") 英特爾AVX-512VNNI技術(shù)解析
英特爾AVX-512VNNI技術(shù)解析
英特爾AVX-512VNNI技術(shù)解析
高級矢量擴(kuò)展指令集(AdvancedVector ExtensionsAVX)是x86架構(gòu)微處理器中的SIMD指令集。英特爾AVX-512顧名思義寄存器位寬是512b,可以支持16路32b單精度浮點(diǎn)數(shù)或64路8b整型數(shù)。
英特爾至強(qiáng)可擴(kuò)展處理器通過英特爾深度學(xué)習(xí)加速(英特爾DLBoost)進(jìn)一步提升了AI計(jì)算性能。英特爾深度學(xué)習(xí)加速包含英特爾AVX-512VNNI(VectorNeural Network Instructions),是對標(biāo)準(zhǔn)英特爾AVX-512指令集的擴(kuò)展。
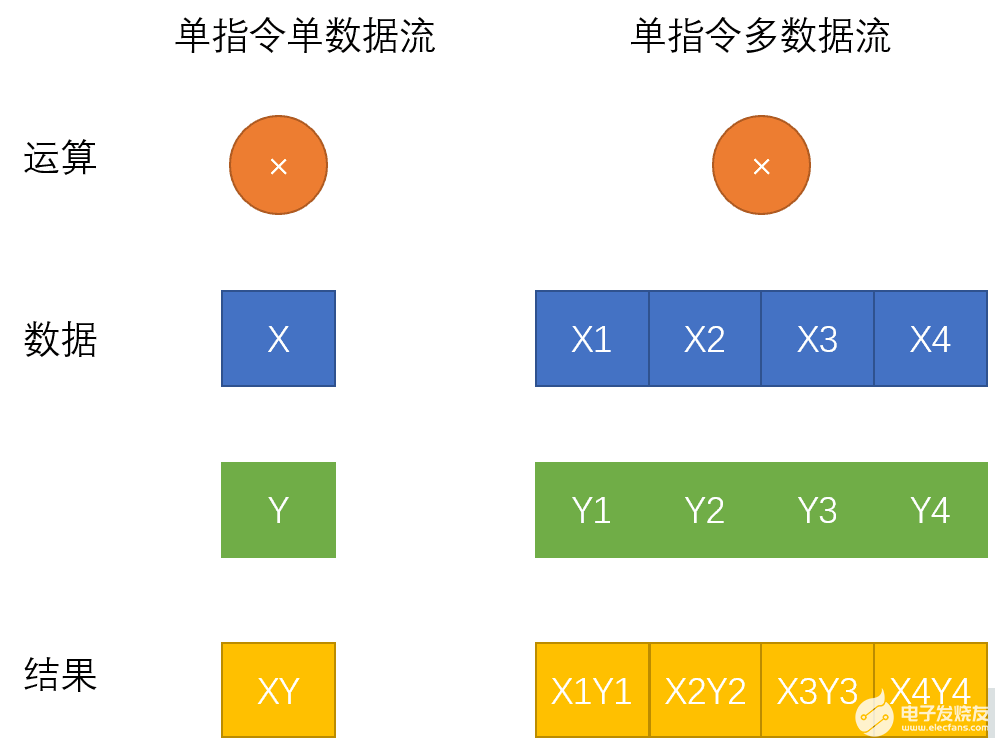
如何理解英特爾AVX-512技術(shù),還要從SIMD指令集說起。SIMD是單指令流多數(shù)據(jù)流操作(SingleInstruction Stream, Multiple Data Stream)的縮寫,相對應(yīng)的是SISD單指令流單數(shù)據(jù)流(SingleInstruction Stream, Single Data Stream)。相較于傳統(tǒng)的單指令單數(shù)據(jù)指令,SIMD指令使得一條指令可以完成多組數(shù)據(jù)的操作。單指令單數(shù)據(jù)流和單指令多數(shù)據(jù)流區(qū)別如下圖所示:
英特爾AVX指令集的前世今生
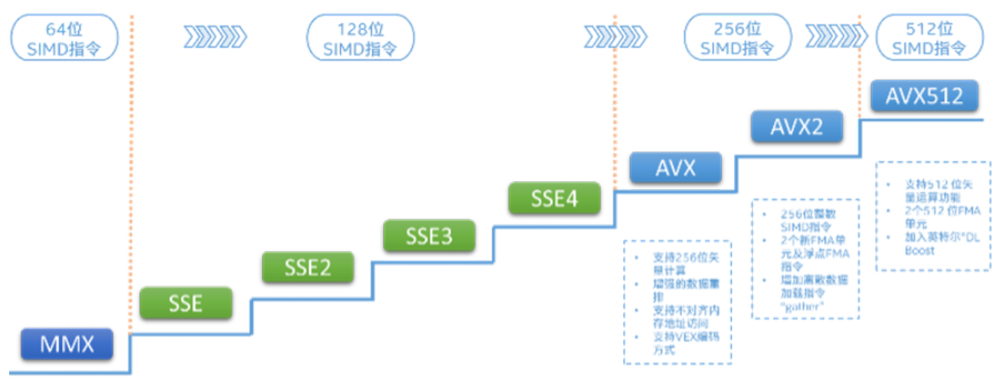
英特爾最早發(fā)布的SIMD指令集是MMX指令集:
1996年,英特爾發(fā)布了基于新版P55C架構(gòu)的PentiumMMX系列處理器,其中引入了新的MMX指令集,開始支持SIMD。