 微軟亞洲研究院把Transformer深度提升到1000層
微軟亞洲研究院把Transformer深度提升到1000層
本周論文包括尤洋團隊FastFold上線,訓練時間從11天壓縮至67小時;微軟亞洲研究院直接把 Transformer 深度提升到 1000 層等研究。
目錄
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
Transformer Memory as a Differentiable Search Index
DeepNet: Scaling Transformers to 1,000 Layers
The Quest for a Common Model of the Intelligent Decision Maker
GenéLive! Generating Rhythm Actions in Love Live!
Transformer Quality in Linear Time
FOURCASTNET: A GLOBAL DATA-DRIVEN HIGH-RESOLUTION WEATHER MODEL USING ADAPTIVE FOURIER NEURAL OPERATORS
ArXiv Weekly Radiostation:NLP、CV、ML 更多精選論文(附音頻)
論文 1:FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
作者:Shenggan Cheng, Ruidong Wu, Zhongming Yu, Binrui Li, Xiwen Zhang, Jian Peng, Yang You
論文鏈接:https://arxiv.org/abs/2203.00854
摘要:來自潞晨科技和上海交大的研究者提出了一種蛋白質結構預測模型的高效實現 FastFold。FastFold 包括一系列基于對 AlphaFold 性能全面分析的 GPU 優化。同時,通過動態軸并行和對偶異步算子,FastFold 提高了模型并行擴展的效率,超越了現有的模型并行方法。
實驗結果表明,FastFold 將整體訓練時間從 11 天減少到 67 小時,并實現了 7.5 ~ 9.5 倍的長序列推理加速。此外,研究者還將 FastFold 擴展到 512 個 A100 GPU 的超算集群上,聚合峰值性能達到了 6.02PetaFLOPs,擴展效率達到 90.1%。
不同于一般的 Transformer 模型,AlphaFold 在 GPU 平臺上的計算效率較低,主要面臨兩個挑戰:1) 有限的全局批大小限制了使用數據并行性將訓練擴展到更多節點,更大的批大小會導致準確率更低。即使使用 128 個谷歌 TPUv3 訓練 AlphaFold 也需要約 11 天;2) 巨大的內存消耗超出了當前 GPU 的處理能力。在推理過程中,較長的序列對 GPU 內存的需求要大得多,對于 AlphaFold 模型,一個長序列的推理時間甚至可以達到幾個小時。
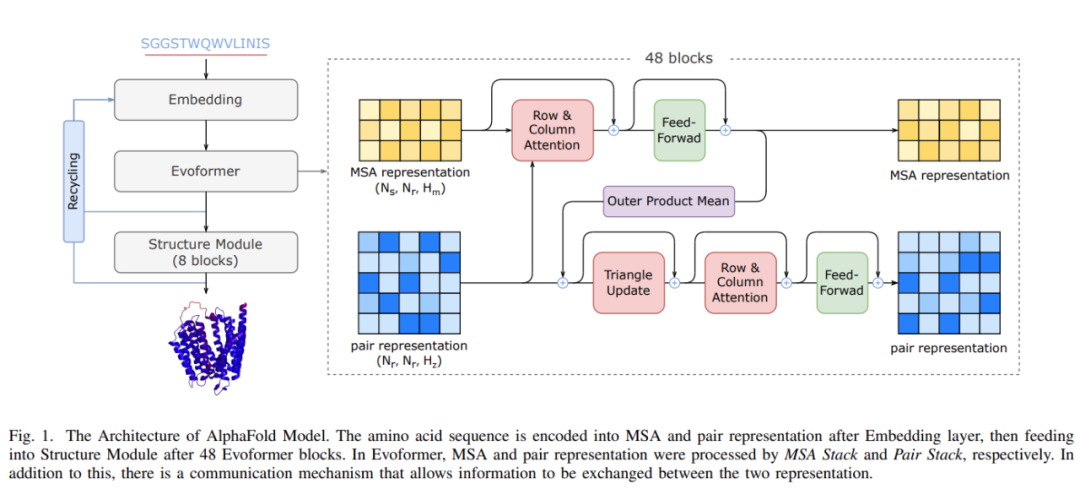
AlphaFold 模型架構
