 緩存使用中常見問題和解決方案
緩存使用中常見問題和解決方案
原始數據存儲在 DB 中(如 MySQL、Hbase 等),但 DB 的讀寫性能低、延遲高。
比如 MySQL 在 4 核 8G 上的 TPS = 5000,QPS = 10000 左右,讀寫平均耗時 10~100 ms。
用 Redis 作為緩存系統正好可以彌補 DB 的不足,「碼哥」在自己的 MacBook Pro 2019 上執行 Redis 性能測試如下:
$redis-benchmark-tset,get-n100000-q SET:107758.62requestspersecond,p50=0.239msec GET:108813.92requestspersecond,p50=0.239msec
TPS 和 QPS 達到 10 萬,于是乎我們就引入緩存架構,在數據庫中存儲原始數據,同時在緩存總存儲一份。
當請求進來的時候,先從緩存中取數據,如果有則直接返回緩存中的數據。
如果緩存中沒數據,就去數據庫中讀取數據并寫到緩存中,再返回結果。
這樣就天衣無縫了么?緩存的設計不當,將會導致嚴重后果,本文將介紹緩存使用中常見的三個問題和解決方案:
緩存擊穿(失效);
緩存穿透;
緩存雪崩。
緩存擊穿(失效)
高并發流量,訪問的這個數據是熱點數據,請求的數據在 DB 中存在,但是 Redis 存的那一份已經過期,后端需要從 DB 從加載數據并寫到 Redis。
關鍵字:單一熱點數據、高并發、數據失效
但是由于高并發,可能會把 DB 壓垮,導致服務不可用。如下圖所示:
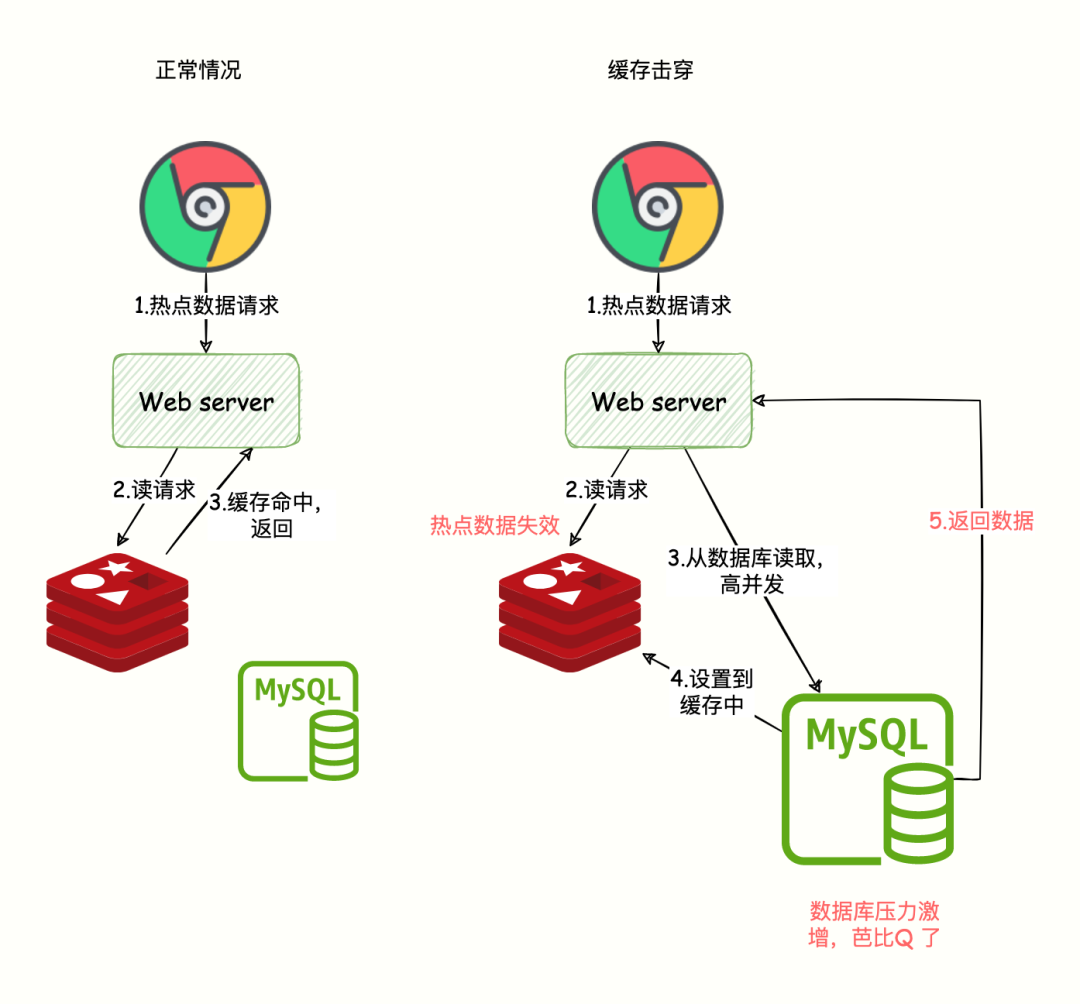 緩存擊穿
緩存擊穿
解決方案
過期時間 + 隨機值
對于熱點數據,我們不設置過期時間,這樣就可以把請求都放在緩存中處理,充分把 Redis 高吞吐量性能利用起來。
