶進(jìn)程就不會再次獲得這個socket了,也就無法在對它進(jìn)行IO處理了。除非,這個socket上有新的IO數(shù)據(jù)到達(dá),根據(jù)epoll的工作過程,該socket會被再次放入rdllist中。
如果你在
邊緣觸發(fā)模式下,處理了部分socket上的數(shù)據(jù),那么想要處理剩下部分的數(shù)據(jù),就只能等到這個socket上再次有網(wǎng)絡(luò)數(shù)據(jù)到達(dá)。
在Netty中實(shí)現(xiàn)的EpollSocketChannel默認(rèn)的就是邊緣觸發(fā)模式。JDK的NIO默認(rèn)是水平觸發(fā)模式。
epoll對select,poll的優(yōu)化總結(jié)
-
epoll在內(nèi)核中通過紅黑樹管理海量的連接,所以在調(diào)用epoll_wait獲取IO就緒的socket時,不需要傳入監(jiān)聽的socket文件描述符。從而避免了海量的文件描述符集合在用戶空間和內(nèi)核空間中來回復(fù)制。
select,poll每次調(diào)用時都需要傳遞全量的文件描述符集合,導(dǎo)致大量頻繁的拷貝操作。
-
epoll僅會通知IO就緒的socket。避免了在用戶空間遍歷的開銷。
select,poll只會在IO就緒的socket上打好標(biāo)記,依然是全量返回,所以在用戶空間還需要用戶程序在一次遍歷全量集合找出具體IO就緒的socket。
-
epoll通過在socket的等待隊(duì)列上注冊回調(diào)函數(shù)ep_poll_callback通知用戶程序IO就緒的socket。避免了在內(nèi)核中輪詢的開銷。
大部分情況下
socket上并不總是IO活躍的,在面對海量連接的情況下,select,poll采用內(nèi)核輪詢的方式獲取IO活躍的socket,無疑是性能低下的核心原因。
根據(jù)以上epoll的性能優(yōu)勢,它是目前為止各大主流網(wǎng)絡(luò)框架,以及反向代理中間件使用到的網(wǎng)絡(luò)IO模型。
利用epoll多路復(fù)用IO模型可以輕松的解決C10K問題。
C100k的解決方案也還是基于C10K的方案,通過epoll 配合線程池,再加上 CPU、內(nèi)存和網(wǎng)絡(luò)接口的性能和容量提升。大部分情況下,C100K很自然就可以達(dá)到。
甚至C1000K的解決方法,本質(zhì)上還是構(gòu)建在 epoll 的多路復(fù)用 I/O 模型上。只不過,除了 I/O 模型之外,還需要從應(yīng)用程序到 Linux 內(nèi)核、再到 CPU、內(nèi)存和網(wǎng)絡(luò)等各個層次的深度優(yōu)化,特別是需要借助硬件,來卸載那些原來通過軟件處理的大量功能(去掉大量的中斷響應(yīng)開銷,以及內(nèi)核協(xié)議棧處理的開銷)。
信號驅(qū)動IO
信號驅(qū)動IO.png大家對這個裝備肯定不會陌生,當(dāng)我們?nèi)ヒ恍┟朗吵浅燥埖臅r候,點(diǎn)完餐付了錢,老板會給我們一個信號器。然后我們帶著這個信號器可以去找餐桌,或者干些其他的事情。當(dāng)信號器亮了的時候,這時代表飯餐已經(jīng)做好,我們可以去窗口取餐了。