作為首個用于蛋白質結構預測模型訓練和推理的性能優化工作,FastFold 成功引入了大型模型訓練技術,顯著降低了 AlphaFold 模型訓練和推理的時間和經濟成本。FastFold 由 Evoformer 的高性能實現、AlphaFold 的主干結構和一種稱為動態軸并行(Dynamic Axial Parallelism,DAP)的模型并行新策略組成。
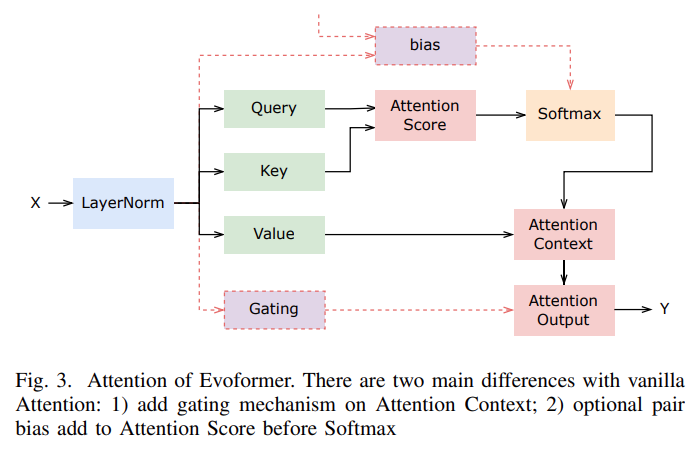
Evoformer 的注意力機制如下圖所示:
推薦:512 塊 A100,AlphaFold 訓練時間從 11 天壓縮至 67 小時:尤洋團隊 FastFold 上線。
論文 2:Transformer Memory as a Differentiable Search Index
作者:Yi Tay 、 Vinh Q. Tran 等
論文鏈接:https://arxiv.org/pdf/2202.06991.pdf
摘要:近日,谷歌研究院在論文《Transformer Memory as a Differentiable Search Index》中提出了一種替代架構,研究者采用序列到序列 (seq2seq) 學習系統。
該研究證明使用單個 Transformer 即可完成信息檢索,其中有關語料庫的所有信息都編碼在模型的參數中。該研究引入了可微搜索索引(Differentiable Search Index,DSI),這是一種學習文本到文本新范式。DSI 模型將字符串查詢直接映射到相關文檔;換句話說,DSI 模型只使用自身參數直接回答查詢,極大地簡化了整個檢索過程。
此外,本文還研究了如何表示文檔及其標識符的變化、訓練過程的變化以及模型和語料庫大小之間的相互作用。實驗表明,在適當的設計選擇下,DSI 明顯優于雙編碼器模型等強大基線,并且 DSI 還具有強大的泛化能力,在零樣本設置中優于 BM25 基線。
DSI 背后的核心思想是在單個神經模型中完全參數化傳統的多階段先檢索后排序 pipeline。為此,DSI 模型必須支持兩種基本操作模式:
索引:DSI 模型應該學會將每個文檔內容 d_j 與其對應的 docid j ( 文檔標識符 :document identifiers,docid)相關聯。本文采用一種簡單的序列到序列方法,將文檔 token 作為輸入并生成標識符作為輸出;
檢索:給定輸入查詢,DSI 模型應返回候選 docid 排序列表。本文是通過自回歸生成實現的。
在這兩個操作之后,DSI 模型可以用來索引文檔語料庫,并對可用的帶標記數據集(查詢和標記文檔)進行微調,然后用于檢索相關文檔 —— 所有這些都在單個、統一的模型中完成。與先檢索后排序方法相反,DSI 模型允許簡單的端到端訓練,并且可以很容易地用作更大、更復雜的神經模型的可微組件。
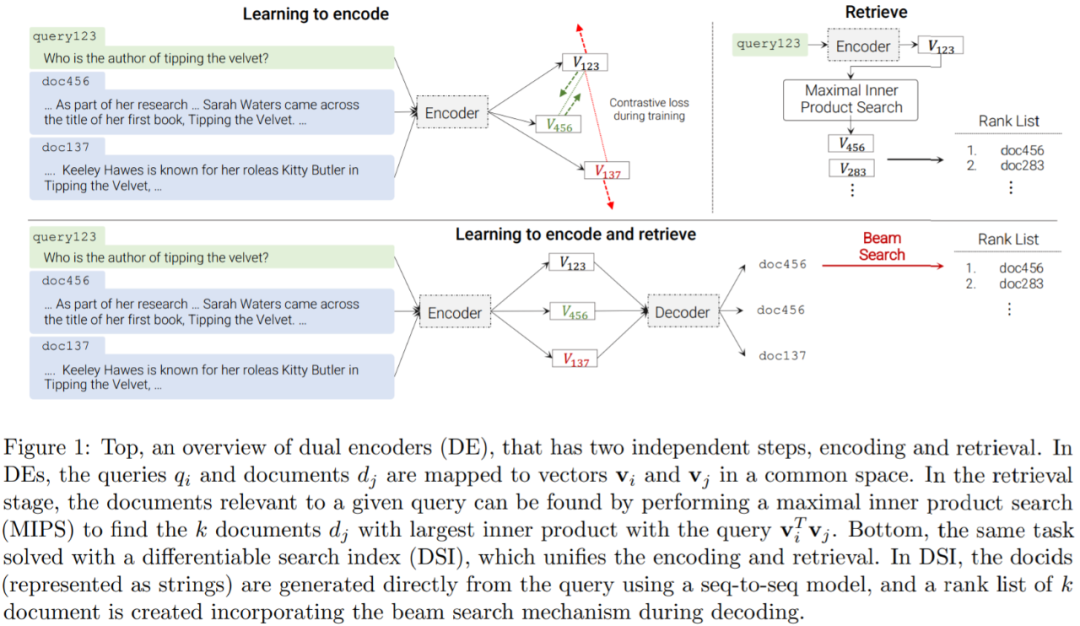
下表為這個進程的偽代碼:

推薦:單個 Transformer 完成信息檢索,谷歌用可微搜索索引打敗雙編碼器模型。
論文 3:DeepNet: Scaling Transformers to 1,000 Layers
作者:Hongyu Wang、Shuming Ma、 Li Dong 、Shaohan Huang 、Dongdong Zhang、 Furu Wei
論文鏈接:https://arxiv.org/pdf/2203.00555.pdf
摘要:微軟亞洲研究院直接把 Transformer 深度提升到 1000 層!
