 如何實現更綠色、經濟的NLP預訓練模型遷移
如何實現更綠色、經濟的NLP預訓練模型遷移
NLP中,預訓練大模型Finetune是一種非常常見的解決問題的范式。利用在海量文本上預訓練得到的Bert、GPT等模型,在下游不同任務上分別進行finetune,得到下游任務的模型。然而,這種方式的代價也很大,經常要對所有任務都保存一個完整的task-specific模型,隨著預訓練模型體積越來越大,這種方式會占用很多存儲空間,當下游任務很多的時候要存儲大量的預訓練模型。同時,為每個任務finetune一個如此龐大的模型,訓練資源的消耗也比較大。
為了實現更綠色、經濟的NLP預訓練模型遷移,近兩年來業內提出了很多優化finetune的方法,例如adapter finetune、mask finetune等。最近很火的prompt更是極大減輕了finetune開銷,甚至不進行finetune就能應用于下游任務。本文重點介紹近兩年幾個NLP中finetune優化的經典工作,包括adapter-finetune、side-tuning、mask-finetune以及prefix-finetune等工作。
Adapter-tuning
遷移NLP預訓練模型的方法主要分為finetune和feature-based。Finetune將原來的模型在下游任務上進行訓練,而feature-based方法使用預訓練模型產出的詞、句子等embedding作為輸入,接下游一個獨立的模型進行預測。其中finetune的效果往往由于feature-based方法。然而finetune的計算開銷要比feature-based大很多,能不能采用一種折中的方式呢?Parameter-Efficient Transfer Learning for NLP(ICML 2019)提出了一種更經濟的遷移學習方法adapter-tuning,只需要finetune少量參數就能達到和finetune整個模型不相上下的效果。具體做法為,在原來的Bert模型的每層中間加入兩個adapter,adapter首先通過全連接對原輸入進行降維進一步縮小參數量,經過內部的NN后再將維度還原,形成一種bottleneck的結構。在finetune過程中,原預訓練Bert模型的參數freeze住不更新,只更新adapter的參數,大大減少了finetune階段需要更新和保存的參數量。
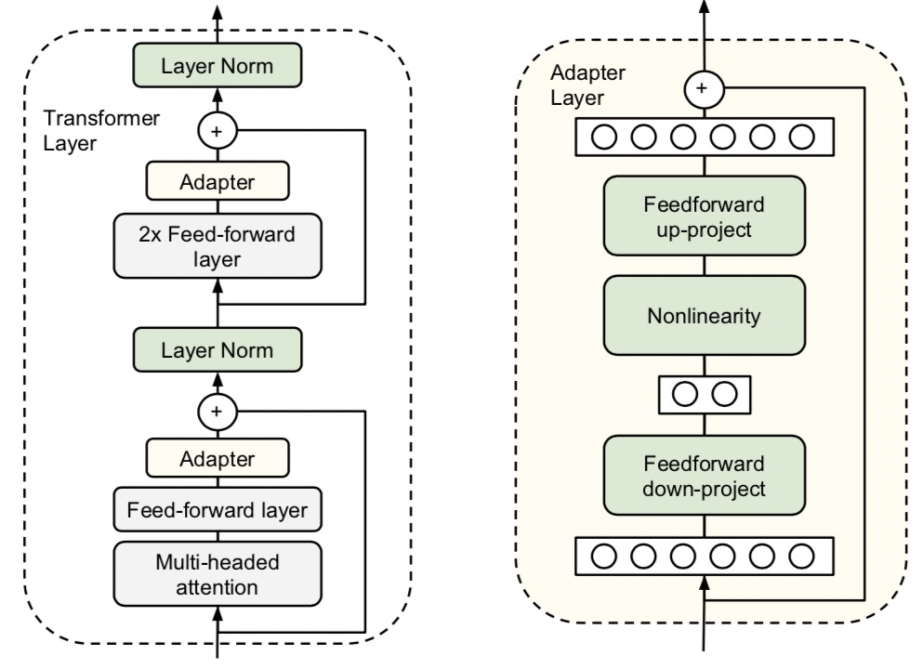
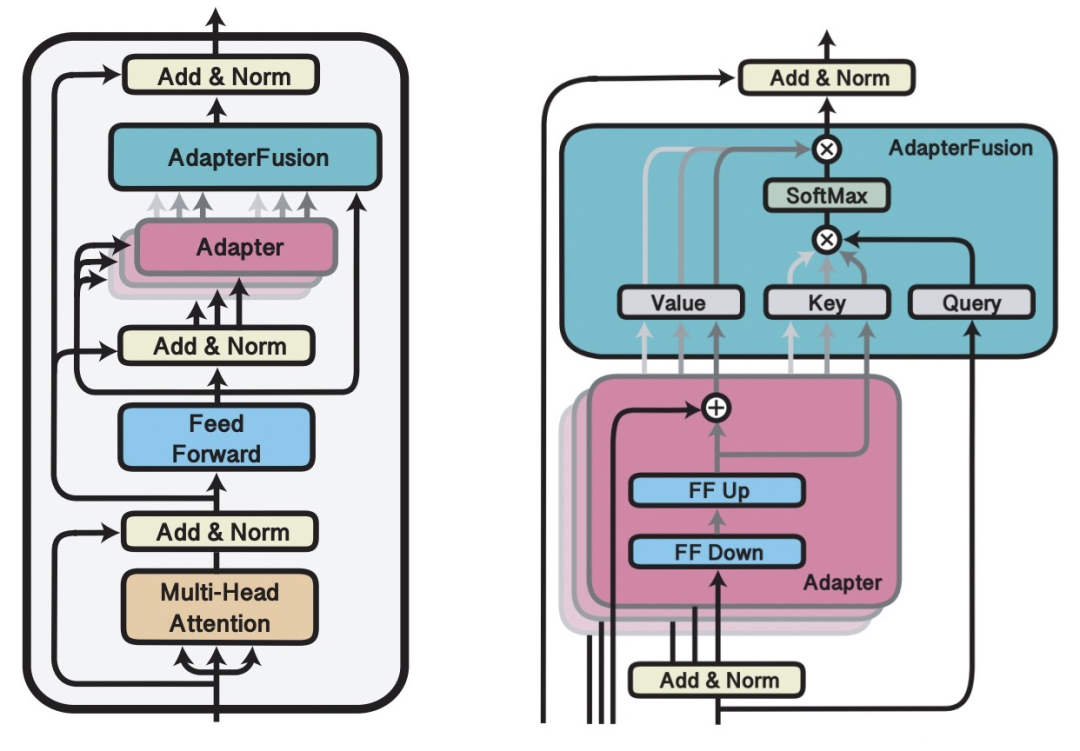
AdapterFusion: Non-Destructive Task Composition for Transfer Learning(2021)在Adapter Finetune的基礎上,提出當下游存在多個任務的時候,使用兩階段的Finetune。第一階段和Adapter Finetune的思路一樣,在預訓練大模型基礎上加上每個任務的adapter進行finetune,大模型參數freeze。在第二階段,繼續freeze預訓練模型,同時freeze住第一階段訓練的adapter模型參數,學習一個AdapterFusion模型,這個模塊的作用是融合各個adapter的信息,實現下游多個任務之間的信息共享。AdapterFusion部分的思路是,利用當前樣本在FF層的輸出和各個任務的adapter輸出做Attention,實現從多個Adapter產出信息中的選擇和融合。這樣模型實現了根據每個樣本選擇合適的adapter輸出,綜合了多任務的adapter信息。