這個典型的生活場景和我們要介紹的信號驅(qū)動IO模型就很像。
在信號驅(qū)動IO模型下,用戶進(jìn)程操作通過系統(tǒng)調(diào)用 sigaction 函數(shù)發(fā)起一個 IO 請求,在對應(yīng)的socket注冊一個信號回調(diào),此時不阻塞用戶進(jìn)程,進(jìn)程會繼續(xù)工作。當(dāng)內(nèi)核數(shù)據(jù)就緒時,內(nèi)核就為該進(jìn)程生成一個 SIGIO 信號,通過信號回調(diào)通知進(jìn)程進(jìn)行相關(guān) IO 操作。
這里需要注意的是:
信號驅(qū)動式 IO 模型依然是同步IO,因?yàn)樗m然可以在等待數(shù)據(jù)的時候不被阻塞,也不會頻繁的輪詢,但是當(dāng)數(shù)據(jù)就緒,內(nèi)核信號通知后,用戶進(jìn)程依然要自己去讀取數(shù)據(jù),在數(shù)據(jù)拷貝階段發(fā)生阻塞。
信號驅(qū)動 IO模型 相比于前三種 IO 模型,實(shí)現(xiàn)了在等待數(shù)據(jù)就緒時,進(jìn)程不被阻塞,主循環(huán)可以繼續(xù)工作,所以
理論上性能更佳。
但是實(shí)際上,使用TCP協(xié)議通信時,信號驅(qū)動IO模型幾乎不會被采用。原因如下:
- 信號IO 在大量 IO 操作時可能會因?yàn)樾盘栮?duì)列溢出導(dǎo)致沒法通知
-
SIGIO 信號是一種 Unix 信號,信號沒有附加信息,如果一個信號源有多種產(chǎn)生信號的原因,信號接收者就無法確定究竟發(fā)生了什么。而 TCP socket 生產(chǎn)的信號事件有七種之多,這樣應(yīng)用程序收到 SIGIO,根本無從區(qū)分處理。
但信號驅(qū)動IO模型可以用在 UDP通信上,因?yàn)閁DP 只有一個數(shù)據(jù)請求事件,這也就意味著在正常情況下 UDP 進(jìn)程只要捕獲 SIGIO 信號,就調(diào)用 read 系統(tǒng)調(diào)用讀取到達(dá)的數(shù)據(jù)。如果出現(xiàn)異常,就返回一個異常錯誤。
這里插句題外話,大家覺不覺得阻塞IO模型在生活中的例子就像是我們在食堂排隊(duì)打飯。你自己需要排隊(duì)去打飯同時打飯師傅在配菜的過程中你需要等待。
IO多路復(fù)用模型就像是我們在飯店門口排隊(duì)等待叫號。叫號器就好比select,poll,epoll可以統(tǒng)一管理全部顧客的吃飯就緒事件,客戶好比是socket連接,誰可以去吃飯了,叫號器就通知誰。
##異步IO(AIO)
以上介紹的四種IO模型均為同步IO,它們都會阻塞在第二階段數(shù)據(jù)拷貝階段。
通過在前邊小節(jié)《同步與異步》中的介紹,相信大家很容易就會理解異步IO模型,在異步IO模型下,IO操作在數(shù)據(jù)準(zhǔn)備階段和數(shù)據(jù)拷貝階段均是由內(nèi)核來完成,不會對應(yīng)用程序造成任何阻塞。應(yīng)用進(jìn)程只需要在指定的數(shù)組中引用數(shù)據(jù)即可。