研究者的目標是提升 Transformer 模型的訓練穩定性,并將模型深度進行數量級的擴展。為此,他們研究了不穩定優化的原因,并且發現爆炸式模型更新是造成不穩定的罪魁禍首。基于這些觀察,研究者在殘差連接處引入了一個新的歸一化函數 —— DEEPNORM,它在將模型更新限制為常數時具有理論上的合理性。
這一方法簡單但高效,只需要改變幾行代碼即可。最終,該方法提升了 Transformer 模型的穩定性,并實現了將模型深度擴展到了 1000 多層。
此外,實驗結果表明,DEEPNORM 能夠將 Post-LN 的良好性能和 Pre-LN 的穩定訓練高效結合起來。研究者提出的方法可以成為 Transformers 的首選替代方案,不僅適用于極其深(多于 1000 層)的模型,也適用于現有大規模模型。值得指出的是,在大規模多語言機器翻譯基準上,文中 32 億參數量的 200 層模型(DeepNet)比 120 億參數量的 48 層 SOTA 模型(即 Facebook AI 的 M2M 模型)實現了 5 BLEU 值提升。
如下圖 2 所示,使用 PostLN 實現基于 Transformer 的方法很簡單。與 Post-LN 相比,DEEPNORM 在執行層歸一化之前 up-scale 了殘差連接。
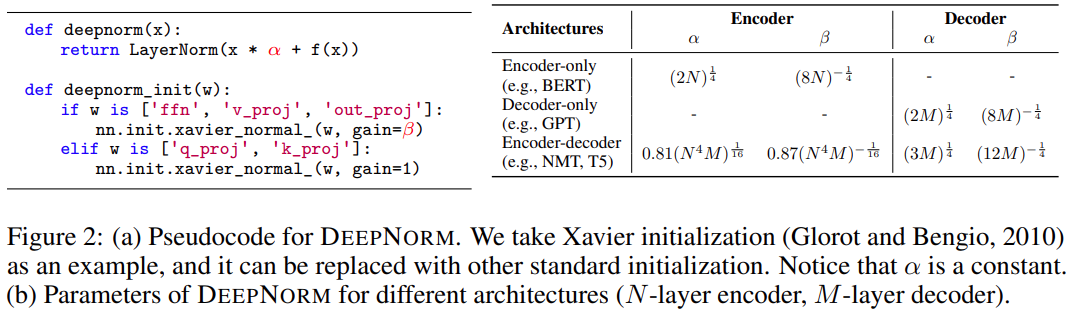
此外,該研究還在初始化期間 down-scale 了參數。值得注意的是,該研究只擴展了前饋網絡的權重,以及注意力層的值投影和輸出投影。此外,殘差連接和初始化的規模取決于圖 2 中不同的架構。
DeepNet 基于 Transformer 架構。與原版 Transformer 相比,DeepNet 在每個子層使用了新方法 DEEPNORM,而不是以往的 Post-LN。
推薦:解決訓練難題,1000 層的 Transformer 來了,訓練代碼很快公開。
論文 4:The Quest for a Common Model of the Intelligent Decision Maker
作者:Richard S. Sutton
論文鏈接:https://arxiv.org/pdf/2202.13252.pdf
摘要:強化學習和決策多學科會議(Multi-Disciplinary Conference on Reinforcement Learning and Decision Making, RLDM)的重要前提是,隨著時間的推移,多個學科對目標導向的決策有著共同的興趣。
