") Propt learnimng是如何發(fā)展形成的
Propt learnimng是如何發(fā)展形成的
1 簡(jiǎn)介
Prompt learning作為近期NLP的新寵,熱度不斷攀升,在接下來(lái)的一段日子,大概率還是會(huì)處于一個(gè)風(fēng)口的位置。什么是Prompt learing?就是通過(guò)引入模版來(lái)將原始輸入改造成類似于完形填空的格式,讓語(yǔ)言模型去回答,進(jìn)而推斷出下游任務(wù)的結(jié)果。prompt leanring是如何發(fā)展形成的?包括組成?類型?面臨哪些挑戰(zhàn)?帶著這些問(wèn)題,我們對(duì)相關(guān)內(nèi)容做了一定的梳理,希望能讓大家對(duì)于Prompt learning整個(gè)框架有個(gè)清晰的認(rèn)識(shí)。
2 NLP發(fā)展的四個(gè)階段
要了解一個(gè)人的話需要去了解他/她的過(guò)去。prompt learning作為NLP發(fā)展的重大產(chǎn)物,又有怎樣的一段過(guò)去呢?縱觀整個(gè)NLP的發(fā)展,它可以分為以下幾個(gè)階段。
a) 第一個(gè)階段:feature engineering
對(duì)應(yīng)下圖中的Fully Supervised Learning (Non-Neural Network),這是大家常提的特征工程階段,由于缺乏充分的有監(jiān)督訓(xùn)練數(shù)據(jù),早期的NLP倚重于前期的特征工程,這需要相關(guān)研究人員或者專業(yè)人士利用自己扎實(shí)的領(lǐng)域知識(shí)從原始數(shù)據(jù)中定義并提取有用的特征供模型學(xué)習(xí)。這個(gè)階段構(gòu)建特征依賴于大量的人工,特征工程的效果也極大程度影響到模型的最終表現(xiàn)。
b) 第二個(gè)階段:architecture engineering
對(duì)應(yīng)下圖中的Fully Supervised Learning (Neural Network),隨著神經(jīng)網(wǎng)絡(luò)的到來(lái),NLP逐漸過(guò)渡到架構(gòu)工程這個(gè)階段,在這個(gè)時(shí)期,大家更注重于如何設(shè)計(jì)一個(gè)合理的網(wǎng)絡(luò)結(jié)果去學(xué)習(xí)有用的特征,從而減少對(duì)人工構(gòu)建特征的依賴。
c) 第三個(gè)階段:objective engineering
對(duì)應(yīng)下圖中的Pre-train, Fine-tune,這也是前幾年常掛在嘴邊的預(yù)訓(xùn)練時(shí)代。在這個(gè)時(shí)期,NLP流行的方法基本都是在大量語(yǔ)料上進(jìn)行預(yù)訓(xùn)練,然后再在少量的下游任務(wù)下完成微調(diào)。在這種范式下,更注重于目標(biāo)的設(shè)計(jì),合理設(shè)計(jì)預(yù)訓(xùn)練跟微調(diào)階段的目標(biāo)函數(shù),對(duì)最終的效果影響深遠(yuǎn)。前面兩個(gè)階段都依賴于有監(jiān)督學(xué)習(xí),但是這個(gè)階段里的預(yù)訓(xùn)練可以不需要有監(jiān)督的數(shù)據(jù),極大的降低了對(duì)監(jiān)督語(yǔ)料的依賴。
