") 一文深入理解操作系統(tǒng)的進(jìn)程調(diào)度
一文深入理解操作系統(tǒng)的進(jìn)程調(diào)度
準(zhǔn)備知識(shí)
想深入理解操作系統(tǒng)的進(jìn)程調(diào)度,需要先獲得一些準(zhǔn)備知識(shí),這樣后面就不懵圈啦:
- 調(diào)度究竟是個(gè)啥
- 操作系統(tǒng)有哪幾種?常用的是哪種?
- 進(jìn)程的分類和優(yōu)先級(jí)是怎么回事
- 搶占式調(diào)度和非搶占式調(diào)度有啥區(qū)別
- 如何設(shè)計(jì)一個(gè)可用的調(diào)度器
調(diào)度的概念
科技源自生活,調(diào)度系統(tǒng)絕對(duì)不是計(jì)算機(jī)領(lǐng)域的專利,現(xiàn)實(shí)生活中調(diào)度無處不在:
- 連鎖超市某些熱門商品短缺,就需要在全城范圍內(nèi)考慮人口密度、超市規(guī)模、商品缺口等多個(gè)因素,進(jìn)行資源調(diào)配
- 鐵路部門為了應(yīng)對(duì)春運(yùn)會(huì)在熱門線路增加列車來緩解運(yùn)輸壓力,春運(yùn)結(jié)束則恢復(fù)正常
“調(diào)度是為了解決資源和需求之間的不匹配問題,現(xiàn)實(shí)往往是資源少&需求多,計(jì)算機(jī)領(lǐng)域也是如此。
在操作系統(tǒng)中CPU資源是有限的,需要使用CPU的進(jìn)程數(shù)量是不確定的,并且大部分情況下進(jìn)程數(shù)量遠(yuǎn)大于CPU數(shù)量,如何解決不匹配問題就是進(jìn)程調(diào)度核心:
操作系統(tǒng)分類
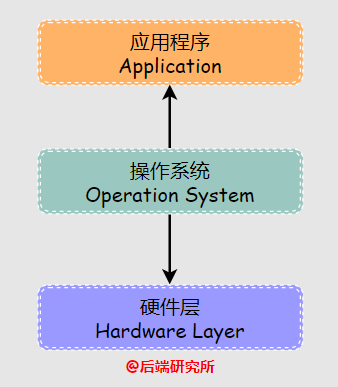
操作系統(tǒng)的種類非常多,本身上是硬件層和應(yīng)用層之間的中間層,對(duì)上與應(yīng)用程序進(jìn)行交互,對(duì)下實(shí)現(xiàn)硬件資源的管理。
- 批處理系統(tǒng)( Batch Processing System )
“批處理是指用戶將一批作業(yè)提交給操作系統(tǒng)后就不再干預(yù),由操作系統(tǒng)控制它們自動(dòng)運(yùn)行,這種采用批量處理作業(yè)任務(wù)的操作系統(tǒng)稱為批處理操作系統(tǒng),不具有交互性,用戶無法干預(yù)任務(wù)的運(yùn)行。
- 實(shí)時(shí)系統(tǒng)( Real-Time System)
“實(shí)時(shí)系統(tǒng)最大的特點(diǎn)在于計(jì)算的正確性不僅取決于程序的邏輯正確性,也取決于結(jié)果產(chǎn)生的時(shí)間,如果系統(tǒng)的時(shí)間約束條件得不到滿足,將會(huì)發(fā)生系統(tǒng)出錯(cuò),強(qiáng)實(shí)時(shí)系統(tǒng)一般應(yīng)用在航空航天、導(dǎo)彈導(dǎo)航制導(dǎo)、核工業(yè)等領(lǐng)域。
- 分時(shí)系統(tǒng)( Time Sharing System)
“分時(shí)系統(tǒng)將計(jì)算機(jī)系統(tǒng)資源(比如CPU)進(jìn)行時(shí)間上的分割,每個(gè)時(shí)間段稱為一個(gè)時(shí)間片,每個(gè)用戶依次輪流使用時(shí)間片,由于時(shí)間間隔很短,每個(gè)用戶的感覺就像他獨(dú)占計(jì)算機(jī)一樣,從而有效增加資源的使用率,提高用戶交互體驗(yàn)。
Linux屬于分時(shí)系統(tǒng),是互聯(lián)網(wǎng)服務(wù)器的主流操作系統(tǒng),重點(diǎn)研究它就行!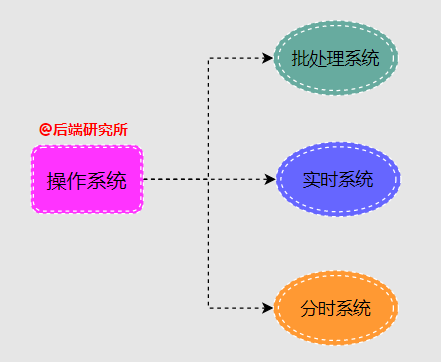
進(jìn)程分類
根據(jù)進(jìn)程運(yùn)行時(shí)的狀態(tài),可以分為:
- I/O密集型( IO-bound )
“在進(jìn)程占用CPU期間頻繁有IO操作,出現(xiàn)IO阻塞等待情況,比如負(fù)責(zé)監(jiān)聽socket的進(jìn)程,真正使用CPU進(jìn)行計(jì)算的時(shí)間并不多。
- CPU密集型( CPU-bound)
“在進(jìn)程占用CPU期間基本都在進(jìn)行計(jì)算,很少進(jìn)行IO操作,期間對(duì)CPU的真實(shí)使用率很高。
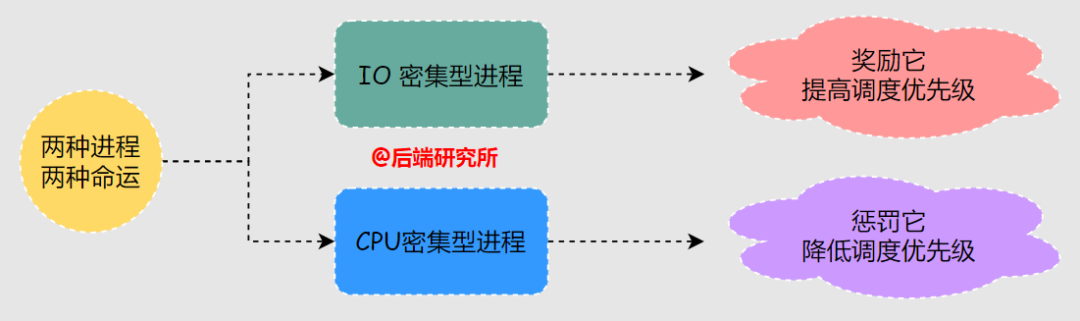
進(jìn)程調(diào)度器需要根據(jù)進(jìn)程是IO密集型還是CPU密集型會(huì)采用不同的策略。
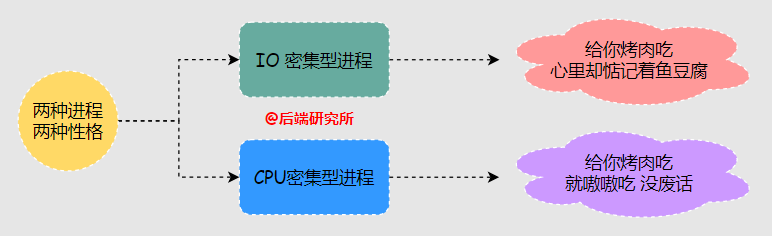
在調(diào)度器中往往需要對(duì)IO密集型進(jìn)程進(jìn)行獎(jiǎng)勵(lì)來提高其調(diào)度優(yōu)先級(jí),對(duì)CPU密集型進(jìn)程進(jìn)行懲罰降低其調(diào)度優(yōu)先級(jí)。
對(duì)進(jìn)程的獎(jiǎng)懲策略是調(diào)度器的一項(xiàng)核心工作,希望大家務(wù)必理解:
“交互進(jìn)程往往伴隨較多的IO操作,同時(shí)也是響應(yīng)時(shí)間敏感的任務(wù),鼠標(biāo)點(diǎn)一下半天沒響應(yīng),想想就很糟糕,因此屬于高優(yōu)先級(jí)進(jìn)程。
“非交互進(jìn)程往往是純CPU計(jì)算,用戶是無感知的,所以對(duì)響應(yīng)時(shí)間的要求并沒有那么高,屬于低優(yōu)先級(jí)進(jìn)程。
進(jìn)程優(yōu)先級(jí)
根據(jù)進(jìn)程的重要性,可以分為:
- 實(shí)時(shí)進(jìn)程(Real-Time Process)