PentiumMMX系列處理器上新引入的MMX指令集開創(chuàng)了x86處理器支持SIMD操作的先河,該指令集定義了8個(gè)64-bit寬度的寄存器,每個(gè)寄存器的64-bit容量中可以放入八個(gè)8-bit長度的整數(shù)或四個(gè)16-bit長度整數(shù)或兩個(gè)32-bit整數(shù),CPU在識別到MMX指令集的新指令時(shí)會自動將寄存器中的數(shù)據(jù)進(jìn)行分割計(jì)算,這樣一來,單個(gè)指令就成功操作了多個(gè)數(shù)據(jù),實(shí)現(xiàn)了SIMD。
英特爾AVX-512指令集實(shí)際上分成不同的擴(kuò)展,用來實(shí)現(xiàn)不同的操作。具體的擴(kuò)展如下:
AVX-512 Foundation
AVX-512 Conflict Detection Instructions (CD)
AVX-512 Exponential and Reciprocal Instructions (ER)
AVX-512 Prefetch Instructions (PF)
AVX-512 Vector Length Extensions (VL)
AVX-512 Byte and Word Instructions (BW)
AVX-512 Doubleword and Quadword Instructions (DQ)
AVX-512 Integer Fused Multiply Add (IFMA)
AVX-512 Vector Byte Manipulation Instructions (VBMI)
AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW)
AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS)
VPOPCNTDQ
VPCLMULQDQ
AVX-512 Vector Neural Network Instructions (VNNI)
AVX-512 Galois Field New Instructions (GFNI)
AVX-512 Vector AES instructions (VAES)
AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2)
AVX-512 Bit Algorithms (BITALG)