d) 第四個(gè)階段:prompt engineering
對(duì)應(yīng)下圖中的Pre-train, Prompt, Predict,也就是本章節(jié)想要介紹的prompt learning的時(shí)期。在這個(gè)時(shí)期,依舊會(huì)在大量語(yǔ)料上進(jìn)行預(yù)訓(xùn)練,但是在特定下游任務(wù)下可以通過(guò)引入合適的模版(prompt)去重構(gòu)下游任務(wù),管控模型的行為,實(shí)現(xiàn)zero shot或者few shot。一個(gè)合適的模版甚至可以讓模型擺脫對(duì)下游特定任務(wù)數(shù)據(jù)的要求,所以如何構(gòu)建一個(gè)合理有效的prompt成為了重中之重。
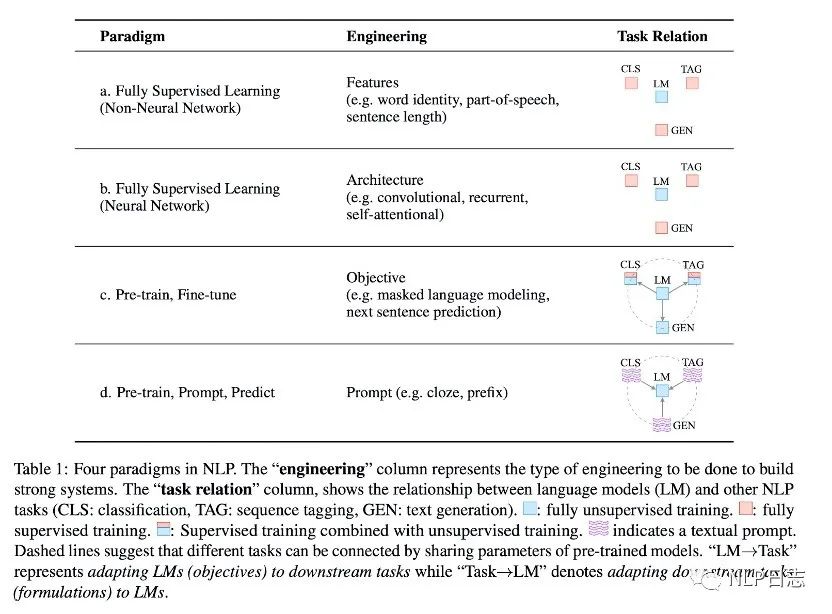
圖2: NLP的發(fā)展歷上的四種范式
3 Prompt learning
傳統(tǒng)的監(jiān)督學(xué)習(xí)任務(wù),是去訓(xùn)練一個(gè)模型P(y|x),接收x作為輸入,去預(yù)測(cè)y。Prompt learning則不然,它依賴于預(yù)訓(xùn)練語(yǔ)言模型P(x),通過(guò)引入合適的模版template將輸入x調(diào)整為完形填空格式的x’,調(diào)整后的輸入x’里含有某些空槽,利用語(yǔ)言模型P將空槽填充后就可以推斷出對(duì)應(yīng)的y。例如對(duì)于情感分析任務(wù),傳統(tǒng)的做法就是訓(xùn)練一個(gè)判別模型,去預(yù)測(cè)輸入x對(duì)應(yīng)的標(biāo)簽是positive或者negative,但是如果是prompt learning,則是利用合適模版,將輸入x調(diào)整為 [x], it is [z]。然后作為語(yǔ)言模型的輸入去預(yù)測(cè)相應(yīng)z的取值,如果z是positive相關(guān)的詞,就表示原始輸入x是positive,反之就是negative的。
Prompt learning包括三個(gè)部分,分別是prompt addition,answer search, answer mapping。
a) Prompt addition
選擇合適的模版,定義函數(shù)fprompt(x),可以將原始的輸入x轉(zhuǎn)化為x‘,即fprompt(x)=x’。經(jīng)過(guò)該函數(shù)轉(zhuǎn)化得到的輸入都是帶有空槽,槽位上的預(yù)測(cè)值會(huì)直接決定最后的結(jié)果。另外,這里的模版不僅僅可以是離散化的token,也可以連續(xù)的向量。在不同的下游任務(wù),可以靈活調(diào)整,選擇合適的模版。