近日,阿爾伯塔大學計算機科學系教授、強化學習先驅 Richard S. Sutton 在其最新論文《The Quest for a Common Model of the Intelligent Decision Maker》中通過提出決策者的觀點來加強和深化這一前提,該觀點在心理學、人工智能、經濟學、控制理論和神經科學等領域得到實質和廣泛的應用,他稱之為「智慧智能體的通用模型」。通常模型不包含任何特定于任何有機體、世界或應用域的東西,而涵蓋了決策者與其世界交互的各個方面(必須有輸入、輸出和目標)以及決策者的內部組件(用于感知、決策、內部評估和世界模型)。
Sutton 確定了這些方面和組件,指出它們在不同學科中被賦予不同的名稱,但本質上指向相同的思路。他探討了設計一個可跨學科應用的中性術語面臨的挑戰和帶來的益處,并表示是時候認可并在智慧智能體的實質性通用模型上構建多樣化學科的融合了。
RLDM 的前提是所有對「隨時間推移學習和決策以實現目標」感興趣的學科融合在一起并共享觀點是有價值的。心理學、神經科學等自然科學學科、人工智能、優化控制理論等工程科學學科以及經濟學和人類學等社會科學學科都只部分關注智能決策者。各個學科的觀點不同,但有相通的元素。跨學科的一個目標是確定共同核心,即決策者對所有或許多學科共有的那些方面。只要能夠建立這樣一個決策者的通用模型,就可以促進思想和成果的交流,進展可能會更快,獲得的理解也可能會更加基礎和持久。
探索決策者的通用模型并不新鮮。衡量其當前活力的一個重要指標是 RLDM 和 NeurIPS 等跨學科會議以及《神經計算》、《生物控制論》和《適應行為》等期刊的成功。很多科學洞見可以從跨學科互動中獲得,例如貝葉斯方法在心理學中的廣泛應用、多巴胺在神經科學中的獎勵預測誤差解釋以及在機器學習中長期使用的神經網絡隱喻。盡管很多這些學科之間的重要關系與學科本身一樣古老,但遠遠未解決。為了找到學科之間、甚至一個學科內部之間的共性,人們必須忽略很多分歧。我們必須要有選擇性,從大局出發,不要期望沒有例外發生。
因此,在這篇論文中,Sutton 希望推進對智能決策者模型的探索。首先明確地將探索與富有成效的跨學科互動區分開來;其次強調目標是作為高度跨學科的累積數值信號的最大化;接著又強調了決策者的特定內部結構,即以特定方式交互的四個主要組件,它們為多個學科所共有;最后突出了掩蓋領域之間共性的術語差異,并提供了鼓勵多學科思維的術語。
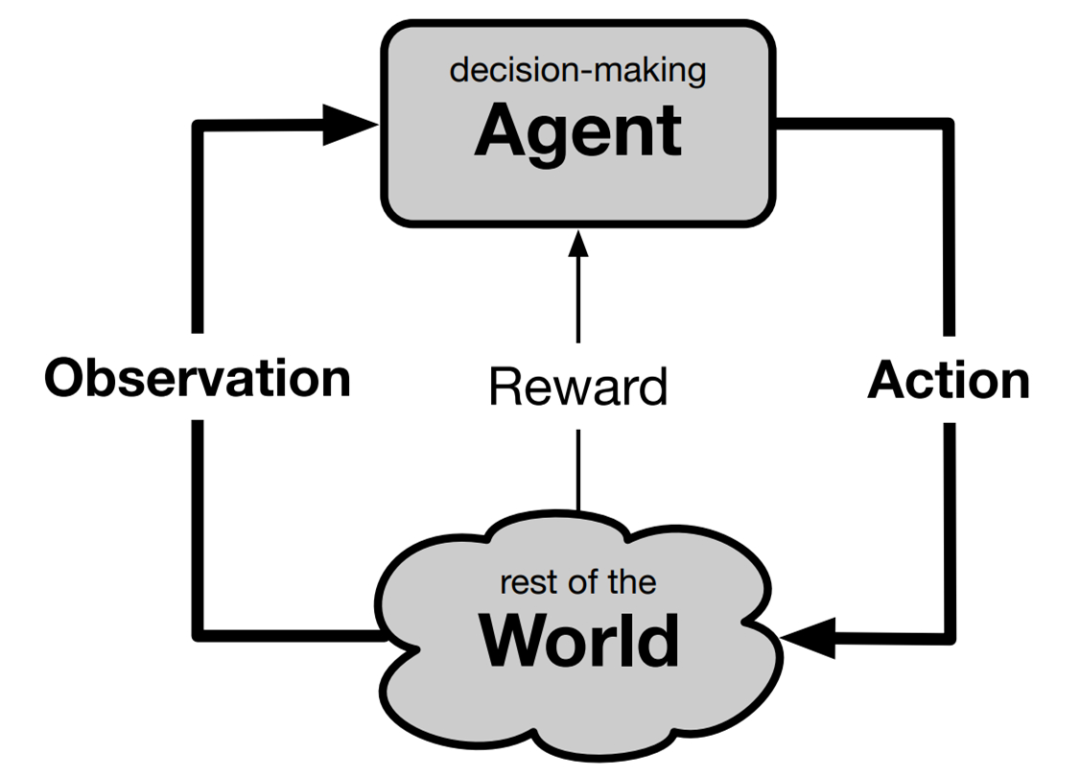
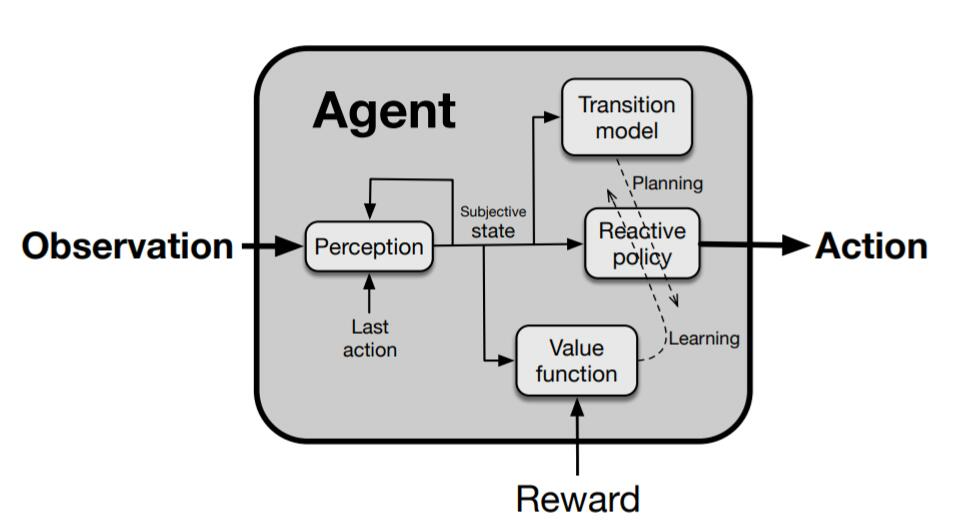
決策智能體標準組件
推薦:強化學習教父 Richard Sutton 新論文探索決策智能體的通用模型:尋找跨學科共性。
論文 5:GenéLive! Generating Rhythm Actions in Love Live!