- 普通進(jìn)程(Normal Process)
“在操作系統(tǒng)中有很多進(jìn)程,實(shí)時(shí)進(jìn)程是相對(duì)重要的,需要保證其CPU占用優(yōu)先級(jí),普通進(jìn)程并不需要額外照顧。
實(shí)時(shí)進(jìn)程和普通進(jìn)程的進(jìn)程優(yōu)先級(jí)不同,調(diào)度器都會(huì)根據(jù)優(yōu)先級(jí)來確定進(jìn)程的CPU優(yōu)先權(quán)和運(yùn)行時(shí)間。
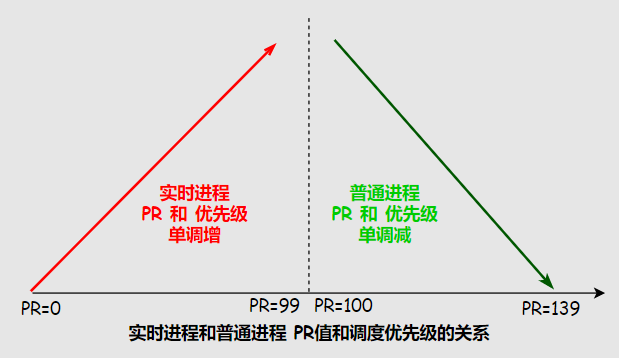
在Linux中影響優(yōu)先級(jí)的兩個(gè)因素:Nice謙讓值和Priority權(quán)重值。
- 實(shí)時(shí)進(jìn)程PR值范圍是0~99,數(shù)值越大被調(diào)度優(yōu)先級(jí)越高
- 普通進(jìn)程PR值范圍是100~139,數(shù)值越小被調(diào)度優(yōu)先級(jí)越高
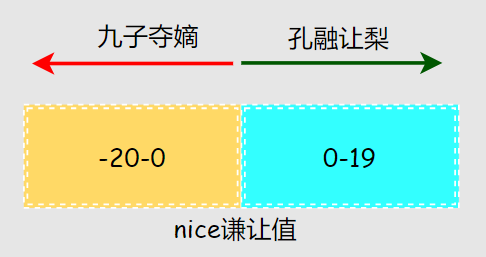
- Nice值范圍是-20~19,并不是優(yōu)先級(jí)但影響PR值,一般作用在普通進(jìn)程上
PR值由內(nèi)核來確定,用戶可以修改Nice謙讓值,進(jìn)而干預(yù)PR值:
- PR_new = PR_old + Nice
nice值也被稱為謙讓值,數(shù)值越大越謙讓,會(huì)哭的孩子有奶吃,總謙讓優(yōu)先級(jí)肯定低了:
- 如果nice值是0,即用戶層認(rèn)可內(nèi)核的決定不額外干預(yù),聽天由命
- 如果nice為負(fù)值表示毫不謙讓,即用戶層干預(yù)來提升被調(diào)度的優(yōu)先級(jí),把機(jī)會(huì)留給自己
- 如果nice為正值表示予以謙讓,即用戶層干預(yù)降低被調(diào)度的優(yōu)先級(jí),把機(jī)會(huì)留給別人
非搶占和搶占式
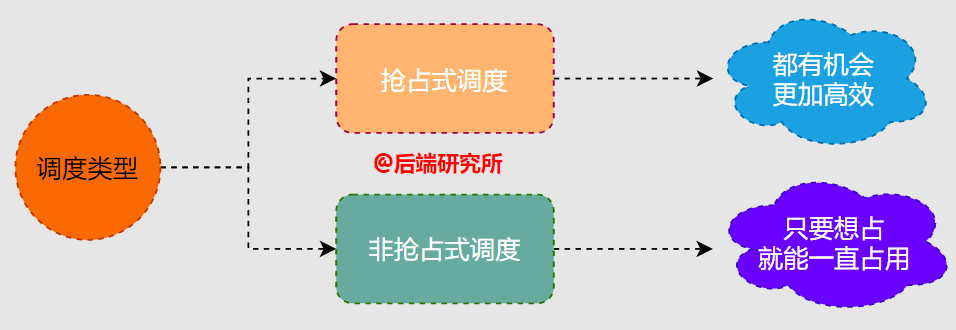
根據(jù)進(jìn)程任務(wù)在占用CPU時(shí),使用權(quán)是否會(huì)被奪取分為:
- 協(xié)作式調(diào)度( Cooperative Scheduling)
“進(jìn)程任務(wù)一旦占用CPU只有當(dāng)任務(wù)完成或者因?yàn)槟承┰蛑鲃?dòng)釋放CPU,除上述兩種情況外不能被其他進(jìn)程奪走
- 搶占式調(diào)度( Preemptive Scheduling)
“進(jìn)程任務(wù)占用CPU期間可以被其他進(jìn)程奪走,具體由操作系統(tǒng)調(diào)度器決定下一個(gè)占用CPU的進(jìn)程
Linux采用搶占式調(diào)度,其可以提高CPU利用率、降低進(jìn)程的響應(yīng)時(shí)間等,同時(shí)也增加了切換進(jìn)程時(shí)的開銷,各有利弊。
調(diào)度器設(shè)計(jì)思路
設(shè)計(jì)目標(biāo)
有兩個(gè)指標(biāo)需要重視:
- 周轉(zhuǎn)時(shí)間( Cycling Time )
“進(jìn)程任務(wù)從開始排隊(duì)等待獲取CPU資源直到任務(wù)完成的時(shí)間差,就像超市排隊(duì)結(jié)賬時(shí)從開始排隊(duì)到結(jié)算完成離開的時(shí)間差。
- 響應(yīng)時(shí)間Response Time
“進(jìn)程任務(wù)從開始排隊(duì)等待獲取CPU資源直到開始使用CPU的時(shí)間差,就像超市排隊(duì)結(jié)賬時(shí)從開始排隊(duì)到輪到結(jié)算的時(shí)間差。
綜合來說:
- 實(shí)時(shí)進(jìn)程要更優(yōu)先被調(diào)度,普通進(jìn)程的優(yōu)先級(jí)一定低于實(shí)時(shí)進(jìn)程
- IO密集型進(jìn)程要調(diào)度頻繁一些,IO密集型要少分配時(shí)間片,少吃多餐
- CPU密集型可以稍微懲罰,CPU密集型可以分配長(zhǎng)一些的時(shí)間片,少餐多吃
只有做到這幾點(diǎn),調(diào)度器才可能在周轉(zhuǎn)時(shí)間和響應(yīng)時(shí)間上得到一個(gè)良好的表現(xiàn)。
設(shè)計(jì)實(shí)現(xiàn)
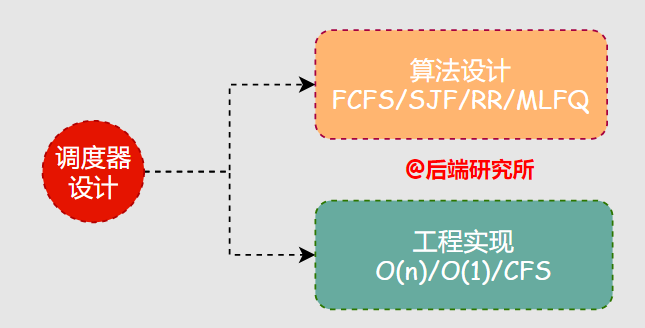
要實(shí)現(xiàn)一個(gè)調(diào)度器,主要包括兩個(gè)核心部分:
- 算法設(shè)計(jì)
- 工程實(shí)現(xiàn)
算法更多是一種思想,調(diào)度器基于某種調(diào)度算法進(jìn)行工程化實(shí)現(xiàn),捋清楚二者的關(guān)系對(duì)于后續(xù)內(nèi)容的理解將大有裨益。
本章重點(diǎn)
- 調(diào)度是為了解決資源和需求之間的不匹配問題,現(xiàn)實(shí)生活和計(jì)算機(jī)領(lǐng)域都非常普遍
- 操作系統(tǒng)可以分為:批處理系統(tǒng)、實(shí)時(shí)系統(tǒng)、分時(shí)系統(tǒng)三大類,分時(shí)系統(tǒng)是研究重點(diǎn)
- 進(jìn)程可以分為兩大類:IO密集型和CPU密集型,調(diào)度時(shí)采用不同的策略
- 進(jìn)程可以分為普通進(jìn)程和實(shí)時(shí)進(jìn)程,實(shí)時(shí)進(jìn)程優(yōu)先級(jí)永遠(yuǎn)高于普通進(jìn)程
- 進(jìn)程調(diào)度模型可以分為兩大類:協(xié)作式調(diào)度和搶占式調(diào)度,搶占式是主流