b) Answer search
通過(guò)prompt函數(shù)后,將x’輸入到語(yǔ)言模型,去預(yù)測(cè)使得語(yǔ)言模型得分最高的候選槽值。Answer search指的就是從所有可能的候選槽值進(jìn)行搜索,然后選擇合適的槽值填充到對(duì)應(yīng)的空槽里。這里槽值的所有可能結(jié)果的集合為Z,對(duì)于生成任務(wù)而言,Z包括所有的token,但是對(duì)于分類任務(wù)而言,Z只包含跟特定分類任務(wù)相關(guān)的一部分token。例如對(duì)于之前那個(gè)例子而言,Z={positive相關(guān)的詞語(yǔ),negative相關(guān)的詞語(yǔ)}
c) Answer mapping
當(dāng)通過(guò)answer search得到合適的槽值時(shí),需要根據(jù)槽值推斷最終的預(yù)測(cè)結(jié)果。這部分比較直接,假如是生成任務(wù),那么填充的槽值就是最終的結(jié)果。但如果是分類任務(wù),就需要根據(jù)相應(yīng)的槽值歸納到具體的類中。例如情感分類中,如果把跟positive相關(guān)的槽值都?xì)w類到positive一類,把跟negative相關(guān)的槽值歸類到negative一類中。
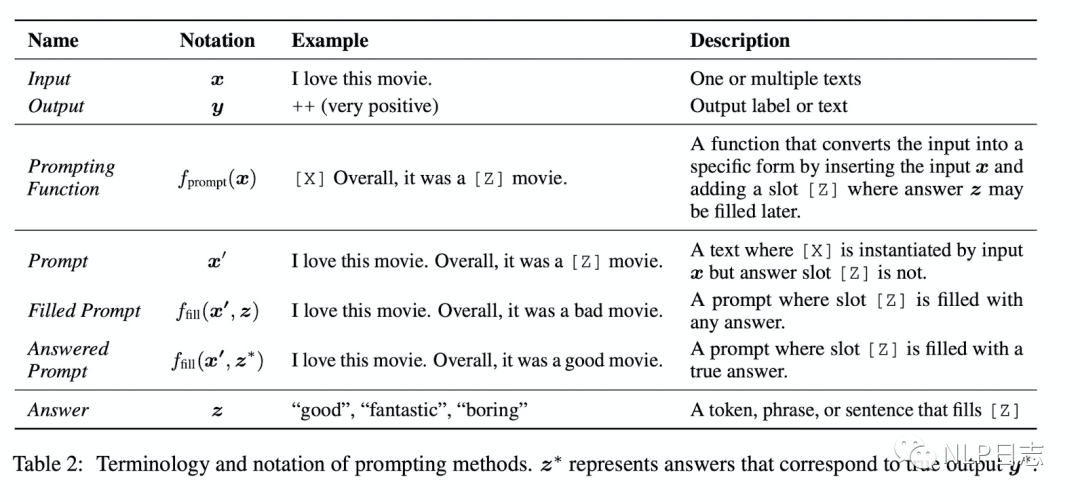
圖3: Prompt learning
在了解prompt learning的基本組成后,不容易發(fā)現(xiàn),有以下幾個(gè)方面都會(huì)影響prompt learning的最終效果,后續(xù)我們?cè)賴@著這幾點(diǎn)分別展開。
a) Prompt engineering,如何選擇一個(gè)合適的模版,也就是設(shè)計(jì)合適的模版函數(shù),是整個(gè)prompt learning的第一個(gè)步。
b) 預(yù)訓(xùn)練語(yǔ)言模型的選擇, 如何預(yù)測(cè)空槽位置上的答案依賴于預(yù)訓(xùn)練語(yǔ)言模型的得分,同時(shí)預(yù)訓(xùn)練語(yǔ)言模型又有4大類。(在文本生成系列的文章對(duì)這這部分的介紹已經(jīng)很詳細(xì)了,這里就不贅述了。)
c) Answer engineering,如何構(gòu)建一個(gè)合適的答案候選集以及一個(gè)從答案到最終結(jié)果的映射。
d) Expanding the paradigm,如何基于基礎(chǔ)的prompt learning去擴(kuò)展,包括multi prompt等。
e) Training strategy,如何選擇訓(xùn)練策略,去訓(xùn)練一個(gè)合適的模型。
4 Prompt engineering