或者過期時間再加一個隨機值。
設計緩存的過期時間時,使用公式:過期時間=baes 時間+隨機時間。
即相同業務數據寫緩存時,在基礎過期時間之上,再加一個隨機的過期時間,讓數據在未來一段時間內慢慢過期,避免瞬時全部過期,對 DB 造成過大壓力
預熱
預先把熱門數據提前存入 Redis 中,并設熱門數據的過期時間超大值。
使用鎖
當發現緩存失效的時候,不是立即從數據庫加載數據。
而是先獲取分布式鎖,獲取鎖成功才執行數據庫查詢和寫數據到緩存的操作,獲取鎖失敗,則說明當前有線程在執行數據庫查詢操作,當前線程睡眠一段時間在重試。
這樣只讓一個請求去數據庫讀取數據。
偽代碼如下:
publicObjectgetData(Stringid){ Stringdesc=redis.get(id); //緩存為空,過期了 if(desc==null){ //互斥鎖,只有一個請求可以成功 if(redis(lockName)){ try //從數據庫取出數據 desc=getFromDB(id); //寫到Redis redis.set(id,desc,60*60*24); }catch(Exceptionex){ LogHelper.error(ex); }finally{ //確保最后刪除,釋放鎖 redis.del(lockName); returndesc; } }else{ //否則睡眠200ms,接著獲取鎖 Thread.sleep(200); returngetData(id); } } }
緩存穿透
緩存穿透:意味著有特殊請求在查詢一個不存在的數據,即數據不存在 Redis 也不存在于數據庫。
導致每次請求都會穿透到數據庫,緩存成了擺設,對數據庫產生很大壓力從而影響正常服務。
如圖所示:
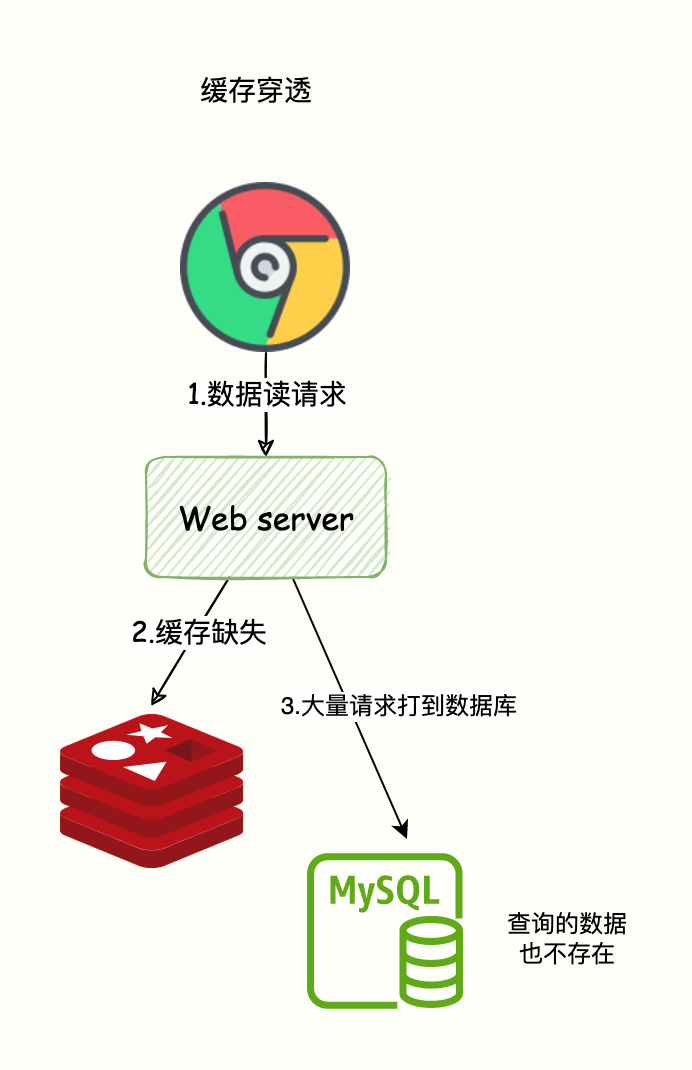 緩存穿透