AVX-512 Bfloat16 Floating-Point Instructions (BF16)
AVX-512 Half-Precision Floating-Point Instructions (FP16)
通過以上這些指令集擴(kuò)展,讓英特爾至強(qiáng)可擴(kuò)展處理器家族在音視頻處理、游戲、科學(xué)計(jì)算、數(shù)據(jù)加密壓縮以及深度學(xué)習(xí)等場景中擁有了出色的表現(xiàn)。
英特爾AVX-512VNNI(VectorNeural Network Instructions)
英特爾AVX-512VNNI(VectorNeural NetworkInstructions)是英特爾深度學(xué)習(xí)加速一項(xiàng)重要的內(nèi)容,也是對標(biāo)準(zhǔn)英特爾AVX-512指令集的擴(kuò)展。可以將三條指令合并成一條指令執(zhí)行,更進(jìn)一步的發(fā)揮新一代英特爾至強(qiáng)可擴(kuò)展處理器的計(jì)算潛能,提升INT8模型的推理性能。目前第2代和第3代英特爾至強(qiáng)可擴(kuò)展處理器均支持英特爾VNNI。
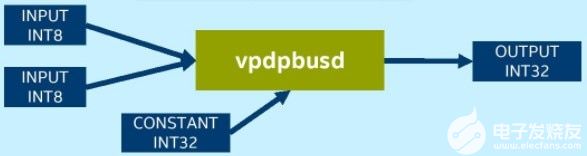
未使用VNNI的平臺需要vpmaddubsw、vpmaddwd和vpaddd指令才能完成INT8卷積運(yùn)算中的乘累加:

而擁有VNNI的平臺上則可以使用一條指令vpdpbusd完成INT8卷積操作:
英特爾深度學(xué)習(xí)加速VNNI加速推薦系統(tǒng)中的矢量召回
下面介紹一個(gè)具體的使用場景:英特爾深度學(xué)習(xí)加速VNNI加速推薦系統(tǒng)中的矢量召回。
眾所周知,推薦系統(tǒng)需要解決的問題是:如何為既定用戶生成一個(gè)長度為K的推薦列表,并使該推薦列表盡量(高準(zhǔn)確性)、盡快(低延遲)地滿足用戶的興趣和需求?常規(guī)的推薦系統(tǒng)包含兩部分:矢量召回(vectorrecall)和重排(ranking)。前者從龐大的推薦池里粗篩出當(dāng)前用戶最可能感興趣的幾百或幾千條內(nèi)容,并將結(jié)果交由后者的排序模塊進(jìn)一步排序,得到最終推薦結(jié)果。
