") NVIDIA Sionna:一個(gè)GPU加速的開源庫
NVIDIA Sionna:一個(gè)GPU加速的開源庫
即使 5G 無線網(wǎng)絡(luò)正在全球范圍內(nèi)安裝和使用,學(xué)術(shù)界和工業(yè)界的研究人員已經(jīng)開始為 6G 定義 愿景和關(guān)鍵技術(shù) 。雖然沒有人知道 6G 將是什么,但一個(gè)反復(fù)出現(xiàn)的愿景是, 6G 必須能夠以前所未有的規(guī)模創(chuàng)建數(shù)字雙胞胎和分布式機(jī)器學(xué)習(xí)( ML )應(yīng)用程序。 6G 研究需要新的工具。
支撐 6G 愿景的一些關(guān)鍵技術(shù)是被稱為太赫茲波段的高頻通信。在這個(gè)波段,更多的光譜是按數(shù)量級(jí)提供的。技術(shù)示例包括:
- 可重構(gòu)智能表面( RIS ),用于控制電磁波的反射方式并實(shí)現(xiàn)最佳覆蓋。
- 集成傳感和通信( ISAC )將 6G 網(wǎng)絡(luò)轉(zhuǎn)化為傳感器,為自動(dòng)駕駛汽車、道路安全、機(jī)器人和物流提供了許多令人興奮的應(yīng)用。
機(jī)器學(xué)習(xí)有望在整個(gè) 6G 協(xié)議棧中發(fā)揮決定性作用,這可能會(huì)徹底改變我們?cè)O(shè)計(jì)和標(biāo)準(zhǔn)化通信系統(tǒng)的方式。
應(yīng)對(duì)這些革命性技術(shù)的研究挑戰(zhàn)需要新一代工具來實(shí)現(xiàn)突破,這些突破將定義 6G 時(shí)代的通信。原因如下:
- 許多 6G 技術(shù)需要模擬特定環(huán)境,例如工廠或小區(qū),物理位置、無線信道脈沖響應(yīng)和視覺輸入之間具有空間一致性的對(duì)應(yīng)關(guān)系。目前,這只能通過昂貴的測量活動(dòng)或基于場景渲染和光線跟蹤組合的高效模擬來實(shí)現(xiàn)。
- 隨著機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)變得越來越重要,研究人員將從帶有本地 ML 集成和自動(dòng)梯度計(jì)算的鏈接級(jí)模擬器中受益匪淺。
- 6G 仿真需要前所未有的建模精度和規(guī)模。 ML 增強(qiáng)算法的全部潛力只能通過基于物理的模擬來實(shí)現(xiàn),這些模擬以過去不可能的細(xì)節(jié)水平來解釋現(xiàn)實(shí)。
介紹 NVIDIA Sionna
為了滿足這些需求, NVIDIA 開發(fā)了 Sionna ,這是一個(gè) GPU 加速的開源庫,用于鏈路級(jí)模擬。
Sionna 能夠快速原型化復(fù)雜的通信系統(tǒng)架構(gòu)。這是世界上第一個(gè)能夠在物理層使用神經(jīng)網(wǎng)絡(luò)的框架,并且不需要為數(shù)據(jù)生成、培訓(xùn)和性能評(píng)估使用單獨(dú)的工具鏈。
Sionna 實(shí)施了一系列經(jīng)過仔細(xì)測試的最先進(jìn)算法,可用于基準(zhǔn)測試和端到端性能評(píng)估。這可以讓你專注于你的研究,使它更具影響力和可復(fù)制性,同時(shí)你花更少的時(shí)間實(shí)現(xiàn)你專業(yè)領(lǐng)域之外的組件。
Sionna 是用 Python 寫成的,基于 TensorFlow 和 Keras 。所有組件都以 Keras 層的形式實(shí)現(xiàn),這使您可以通過與構(gòu)建神經(jīng)網(wǎng)絡(luò)相同的方式連接所需的層來構(gòu)建復(fù)雜的系統(tǒng)架構(gòu)。
除了少數(shù)例外,所有組件都是可微的,因此梯度可以在整個(gè)系統(tǒng)中反向傳播。這是系統(tǒng)優(yōu)化和機(jī)器學(xué)習(xí)的關(guān)鍵因素,尤其是神經(jīng)網(wǎng)絡(luò)的集成。
NVIDIA GPU acceleration 提供了幾個(gè)數(shù)量級(jí)的更快模擬,并可擴(kuò)展到大型多 GPU 設(shè)置,從而實(shí)現(xiàn)此類系統(tǒng)的交互式探索。如果沒有 GPU 可用,那么 Sionna 甚至可以在 CPU 上運(yùn)行,盡管速度較慢。
Sionna 提供了豐富的 documentation 和一系列教程,使其易于入門。
Sinna 的第一個(gè)版本具有以下主要功能:
- 5G LDPC 、 5G 極性碼和卷積碼、速率匹配、 CRC 、交織器、擾碼器
- 各種解碼器: BP 變體、 SC 、 SCL 、 SCL-CRC 、維特比
- QAM 和定制調(diào)制方案
- 3GPP 38.901 信道模型( TDL 、 CDL 、 RMa 、 UMa 、 Umi )、瑞利、 AWGN
- 正交頻分復(fù)用
- MIMO 信道估計(jì)、均衡和預(yù)編碼
Sionna 是根據(jù) Apache 2.0 許可證發(fā)布的,我們歡迎外部各方的貢獻(xiàn)。
你好,Sionna!