異步 IO 與信號驅(qū)動 IO 的主要區(qū)別在于:信號驅(qū)動 IO 由內(nèi)核通知何時可以開始一個 IO 操作,而異步 IO由內(nèi)核通知 IO 操作何時已經(jīng)完成。
舉個生活中的例子:異步IO模型就像我們?nèi)ヒ粋€高檔飯店里的包間吃飯,我們只需要坐在包間里面,點(diǎn)完餐(類比異步IO調(diào)用)之后,我們就什么也不需要管,該喝酒喝酒,該聊天聊天,飯餐做好后服務(wù)員(類比內(nèi)核)會自己給我們送到包間(類比用戶空間)來。整個過程沒有任何阻塞。
異步IO的系統(tǒng)調(diào)用需要操作系統(tǒng)內(nèi)核來支持,目前只有Window中的IOCP實(shí)現(xiàn)了非常成熟的異步IO機(jī)制。
而Linux系統(tǒng)對異步IO機(jī)制實(shí)現(xiàn)的不夠成熟,且與NIO的性能相比提升也不明顯。
但Linux kernel 在5.1版本由Facebook的大神Jens Axboe引入了新的異步IO庫
io_uring改善了原來Linux native AIO的一些性能問題。性能相比Epoll以及之前原生的AIO提高了不少,值得關(guān)注。
再加上信號驅(qū)動IO模型不適用TCP協(xié)議,所以目前大部分采用的還是IO多路復(fù)用模型。
IO線程模型
在前邊內(nèi)容的介紹中,我們詳述了網(wǎng)絡(luò)數(shù)據(jù)包的接收和發(fā)送過程,并通過介紹5種IO模型了解了內(nèi)核是如何讀取網(wǎng)絡(luò)數(shù)據(jù)并通知給用戶線程的。
前邊的內(nèi)容都是以內(nèi)核空間的視角來剖析網(wǎng)絡(luò)數(shù)據(jù)的收發(fā)模型,本小節(jié)我們站在用戶空間的視角來看下如果對網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行收發(fā)。
相對內(nèi)核來講,用戶空間的IO線程模型相對就簡單一些。這些用戶空間的IO線程模型都是在討論當(dāng)多線程一起配合工作時誰負(fù)責(zé)接收連接,誰負(fù)責(zé)響應(yīng)IO 讀寫、誰負(fù)責(zé)計(jì)算、誰負(fù)責(zé)發(fā)送和接收,僅僅是用戶IO線程的不同分工模式罷了。
Reactor
Reactor是利用NIO對IO線程進(jìn)行不同的分工:
-
使用前邊我們提到的
IO多路復(fù)用模型比如select,poll,epoll,kqueue,進(jìn)行IO事件的注冊和監(jiān)聽。 -
將監(jiān)聽到
就緒的IO事件分發(fā)dispatch到各個具體的處理Handler中進(jìn)行相應(yīng)的IO事件處理。
通過IO多路復(fù)用技術(shù)就可以不斷的監(jiān)聽IO事件,不斷的分發(fā)dispatch,就像一個反應(yīng)堆一樣,看起來像不斷的產(chǎn)生IO事件,因此我們稱這種模式為Reactor模型。
下面我們來看下Reactor模型的三種分類:
單Reactor單線程