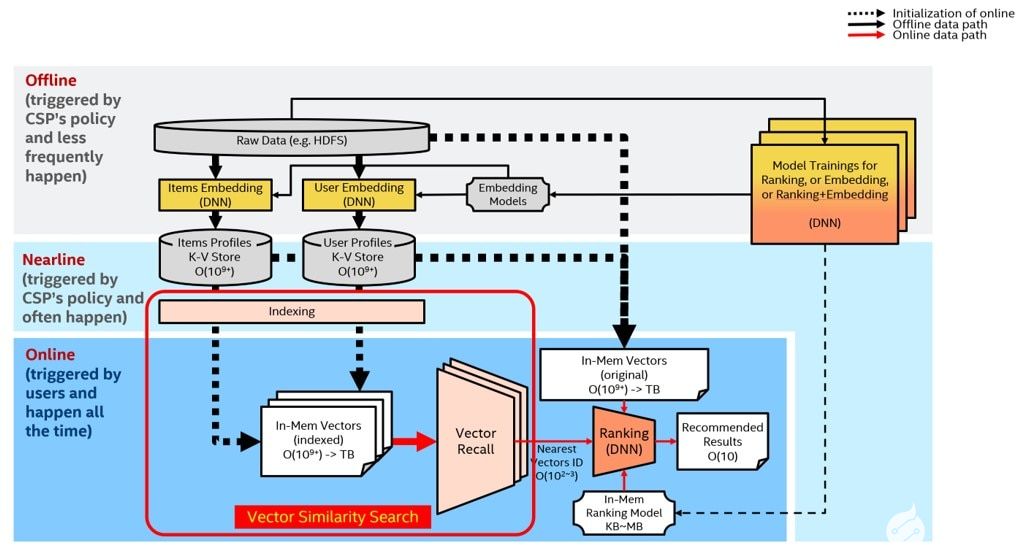
矢量召回可以轉(zhuǎn)換成高緯度的矢量相似性搜索問題。HNSW(HierarchicalNavigable Small World)算法是基于圖結(jié)構(gòu)的ANN(ApproximateNearest Neighbor)矢量相似度搜索算法之一,也是速度最快精度最高的算法之一。
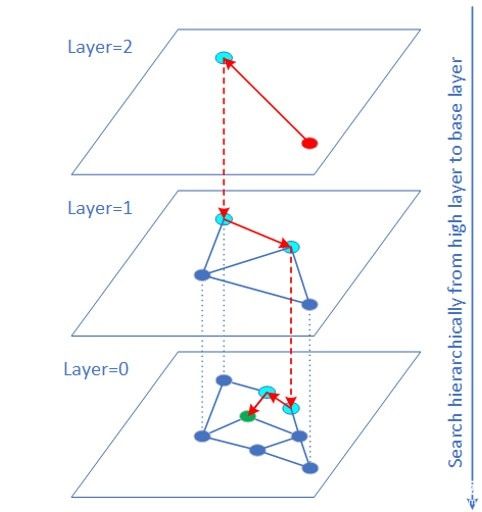
矢量原始數(shù)據(jù)的數(shù)據(jù)類型常常是FP32。對于很多業(yè)務(wù)(如圖片檢索),矢量數(shù)據(jù)是可以用INT8/INT16表示而且量化誤差對最終搜集結(jié)果影響有限。這時(shí)可以使用VNNI intrinsic 指令實(shí)現(xiàn)矢量INT8/INT16 的內(nèi)積計(jì)算。大量實(shí)驗(yàn)表明QPS性能有較大的提升,而且召回率幾乎不變。QPS提升的原因一方面是 INT8/INT16訪問帶寬比 FP32少很多,另一方面距離計(jì)算部分由于使用 VNNI指令得以加速。
當(dāng)數(shù)據(jù)集比較大時(shí)(如1億到10億數(shù)據(jù)量級范圍),傳統(tǒng)的做法是將數(shù)據(jù)集切片,變成幾個(gè)較小的數(shù)據(jù)集,每個(gè)數(shù)據(jù)集單獨(dú)獲取topK,最后再合并。由于增加了多個(gè)機(jī)器之間的通信,增加延遲的同時(shí)降低了QPS。在大數(shù)據(jù)集上使用HNSW方案的最佳實(shí)踐是:盡量不切片,在完整的數(shù)據(jù)集上建立索引和執(zhí)行搜索,可獲得最佳性能。當(dāng)數(shù)據(jù)集過大,內(nèi)存空間不夠時(shí),可以考慮使用英特爾傲騰持久內(nèi)存解決。
Super-FusedBERT技術(shù)解析
BERT介紹
