") 900GB/s,NVLink才是英偉達(dá)的互聯(lián)殺手锏
900GB/s,NVLink才是英偉達(dá)的互聯(lián)殺手锏
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))英偉達(dá)在GTC22上發(fā)布了全新的GraceSuperchip,該芯片中用到了NVLink-C2C技術(shù),而去年公開的GraceHopperSuperchip同樣用到了這一技術(shù)。根據(jù)英偉達(dá)超大規(guī)模計(jì)算部門副總裁IanBuck的說(shuō)法,Chiplet和異構(gòu)計(jì)算已經(jīng)成了解決摩爾定律緩慢進(jìn)展的兩大有效手段。而NVLink-C2C這一面向die和chip的互聯(lián)技術(shù),成了英偉達(dá)對(duì)愈發(fā)普及的Chiplet設(shè)計(jì)的回應(yīng)。
Superchip的互聯(lián)
也許在不少人看來(lái)的印象中,提到NVLink會(huì)想到下圖這個(gè)橋接多個(gè)高端顯卡或?qū)I(yè)顯卡的RTX NVLinkBridge,其實(shí)NVLink這一技術(shù)在服務(wù)器級(jí)別的GPU中反倒更為普遍。從P100的第一代NVLink,到V100的第二代NVLink,A100的第三代NVLink,最后再到如今H100的第四代NVLink。NVLink可以說(shuō)是跟著GPU架構(gòu)一路推陳出新了,如今享受第四代NVLink性能的成了Hopper架構(gòu)的GPU。而在英偉達(dá)的SERDES和LINK技術(shù)發(fā)展下,NVLink也從PCB、MCM走向了硅中介層和晶圓,也因此有了NVLink-C2C。

RTX NVLinkBridge/ 英偉達(dá)
GraceSuperchip顯然用的是ARM NeoverseN2這一基于Armv9架構(gòu)的設(shè)計(jì),但從芯片圖可以看出,單個(gè)GraceSuperchip芯片由兩個(gè)GraceCPU組成,才讓總核心數(shù)達(dá)到了144。而這兩個(gè)CPU組成的方式,正是NVLink-C2C這一互聯(lián)技術(shù)。我們?cè)陂_頭已經(jīng)提到,去年公開的GraceHopperSuperchip同樣使用了這一互聯(lián)技術(shù),只不過(guò)當(dāng)時(shí)單個(gè)GraceHopperSuperchip芯片中互聯(lián)的,是一個(gè)GraceCPU和一個(gè)HopperGPU。