Side-Tuning
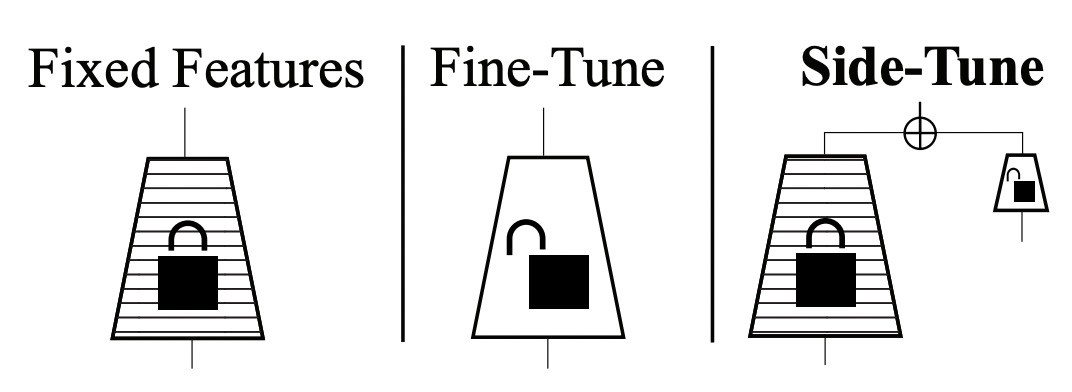
Side-tuning: A baseline for network adaptation via additive side networks(ECCV 2019)提出了一種side-tuning的方法。如下圖,side-tune是在原來的預訓練模型基礎上,增加一個小的side network,然后將預訓練模型的輸入和side-network的輸出進行融合。融合的方法文中提出使用一個可學習的參數α進行加權融合就能取得比較的效果。在訓練過程中,預訓練模型不會進行更新,只更新side-network部分的參數。Side模型的尺寸和復雜度也可以根據任務的難易程度進行調整。Side-tuning和adapt-tuning有相似之處,都是利用一個附屬的小模型對原預訓練大模型的表示進行更精細化的針對下游任務的調整。
Mask-tuning
Masking as an efficient alternative to finetuning for pretrained language models(2020)提出一種簡單的mask方法實現高效finetune。相比一般的finetune,該方法在finetune階段不對參數進行調整,而是學習一個mask矩陣。對于每一個Transformer層,都會學習一個0-1的矩陣,然后用這個矩陣對該層所有全連接權重進行縮放。公式如下,m表示矩陣中某一個元素,根據一個閾值設置為1或0,再用這個矩陣和每層的全連接參數相乘進行對應元素的縮放。
Mask-tuning的出發點為,在預訓練模型finetune的過程中,其實不需要finetune那么多參數,只要finetune一些關鍵參數就能達到較好的效果,減少finetune階段計算的冗余性。在How fine can fine-tuning be? Learning efficient language models(2020)一文中也提出了類似的思路。
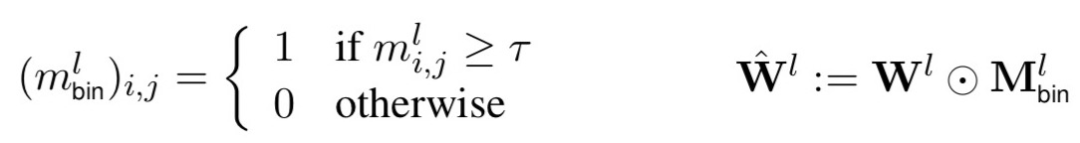
Mask-tuning的出發點為,在預訓練模型finetune的過程中,其實不需要finetune那么多參數,只要finetune一些關鍵參數就能達到較好的效果,減少finetune階段計算的冗余性。在How fine can fine-tuning be? Learning efficient language models(2020)一文中也提出了類似的思路。
Prefix-tuning
REFORMER: THE EFFICIENT TRANSFORMER(ICLR 2020)提出了采用局部敏感哈希的方法提升Transformer效率。當序列較長時,QK^T的維度[batch_size, L, L]的計算量和存儲開銷會非常大,但是由于我們關注的是softmax后的結果,并不關注QK^T本身是什么,而softmax只關注值最大的幾個元素,因此我們可以只選擇k<