緩存穿透
解決方案
緩存空值:當請求的數據不存在 Redis 也不存在數據庫的時候,設置一個缺省值(比如:None)。當后續再次進行查詢則直接返回空值或者缺省值。
布隆過濾器:在數據寫入數據庫的同時將這個 ID 同步到到布隆過濾器中,當請求的 id 不存在布隆過濾器中則說明該請求查詢的數據一定沒有在數據庫中保存,就不要去數據庫查詢了。
BloomFilter 要緩存全量的 key,這就要求全量的 key 數量不大,10 億 條數據以內最佳,因為 10 億 條數據大概要占用 1.2GB 的內存。
“
說下布隆過濾器的原理吧
”
BloomFilter 的算法是,首先分配一塊內存空間做 bit 數組,數組的 bit 位初始值全部設為 0。
加入元素時,采用 k 個相互獨立的 Hash 函數計算,然后將元素 Hash 映射的 K 個位置全部設置為 1。
檢測 key 是否存在,仍然用這 k 個 Hash 函數計算出 k 個位置,如果位置全部為 1,則表明 key 存在,否則不存在。
如下圖所示:
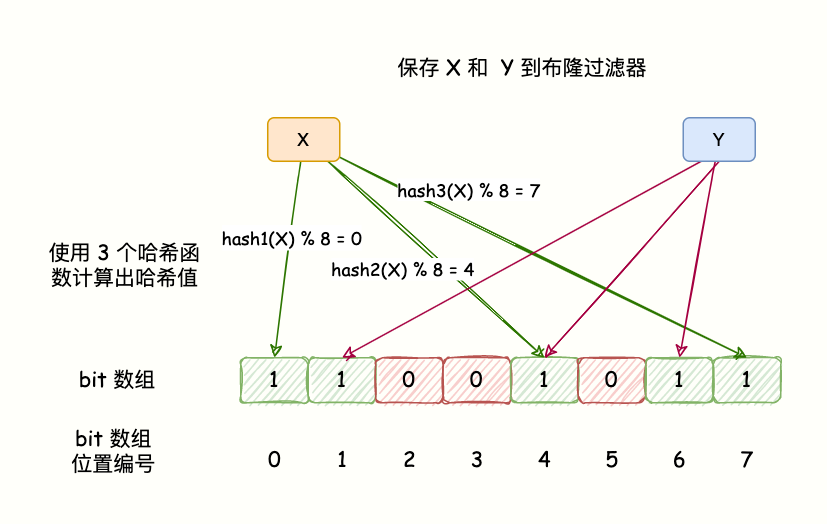 布隆過濾器
布隆過濾器
哈希函數會出現碰撞,所以布隆過濾器會存在誤判。
這里的誤判率是指,BloomFilter 判斷某個 key 存在,但它實際不存在的概率,因為它存的是 key 的 Hash 值,而非 key 的值。
所以有概率存在這樣的 key,它們內容不同,但多次 Hash 后的 Hash 值都相同。
對于 BloomFilter 判斷不存在的 key ,則是 100% 不存在的,反證法,如果這個 key 存在,那它每次 Hash 后對應的 Hash 值位置肯定是 1,而不會是 0。布隆過濾器判斷存在不一定真的存在。
緩存雪崩