BERT(BidirectionalEncoder Representations fromTransformers,基于變換器的雙向編碼器表示技術(shù))是2018年谷歌公司提出的NLP(Naturallanguageprocessing,自然語言處理)學(xué)科的新技術(shù)。谷歌正在利用BERT來更好地理解用戶搜索語句的語義。2020年的一項(xiàng)文獻(xiàn)調(diào)查得出結(jié)論:“在一年多一點(diǎn)的時(shí)間里,BERT已經(jīng)成為NLP實(shí)驗(yàn)中無處不在的基線”,算上分析和改進(jìn)模型的研究出版物超過150篇。
BERT的創(chuàng)新點(diǎn)在于它將雙向Transformer用于語言模型,之前的模型是從左向右輸入一個(gè)文本序列,或者將left-to-right和right-to-left的訓(xùn)練結(jié)合起來。實(shí)驗(yàn)的結(jié)果表明,雙向訓(xùn)練的語言模型對語境的理解會比單向的語言模型更深刻,BERT使用了一種新技術(shù)叫做MaskedLM(MLM),在這個(gè)技術(shù)出現(xiàn)之前是無法進(jìn)行雙向語言模型訓(xùn)練的。
英特爾AVX-512技術(shù)加速新浪廣告業(yè)務(wù)
通過使用英特爾AVX-512實(shí)現(xiàn)Super-FusedBert優(yōu)化方案
一、利用Intel MKL高性能數(shù)學(xué)庫
MKL是Intel發(fā)布的高性能數(shù)學(xué)庫,適用于科學(xué)計(jì)算,工程和金融領(lǐng)域。經(jīng)過多年的打磨,MKL已經(jīng)是x86平臺上性能最好的數(shù)學(xué)庫之一。借助MKL可以最大限度的發(fā)揮出Xeon處理器的硬件性能,幫助加速Bert模型的推理。

圖 MKL高性能數(shù)學(xué)庫
深度學(xué)習(xí)模型中存在大量矩陣乘法(GEMM)這種計(jì)算密集操作,可以直接使用MKL的cblas_sgemm接口。
此外,MKL還提供了一種新的GEMM接口,叫PackedAPI。這種API可以對輸入的矩陣進(jìn)行預(yù)處理(Pack),進(jìn)一步提高GEMM的效率。
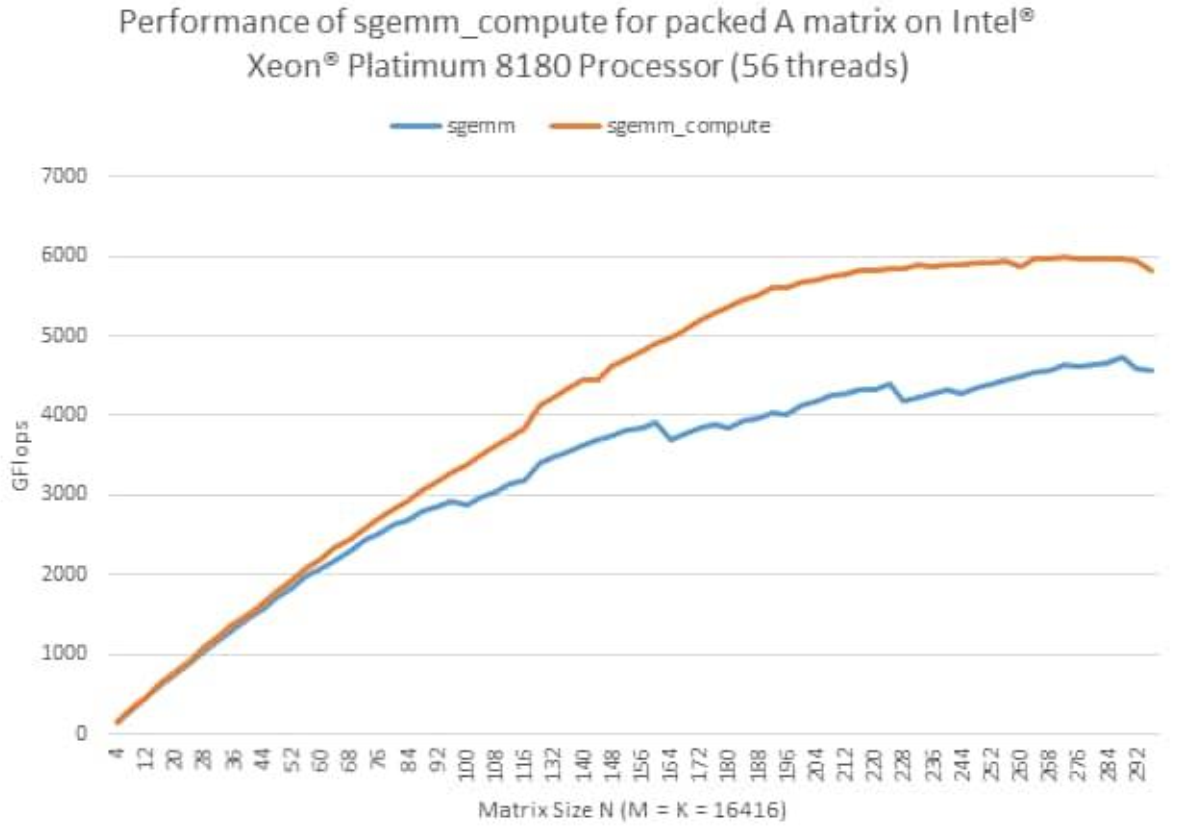
圖 MKLPacked API性能曲線