下面的代碼示例顯示了一個(gè)“你好,世界!”模擬使用 16QAM 調(diào)制在 AWGN 信道上傳輸一批 LDPC 碼字的示例。本例顯示了如何實(shí)例化 Sionna 層,并將其應(yīng)用于先前定義的張量。編碼風(fēng)格遵循 Keras 的 functional API 。您可以在 Google Collaboratory 上的 Jupyter notebook 中直接打開此示例。
batch_size = 1024 n = 1000 # codeword length k = 500 # information bits per codeword m = 4 # bits per symbol snr = 10 # signal-to-noise ratio c = Constellation("qam",m,trainable=True) b = BinarySource()([batch_size, k]) u = LDPC5GEncoder (k,n)(b) x = Mapper (constellation=c)(u) y = AWGN()([x,1/snr]) 11r = Demapper("app", constellation=c)([y,1/snr]) b_hat = LDPC5GDecoder(LDPC5GEncoder (k, n))(11r)
Sionna 的一個(gè)關(guān)鍵優(yōu)勢是,組件可以進(jìn)行訓(xùn)練或由神經(jīng)網(wǎng)絡(luò)代替。 NVIDIA 使Constellation可訓(xùn)練,并用NeuralDemapper取代Demapper,后者只是通過 Keras 定義的神經(jīng)網(wǎng)絡(luò)。
c = Constellation("qam",m,trainable=True) b = BinarySource()([batch_size, k]) u = LDPC5GEncoder (k,n)(b) x = Mapper (constellation=c)(u) y = AWGN()([x,1/snr]) 11r = NeuralDemapper()([y,1/snr]) b_hat = LDPC5GDecoder(LDPC5GEncoder (k, n))(11r)
在這種情況下,定義星座點(diǎn)的張量現(xiàn)在變成了一個(gè)可訓(xùn)練的 TensorFlow 變量,可以通過 TensorFlow 自動(dòng)微分功能與NeuralDemapper的權(quán)重一起跟蹤。由于這些原因, SIONA 可以被視為一個(gè)可微鏈路級(jí)模擬器。
展望未來
很快, Sionna 將允許集成光線跟蹤來取代隨機(jī)通道模型,從而實(shí)現(xiàn)許多新的研究領(lǐng)域。超快射線追蹤是通信系統(tǒng)數(shù)字孿生的關(guān)鍵技術(shù)。例如,這使得建筑物的架構(gòu)和通信基礎(chǔ)設(shè)施的共同設(shè)計(jì)能夠?qū)崿F(xiàn)前所未有的吞吐量和可靠性。
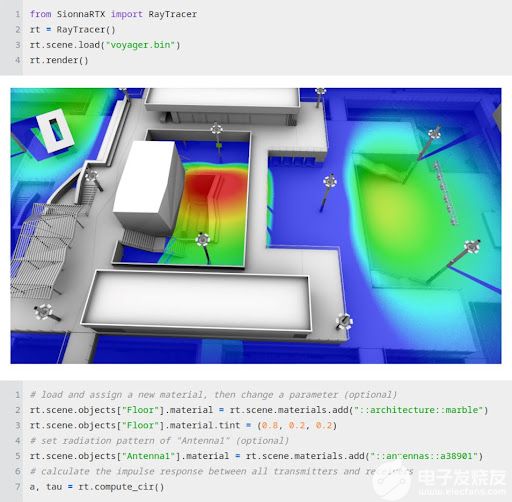
圖 3 。從 Jupyter 筆記本電腦中訪問硬件加速光線跟蹤功能
Sionna 利用計(jì)算( NVIDIA CUDA 核)、 AI ( NVIDIA 張量核)和 NVIDIA GPU 的光線跟蹤核對(duì) 6G 系統(tǒng)進(jìn)行閃電般的模擬。
我們希望你們能分享我們對(duì) Sionna 的興奮,我們期待著聽到你們的成功故事!
- Sionna 產(chǎn)品頁面
- Sionna documentation
- nvlabs/sionna GitHub 回購
-
通信
+關(guān)注
關(guān)注
18文章
5977瀏覽量
135871 -
NVIDIA
+關(guān)注
關(guān)注
14文章
4949瀏覽量
102826 -
gpu
+關(guān)注
關(guān)注
28文章
4703瀏覽量
128725
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA CUDA深度神經(jīng)網(wǎng)絡(luò)庫實(shí)現(xiàn)高性能GPU加速
OpenHarmony開源GPU庫Mesa3D適配說明
NVIDIA火熱招聘GPU高性能計(jì)算架構(gòu)師
NVIDIA-SMI:監(jiān)控GPU的絕佳起點(diǎn)
購買哪款Nvidia GPU
Nvidia GPU風(fēng)扇和電源顯示ERR怎么解決
在Ubuntu上使用Nvidia GPU訓(xùn)練模型
NVIDIA深度神經(jīng)網(wǎng)絡(luò)加速庫cuDNN軟件安裝教程
NVIDIA宣布一套用于構(gòu)建GPU加速ARM服務(wù)器的參考設(shè)計(jì)
NVIDIA推出適用于Python的VPF,簡化開發(fā)GPU加速視頻編碼/解碼
NVIDIA GPU加速計(jì)算之路
Nvidia宣布推出了一套新的開源RAPIDS庫
使用NVIDIA數(shù)學(xué)庫加速GPU應(yīng)用程序
177倍加速!NVIDIA最新開源 | GPU加速各種SDF建圖!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論