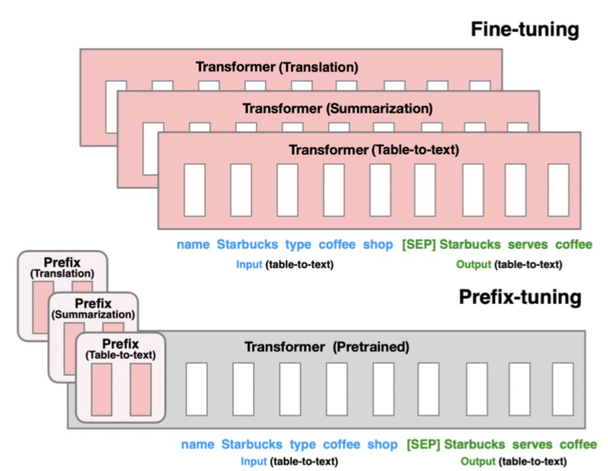
Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021)提出的方法只finetune 0.1%的參數就取得和finetune相當的效果,并且在少樣本任務上效果優于finetune。本文提出針對自然語言生成任務(如摘要生成、table-to-text等任務)的遷移預訓練大模型的方法。基于Language models are few-shot learners(2020,GPT3)等文章中提出的Prompt思路,只要能給模型一個合適的上下文信息context,預訓練的語言模型不需要修改參數就能很好的解決下游問題。例如當我們想生成Obama這個詞,只要上下文信息給Barack,模型就可有可能生成Obama,因為模型在預訓練階段已經學到了這些信息。
該方法的具體實現為,將預訓練的Transformer模型參數整體Freeze住,當正常輸入文本序列的時候,在最前端添加幾個prefix id,每一個prefix id都對應一個隨機初始化的embedding,不同的任務有不同的prefix id。這樣在模型中,prefix之后每個時刻的表示都會受到prefix的影響,prefix代表某個對應具體任務的上下文信息。在Finetune過程中,模型的其他參數都Freeze,只finetune prefix的embedding,以及prefix后面接的一些全連接層,Finetune參數量只占整體模型的0.1%,遠小于其他的Finetune方法。該方法核心思想利用了prefix embedding去學習對于某個任務來說,需要從預訓練語言模型中提取什么樣的信息。
總結
NLP領域預訓練大模型的發展,催生出很多針對如何提升遷移效率的研究工作。從目前的研究趨勢來看,基于prompt思想的finetune是未來的一個重要研究趨勢,充分利用預訓練模型的信息,讓下游任務更貼近預訓練模型,而不是讓預訓練模型貼近下游任務。后續我們也會對prompt進行更為詳細的介紹。
原文標題:NLP中的綠色Finetune方法
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
存儲
+關注
關注
13文章
4127瀏覽量
85286 -
參數
+關注
關注
11文章
1668瀏覽量
31891 -
模型
+關注
關注
1文章
3032瀏覽量
48374
原文標題:NLP中的綠色Finetune方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于不同量級預訓練數據的RoBERTa模型分析
【大語言模型:原理與工程實踐】大語言模型的預訓練
為什么要使用預訓練模型?8種優秀預訓練模型大盤點
遷移學習與模型預訓練:何去何從

基于BERT的中文科技NLP預訓練模型
2021 OPPO開發者大會:NLP預訓練大模型
2021年OPPO開發者大會 融合知識的NLP預訓練大模型






 工商網監
工商網監
評論