Prompt engineering,如何構(gòu)建一個(gè)合適的模版函數(shù),使得在下游任務(wù)能取得最高效的表現(xiàn)。Prompt learning利用預(yù)訓(xùn)練語(yǔ)言模型去預(yù)測(cè)最終結(jié)果,那么如何將輸入x轉(zhuǎn)化為語(yǔ)言模型擅長(zhǎng)處理的樣式就是Prompt engineering的工作。一個(gè)不合適的prompt function會(huì)導(dǎo)致語(yǔ)言模型不能做出令人滿意的預(yù)測(cè)。為了最終任務(wù)的效果,我們需要根據(jù)語(yǔ)言模型和下游任務(wù)的特性,去構(gòu)建合理的prompt。
如果模版處于輸入x之中,那么稱為cloze prompt,這種情形多應(yīng)用于使用掩碼語(yǔ)言模型的場(chǎng)景,它能夠緊密的跟掩碼語(yǔ)言模型的預(yù)訓(xùn)練過(guò)程相配合。如果輸入x全部位于模版內(nèi)容之前,那么稱為prefix prompt,這種情形多應(yīng)用于生成任務(wù)或者使用使用自回歸的語(yǔ)言模型的場(chǎng)景,它能跟從左往右的回歸模型本質(zhì)更加匹配。
Prompt可以是通過(guò)人工構(gòu)建的,根據(jù)人的經(jīng)驗(yàn)知識(shí)構(gòu)建合理的prompt,這也是最直接的方式。但是通過(guò)人工構(gòu)建的模版需要耗費(fèi)時(shí)間跟精力, 而且即便是專業(yè)人員也不一定能構(gòu)建得到最優(yōu)的prompt,為此,衍生了不少自動(dòng)選擇prompt的方法,其中包括離散的prompt,也包括連續(xù)的prompt。
5 Answer engineering
Answer engineering旨在尋找一個(gè)合適的答案空間Z以及一個(gè)從答案到最終輸入y的一個(gè)映射。Prompt learning之所以能實(shí)現(xiàn)few shot甚至zero shot,是依仗于預(yù)訓(xùn)練語(yǔ)言模型強(qiáng)大的泛化能力。但是語(yǔ)言模型在預(yù)測(cè)時(shí)都是針對(duì)全詞表的,對(duì)于下游任務(wù)而言并不一定需要全詞表的,例如情感分析任務(wù)下如果預(yù)測(cè)到人稱代詞時(shí)要怎么推斷最終結(jié)果的情緒呢?為此,Answer engineering要去尋找一個(gè)跟下游任務(wù)匹配的答案空間,也就是構(gòu)建候選集,并定義好答案空間到最終輸出之間的映射,候選詞跟最終輸出的對(duì)應(yīng)關(guān)系。
Answer engineering里的答案空間可以是由token,或者片段,或者完整的句子組成。Token跟片段的情形多見于分類相關(guān)任務(wù),完整的句子多見于生成相關(guān)任務(wù)。答案空間同樣也可以通過(guò)人工構(gòu)建,也可以通過(guò)模型去搜索查找。大部分的方法構(gòu)造的候選集都是離散化的,只有很少部分方法是連續(xù)化的。
6 Multi-prompt learning