- 要設(shè)計(jì)一個(gè)進(jìn)程調(diào)度器需要有設(shè)計(jì)目標(biāo)后選擇合適的調(diào)度算法進(jìn)行工程化實(shí)現(xiàn)
調(diào)度算法
調(diào)度算法也經(jīng)歷了從簡(jiǎn)單到復(fù)雜的演進(jìn),到目前為止也沒有哪種調(diào)度算法是萬能的,拋開場(chǎng)景來評(píng)判調(diào)度算法優(yōu)劣并不明智。
以下介紹的主要是調(diào)度算法的思想,工程上使用的調(diào)度算法往往是其中一種或者幾種的變形,更加復(fù)雜。
先來先服務(wù)FCFS
先來先服務(wù)First Come First Service可以說是最早最簡(jiǎn)單的調(diào)度算法,哪個(gè)進(jìn)程先來就先讓它占用CPU,釋放CPU之后第二個(gè)進(jìn)程再使用,依次類推。
-
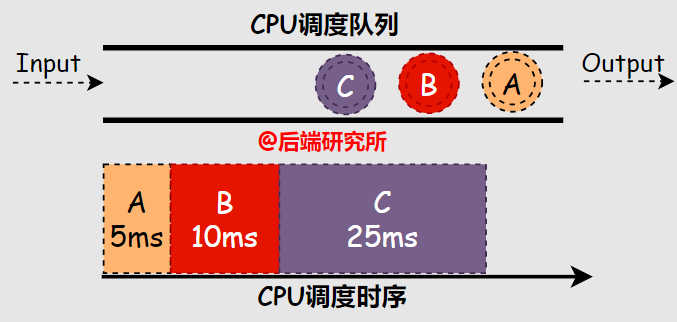
場(chǎng)景一
假如有ABC三個(gè)進(jìn)程依次進(jìn)入等候使用CPU資源的隊(duì)列FIFO,A進(jìn)程占用CPU運(yùn)行5ms,B進(jìn)程10ms,C進(jìn)程25ms,根據(jù)FCFS算法的規(guī)則,可知:- 周轉(zhuǎn)時(shí)間 A-5ms B-15ms C-40ms 平均(5+15+40)/3=20ms
- 響應(yīng)時(shí)間 A-0ms B-5ms C-15ms 平均(0+5+15)/3=6.67ms
-
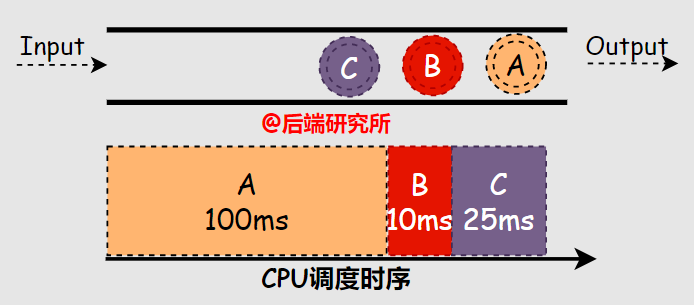
場(chǎng)景二
假如有ABC三個(gè)進(jìn)程依次進(jìn)入等候使用CPU資源的隊(duì)列FIFO,A進(jìn)程占用CPU運(yùn)行100ms,B進(jìn)程10ms,C進(jìn)程25ms,根據(jù)FCFS算法的規(guī)則,可知:- 周轉(zhuǎn)時(shí)間 A-100ms B-110ms C-135ms 平均(100+110+135)/3=115ms
- 響應(yīng)時(shí)間 A-0ms B-100ms C-110ms 平均(0+100+110)/3=70ms綜上,在場(chǎng)景二中A進(jìn)程的運(yùn)行時(shí)間長(zhǎng)達(dá)100ms,這樣拉升了B和C的周轉(zhuǎn)時(shí)間5倍多。
在FCFS中優(yōu)先被調(diào)度的進(jìn)程如果耗時(shí)很長(zhǎng),后續(xù)進(jìn)程都必須要等待這個(gè)大CPU消耗的進(jìn)程,最終導(dǎo)致周轉(zhuǎn)時(shí)間直線拉升,也就是護(hù)航效應(yīng)。
最短任務(wù)優(yōu)先SJF
最短任務(wù)優(yōu)先Shortest Job First的思想是當(dāng)多個(gè)進(jìn)程同時(shí)出現(xiàn)時(shí),優(yōu)先安排執(zhí)行時(shí)間最短的任務(wù),然后是執(zhí)行時(shí)間次短,以此類推。
SJF可以解決FCFS中同時(shí)到達(dá)進(jìn)程執(zhí)行時(shí)間不一致帶來的護(hù)航效應(yīng)問題:
-
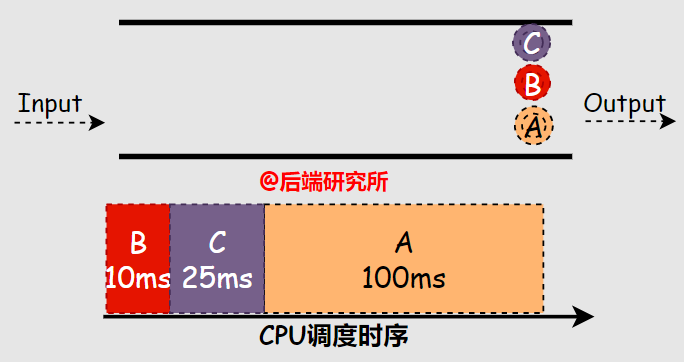
場(chǎng)景一
假如有ABC三個(gè)進(jìn)程同時(shí)進(jìn)入等候使用CPU資源的隊(duì)列FIFO,A進(jìn)程占用CPU運(yùn)行100ms,B進(jìn)程10ms,C進(jìn)程25ms,根據(jù)SJF算法的規(guī)則,可知:- 進(jìn)程執(zhí)行順序是B->C->A
- 周轉(zhuǎn)時(shí)間 A-135ms B-10ms C-35ms 平均(135+10+35)/3=60ms
- 響應(yīng)時(shí)間 A-35ms B-0ms C-10ms 平均(35+0+10)/3=15ms
相比于FCFS可能的執(zhí)行順序是A->C->B來說,周轉(zhuǎn)時(shí)間和響應(yīng)時(shí)間都得到很大的改善。
SJF的算法思想有些理想化,但并非一無是處,升級(jí)改進(jìn)下也有用武之地:
- 大部分場(chǎng)景下進(jìn)程都是有先后順序進(jìn)行等待隊(duì)列的,同時(shí)出現(xiàn)的概率并不高
- 進(jìn)程執(zhí)行時(shí)間的長(zhǎng)短并不能預(yù)測(cè)
搶占式最短任務(wù)優(yōu)先PSJF
SJF算法最具啟發(fā)的地方在于優(yōu)先調(diào)度執(zhí)行時(shí)間短的任務(wù)來解決護(hù)航效應(yīng),但是該算法屬于非搶占式調(diào)度,對(duì)于先后到達(dá)且執(zhí)行時(shí)間差別較大的場(chǎng)景也束手無策。
當(dāng)向SJF算法增加搶占調(diào)度時(shí)能力就大大增強(qiáng)了,這就是PSJF( Preemptive Shortest Job First )算法。
-
場(chǎng)景一
假如有ABC三個(gè)進(jìn)程間隔20ms(BC同時(shí)且晚于A)依次進(jìn)入等候使用CPU資源的隊(duì)列FIFO,A進(jìn)程占用CPU運(yùn)行100ms,B進(jìn)程10ms,C進(jìn)程25ms,根據(jù)PSJF算法的規(guī)則,可知:- A先被執(zhí)行20ms,再執(zhí)行B10ms,再執(zhí)行C25ms,再執(zhí)行A80ms
- 周轉(zhuǎn)時(shí)間 A-135ms B-10ms C-35ms 平均(135+10+35)/3=60ms
- 響應(yīng)時(shí)間 A-0ms B-0ms C-10ms 平均(0+0+10)/3=3.3ms
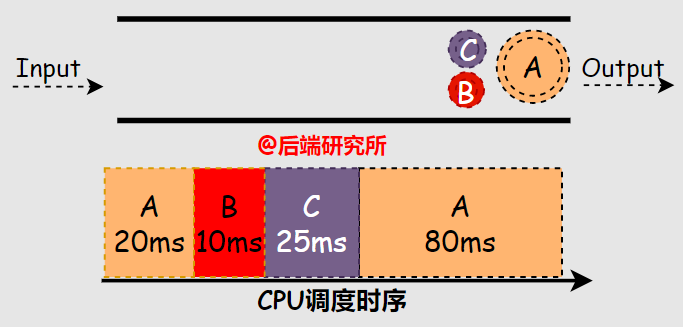