作者:Atsushi Takada、Daichi Yamazaki、Likun Liu 等
論文鏈接:https://arxiv.org/abs/2202.12823
摘要:最近,預印版論文平臺 arXiv 上的一篇論文引起了人們的注意,其作者來自游戲開發商 KLab 和九州大學。他們提出了一種給偶像歌曲自動寫譜的模型,更重要的是,作者表示這種方法其實已經應用過很長一段時間了。
KLab 等機構提交的論文介紹了自己的節奏動作游戲生成模型。KLab Inc 是一家智能手機游戲開發商。該公司在線運營的節奏動作游戲包括《Love Live!學院偶像季:群星閃耀》(簡稱 LLAS)已以 6 種語言在全球發行,獲得了上千萬用戶。已經有一系列具有類似影響的類似游戲,這使得該工作與大量玩家密切相關。
在研究過程中,開發者們首先提出了 Dance Dance Convolution (DDC) ,生成了具有人類高水平的,較高難度游戲模式的樂譜,但低難度反而效果不好。隨后研究者們通過改進數據集和多尺度 conv-stack 架構,成功捕捉了樂譜中四分音符之間的時間依賴性以及八分音符和提示節拍的位置,它們是音游中放置按鍵的較好時機。
DDC 由兩個子模型組成:onset(生成音符的時機)和 sym(決定音符類型,如輕按或滑動)目前正在使用的 AI 模型在所有難度的曲譜上都獲得了很好的效果,研究人員還展望了該技術擴展到其他領域的可能性。
GenéLive! 的基礎模型由卷積神經網絡 CNN 層和長短期記憶網絡 LSTM 層組成。對于頻域中的信號,作者利用 CNN 層來捕獲頻率特征,對于時域利用 LSTM 層來完成任務。
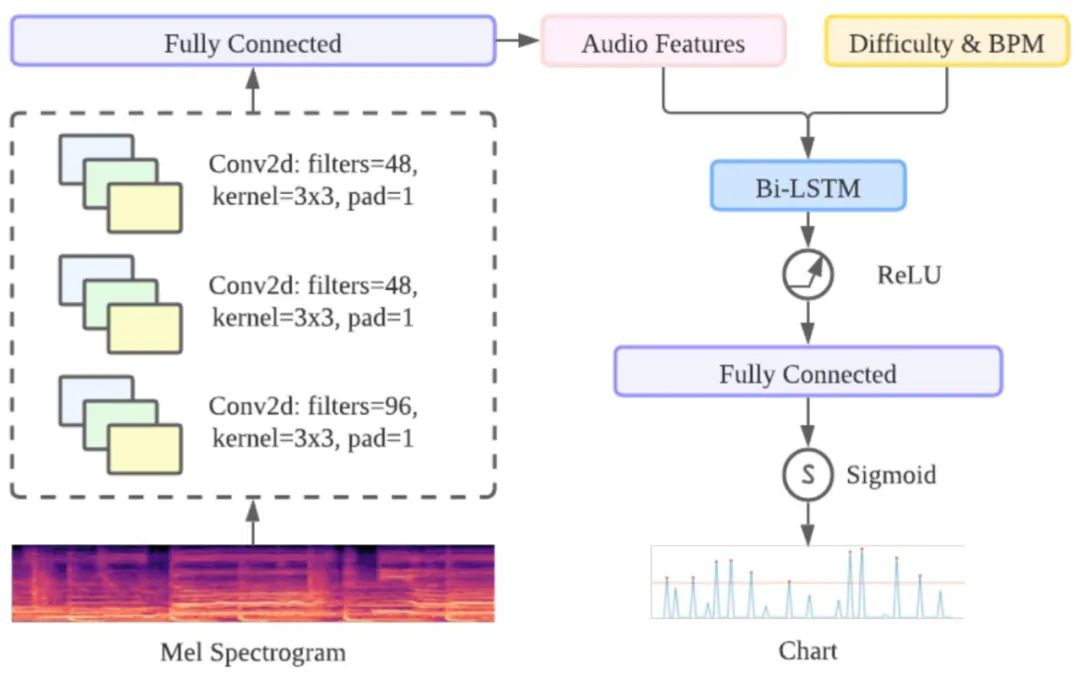
時域方面采用了 BiLSTM,提供前一個 conv-stack 的輸出作為輸入。為了實現不同的難度模式,作者將難度編碼為一個標量(初級是 10,中級是 20,以此類推)并將這個值作為新特征附加到 convstack 的輸出中。
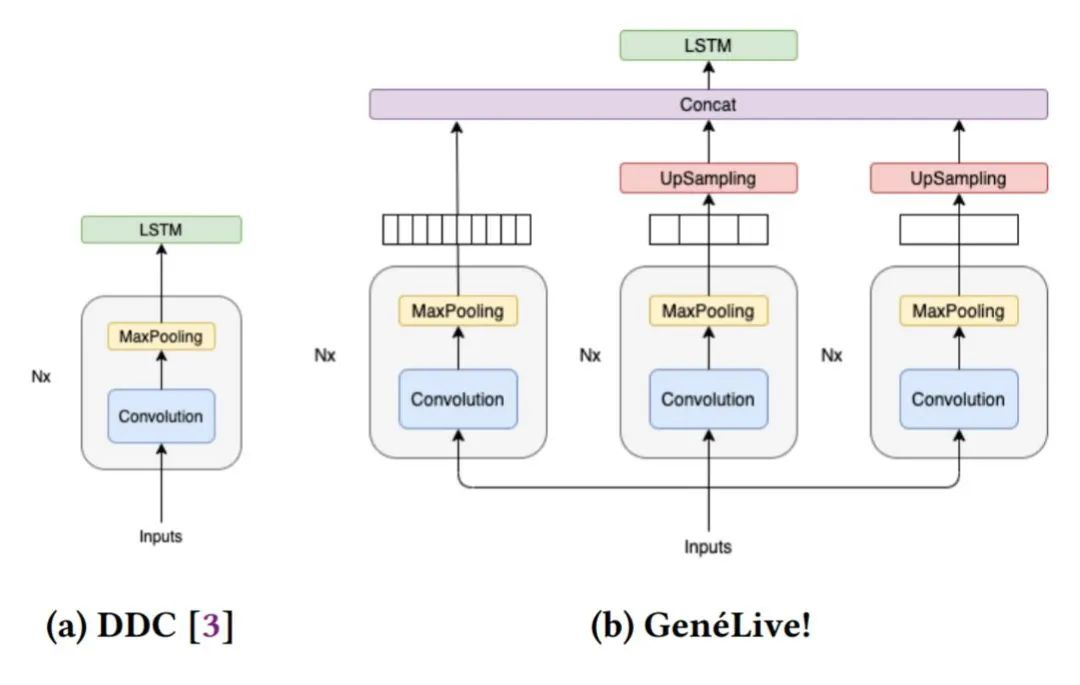
Conv-stack 架構。
該模型是由 KLab 和九州大學合作完成的。兩個團隊之間需要一個基于 Web 的協作平臺來共享源代碼、數據集、模型和實驗等。具體來說,該研究用于模型開發的系統架構如下圖所示。
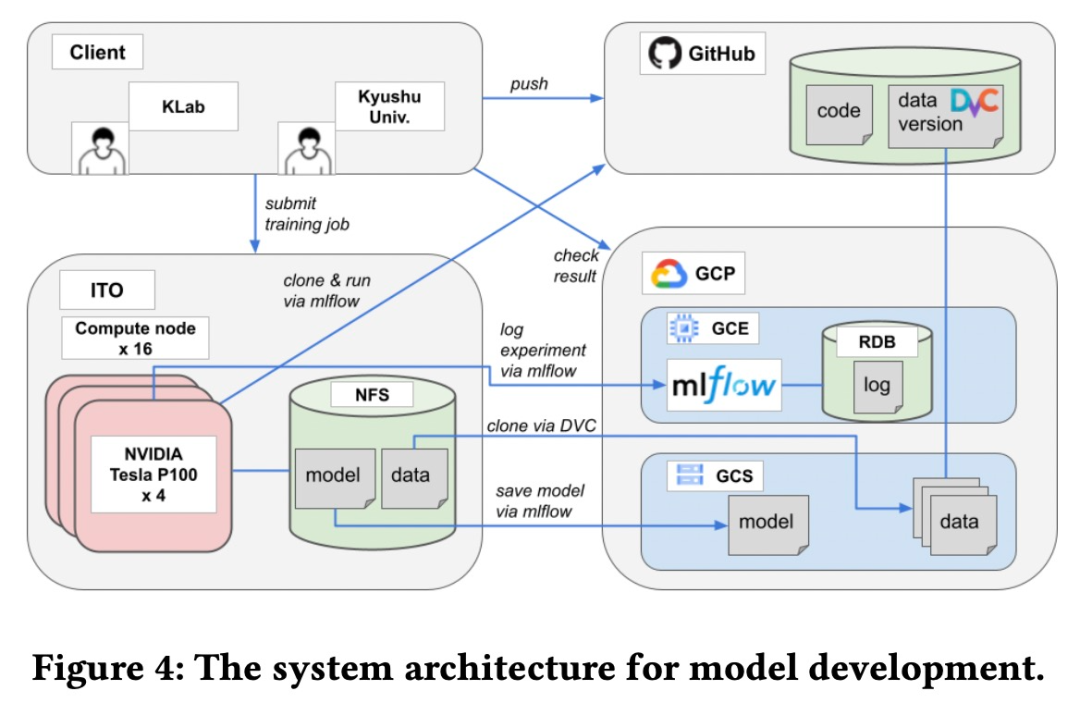
為了使樂譜生成程序可供藝術家按需使用,它應該方便藝術家自行使用而無需 AI 工程師的幫助。并且由于該程序需要高端 GPU,將其安裝在藝術家的本地計算機上并不是一個合適的選擇。該模型服務系統架構如下圖所示。