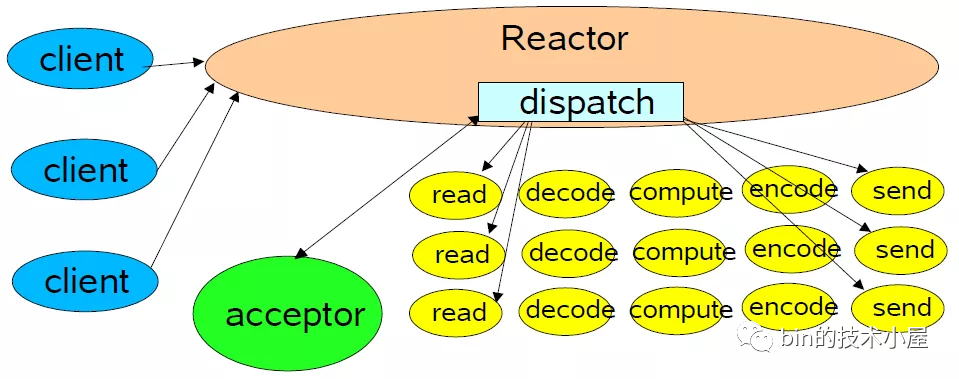 單Reactor單線程
單Reactor單線程
Reactor模型是依賴IO多路復(fù)用技術(shù)實(shí)現(xiàn)監(jiān)聽IO事件,從而源源不斷的產(chǎn)生IO就緒事件,在Linux系統(tǒng)下我們使用epoll來進(jìn)行IO多路復(fù)用,我們以Linux系統(tǒng)為例:
-
單
Reactor意味著只有一個epoll對象,用來監(jiān)聽所有的事件,比如連接事件,讀寫事件。 -
單線程意味著只有一個線程來執(zhí)行epoll_wait獲取IO就緒的Socket,然后對這些就緒的Socket執(zhí)行讀寫,以及后邊的業(yè)務(wù)處理也依然是這個線程。
單Reactor單線程模型就好比我們開了一個很小很小的小飯館,作為老板的我們需要一個人干所有的事情,包括:迎接顧客(accept事件),為顧客介紹菜單等待顧客點(diǎn)菜(IO請求),做菜(業(yè)務(wù)處理),上菜(IO響應(yīng)),送客(斷開連接)。
單Reactor多線程
隨著客人的增多(并發(fā)請求),顯然飯館里的事情只有我們一個人干(單線程)肯定是忙不過來的,這時候我們就需要多招聘一些員工(多線程)來幫著一起干上述的事情。
于是就有了單Reactor多線程模型:
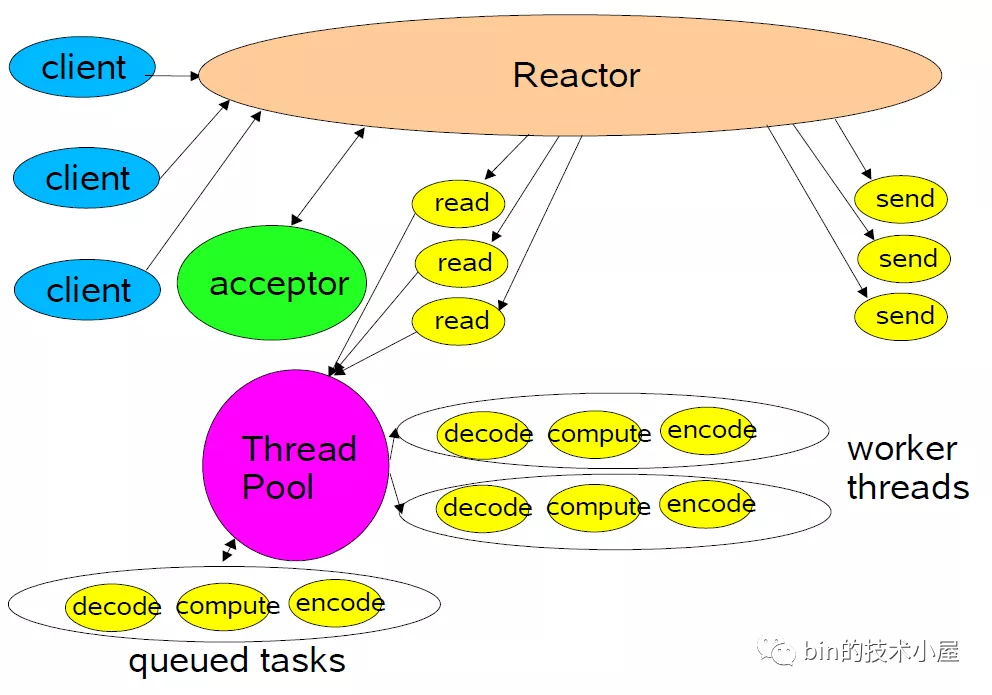 單Reactor多線程
單Reactor多線程-
這種模式下,也是只有一個
epoll對象來監(jiān)聽所有的IO事件,一個線程來調(diào)用epoll_wait獲取IO就緒的Socket。 -
但是當(dāng)
IO就緒事件產(chǎn)生時,這些IO事件對應(yīng)處理的業(yè)務(wù)Handler,我們是通過線程池來執(zhí)行。這樣相比單Reactor單線程模型提高了執(zhí)行效率,充分發(fā)揮了多核CPU的優(yōu)勢。
主從Reactor多線程
做任何事情都要區(qū)分事情的優(yōu)先級,我們應(yīng)該優(yōu)先高效的去做優(yōu)先級更高的事情,而不是一股腦不分優(yōu)先級的全部去做。
當(dāng)我們的小飯館客人越來越多(并發(fā)量越來越大),我們就需要擴(kuò)大飯店的規(guī)模,在這個過程中我們發(fā)現(xiàn),迎接客人是飯店最重要的工作,我們要先把客人迎接進(jìn)來,不能讓客人一看人多就走掉,只要客人進(jìn)來了,哪怕菜做的慢一點(diǎn)也沒關(guān)系。
于是,主從Reactor多線程模型就產(chǎn)生了:
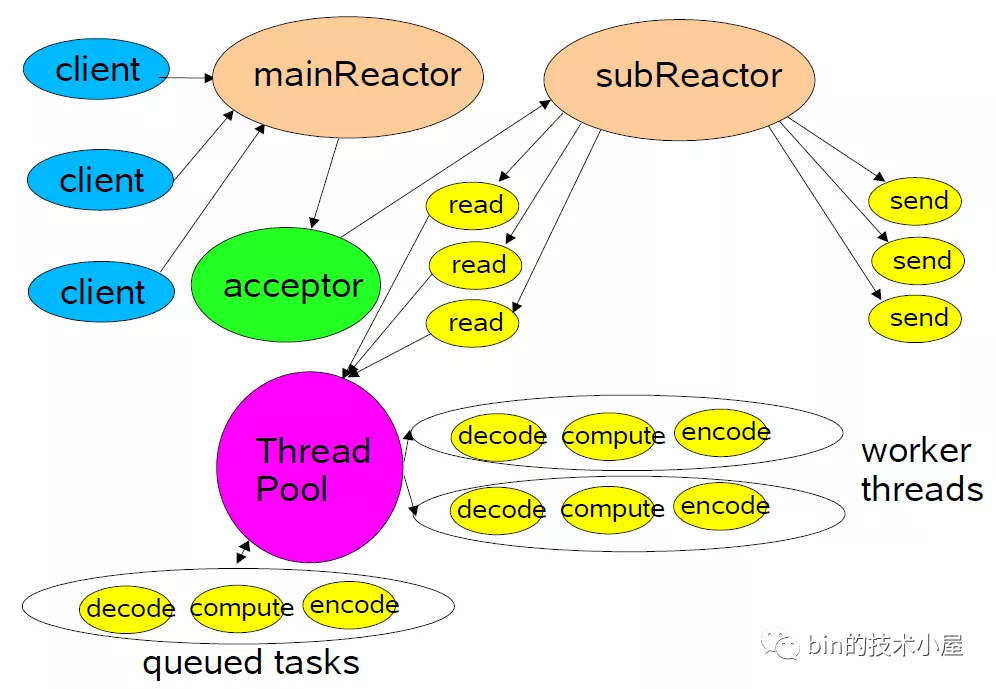 主從Reactor多線程
主從Reactor多線程-
我們由原來的
單Reactor變?yōu)榱?/span>多Reactor。主Reactor用來優(yōu)先專門做優(yōu)先級最高的事情,也就是迎接客人(處理連接事件),對應(yīng)的處理Handler就是圖中的acceptor。 -
當(dāng)創(chuàng)建好連接,建立好對應(yīng)的