搶占機(jī)制有效削弱了護(hù)航效應(yīng),周轉(zhuǎn)時(shí)間和響應(yīng)時(shí)間都降低了許多,但是還遠(yuǎn)不夠完美。
PSJF算法對(duì)于進(jìn)程A來說卻不友好,進(jìn)程A在被搶占之后只能等待B和C運(yùn)行完成后,此時(shí)如果再來短任務(wù)DEF都會(huì)搶占A,就會(huì)產(chǎn)生饑餓效應(yīng)。
PSJF算法是基于對(duì)任務(wù)運(yùn)行時(shí)間長(zhǎng)短來進(jìn)行調(diào)度的,但在調(diào)度前任務(wù)的運(yùn)行時(shí)間是未知的,因此首要問題是通過歷史數(shù)據(jù)來預(yù)測(cè)運(yùn)行時(shí)間。
時(shí)間片輪轉(zhuǎn)RR
時(shí)間片輪轉(zhuǎn)RR(Round-Robin)將CPU執(zhí)行時(shí)間按照時(shí)鐘脈沖進(jìn)行切割稱為時(shí)間切片Time-Slice,一個(gè)時(shí)間切片是時(shí)鐘周期的數(shù)倍,時(shí)鐘周期和CPU的主頻呈倒數(shù)關(guān)系。
“比如 CPU的主頻是1000hz,則時(shí)鐘周期TimeClick=1ms,Time Slice = n*Time Click,時(shí)間切片可以是2ms/4ms/10ms等。
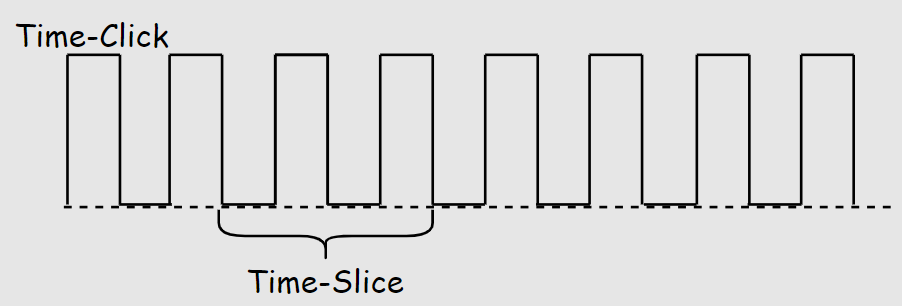
在一個(gè)時(shí)間片內(nèi)CPU分配給一個(gè)進(jìn)程,時(shí)間片耗盡則調(diào)度選擇下一個(gè)進(jìn)程,如此循環(huán)。
進(jìn)程往往需要多個(gè)循環(huán)獲取多次時(shí)間片才能完成任務(wù),因此需要操作系統(tǒng)記錄上一次的數(shù)據(jù),等進(jìn)程下一次被分配時(shí)間片時(shí)再拿出來,這就是傳說中的上下文Context。
進(jìn)程上下文被存儲(chǔ)和拿出的過程被稱為上下文切換Context Switch,上下文切換是比較消耗資源的,因此時(shí)間片的劃分就顯得很重要:
- 時(shí)間片太短,上下文頻繁切換,有效執(zhí)行時(shí)間變少
- 時(shí)間片太大,無法保證多個(gè)進(jìn)程可以雨露均沾,響應(yīng)時(shí)間較大
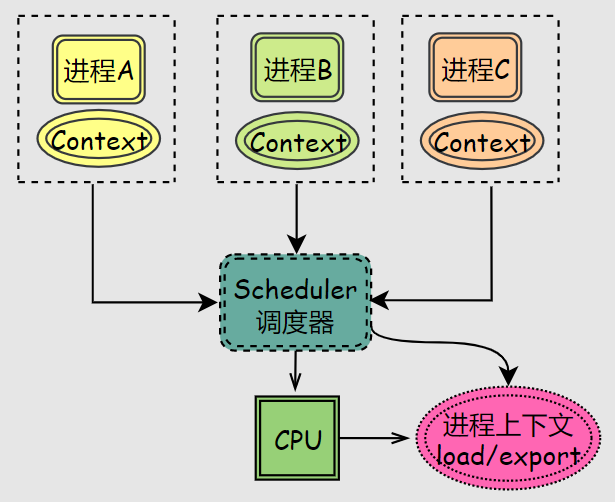
RR算法在保障了多個(gè)進(jìn)程都能占用CPU,屬于公平策略的一種,但是RR算法將原本可以一次運(yùn)行完的任務(wù)切分成多個(gè)部分來完成,從而拉升了周轉(zhuǎn)時(shí)間。
RR算法也非銀彈,但是響應(yīng)時(shí)間和公平性得到了有效保障,是個(gè)非常有意義的算法模型。
多級(jí)反饋隊(duì)列MLFQ
多級(jí)反饋隊(duì)列( Multi-Level Feedback Queue )嘗試去同時(shí)解決響應(yīng)時(shí)間和周轉(zhuǎn)時(shí)間兩個(gè)問題,具體做法:
- 設(shè)置了多個(gè)任務(wù)隊(duì)列,每個(gè)隊(duì)列對(duì)應(yīng)的優(yōu)先級(jí)不同,隊(duì)列內(nèi)部的優(yōu)先級(jí)相同
- 優(yōu)先分配CPU給高優(yōu)先級(jí)的任務(wù),同優(yōu)先級(jí)隊(duì)列中的任務(wù)采用RR輪詢機(jī)制
-
通過對(duì)任務(wù)運(yùn)行狀態(tài)的追蹤來調(diào)整優(yōu)先級(jí),也就是所謂的Feedback反饋機(jī)制
- 任務(wù)在運(yùn)行期間有較多IO請(qǐng)求和等待,預(yù)測(cè)為交互進(jìn)程,優(yōu)先級(jí)保持或提升
- 任務(wù)在運(yùn)行期間一直進(jìn)行CPU計(jì)算,預(yù)測(cè)為非交互進(jìn)程,優(yōu)先級(jí)保持或下降
-
最初將所以任務(wù)都設(shè)置為高優(yōu)先級(jí)隊(duì)列,隨著后續(xù)的運(yùn)行狀態(tài)再進(jìn)行調(diào)整
- 運(yùn)行期間有IO操作則保持優(yōu)先級(jí)
- 運(yùn)行期間無IO操作則把任務(wù)放到低一級(jí)的隊(duì)列中
-
不同隊(duì)列分配不同的時(shí)間片
- 高優(yōu)先級(jí)隊(duì)列往往是IO型任務(wù),配置較小的時(shí)間片來保障響應(yīng)時(shí)間
- 低優(yōu)先級(jí)隊(duì)列往往是CPU型任務(wù),配置較長(zhǎng)時(shí)間片來保障任務(wù)一直運(yùn)行
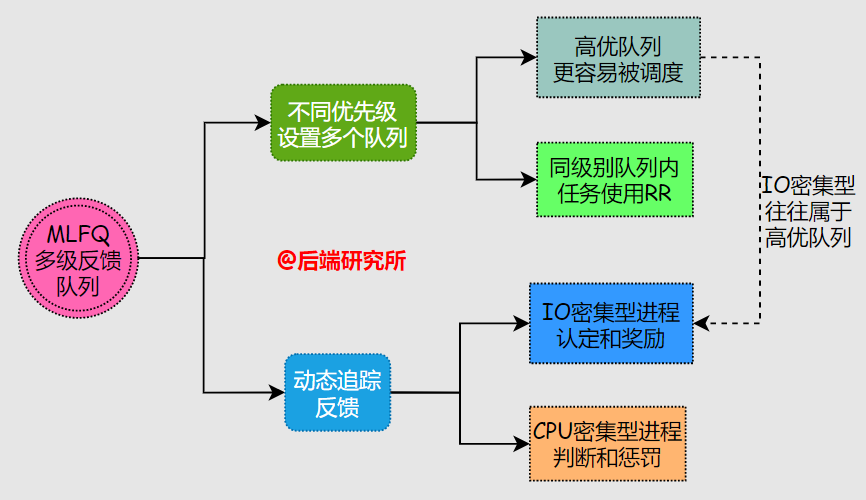
上述是MLFQ算法的基本規(guī)則,在實(shí)際應(yīng)用中仍然會(huì)有一些問題:
-
饑餓問題
- CPU密集型的任務(wù)隨著時(shí)間推移優(yōu)先級(jí)會(huì)越來越低,在IO型進(jìn)程多的場(chǎng)景下很容易出現(xiàn)饑餓問題,一直無法得到調(diào)度
- 任務(wù)是CPU密集型還是IO密集型可能是動(dòng)態(tài)變化的,低優(yōu)先級(jí)隊(duì)列中的IO型任務(wù)的響應(yīng)時(shí)間被拉升,調(diào)度頻率下降
-
作弊問題
- 基于MLFQ對(duì)IO型任務(wù)的偏愛,用戶可能為CPU密集型任務(wù)編寫無用的IO空操作,從而人為提升任務(wù)優(yōu)先級(jí),相當(dāng)于作弊
針對(duì)上述問題MLFQ還需增加幾個(gè)補(bǔ)丁:
- 周期性提升所有任務(wù)的優(yōu)先級(jí)到最高,避免饑餓問題