緩存雪崩指的是大量的請求無法在 Redis 緩存系統中處理,請求全部打到數據庫,導致數據庫壓力激增,甚至宕機。
出現該原因主要有兩種:
大量熱點數據同時過期,導致大量請求需要查詢數據庫并寫到緩存;
Redis 故障宕機,緩存系統異常。
緩存大量數據同時過期
數據保存在緩存系統并設置了過期時間,但是由于在同時一刻,大量數據同時過期。
系統就把請求全部打到數據庫獲取數據,并發量大的話就會導致數據庫壓力激增。
緩存雪崩是發生在大量數據同時失效的場景,而緩存擊穿(失效)是在某個熱點數據失效的場景,這是他們最大的區別。
如下圖:
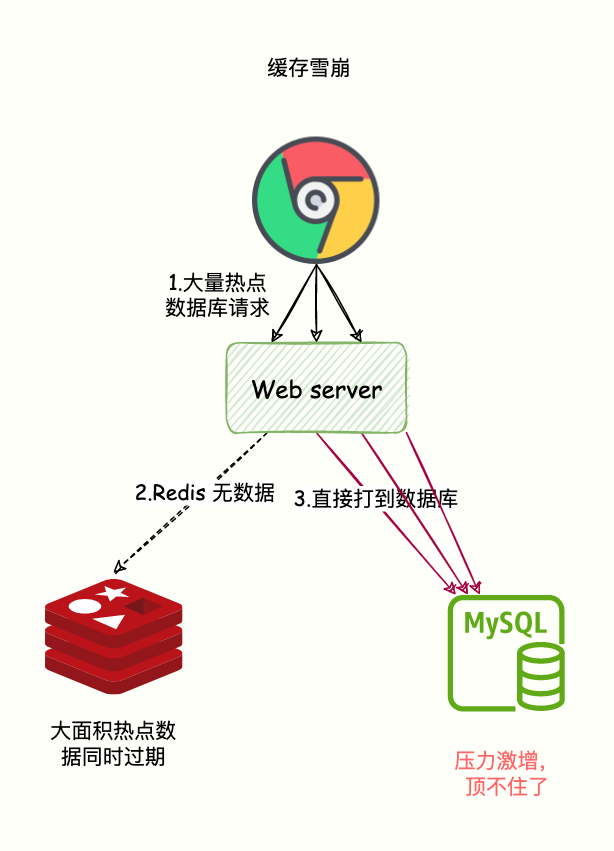 緩存雪崩-大量緩存同時失效
緩存雪崩-大量緩存同時失效
解決方案
過期時間添加隨機值
要避免給大量的數據設置一樣的過期時間,過期時間 = baes 時間+ 隨機時間(較小的隨機數,比如隨機增加 1~5 分鐘)。
這樣一來,就不會導致同一時刻熱點數據全部失效,同時過期時間差別也不會太大,既保證了相近時間失效,又能滿足業務需求。
接口限流
當訪問的不是核心數據的時候,在查詢的方法上加上接口限流保護。比如設置 10000 req/s。
如果訪問的是核心數據接口,緩存不存在允許從數據庫中查詢并設置到緩存中。
這樣的話,只有部分請求會發送到數據庫,減少了壓力。
限流,就是指,我們在業務系統的請求入口前端控制每秒進入系統的請求數,避免過多的請求被發送到數據庫。
如下圖所示:
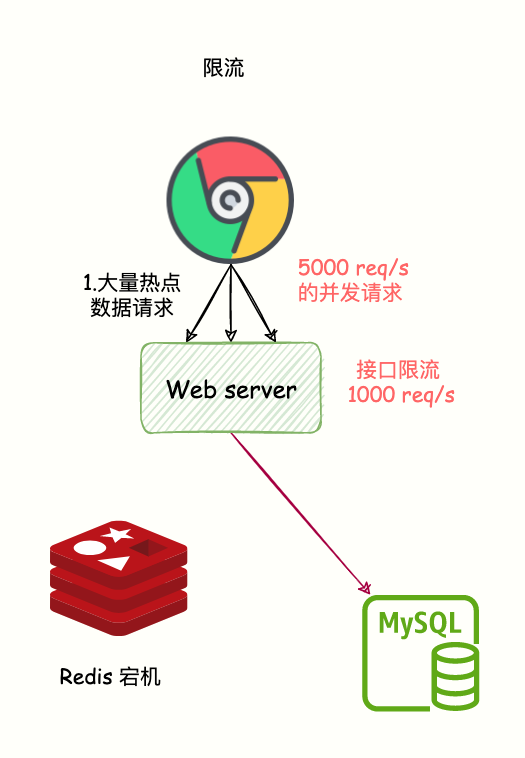 緩存雪崩-限流
緩存雪崩-限流
Redis 故障宕機
一個 Redis 實例能支撐 10 萬的 QPS,而一個數據庫實例只有 1000 QPS。
一旦 Redis 宕機,會導致大量請求打到數據庫,從而發生緩存雪崩。
解決方案
對于緩存系統故障導致的緩存雪崩的解決方案有兩種:
服務熔斷和接口限流;
構建高可用緩存集群系統。
服務熔斷和限流
在業務系統中,針對高并發的使用服務熔斷來有損提供服務從而保證系統的可用性。
服務熔斷就是當從緩存獲取數據發現異常,則直接返回錯誤數據給前端,防止所有流量打到數據庫導致宕機。
服務熔斷和限流屬于在發生了緩存雪崩,如何降低雪崩對數據庫造成的影響的方案。
構建高可用的緩存集群
所以,緩存系統一定要構建一套 Redis 高可用集群,如果 Redis 的主節點故障宕機了,從節點還可以切換成為主節點,繼續提供緩存服務,避免了由于緩存實例宕機而導致的緩存雪崩問題。
總結
緩存穿透指的是數據庫本就沒有這個數據,請求直奔數據庫,緩存系統形同虛設。
緩存擊穿(失效)指的是數據庫有數據,緩存本應該也有數據,但是緩存過期了,Redis 這層流量防護屏障被擊穿了,請求直奔數據庫。
緩存雪崩指的是大量的熱點數據無法在 Redis 緩存中處理(大面積熱點數據緩存失效、Redis 宕機),流量全部打到數據庫,導致數據庫極大壓力。
原文標題:Redis 緩存擊穿(失效)、緩存穿透、緩存雪崩怎么解決?
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
-
數據存儲
+關注
關注
5文章
964瀏覽量
50861 -
緩存
+關注
關注
1文章
233瀏覽量
26649 -
數據庫
+關注
關注
7文章
3767瀏覽量
64280
原文標題:Redis 緩存擊穿(失效)、緩存穿透、緩存雪崩怎么解決?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電壓開關中常見問題及解決方案

labview有哪些常見問題?labview三個常見問題和解決方法概述
調試中常見復雜問題和TRACE32相應的解決方案






 工商網監
工商網監
評論