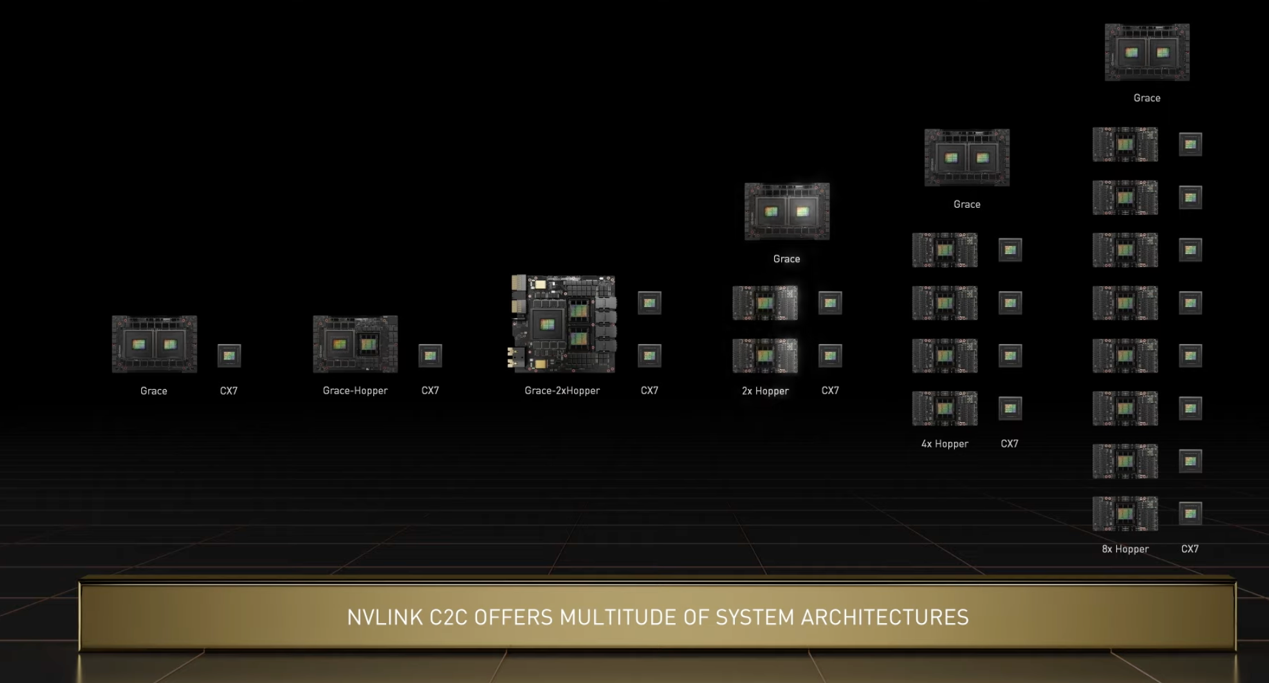
NVLink-C2C為英偉達(dá)帶來(lái)的遠(yuǎn)不止這樣一對(duì)一的互聯(lián)方案,而是一整套系統(tǒng)架構(gòu)上的創(chuàng)新。在NVLink-C2C的支持下,英偉達(dá)可以選擇一個(gè)GraceCPU,兩個(gè)HopperGPU的設(shè)計(jì),或是兩個(gè)2個(gè)GraceCPU+2個(gè)HopperGPU,甚至是2個(gè)GraceCPU+8個(gè)HopperGPU。可以看出,NVLink-C2C為Grace和Hopper在數(shù)據(jù)中心和HPC應(yīng)用提供了極大的擴(kuò)展性。
遠(yuǎn)超PCIe5.0的性能
英偉達(dá)強(qiáng)調(diào),NVLink-C2C具有前所未有的性能,比如處理器與加速器之間900GB/s的高帶寬數(shù)據(jù)傳輸,以及快速同步和高頻率更新下的超低延遲,以及在先進(jìn)封裝英偉達(dá)芯片下,能效比可以做到PCIe5.0的25倍,面積效率更是達(dá)到90倍。

H100 SXM5 GPU / 英偉達(dá)
NVLink-C2C900GB/s的帶寬確實(shí)優(yōu)秀,也與第四代NVLink的性能一致,但這并不代表只要用上NVLink就能獲得,我們從Hopper架構(gòu)的GPU H100的參數(shù)上也能窺見一二。要想獲得900GB/s的帶寬性能,必須用到SXM5的大功率卡,而不是PCIe5.0的卡,雖然前者的功耗是后者的兩倍,達(dá)到了可怕的700W,但PCIe5.0的H100在總體性能和帶寬上確實(shí)差SXM5一截。
兩者在PCIe5.0上的帶寬一致,都是128GB/s,但如果用上NVLink,PCIe5.0版本的H100只能達(dá)到600GB/s的帶寬,與第三代NVLink性能一致,只有SXM5版本下的NVLink才能達(dá)到滿血的900GB/s。
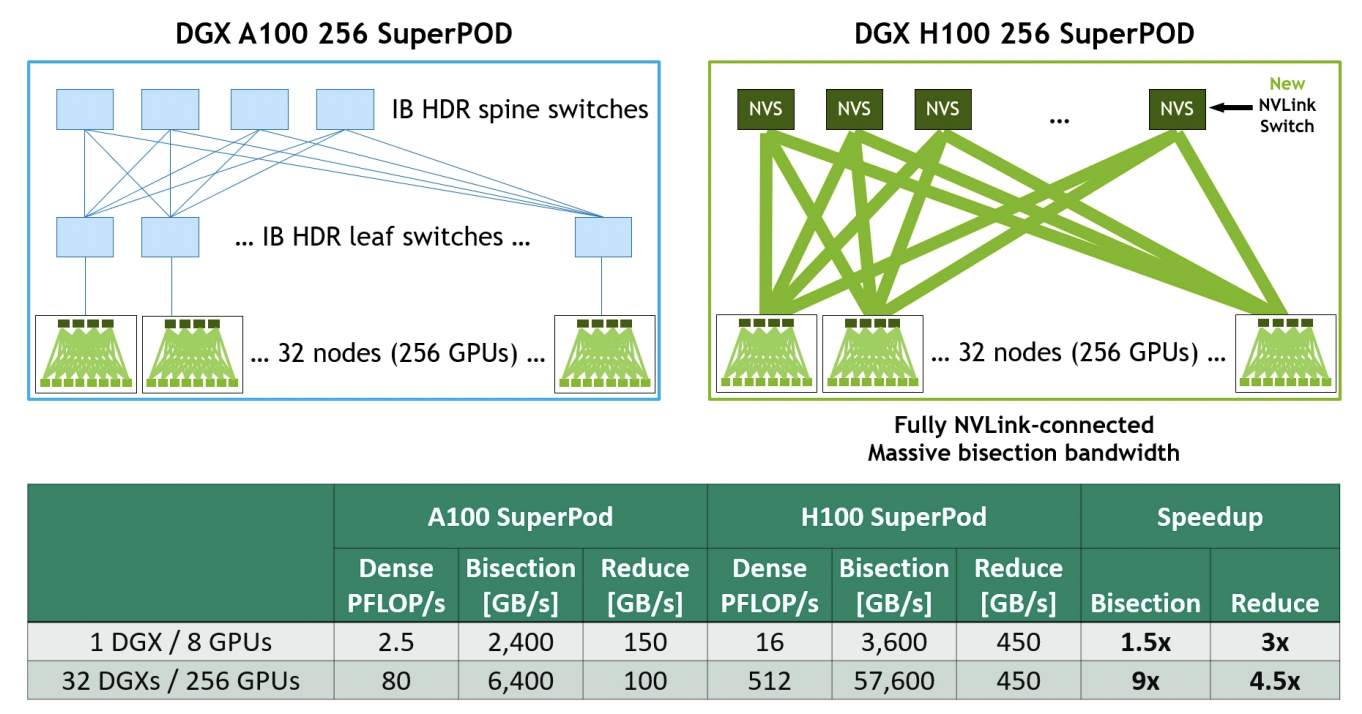
另外在第四代NVLink和第三代NVSwitch技術(shù)的組合下,英偉達(dá)推出了NVLinkSwitch這一方案,該系統(tǒng)最多支持到256個(gè)GPU,可實(shí)現(xiàn)57.6TB/s的總帶寬。NVLinkSwitch也是英偉達(dá)DGX H100 SuperPOD系統(tǒng)的關(guān)鍵技術(shù),英偉達(dá)甚至把自己收購(gòu)的Mellanox旗下的InfiniBand節(jié)點(diǎn)互聯(lián)技術(shù)拿來(lái)對(duì)比。從上圖可以看出與基于A100+InfiniBand的SuperPOD系統(tǒng)相比,基于H100+NVLinkSwitch的SuperPOD系統(tǒng)在對(duì)分帶寬上是前者的9倍。