- 調(diào)度程序記錄任務(wù)在某個(gè)層級(jí)隊(duì)列中消耗的時(shí)間片,如果達(dá)到某個(gè)比例,無論期間是否有IO操作都降低任務(wù)的優(yōu)先級(jí),通過計(jì)時(shí)來確定真正的IO型任務(wù)
MLFQ的算法思想在1962年被提出,其作者也獲得了圖靈獎(jiǎng),可謂是影響深遠(yuǎn)。
在樸素MLFQ算法基礎(chǔ)上出現(xiàn)一些變種,通過工程實(shí)現(xiàn)和經(jīng)驗(yàn)配置最終被使用到操作系統(tǒng)中,成為真正的工業(yè)級(jí)進(jìn)程調(diào)度器。
Linux進(jìn)程調(diào)度器
Linux的進(jìn)程調(diào)度器是不斷演進(jìn)的,先后出現(xiàn)過三種里程碑式的調(diào)度器:
- O(n)調(diào)度器 內(nèi)核版本 2.4-2.6
- O(1) 調(diào)度器 內(nèi)核版本 2.6.0-2.6.22
- CFS調(diào)度器 內(nèi)核版本 2.6.23-至今
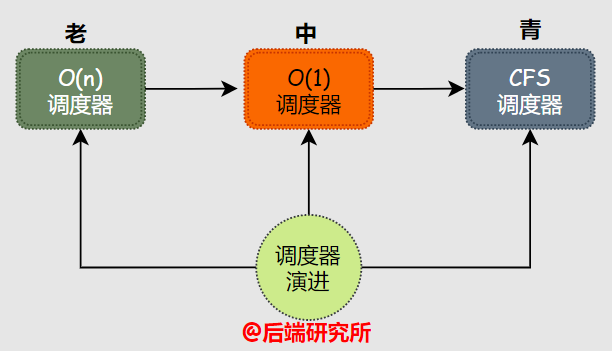
O(n)屬于早期版本在pick next過程是需要遍歷進(jìn)程任務(wù)隊(duì)列來實(shí)現(xiàn),O(1)版本性能上有較大提升可以實(shí)現(xiàn)O(1)復(fù)雜度的pick next過程。
CFS調(diào)度器可以說是一種O(logn)調(diào)度器,但是其算法思想相比前兩種有些不同,并且設(shè)計(jì)實(shí)現(xiàn)上也更加輕量,一直被Linux內(nèi)核沿用至今。
調(diào)度器設(shè)計(jì)核心
要理解這些復(fù)雜的調(diào)度器設(shè)計(jì),我們必須要有一個(gè)核心主線,再去理解精髓。
調(diào)度器需要解決的關(guān)鍵問題:
- 采用何種數(shù)據(jù)結(jié)構(gòu)來組織進(jìn)程以及如何實(shí)現(xiàn)pick next
- 如何根據(jù)進(jìn)程優(yōu)先級(jí)來確定進(jìn)程運(yùn)行時(shí)間
-
如何判斷進(jìn)程類型
- 判斷進(jìn)程的交互性質(zhì),是否為IO密集
- 獎(jiǎng)勵(lì)I(lǐng)O密集型&懲罰CPU密集型
- 實(shí)時(shí)進(jìn)程高優(yōu)&普通進(jìn)程低優(yōu)
-
如何確定進(jìn)程的動(dòng)態(tài)優(yōu)先級(jí)
- 影響因素:靜態(tài)優(yōu)先級(jí)、nice值、IO密集型和CPU密集型產(chǎn)生的獎(jiǎng)懲
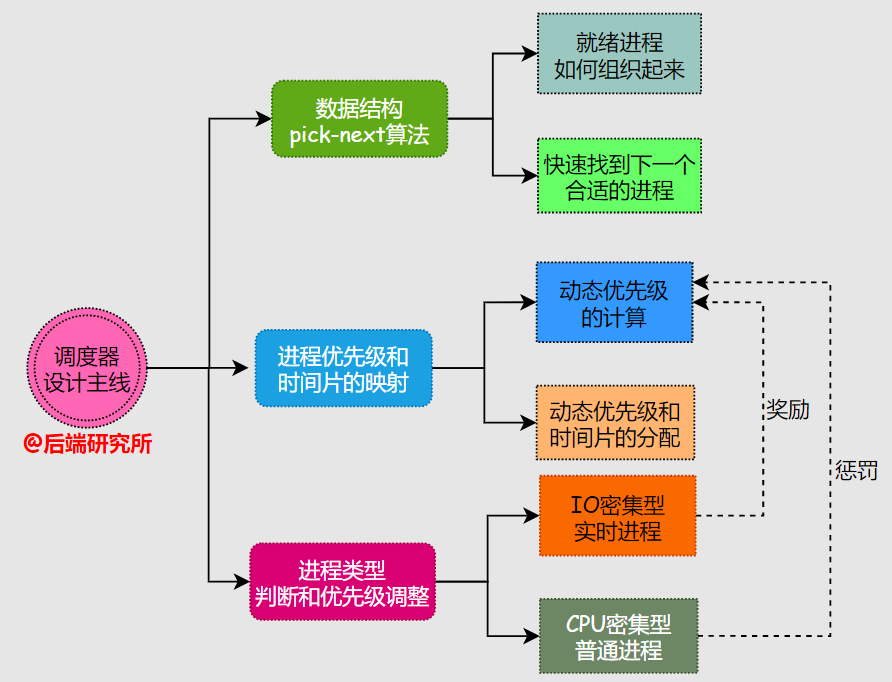
事實(shí)上,調(diào)度器在設(shè)計(jì)實(shí)現(xiàn)上考慮的問題還有很多,篇幅所限只列舉幾個(gè)公共問題。
O(n) 調(diào)度器
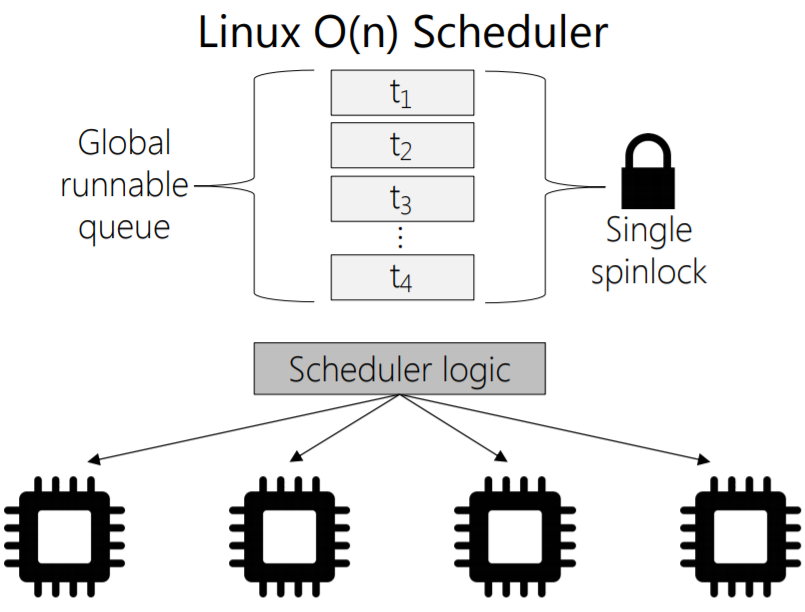
O(n)調(diào)度器采用一個(gè)全局隊(duì)列runqueue作為核心數(shù)據(jù)結(jié)構(gòu),具備以下特點(diǎn):
- 多個(gè)cpu共享全局隊(duì)列,并非每個(gè)cpu有單獨(dú)的隊(duì)列
- 實(shí)時(shí)進(jìn)程和普通進(jìn)程混合且無序存放,尋找最合適進(jìn)程需要遍歷
- 就緒進(jìn)程將被添加到隊(duì)列,運(yùn)行結(jié)束被刪除
- 全局隊(duì)列增刪進(jìn)程任務(wù)時(shí)需要加鎖
- 進(jìn)程被掛到不同CPU運(yùn)行,緩存利用率低
在Linux中進(jìn)程使用task_struct結(jié)構(gòu)體來表示,其中有個(gè)counter表示進(jìn)程剩余的CPU時(shí)間片:
structtask_struct{
longcounter;
longnice;
unsignedlongpolicy;
intprocessor;
unsignedlongcpus_runnable,cpus_allowed;
}
counter值在調(diào)度周期開始時(shí)被賦值,隨著調(diào)度的進(jìn)行遞減,直至counter=0表示無可用CPU時(shí)間,等待下一個(gè)調(diào)度周期。
O(n)調(diào)度器中調(diào)度權(quán)重是在goodness函數(shù)中完成計(jì)算的:
staticinlineintgoodness(structtask_struct*p,intthis_cpu,structmm_struct*this_mm)
{
intweight;
weight=-1;
/*進(jìn)程可以設(shè)置調(diào)度策略為SCHED_YIELD即“禮讓”策略,這時(shí)候它的權(quán)值為-1,權(quán)值相當(dāng)?shù)?/
if(p->policy&SCHED_YIELD)
gotoout;
/*
*Non-RTprocess-normalcasefirst.
*/
/*對(duì)于調(diào)度策略為SCHED_OTHER的進(jìn)程,沒有實(shí)時(shí)性要求,它的權(quán)值僅僅取決于
*時(shí)間片的剩余和它的nice值,數(shù)值上nice越小,則優(yōu)先級(jí)越高,總的權(quán)值=時(shí)間片剩余+(20-nice)
**/
if(p->policy==SCHED_OTHER){
/*
*Givetheprocessafirst-approximationgoodnessvalue
*accordingtothenumberofclock-ticksithasleft.
*
*Don'tdoanyothercalculationsifthetimesliceis
*over..