對于Bert模型,在其推理時(shí)權(quán)重是固定的,因此可以對權(quán)重進(jìn)行重排,使用MKL的PackedAPI進(jìn)行模型推理加速。
二、利用Intel oneDNN開源深度學(xué)習(xí)加速庫
oneDNN是Intel開源的深度學(xué)習(xí)加速庫,同樣可以支持不同的計(jì)算設(shè)備,如CPU,GPU等。oneDNN抽象了以下幾個(gè)概念:
Primitive:一種DNN算子的底層原語,支持matmul,convolution等。
Memory:對Primitive使用的內(nèi)存的抽象,存在多種布局,不同的內(nèi)存布局也會影響
Primitive:的執(zhí)行效率。
Engine:底層計(jì)算設(shè)備抽象,可支持 CPU, GPU。
Stream:Engine中Primitive的隊(duì)列。
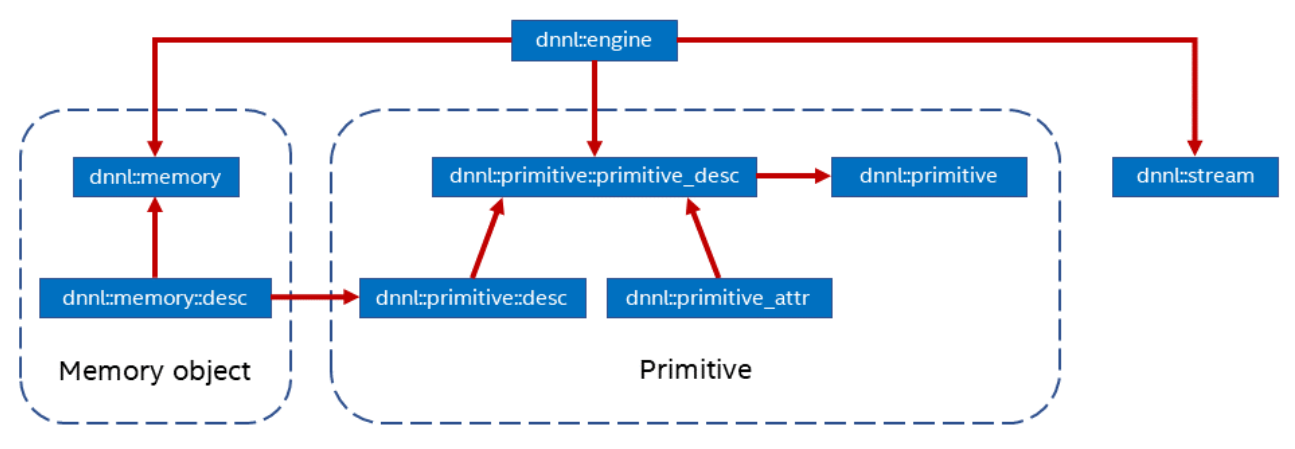
圖 oneDNN結(jié)構(gòu)
oneDNN中支持了大量常用的深度學(xué)習(xí)算子。Bert中使用的softmax,layernorm,gelu也都在oneDNN的Primitive中找到相應(yīng)的實(shí)現(xiàn)。
三、使用AVX-512技術(shù)進(jìn)行算子融合
在深度學(xué)習(xí)框架中,一個(gè)模型由多個(gè)算子組成,這些算子執(zhí)行都服從深度學(xué)習(xí)中調(diào)度器的調(diào)度。冗余的算子會增加調(diào)度開銷,進(jìn)而影響執(zhí)行效率。并且算子實(shí)現(xiàn)中可能還有很多不必要的訪存和內(nèi)存分配。因此在針對推理的優(yōu)化中,減少算子數(shù)量非常必要。

圖 算子融合示意圖
除此之外,深度學(xué)習(xí)模型中,計(jì)算密集的算子(matmul,conv)后面會跟一個(gè)element-wise的操作(激活函數(shù)relu)。這些element-wise的操作可以在計(jì)算密集算子計(jì)算的過程中完成,而不必等到計(jì)算密集算子完全計(jì)算完后再進(jìn)行。這種優(yōu)化也叫算子融合。