開放而不是獨(dú)占
其實(shí)NVLink的存在最初讓不少人覺得有些一家獨(dú)大的意思,畢竟最早NVLink僅僅只是用于多個(gè)英偉達(dá)GPU之間的互聯(lián),僅僅只是為自家的產(chǎn)品提供更多優(yōu)勢(shì)而已。而去年發(fā)布的GraceHopperSuperchip同樣用到了這一技術(shù),但這顆芯片卻是英偉達(dá)設(shè)計(jì)的ArmCPU和GPU的互聯(lián)。
這讓人不禁擔(dān)心,如果英偉達(dá)真的成功收購(gòu)了Arm,會(huì)不會(huì)利用這一優(yōu)勢(shì)來(lái)全面壟斷數(shù)據(jù)中心和HPC市場(chǎng)。畢竟Arm自己給出的互聯(lián)方案CMN-700支持的是CCIX 2.0和CXL 2.0這兩大標(biāo)準(zhǔn)互聯(lián)協(xié)議,同時(shí)為第三方加速器提供PCIe5.0的連接。但就紙面參數(shù)給到的性能看來(lái),NVLink這種專用方案似乎更加吃香一些。
不過(guò)Arm作為一家IP公司,目標(biāo)自然是支持到多樣化的加速器,從而全面發(fā)展Arm的生態(tài)。此前Arm在接受電子發(fā)燒友網(wǎng)采訪時(shí)也表示,Arm期待給市場(chǎng)帶來(lái)更多的靈活性,支持更多像Grace這樣的系統(tǒng)。

NVLink-C2C示意圖 / 英偉達(dá)
好在英偉達(dá)似乎也不打算將NVLink-C2C獨(dú)占,而是宣布開放這一技術(shù),支持集成英偉達(dá)技術(shù)的芯片半定制,通過(guò)Chiplet技術(shù)充分利用自家的GPU、DPU、NIC、CPU和SoC產(chǎn)品,與客戶的IP進(jìn)行NVLink-C2C互聯(lián)。
盡管收購(gòu)失敗,英偉達(dá)與Arm的合作并沒(méi)有就此停止,英偉達(dá)也在GTC22上宣布繼續(xù)與Arm緊密合作,以支持并在未來(lái)改進(jìn)Arm的AMBA CHI協(xié)議,加上對(duì)CXL的支持,從而與更多加速器和處理器做到互聯(lián)。