跟打比賽時(shí)經(jīng)常會(huì)集成多個(gè)模型的思路如出一轍,相對(duì)于單個(gè)prompt,多個(gè)prompt往往能提高prompting methods的有效性。常見的多個(gè)prompt的方法有以下幾種類型。
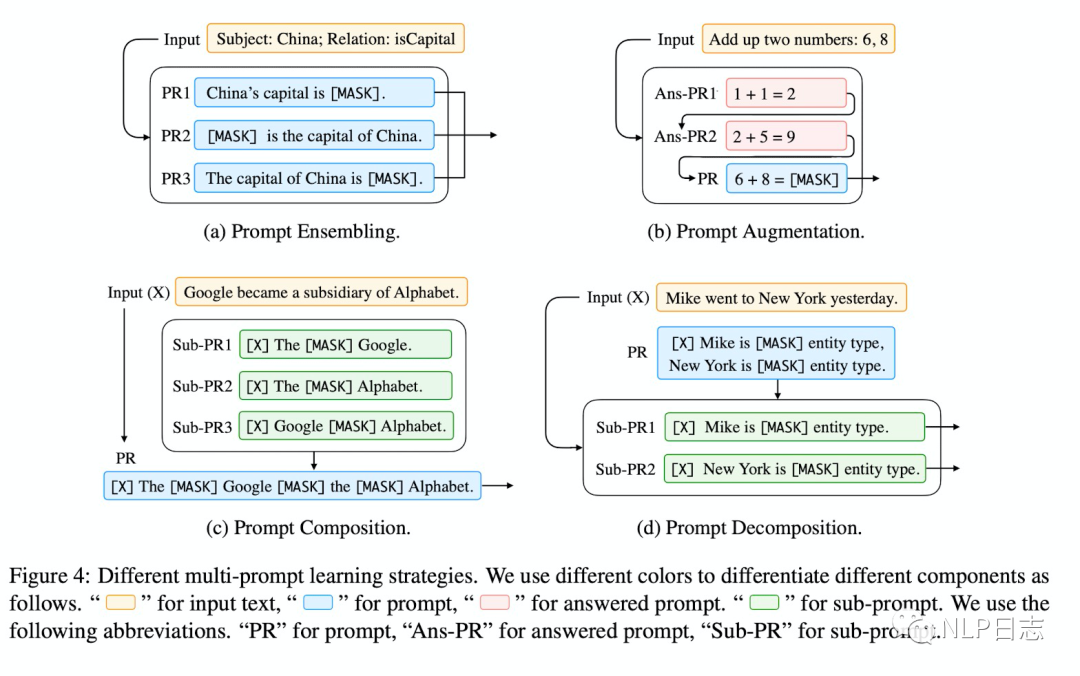
圖4: multi-prompt的類型
a) Ensemble
多個(gè)prompt,每個(gè)prompt都按照單prompt的方法并行進(jìn)行,然后再把最終的結(jié)果匯總,可以通過(guò)加權(quán)或者投票的方式匯總多個(gè)單prompt的方法的結(jié)果。
b) Augmentation
增強(qiáng)的方式其實(shí)就是找一個(gè)跟當(dāng)前問(wèn)題相似的case,然后將這個(gè)case跟當(dāng)前輸入x‘一起輸入,這種模型就可以根據(jù)那個(gè)case對(duì)x‘做出更精準(zhǔn)的預(yù)測(cè)了。
c) Composition
同時(shí)利用多個(gè)prompt構(gòu)建prompt函數(shù),每個(gè)prompt負(fù)責(zé)一個(gè)子任務(wù),把多個(gè)prompt的內(nèi)容融合到一起,同時(shí)進(jìn)行多個(gè)子任務(wù)的預(yù)測(cè)。例如關(guān)系抽取任務(wù),有的prompt負(fù)責(zé)實(shí)體識(shí)別,有的prompt負(fù)責(zé)判斷實(shí)體間的關(guān)系。
d) Decomposition
對(duì)于有多個(gè)預(yù)測(cè)值的任務(wù),將原始的任務(wù)拆分程多個(gè)子任務(wù),引入多個(gè)prompt,分別處理子任務(wù),彼此隔離。也就是把多個(gè)預(yù)測(cè)值的任務(wù)拆分程多個(gè)單prompt任務(wù)去分別處理。
7 Training strategy
根據(jù)是否需要在語(yǔ)言模型的基礎(chǔ)上引進(jìn)新的跟模版相關(guān)的參數(shù),以及模型參數(shù)是否凍結(jié)可以分為以下4種。(圖中第一種不算是prompt learning)
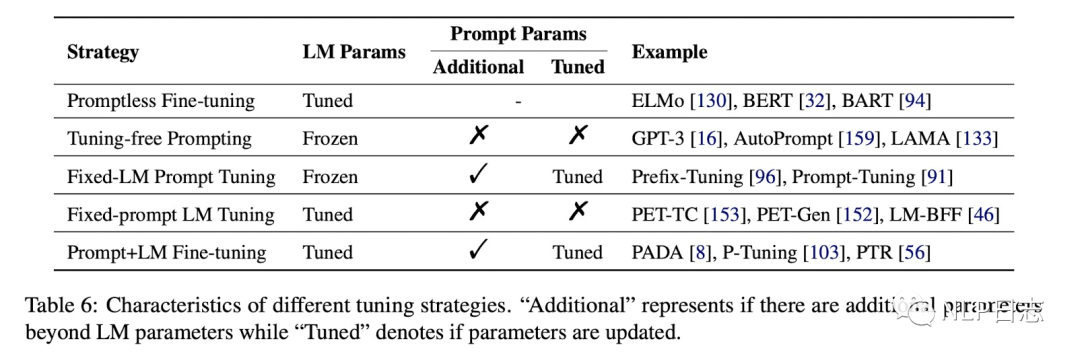
圖5:訓(xùn)練策略
a) Prompt fine-tuning
NLP發(fā)展史上第三個(gè)階段的先預(yù)訓(xùn)練然后再微調(diào)的方法。
b) Tuning-free Prompting
不需要微調(diào),直接利用一個(gè)prompt做zero-shot任務(wù)
c) Fixed_LM Prompt Tuning
引進(jìn)了額外的跟prompt相關(guān)的的參數(shù),通過(guò)固定語(yǔ)言模型參數(shù),去微調(diào)跟prompt相關(guān)的參數(shù)。