socket后,在acceptor中將要監(jiān)聽的read事件注冊到從Reactor中,由從Reactor來監(jiān)聽socket上的讀寫事件。 -
最終將讀寫的業(yè)務(wù)邏輯處理交給線程池處理。
注意:這里向
從Reactor注冊的只是read事件,并沒有注冊write事件,因?yàn)?/span>read事件是由epoll內(nèi)核觸發(fā)的,而write事件則是由用戶業(yè)務(wù)線程觸發(fā)的(什么時候發(fā)送數(shù)據(jù)是由具體業(yè)務(wù)線程決定的),所以write事件理應(yīng)是由用戶業(yè)務(wù)線程去注冊。
用戶線程注冊
write事件的時機(jī)是只有當(dāng)用戶發(fā)送的數(shù)據(jù)無法一次性全部寫入buffer時,才會去注冊write事件,等待buffer重新可寫時,繼續(xù)寫入剩下的發(fā)送數(shù)據(jù)、如果用戶線程可以一股腦的將發(fā)送數(shù)據(jù)全部寫入buffer,那么也就無需注冊write事件到從Reactor中。
主從Reactor多線程模型是現(xiàn)在大部分主流網(wǎng)絡(luò)框架中采用的一種IO線程模型。我們本系列的主題Netty就是用的這種模型。
Proactor
Proactor是基于AIO對IO線程進(jìn)行分工的一種模型。前邊我們介紹了異步IO模型,它是操作系統(tǒng)內(nèi)核支持的一種全異步編程模型,在數(shù)據(jù)準(zhǔn)備階段和數(shù)據(jù)拷貝階段全程無阻塞。
ProactorIO線程模型將IO事件的監(jiān)聽,IO操作的執(zhí)行,IO結(jié)果的dispatch統(tǒng)統(tǒng)交給內(nèi)核來做。
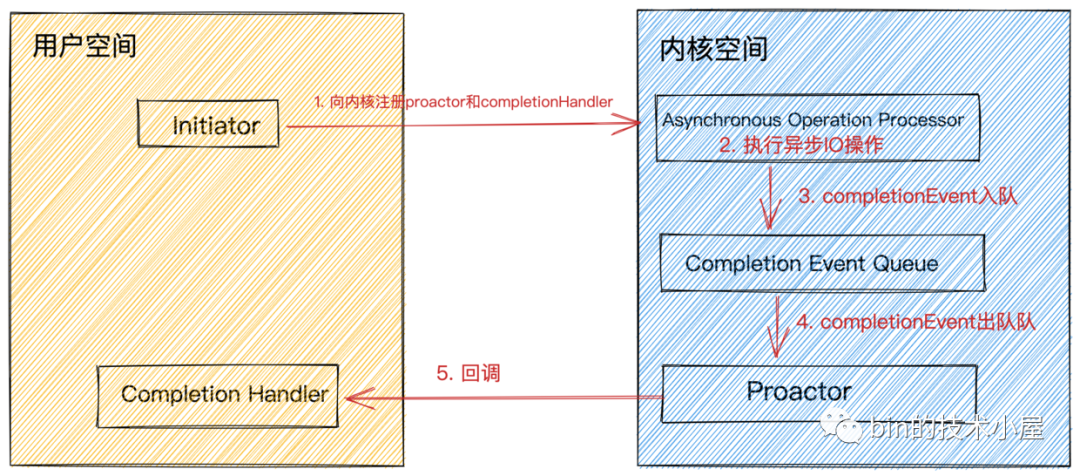 proactor.png
proactor.png
Proactor模型組件介紹:
-
completion handler為用戶程序定義的異步IO操作回調(diào)函數(shù),在異步IO操作完成時會被內(nèi)核回調(diào)并通知IO結(jié)果。 -
Completion Event Queue異步IO操作完成后,會產(chǎn)生對應(yīng)的IO完成事件,將IO完成事件放入該隊(duì)列中。 -
Asynchronous Operation Processor負(fù)責(zé)異步IO的執(zhí)行。執(zhí)行完成后產(chǎn)生IO完成事件放入Completion Event Queue隊(duì)列中。 -
Proactor是一個事件循環(huán)派發(fā)器,負(fù)責(zé)從Completion Event Queue中獲取IO完成事件,并回調(diào)與IO完成事件關(guān)聯(lián)的completion handler。 -
Initiator初始化異步操作(asynchronous operation)并通過Asynchronous Operation Processor將completion handler和proactor注冊到內(nèi)核。
Proactor模型執(zhí)行過程:
-
用戶線程發(fā)起