與此同時(shí),在全行業(yè)群策群力,試圖打通生態(tài)的情況下,英偉達(dá)也并不打算將NVLink-C2C作為唯一的可選方案。所以除了NVLink-C2C外,集成了英偉達(dá)芯片的定制SoC也可選用前段時(shí)日公布的UCIe通用Chiplet互聯(lián)標(biāo)準(zhǔn),所以不必將數(shù)據(jù)中心上的CPU、DPU和GPU一整套都換成英偉達(dá)旗下的產(chǎn)品,給到第三方服務(wù)器芯片、DPU和加速器一個(gè)機(jī)會(huì)。不過(guò),考慮到這兩種互聯(lián)方式只能選其一,英偉達(dá)也強(qiáng)調(diào)了NVLink-C2C經(jīng)過(guò)優(yōu)化,擁有更低的延遲、更高的帶寬和更高的能效比,該如何選擇還是看廠商自己的考量了。
-
芯片
+關(guān)注
關(guān)注
450文章
49636瀏覽量
417210 -
互聯(lián)技術(shù)
+關(guān)注
關(guān)注
0文章
13瀏覽量
8319 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3637瀏覽量
89863
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
挑戰(zhàn)英偉達(dá)NVLink!英特爾/谷歌等成立聯(lián)盟,推出UALink 1.0


英偉達(dá)TITAN AI顯卡曝光,性能狂超RTX 4090達(dá)63%!# 英偉達(dá)# 顯卡
鴻海再獲AI領(lǐng)域大單,獨(dú)家供貨英偉達(dá)GB200 NVLink交換器
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
全面解讀英偉達(dá)NVLink技術(shù)

英偉達(dá)發(fā)布最強(qiáng)AI加速卡Blackwell GB200
英偉達(dá)官宣新一代Blackwell架構(gòu),把AI擴(kuò)展到萬(wàn)億參數(shù)
英偉達(dá)AI服務(wù)器NVLink版與PCIe版有何區(qū)別?又如何選擇呢?
英偉達(dá)市值超過(guò)2.3萬(wàn)億美元
英偉達(dá)H200性能怎么樣
全球最小英偉達(dá)GH200服務(wù)器發(fā)布:永擎制造
英偉達(dá)推出為中國(guó)大陸定制的H20 AI GPU芯片
英偉達(dá)和華為/海思主流GPU型號(hào)性能參考

NVLink的演進(jìn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論