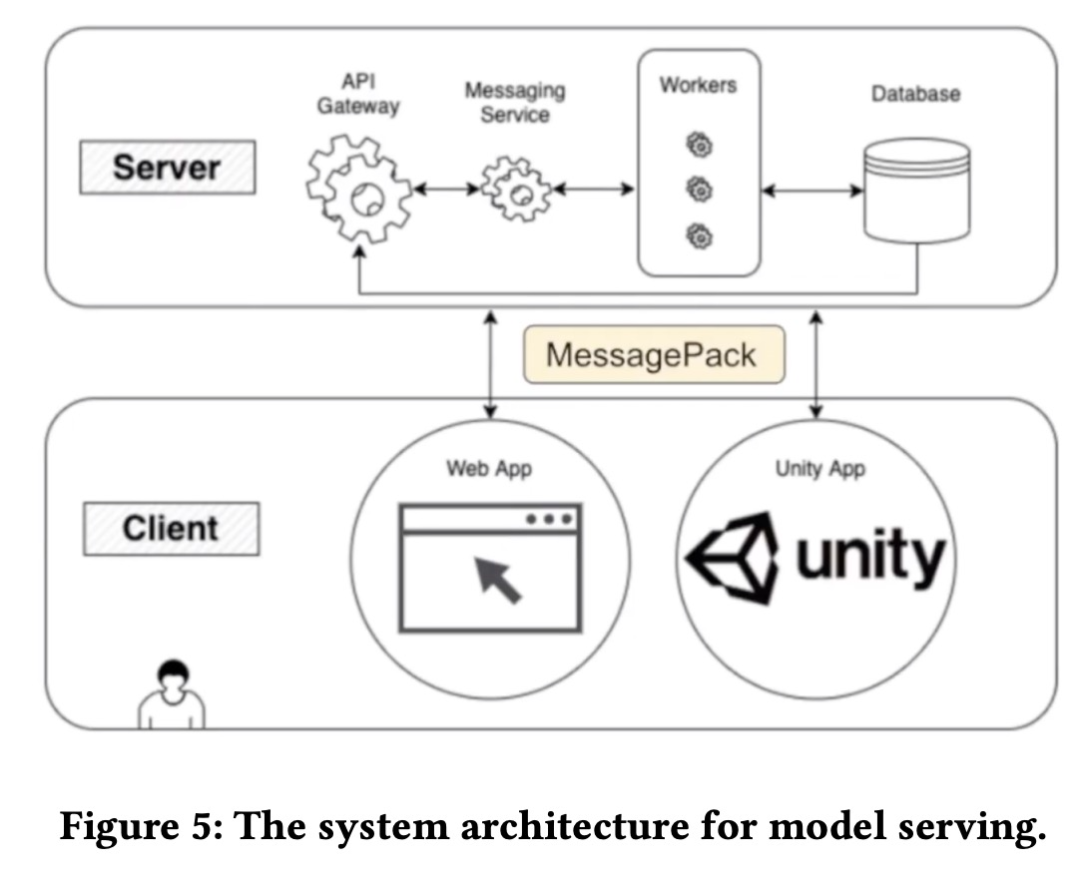
推薦:LoveLive! 出了一篇 AI 論文:生成模型自動寫曲譜。
論文 6:Transformer Quality in Linear Time
作者:Weizhe Hua、Zihang Dai、Hanxiao Liu、Quoc V. Le
論文鏈接:https://arxiv.org/abs/2202.10447
摘要:來自康奈爾大學、谷歌大腦的研究人員近日提出了一個新模型 FLASH(Fast Linear Attention with a Single Head),首次不僅在質量上與完全增強的 Transformer 相當,而且在現代加速器的上下文大小上真正享有線性可擴展性。與旨在逼近 Transformers 中的多頭自注意力 (MHSA) 的現有高效注意力方法不同,谷歌從一個新層設計開始,自然地實現更高質量的逼近。FLASH 分兩步開發:
首先設置一個更適合有效近似的新層,引入門控機制來減輕自注意力的負擔,產生了下圖 2 中的門控注意力單元 (Gated Attention Unit, GAU)。與 Transformer 層相比,每個 GAU 層更便宜。更重要的是,它的質量更少依賴于注意力精度。事實上,小單頭、無 softmax 注意力的 GAU 與 Transformers 性能相近。
隨后作者提出了一種有效的方法來逼近 GAU 中的二次注意力,從而導致在上下文大小上具有線性復雜度的層變體。其思路是首先將標記分組為塊,然后在一個塊內使用精確的二次注意力和跨塊的快速線性注意力(如下圖 4 所示)。在論文中,研究者進一步描述了如何利用此方法自然地推導出一個高效的加速器實現,在實踐中做到只需更改幾行代碼的線性可擴展能力。
在大量實驗中,FLASH 在各種任務、數據集和模型尺度上均效果很好。FLASH 在質量上與完全增強的 Transformer (Transformer++) 相比具有競爭力,涵蓋了各種實踐場景的上下文大小 (512-8K),同時在現代硬件加速器上實現了線性可擴展。
例如,在質量相當的情況下,FLASH 在 Wiki-40B 上的語言建模實現了 1.2 倍至 4.9 倍的加速,在 Transformer++ 上 C4 上的掩碼語言建模實現了 1.0 倍至 4.8 倍的加速。在進一步擴展到 PG-19 (Rae et al., 2019) 之后,FLASH 將 Transformer++ 的訓練成本降低了 12.1 倍,并實現了質量的顯著提升。
研究者首先提出了門控注意力單元(Gated Attention Unit, GAU),這是一個比 Transformers 更簡單但更強的層。