aio_read,并告訴內(nèi)核用戶空間中的讀緩沖區(qū)地址,以便內(nèi)核完成IO操作將結(jié)果放入用戶空間的讀緩沖區(qū),用戶線程直接可以讀取結(jié)果(無任何阻塞)。 -
Initiator初始化aio_read異步讀取操作(asynchronous operation),并將completion handler注冊到內(nèi)核。
在
Proactor中我們關(guān)心的IO完成事件:內(nèi)核已經(jīng)幫我們讀好數(shù)據(jù)并放入我們指定的讀緩沖區(qū),用戶線程可以直接讀取。在Reactor中我們關(guān)心的是IO就緒事件:數(shù)據(jù)已經(jīng)到來,但是需要用戶線程自己去讀取。
-
此時用戶線程就可以做其他事情了,無需等待IO結(jié)果。而內(nèi)核與此同時開始異步執(zhí)行IO操作。當(dāng)
IO操作完成時會產(chǎn)生一個completion event事件,將這個IO完成事件放入completion event queue中。 -
Proactor從completion event queue中取出completion event,并回調(diào)與IO完成事件關(guān)聯(lián)的completion handler。 -
在
completion handler中完成業(yè)務(wù)邏輯處理。
Reactor與Proactor對比
-
Reactor是基于NIO實(shí)現(xiàn)的一種IO線程模型,Proactor是基于AIO實(shí)現(xiàn)的IO線程模型。 -
Reactor關(guān)心的是IO就緒事件,Proactor關(guān)心的是IO完成事件。 -
在
Proactor中,用戶程序需要向內(nèi)核傳遞用戶空間的讀緩沖區(qū)地址。Reactor則不需要。這也就導(dǎo)致了在Proactor中每個并發(fā)操作都要求有獨(dú)立的緩存區(qū),在內(nèi)存上有一定的開銷。 -
Proactor的實(shí)現(xiàn)邏輯復(fù)雜,編碼成本較Reactor要高很多。 -
Proactor在處理高耗時 IO時的性能要高于Reactor,但對于低耗時 IO的執(zhí)行效率提升并不明顯。
Netty的IO模型
在我們介紹完網(wǎng)絡(luò)數(shù)據(jù)包在內(nèi)核中的收發(fā)過程以及五種IO模型和兩種IO線程模型后,現(xiàn)在我們來看下netty中的IO模型是什么樣的。
在我們介紹Reactor IO線程模型的時候提到有三種Reactor模型:單Reactor單線程,單Reactor多線程,主從Reactor多線程。
這三種Reactor模型在netty中都是支持的,但是我們常用的是主從Reactor多線程模型。
而我們之前介紹的三種Reactor只是一種模型,是一種設(shè)計(jì)思想。實(shí)際上各種網(wǎng)絡(luò)框架在實(shí)現(xiàn)中并不是嚴(yán)格按照模型來實(shí)現(xiàn)的,會有一些小的不同,但大體設(shè)計(jì)思想上是一樣的。
下面我們來看下netty中的主從Reactor多線程模型是什么樣子的?