*/
weight=p->counter;
if(!weight)
gotoout;
#ifdefCONFIG_SMP
/*Givealargishadvantagetothesameprocessor...*/
/*(thisisequivalenttopenalizingotherprocessors)*/
if(p->processor==this_cpu)
weight+=PROC_CHANGE_PENALTY;
#endif
/*..andaslightadvantagetothecurrentMM*/
if(p->mm==this_mm||!p->mm)
weight+=1;
weight+=20-p->nice;
gotoout;
}
/*
*對(duì)于實(shí)時(shí)進(jìn)程,也就是SCHED_FIFO或者SCHED_RR調(diào)度策略,
*具有一個(gè)實(shí)時(shí)優(yōu)先級(jí),總的權(quán)值僅僅取決于該實(shí)時(shí)優(yōu)先級(jí),
*總的權(quán)值= 1000+實(shí)時(shí)優(yōu)先級(jí)。
**/
weight=1000+p->rt_priority;
out:
returnweight;
}
從代碼可以看到:
- 當(dāng)進(jìn)程的剩余時(shí)間片Counter為0時(shí),無論靜態(tài)優(yōu)先級(jí)是多少都不會(huì)被選中
- 普通進(jìn)程的優(yōu)先級(jí)=剩余時(shí)間片Counter+20-nice
- 實(shí)時(shí)進(jìn)程的優(yōu)先級(jí)=1000+進(jìn)程靜態(tài)優(yōu)先級(jí)
- 實(shí)時(shí)進(jìn)程的動(dòng)態(tài)優(yōu)先級(jí)遠(yuǎn)大于普通進(jìn)程,更容易被選中
- 剩余時(shí)間片counter越多說明進(jìn)程IO較多,分配給它的沒用完,被調(diào)度的優(yōu)先級(jí)需要高一些
#ifHZ
#defineTICK_SCALE(x)((x)>>2)
#elifHZ
#defineTICK_SCALE(x)((x)>>1)
#elifHZ
#defineTICK_SCALE(x)(x)
#elifHZ
#defineTICK_SCALE(x)((x)<
#else
#defineTICK_SCALE(x)((x)<
#endif
#defineNICE_TO_TICKS(nice)(TICK_SCALE(20-(nice))+1)
NICE_TO_TICKS是個(gè)宏函數(shù),根據(jù)不同的調(diào)度頻率HZ有對(duì)應(yīng)的TICK_SCALE宏定義,這樣就解決了不同優(yōu)先級(jí)的進(jìn)程的時(shí)間片分配問題。
O(n)調(diào)度器對(duì)實(shí)時(shí)進(jìn)程和普通進(jìn)程采用不同的調(diào)度策略:- 實(shí)時(shí)進(jìn)程采用的是SCHED_RR或者SCHED_FIFO,高級(jí)優(yōu)先&同級(jí)輪轉(zhuǎn)或者順序執(zhí)行
- 普通進(jìn)程采用的是SCHED_OTHER
- 進(jìn)程采用的策略在task_struct中policy體現(xiàn)
在runqueue中搜索下一個(gè)合適的進(jìn)程是基于動(dòng)態(tài)優(yōu)先級(jí)來實(shí)現(xiàn)的,動(dòng)態(tài)優(yōu)先級(jí)最高的就是下一個(gè)被執(zhí)行的進(jìn)程。
O(n)調(diào)度器設(shè)計(jì)和實(shí)現(xiàn)上存在一些問題,但是其中的很多思想為后續(xù)調(diào)度器設(shè)計(jì)指明了方向,意義深遠(yuǎn)。
O(1)調(diào)度器
O(n)調(diào)度器在linux內(nèi)核中大約使用了4年,在Linux 2.6.0采納了Red Hat公司Ingo Molnar設(shè)計(jì)的O(1)調(diào)度算法,該調(diào)度算法的核心思想基于Corbato等人提出的多級(jí)反饋隊(duì)列算法。
O(1)調(diào)度器引入了多個(gè)隊(duì)列,并且增加了負(fù)載均衡機(jī)制,對(duì)新出現(xiàn)的進(jìn)行任務(wù)分配到合適的cpu-runqueue中:
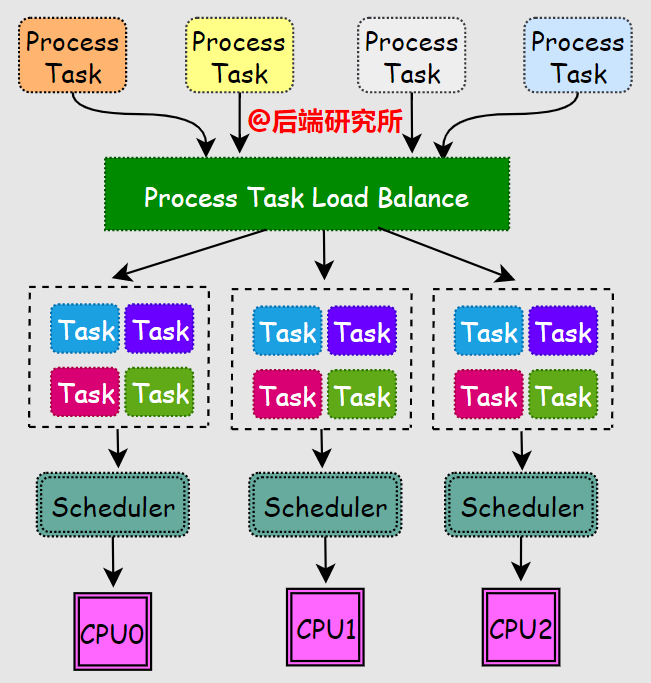
為了實(shí)現(xiàn)O(1)復(fù)雜度的pick-next算法,內(nèi)核實(shí)現(xiàn)代碼量增加了一倍多,其有以下幾個(gè)特點(diǎn):
- 實(shí)現(xiàn)了per-cpu-runqueue,每個(gè)CPU都有一個(gè)就緒進(jìn)程任務(wù)隊(duì)列
- 引入活躍數(shù)組active和過期數(shù)組expire,分別存儲(chǔ)就緒進(jìn)程和結(jié)束進(jìn)程
- 采用全局優(yōu)先級(jí):實(shí)時(shí)進(jìn)程0-99,普通進(jìn)程100-139,數(shù)值越低優(yōu)先級(jí)越高,更容易被調(diào)度
-
每個(gè)優(yōu)先級(jí)對(duì)應(yīng)一個(gè)鏈表,引入bitmap數(shù)組來記錄140個(gè)鏈表中的活躍任務(wù)情況
任務(wù)隊(duì)列的數(shù)據(jù)結(jié)構(gòu):
structrunqueue{
spinlock_tlock;
unsignedlongnr_running;
unsignedlonglongnr_switches;
unsignedlongexpired_timestamp,nr_uninterruptible;
unsignedlonglongtimestamp_last_tick;
task_t*curr,*idle;
structmm_struct*prev_mm;
prio_array_t*active,*expired,arrays[2];
intbest_expired_prio;
atomic_tnr_iowait;
......
};
- active和expired是指向prio_array_t的結(jié)構(gòu)體指針
- arrays是元素為prio_array_t的結(jié)構(gòu)體數(shù)組
prio_array_t結(jié)構(gòu)體的定義:
#defineBITMAP_SIZE((((MAX_PRIO+1+7)/8)+sizeof(long)-1)/sizeof(long))
typedefstructprio_arrayprio_array_t;
structprio_array{
unsignedintnr_active;
unsignedlongbitmap[BITMAP_SIZE];
structlist_headqueue[MAX_PRIO];
};
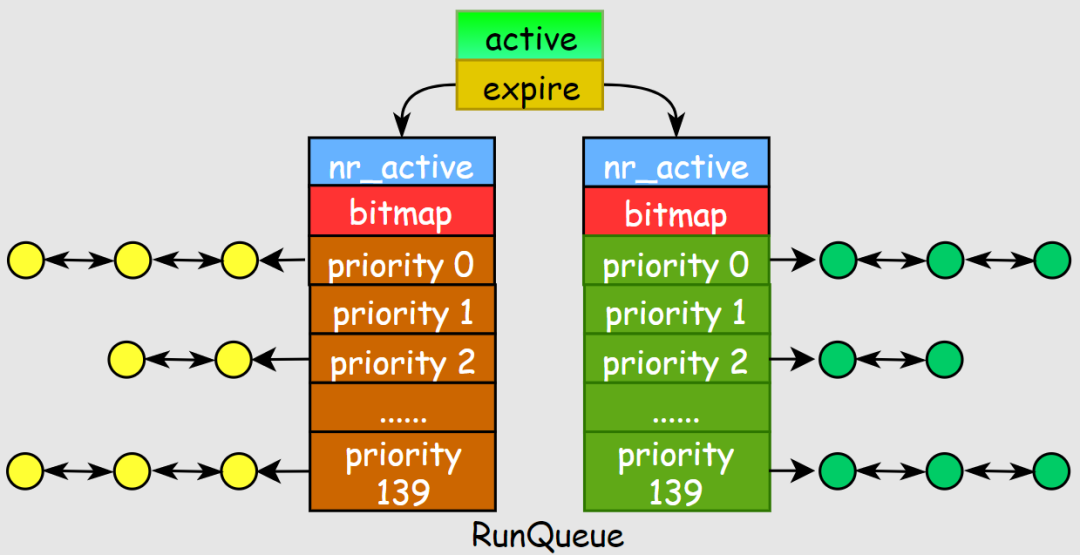
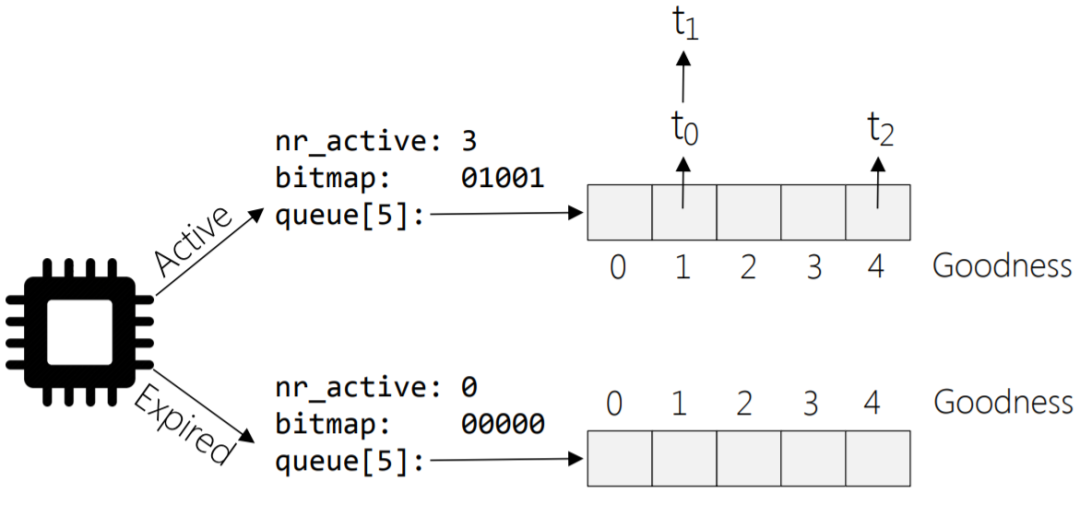
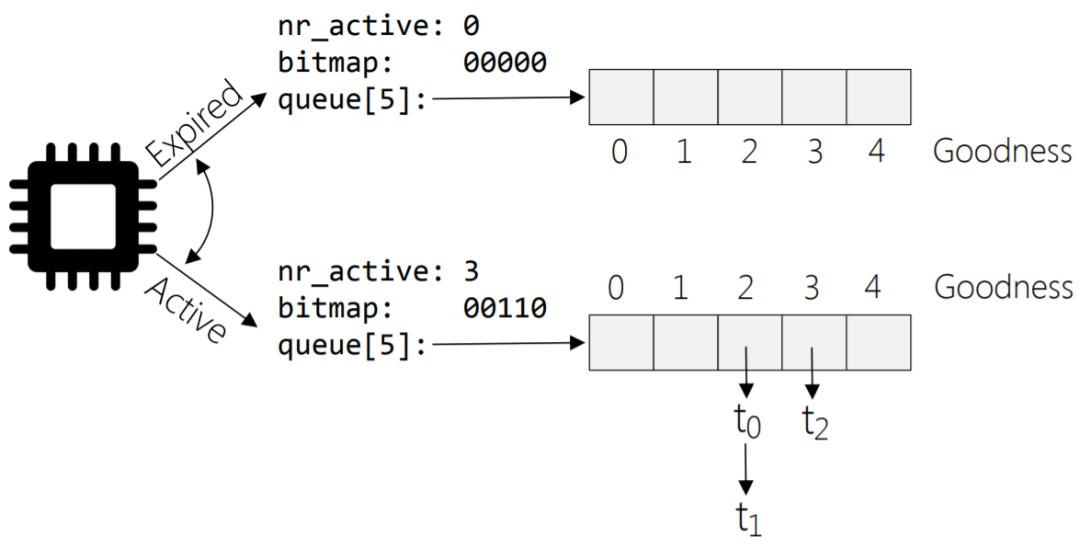
O(1)調(diào)度器對(duì)pick-next的實(shí)現(xiàn):
- 在runqueue結(jié)構(gòu)中有active和expire兩個(gè)數(shù)組指針,active指向就緒進(jìn)程的結(jié)構(gòu),從active-bitmap中尋找優(yōu)先級(jí)最高且非空的數(shù)組元素,這個(gè)數(shù)組是元素是進(jìn)程鏈表,找該鏈表中第1個(gè)進(jìn)程即可。
idx=sched_find_first_bit(array->bitmap);
queue=array->queue+idx;
next=list_entry(queue->next,task_t,run_list);
- 當(dāng)active的nr_active=0時(shí)表示沒有活躍任務(wù),此時(shí)進(jìn)行active和expire雙指針互換,速度很快。
array=rq->active;
if(unlikely(!array->nr_active)){
/*
*Switchtheactiveandexpiredarrays.