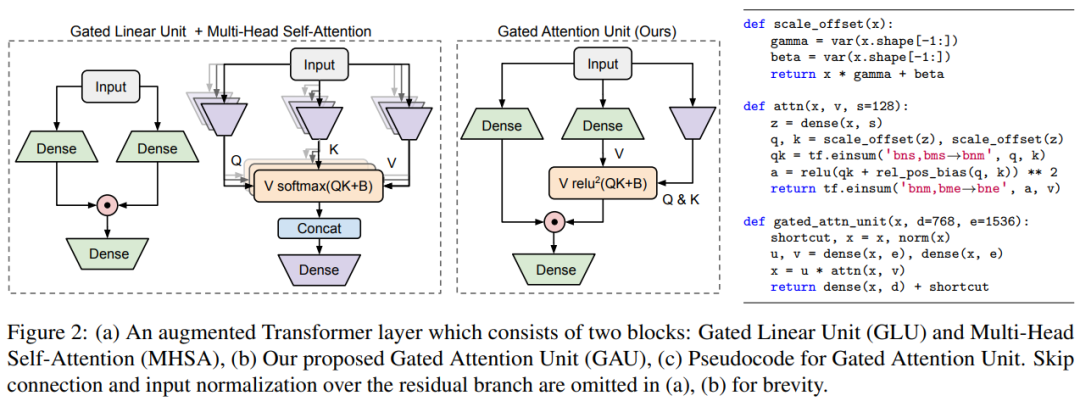
研究者在下圖 3 中展示了 GAU 與 Transformers 的比較情況,結果顯示對于不同模型大小,GAU 在 TPUs 上的性能可與 Transformers 競爭。需要注意,這些實驗是在相對較短的上下文大小(512)上進行的。

推薦:谷歌 Quoc Le 團隊新 transformer:線性可擴展,訓練成本僅有原版 1/12。
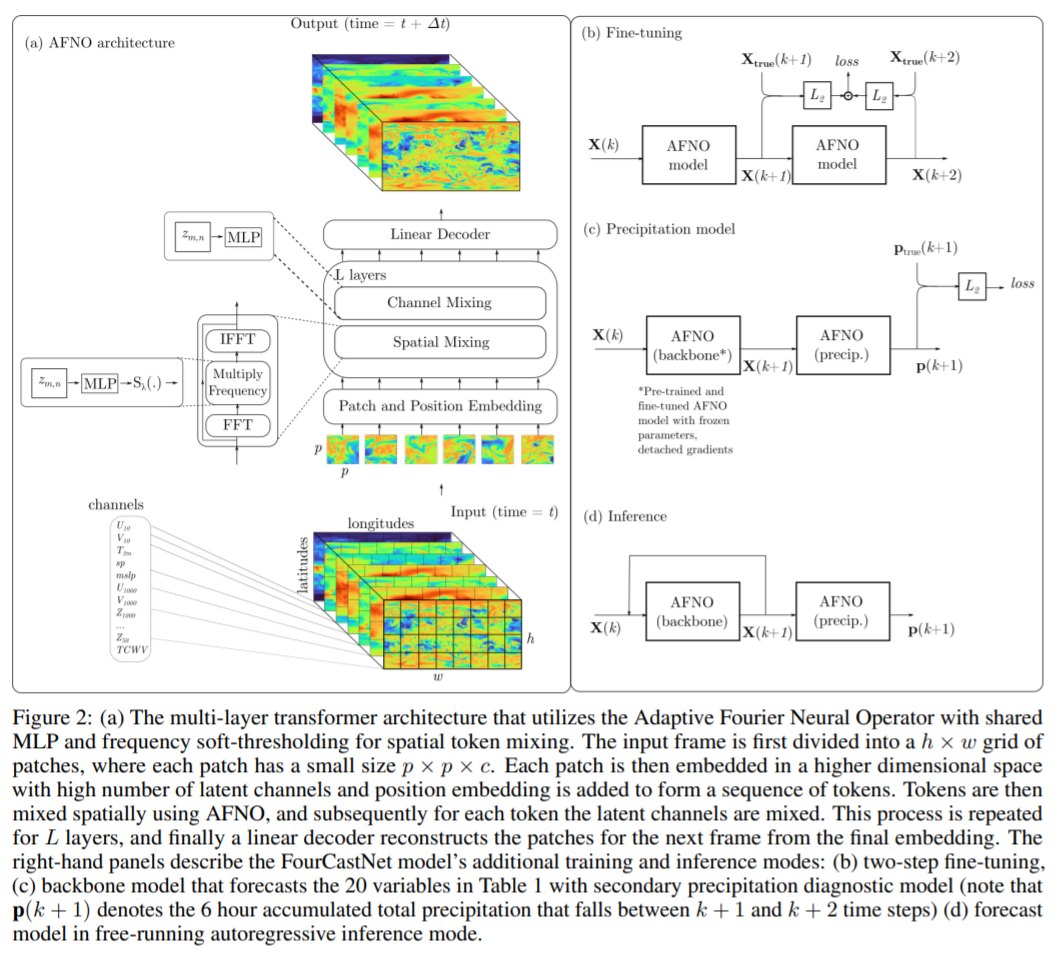
論文 7:FOURCASTNET: A GLOBAL DATA-DRIVEN HIGH-RESOLUTION WEATHER MODEL USING ADAPTIVE FOURIER NEURAL OPERATORS
作者:Jaideep Pathak 、 Shashank Subramanian 等
論文鏈接:https://arxiv.org/pdf/2202.11214.pdf
摘要:在近日的一篇論文中,英偉達、勞倫斯伯克利國家實驗室、密歇根大學安娜堡分校、萊斯大學等機構的研究者開發了一種基于傅里葉的神經網絡預測模型 FourCastNet,它能以 0.25° 的分辨率生成關鍵天氣變量的全球數據驅動預測,相當于赤道附近大約 30×30 km 的空間分辨率和 720×1440 像素的全球網格大小。這使得我們首次能夠與歐洲中期天氣預報中心(ECMWF)的高分辨率綜合預測系統(IFS)模型進行直接比較。
FourCastNet 在節點小時(node-hour)基礎上比傳統 NWP 模型快約 45,000 倍。FourCastNet 這種數量級的加速以及在高分辨率下前所未有的準確性,使得它能夠以很低的成本生成超大規模集合預測。FourCastNet 極大地改善了概率天氣預報的效果,使用它可以在幾秒鐘內生成對颶風、大氣層河流和極端降水等事件的大規模集合預報,從而可以實現更及時、更明智的災難響應。
此外,FourCastNet 對近地表風速的可靠、快速和低廉預測可以改善陸海風電場的風能資源規劃。訓練 FourCastNet 所需的能量大約等于使用 IFS 模型生成 10 天預測所需的能量(50 個成員)。然而,一旦經過訓練,FourCastNet 生成預測所需的能量比 IFS 模型少 12,000 倍。研究者希望 FourCastNet 只訓練一次,并且后續微調的能耗可以忽略不計。