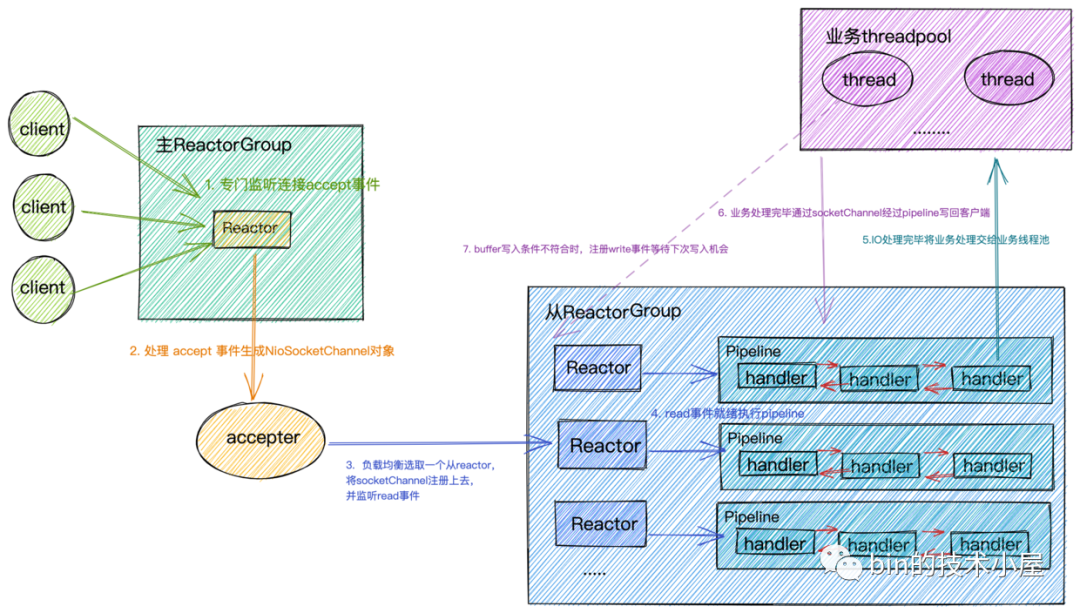 netty中的reactor.png
netty中的reactor.png-
Reactor在netty中是以group的形式出現(xiàn)的,netty中將Reactor分為兩組,一組是MainReactorGroup也就是我們在編碼中常常看到的EventLoopGroup bossGroup,另一組是SubReactorGroup也就是我們在編碼中常常看到的EventLoopGroup workerGroup。 -
MainReactorGroup中通常只有一個Reactor,專門負(fù)責(zé)做最重要的事情,也就是監(jiān)聽連接accept事件。當(dāng)有連接事件產(chǎn)生時,在對應(yīng)的處理handler acceptor中創(chuàng)建初始化相應(yīng)的NioSocketChannel(代表一個Socket連接)。然后以負(fù)載均衡的方式在SubReactorGroup中選取一個Reactor,注冊上去,監(jiān)聽Read事件。
MainReactorGroup中只有一個Reactor的原因是,通常我們服務(wù)端程序只會綁定監(jiān)聽一個端口,如果要綁定監(jiān)聽多個端口,就會配置多個Reactor。
-
SubReactorGroup中有多個Reactor,具體Reactor的個數(shù)可以由系統(tǒng)參數(shù)-D io.netty.eventLoopThreads指定。默認(rèn)的Reactor的個數(shù)為CPU核數(shù) * 2。SubReactorGroup中的Reactor主要負(fù)責(zé)監(jiān)聽讀寫事件,每一個Reactor負(fù)責(zé)監(jiān)聽一組socket連接。將全量的連接分?jǐn)?/span>在多個Reactor中。 -
一個
Reactor分配一個IO線程,這個IO線程負(fù)責(zé)從Reactor中獲取IO就緒事件,執(zhí)行IO調(diào)用獲取IO數(shù)據(jù),執(zhí)行PipeLine。
Socket連接在創(chuàng)建后就被固定的分配給一個Reactor,所以一個Socket連接也只會被一個固定的IO線程執(zhí)行,每個Socket連接分配一個獨(dú)立的PipeLine實(shí)例,用來編排這個Socket連接上的IO處理邏輯。這種無鎖串行化的設(shè)計(jì)的目的是為了防止多線程并發(fā)執(zhí)行同一個socket連接上的IO邏輯處理,防止出現(xiàn)線程安全問題。同時使系統(tǒng)吞吐量達(dá)到最大化
由于每個
Reactor中只有一個IO線程,這個IO線程既要執(zhí)行IO活躍Socket連接對應(yīng)的PipeLine中的ChannelHandler,又要從Reactor中獲取IO就緒事件,執(zhí)行IO調(diào)用。所以PipeLine中ChannelHandler中執(zhí)行的邏輯不能耗時太長,盡量將耗時的業(yè)務(wù)邏輯處理放入單獨(dú)的業(yè)務(wù)線程池中處理,否則會影響其他連接的IO讀寫,從而近一步影響整個服務(wù)程序的IO吞吐。
-
當(dāng)
IO請求在業(yè)務(wù)線程中完成相應(yīng)的業(yè)務(wù)邏輯處理后,在業(yè)務(wù)線程中利用持有的ChannelHandlerContext引用將響應(yīng)數(shù)據(jù)在PipeLine中反向傳播,最終寫回給客戶端。
netty中的IO模型我們介紹完了,下面我們來簡單介紹下在netty中是如何支持前邊提到的三種Reactor模型的。