*/
rq->active=rq->expired;
rq->expired=array;
array=rq->active;
rq->expired_timestamp=0;
rq->best_expired_prio=MAX_PRIO;
}
O(1)和O(n)調(diào)度器確定進(jìn)程優(yōu)先級(jí)的方法不一樣,O(1)借助了sleep_avg變量記錄進(jìn)程的睡眠時(shí)間,來識(shí)別IO密集型進(jìn)程,計(jì)算bonus值來調(diào)整優(yōu)先級(jí):
#defineNICE_TO_PRIO(nice)(MAX_RT_PRIO+(nice)+20)
#defineNS_TO_JIFFIES(TIME)((TIME)/(1000000000/HZ))
#defineCURRENT_BONUS(p)
(NS_TO_JIFFIES((p)->sleep_avg)*MAX_BONUS/
MAX_SLEEP_AVG)
staticinteffective_prio(task_t*p)
{
intbonus,prio;
if(rt_task(p))
returnp->prio;
bonus=CURRENT_BONUS(p)-MAX_BONUS/2;
prio=p->static_prio-bonus;
if(prioif(prio>MAX_PRIO-1)
prio=MAX_PRIO-1;
returnprio;
}
O(1)調(diào)度器為了實(shí)現(xiàn)復(fù)雜場(chǎng)景IO密集型任務(wù)的識(shí)別,做了大量的工作仍然無法到達(dá)100%的準(zhǔn)確,但不可否認(rèn)O(1)調(diào)度器是一款非常優(yōu)秀的產(chǎn)品。
CFS調(diào)度器
O(1)調(diào)度器本質(zhì)上是MLFQ算法的思想,隨著時(shí)間的推移也暴露除了很多問題,主要集中在O(1)調(diào)度器對(duì)進(jìn)程交互性的判斷上積重難返。
無論是O(n)還是O(1)都需要去根據(jù)進(jìn)程的運(yùn)行狀況判斷它屬于IO密集型還是CPU密集型,再做優(yōu)先級(jí)獎(jiǎng)勵(lì)和懲罰,這種推測(cè)本身就會(huì)有誤差,而且場(chǎng)景越復(fù)雜判斷難度越大。
是繼續(xù)優(yōu)化進(jìn)程交互性算法,還是另辟蹊徑呢?一直困擾著Linux社區(qū)的大神們。
Con Kolivas和RSDL調(diào)度器
在CFS出現(xiàn)之前,不得不提一位有態(tài)度&有實(shí)力的麻醉師Con Kolivas,同時(shí)也是linux內(nèi)核開發(fā)者,他在進(jìn)程調(diào)度領(lǐng)域有自己獨(dú)到的見解。
Con Kolivas針對(duì)O(1)調(diào)度器存在的維護(hù)和優(yōu)化問題,提出了樓梯調(diào)度算法(Staircase Deadline Scheduler)和 基于公平策略RSDL調(diào)度器(The Rotating Staircase Deadline Schedule),遺憾的是Linux之父并沒有采納RDSL調(diào)度器。
對(duì)此Con Kolivas感到很憤怒,離開了Linux內(nèi)核開發(fā)社區(qū),但是事實(shí)上從后面CFS調(diào)度器幾個(gè)版本的修訂來看,Con Kolivas的大方向是正確的,離開之后的Con Kolivas又開發(fā)了BFS(Brain Fuck Scheduler)來對(duì)抗CFS調(diào)度器。
“沒錯(cuò),BFS調(diào)度器譯為腦殘調(diào)度器,可見Con Kolivas的憤怒和不滿。
Linux之父選擇了CFS調(diào)度器,它借鑒了Con Kolivas的樓梯調(diào)度算法和RSDL調(diào)度器的經(jīng)驗(yàn),由匈牙利人Ingo Molnar所提出和實(shí)現(xiàn),并在Linux kernel 2.6.23之后取代O(1)調(diào)度器,名震江湖。
CFS調(diào)度器
在2.6.23內(nèi)核中引入scheduling class的概念,將調(diào)度器模塊化,系統(tǒng)中可以有多種調(diào)度器,使用不同策略調(diào)度不同類型的進(jìn)程:
- DL Scheduler 采用sched_deadline策略
- RT Scheduler 采用sched_rr和sched_fifo策略
- CFS Scheduler 采用sched_normal和sched_batch策略
- IDEL Scheduler 采用sched_idle策略
這樣一來,CFS調(diào)度器就不關(guān)心實(shí)時(shí)進(jìn)程了,專注于普通進(jìn)程就可以了。
CFS( Completely Fair Scheduler )完全公平調(diào)度器,從實(shí)現(xiàn)思想上和之前的O(1)/O(n)很不一樣。
我的腦海里浮現(xiàn)了這幅漫畫,我想右邊的應(yīng)該更好,按需分配&達(dá)成共贏。
這個(gè)世界怎么會(huì)有絕對(duì)的公平呢?為啥這個(gè)調(diào)度器敢說自己是完全公平呢?
這一切CFS是如何實(shí)現(xiàn)的呢?我們繼續(xù)看!
優(yōu)先級(jí)和權(quán)重
O(1)和O(n)都將CPU資源劃分為時(shí)間片,采用了固定額度分配機(jī)制,在每個(gè)調(diào)度周期進(jìn)程可使用的時(shí)間片是確定的,調(diào)度周期結(jié)束被重新分配。
CFS摒棄了固定時(shí)間片分配,采用動(dòng)態(tài)時(shí)間片分配,本次調(diào)度中進(jìn)程可占用的時(shí)間與進(jìn)程總數(shù)、總CPU時(shí)間、進(jìn)程權(quán)重等均有關(guān)系,每個(gè)調(diào)度周期的值都可能會(huì)不一樣。
CFS調(diào)度器從進(jìn)程優(yōu)先級(jí)出發(fā),它建立了優(yōu)先級(jí)prio和權(quán)重weight之間的映射關(guān)系,把優(yōu)先級(jí)轉(zhuǎn)換為權(quán)重來參與后續(xù)的計(jì)算:
constintsched_prio_to_weight[40]={
/*-20*/88761,71755,56483,46273,36291,
/*-15*/29154,23254,18705,14949,11916,
/*-10*/9548,7620,6100,4904,3906,
/*-5*/3121,2501,1991,1586,1277,
/*0*/1024,820,655,526,423,
/*5*/335,272,215,172,137,
/*10*/110,87,70,56,45,
/*15*/36,29,23,18,15,
};
“普通進(jìn)程的優(yōu)先級(jí)范圍是[100,139],prio整體減小120就和代碼左邊的注釋對(duì)上了,也就是nice值的范圍[-20,19],因此sched_prio=0相當(dāng)于static_prio=120。
比如現(xiàn)有進(jìn)程A sched_prio=0,進(jìn)程B sched_prio=-5,通過sched_prio_to_weight的映射:
- 進(jìn)程A weight=1024,進(jìn)程B weight = 3121
- 進(jìn)程A的CPU占比 = 1024/(1024+3121)= 24.7%
- 進(jìn)程B的CPU占比 = 3121/(1024+3121) = 75.3%
- 假如CPU總時(shí)間是10ms,那么根據(jù)A占用2.47ms,B占用7.53ms
在CFS中引入sysctl_sched_latency(調(diào)度延遲)作為一個(gè)調(diào)度周期,真實(shí)的CPU時(shí)間表示為:
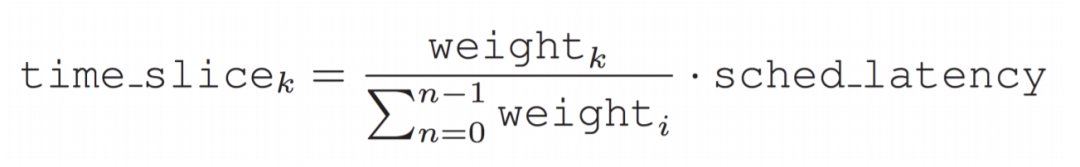
顯然這樣根據(jù)權(quán)重計(jì)算后的各個(gè)進(jìn)程的運(yùn)行時(shí)間是不等的,也就違背了"完全公平"思想,于是CFS引入了虛擬運(yùn)行時(shí)間(virtual runtime)。
虛擬運(yùn)行時(shí)間
每個(gè)進(jìn)程的物理運(yùn)行時(shí)間時(shí)肯定不能一樣的,CFS調(diào)度器只要保證的就是進(jìn)程的虛擬運(yùn)行時(shí)間相等即可。
那虛擬運(yùn)行時(shí)間該如何計(jì)算呢?