在實現技術上,FourCastNet 使用基于傅里葉變換的 token 混合方法 [Guibas et al., 2022] 和 ViT 骨干 [Dosovitskiy et al., 2021]。這一方法基于最近的的傅里葉神經算子,該算子以分辨率不變的方式學習,并在建模流體動力學等具有挑戰性的偏微分方程中取得了成功。此外,他們選擇 ViT 骨干的原因是它能夠很好地建模長程依賴。ViT 和基于傅里葉的 token 方法混合生成了 SOTA 高分辨率模型,它可以解析細粒度的特征,并能夠很好地隨分辨率和數據集大小擴展。研究者表示,這一方法能夠以真正前所未有的高分辨率訓練高保真數據驅動的模型。
歐洲中期天氣預報中心(ECMWF)提供了一個公開可用的綜合數據集 ERA5,該研究使用 ERA5 來訓練 FourCastNet。他們專注于兩個大氣變量,即(1)距離地球表面 10m 處的風速和(2)6 小時總降水量,除此以外,該研究還預測了其他幾個變量,包括幾個不同垂直高度的位勢高度、溫度、風速和相對濕度,一些近地表變量,如地面氣壓和平均海平面氣壓以等。
整個訓練過程是在 64 個 Nvidia A100 GPU 的集群上完成,端到端訓練大約需要 16 小時。
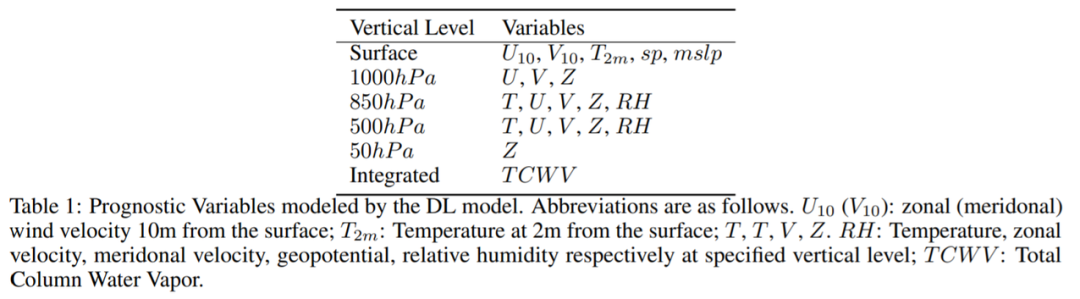
該研究選擇了一些變量(表 1)來表示大氣的瞬時狀態:
推薦:速度提升 45000 倍,英偉達用傅里葉模型實現前所未有天氣預報準確率。
原文標題:7 Papers & Radios | 尤洋團隊FastFold上線;1000層的Transformer來了
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
微軟
+關注
關注
4文章
6572瀏覽量
103963 -
gpu
+關注
關注
28文章
4703瀏覽量
128725 -
模型
+關注
關注
1文章
3178瀏覽量
48730
原文標題:7 Papers & Radios | 尤洋團隊FastFold上線;1000層的Transformer來了
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人工智能方向在哪里?看微軟亞洲研究院四任院長的建言

西安某500強研究院招聘
中馬研究院正式掛牌成立
Excel被提升到了非常重要的地位
英特爾研究院與聯想研究院簽署研究院合作框架協議
微軟將在上海設立微軟亞洲研究院
微軟亞洲研究院被譽為AI黃埔軍校,覆蓋了國內高科技領導的半壁江山
微軟亞洲研究院"創新匯": AI為數字化轉型注入動能
微軟亞洲研究院開發出了一種超級鳳凰人工智能系統
微軟亞洲研究院的研究員們提出了一種模型壓縮的新思路
無線及移動網絡領域專家邱鋰力加入微軟亞洲研究院
微軟亞洲研究院否認撤離中國,但確認部分 AI 科學家將遷至溫哥華
科學匠人 | 邊江:在研究院的七年“技癢”,探尋大模型助力AI與產業融合之道






 工商網監
工商網監
評論