配置單Reactor單線程
EventLoopGroupeventGroup=newNioEventLoopGroup(1);
ServerBootstrapserverBootstrap=newServerBootstrap();
serverBootstrap.group(eventGroup);
配置單Reactor多線程
EventLoopGroupeventGroup=newNioEventLoopGroup();
ServerBootstrapserverBootstrap=newServerBootstrap();
serverBootstrap.group(eventGroup);
配置主從Reactor多線程
EventLoopGroupbossGroup=newNioEventLoopGroup(1);
EventLoopGroupworkerGroup=newNioEventLoopGroup();
ServerBootstrapserverBootstrap=newServerBootstrap();
serverBootstrap.group(bossGroup,workerGroup);
總結(jié)
本文是一篇信息量比較大的文章,用了25張圖,22336個字從內(nèi)核如何處理網(wǎng)絡(luò)數(shù)據(jù)包的收發(fā)過程開始展開,隨后又在內(nèi)核角度介紹了經(jīng)常容易混淆的阻塞與非阻塞,同步與異步的概念。以這個作為鋪墊,我們通過一個C10K的問題,引出了五種IO模型,隨后在IO多路復(fù)用中以技術(shù)演進(jìn)的形式介紹了select,poll,epoll的原理和它們綜合的對比。最后我們介紹了兩種IO線程模型以及netty中的Reactor模型。
原文標(biāo)題:深入理解 Netty 高性能網(wǎng)絡(luò)框架
文章出處:【微信公眾號:Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7523瀏覽量
88649 -
框架
+關(guān)注
關(guān)注
0文章
399瀏覽量
17437 -
程序
+關(guān)注
關(guān)注
116文章
3778瀏覽量
80858
原文標(biāo)題:深入理解 Netty 高性能網(wǎng)絡(luò)框架
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于多路復(fù)用模型的Netty框架
如何利用FPGA開發(fā)高性能網(wǎng)絡(luò)安全處理平臺?
怎樣使用springboot整合netty來開發(fā)一套高性能的通信系統(tǒng)呢
《Linux設(shè)備驅(qū)動開發(fā)詳解》第9章、Linux設(shè)備驅(qū)動中的異步通知與異步IO
Springboot整合netty框架實(shí)現(xiàn)終端、通訊板子(單片機(jī))TCP/UDP通信案例

Netty如何實(shí)現(xiàn)消息推送
Netty如何做到單機(jī)百萬并發(fā)?
一個高性能異步計(jì)算框架介紹
netty推送消息接口及實(shí)現(xiàn)
聊聊Netty那些事兒之從內(nèi)核角度看IO模型
AP3160 高性能異步升壓型led恒流驅(qū)動器芯片
高性能網(wǎng)絡(luò)框架之XDP技術(shù)解析
linux異步io框架iouring應(yīng)用
異步IO框架iouring介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論