“virtual_time = wall_time * nice_0_weight/sched_prio_to_weigh
比如現(xiàn)有進(jìn)程A sched_prio=0,進(jìn)程B sched_prio=-5:
- 調(diào)度延遲=10ms,A的運(yùn)行時(shí)間=2.47ms B的運(yùn)行時(shí)間=7.53ms,也就是wall_time
- nice_0_weight表示sched_prio=0的權(quán)重為1024
- 進(jìn)程A的虛擬時(shí)間:2.47*1024/1024=2.47ms
- 進(jìn)程B的虛擬時(shí)間:7.53*1024/3121=2.47ms
經(jīng)過這樣映射,A和B的虛擬時(shí)間就相等了。
上述公式涉及了除法和浮點(diǎn)數(shù)運(yùn)算,因此需要轉(zhuǎn)換成為乘法來保證數(shù)據(jù)準(zhǔn)確性,再給出虛擬時(shí)間計(jì)算的變形等價(jià)公式:
“virtual_time = (wall_time * nice_0_weight * 2^32/sched_prio_to_weigh)>>32
“令 inv_weight = 2^32/sched_prio_to_weigh
“則 virtual_time = (wall_time * 1024 * inv_weight)>>32
由于sched_prio_to_weigh的值存儲(chǔ)在數(shù)組中,inv_weight同樣可以:
constu32sched_prio_to_wmult[40]={
/*-20*/48388,59856,76040,92818,118348,
/*-15*/147320,184698,229616,287308,360437,
/*-10*/449829,563644,704093,875809,1099582,
/*-5*/1376151,1717300,2157191,2708050,3363326,
/*0*/4194304,5237765,6557202,8165337,10153587,
/*5*/12820798,15790321,19976592,24970740,31350126,
/*10*/39045157,49367440,61356676,76695844,95443717,
/*15*/119304647,148102320,186737708,238609294,286331153,
};
經(jīng)過一番計(jì)算,各個(gè)進(jìn)程的虛擬運(yùn)行時(shí)間一致了,似乎我們理解了"完全公平"的思想。
虛擬運(yùn)行時(shí)間與優(yōu)先級(jí)的衰減因子有關(guān),也就是inv_weight隨著nice值增大而增大,同時(shí)其作為分母也加速了低優(yōu)先級(jí)進(jìn)程的衰減。
- nice=0 虛擬運(yùn)行時(shí)間 = 物理運(yùn)行時(shí)間
- nice>0 虛擬運(yùn)行時(shí)間 > 物理運(yùn)行時(shí)間
- nice<0 虛擬運(yùn)行時(shí)間 < 物理運(yùn)行時(shí)間
“簡(jiǎn)言之:CFS將物理運(yùn)行時(shí)間在不同優(yōu)先級(jí)進(jìn)程中發(fā)生了不同的通脹。
摒棄了固定時(shí)間片機(jī)制也是CFS的亮點(diǎn),系統(tǒng)負(fù)載高時(shí)大家都少用一些CPU,系統(tǒng)負(fù)載低時(shí)大家都多用一些CPU,讓調(diào)度器有了一定的自適應(yīng)能力。
pick-next和紅黑樹
那么這些進(jìn)程應(yīng)該采用哪種數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)pick-next算法呢?
CFS調(diào)度器采用了紅黑樹來保存活躍進(jìn)程任務(wù),紅黑樹的增刪查復(fù)雜度是O(logn),但是CFS引入了一些額外的數(shù)據(jù)結(jié)構(gòu),可以免去遍歷獲得下一個(gè)最合適的進(jìn)程。
紅黑樹的key是進(jìn)程已經(jīng)使用的虛擬運(yùn)行時(shí)間,并且把虛擬時(shí)間數(shù)值最小的放到最左的葉子節(jié)點(diǎn),這個(gè)節(jié)點(diǎn)就是下一個(gè)被pick的進(jìn)程了。
前面已經(jīng)論證了,每個(gè)進(jìn)程的虛擬運(yùn)行時(shí)間是一樣的,數(shù)值越小表示被調(diào)度的越少,因此需要更偏愛一些,當(dāng)虛擬運(yùn)行時(shí)間耗盡則從紅黑樹中刪除,下個(gè)調(diào)度周期開始后再添加到紅黑樹上。
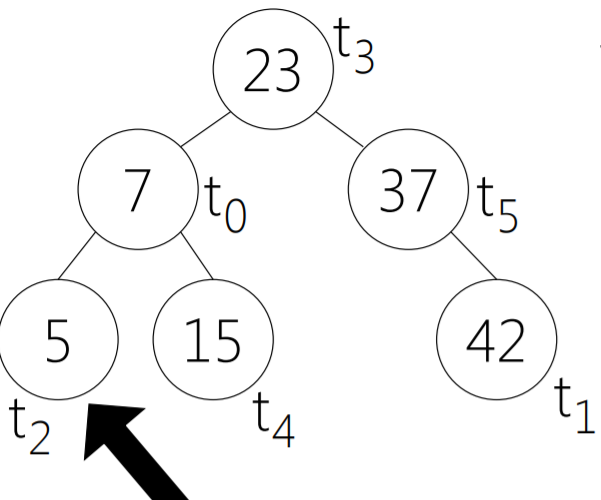

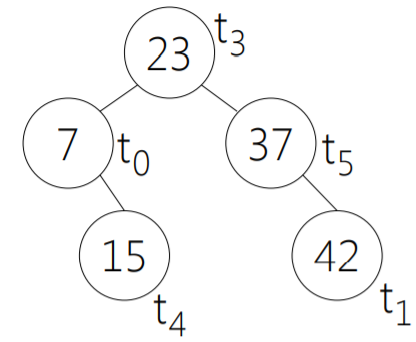
本章重點(diǎn)
- O(n)調(diào)度器采用全局runqueue,導(dǎo)致多cpu加鎖問題和cache利用率低的問題
- O(1)調(diào)度器為每個(gè)cpu設(shè)計(jì)了一個(gè)runqueue,并且采用MLFQ算法思想設(shè)置140個(gè)優(yōu)先級(jí)鏈表和active/expire兩個(gè)雙指針結(jié)構(gòu)
- CFS調(diào)度器采用紅黑樹來實(shí)現(xiàn)O(logn)復(fù)雜度的pick-next算法,摒棄固定時(shí)間片機(jī)制,采用調(diào)度周期內(nèi)的動(dòng)態(tài)時(shí)間機(jī)制
- O(1)和O(n)都在交互進(jìn)程的識(shí)別算法上下了功夫,但是無法做的100%準(zhǔn)確
- CFS另辟蹊徑采用完全公平思想以及虛擬運(yùn)行時(shí)間來實(shí)現(xiàn)進(jìn)行的調(diào)度
- CFS調(diào)度器也并非銀彈,在某些方面可能不如O(1)
原文標(biāo)題:Linux進(jìn)程調(diào)度器
文章出處:【微信公眾號(hào):Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
Linux
+關(guān)注
關(guān)注
87文章
11123瀏覽量
207908 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7174瀏覽量
87153 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6545瀏覽量
122743 -
調(diào)度器
+關(guān)注
關(guān)注
0文章
98瀏覽量
5210
原文標(biāo)題:Linux進(jìn)程調(diào)度器
文章出處:【微信號(hào):LinuxHub,微信公眾號(hào):Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
實(shí)時(shí)操作系統(tǒng)和分時(shí)操作系統(tǒng)的區(qū)別
深入探討Linux的進(jìn)程調(diào)度器

深入理解和實(shí)現(xiàn)RTOS_連載
深入理解和實(shí)現(xiàn)RTOS_連載
【安富萊】【RTX操作系統(tǒng)教程】第10章 任務(wù)調(diào)度-搶占式,時(shí)間片和合作式
怎么學(xué)習(xí)嵌入式Linux操作系統(tǒng)
深入理解STM32
對(duì)棧的深入理解
MINIX嵌入式操作系統(tǒng)進(jìn)程調(diào)度的移植

嵌入式linux操作系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論