d) Fixed-prompt LM Tuning
引進(jìn)了額外的跟prompt相關(guān)的的參數(shù),通過(guò)固定prompt相關(guān)參數(shù),去微調(diào)語(yǔ)言模型參數(shù)。
f) Prompt+LM Tuning
同時(shí)微調(diào)語(yǔ)言模型跟prompt相關(guān)的參數(shù)。
8 總結(jié)
Propt learnimng,充分利用了預(yù)訓(xùn)練語(yǔ)言模型強(qiáng)大的泛化能力,極大的減少了對(duì)下游任務(wù)有監(jiān)督數(shù)據(jù)的依賴,能實(shí)現(xiàn)few shot甚至zero shot,對(duì)于當(dāng)下數(shù)量眾多的NLP下游任務(wù),有很大的應(yīng)用前景。但是關(guān)于如何構(gòu)建prompt,如何選擇語(yǔ)言模型,構(gòu)建候選答案空間,構(gòu)建答案到最終輸出的映射,如何選擇訓(xùn)練策略,如何尋找一個(gè)最佳配置使得下游任務(wù)效果達(dá)到最優(yōu),依舊是個(gè)需要持續(xù)探索的事情。
原文標(biāo)題:Prompt learning入門
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
審核編輯:湯梓紅
-
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7519瀏覽量
88635 -
模型
+關(guān)注
關(guān)注
1文章
3174瀏覽量
48718 -
nlp
+關(guān)注
關(guān)注
1文章
487瀏覽量
22012
原文標(biāo)題:Prompt learning入門
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
電路漏電流形成及預(yù)防知識(shí)
電壓形成的原因?
PIM的形成原因與測(cè)試方法
基于FPGA器件和LVDS技術(shù)設(shè)計(jì)的高速實(shí)時(shí)波束形成器
高速PCB設(shè)計(jì)信號(hào)完整性問(wèn)題形成原因是什么?
什么是地環(huán)路?地環(huán)路是如何形成的?怎么解決?
智能卡芯片的發(fā)展及其所形成的設(shè)計(jì)方法
倉(cāng)儲(chǔ)機(jī)器人近兩年飛速發(fā)展 競(jìng)爭(zhēng)格局逐漸形成
VR產(chǎn)業(yè)發(fā)展的戰(zhàn)略窗口期已然形成
工信部新版新能源汽車發(fā)展規(guī)劃初稿形成 將推動(dòng)新能源汽車產(chǎn)業(yè)高質(zhì)量可持續(xù)發(fā)展
OLED產(chǎn)業(yè)發(fā)展集群化,帶動(dòng)產(chǎn)業(yè)鏈加速形成
開關(guān)電器電弧的形成





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論