在Bert模型中,matmul,biasadd,gelu的組合可以使用oneDNN的matmulprimitive算子結(jié)合追加post_op來完成。
oneDNN的matmulprimitive可以進(jìn)行多維tensor的乘法操作,并附加融合bias加法。
四、訪存優(yōu)化
由于CPU架構(gòu)的特點(diǎn),越靠近CPU的存儲越快,體積越小。因此高效利用緩存對程序性能非常重要。
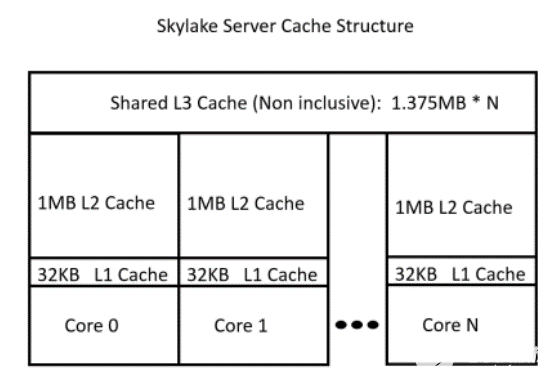
圖 CPUcache結(jié)構(gòu)示意圖
這就要求算子在實(shí)現(xiàn)的過程中能夠盡可能減少內(nèi)存占用,進(jìn)而減少cache的換出,提高cache利用率。
在Bert的self-attention中,對于q、k、v的計(jì)算中存在轉(zhuǎn)置操作。通過下圖可以清楚的看到,每一個(gè)q、k、v在經(jīng)過一個(gè)線性層后,都會按照head進(jìn)行split并轉(zhuǎn)置。在self-attention最后和v進(jìn)行點(diǎn)積后,還需要一個(gè)轉(zhuǎn)置來擺放數(shù)據(jù)。
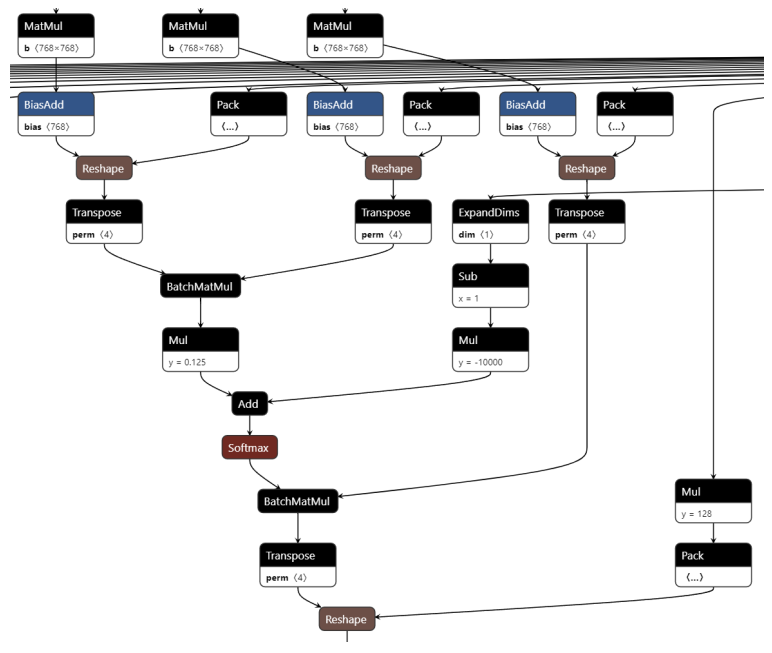
圖self-attention圖結(jié)構(gòu)
其實(shí)通過分析圖結(jié)構(gòu)的計(jì)算流程,我們可以將上面的轉(zhuǎn)置消除。如下圖,原來的數(shù)據(jù)是按紅色方框的方式存放,但是BatchMatmul需要用到的數(shù)據(jù)位于綠色方塊中。因此我們可以使用MKL的batch_sgemm接口,將參數(shù)stride指定為64*12。這樣就可以避免轉(zhuǎn)置帶來的內(nèi)存占用和訪存開銷。
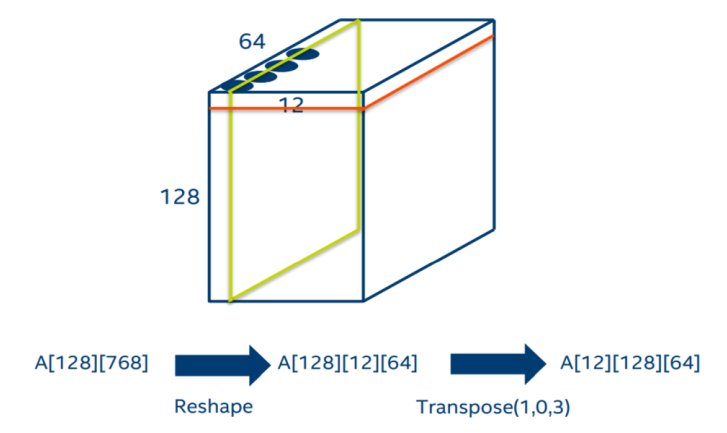
圖消除self-attention轉(zhuǎn)置
性能優(yōu)化數(shù)據(jù)
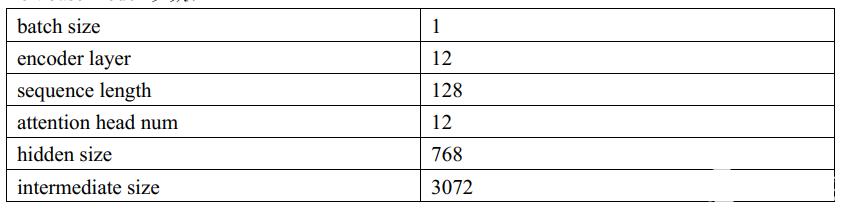
在Intel第三代Xeon處理器IceLake8358P上,我們對Super-FusedBert進(jìn)行了性能測試:
Bertbase model 參數(shù):
數(shù)據(jù)對比:
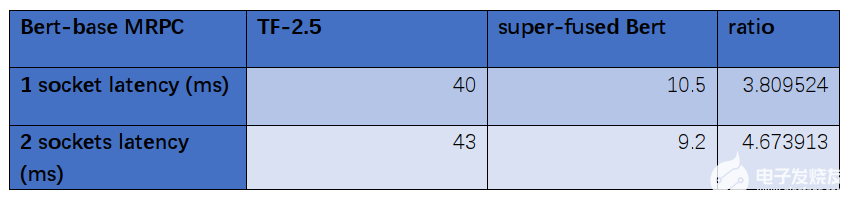
通過數(shù)據(jù)對比分析,經(jīng)過優(yōu)化后的Bert-base模型在第三代Xeon處理器IceLake8358P比優(yōu)化前節(jié)省了大約四分之三的時(shí)長,分別從40ms優(yōu)化到10.5ms、43ms優(yōu)化到9.2ms。
這種優(yōu)化對于滿足實(shí)時(shí)在線服務(wù)推理的延遲要求有著十分顯著的作用,有利于業(yè)務(wù)部門搭建基于Bert模型的業(yè)務(wù),提高了集群中CPU利用率。
*實(shí)際性能受使用情況、配置和其他因素的差異影響。更多信息請見www.Intel.com/PerformanceIndex性能測試結(jié)果基于配置信息中顯示的日期進(jìn)行測試,且可能并未反映所有公開可用的更新。
詳情請參閱配置信息披露。沒有任何產(chǎn)品或組件是絕對安全的。
英特爾技術(shù)可能需要啟用硬件、軟件或激活服務(wù)。
具體成本和結(jié)果可能不同。
審核編輯:湯梓紅
-
英特爾
+關(guān)注
關(guān)注
60文章
9900瀏覽量
171551 -
微處理器
+關(guān)注
關(guān)注
11文章
2247瀏覽量
82331 -
指令集
+關(guān)注
關(guān)注
0文章
222瀏覽量
23368
發(fā)布評論請先 登錄
相關(guān)推薦
世紀(jì)大并購!傳高通有意整體收購英特爾,英特爾最新回應(yīng)

英特爾考慮出售Altera股權(quán)
英特爾IT的發(fā)展現(xiàn)狀和創(chuàng)新動向
英特爾是如何實(shí)現(xiàn)玻璃基板的?
英特爾攜手日企加碼先進(jìn)封裝技術(shù)
英特爾CEO:AI時(shí)代英特爾動力不減
英特爾加大玻璃基板技術(shù)布局力度
借助英特爾DLB技術(shù)優(yōu)化網(wǎng)絡(luò)性能


第五代英特爾至強(qiáng),以卓越性能為多元化工作負(fù)載“保駕護(hù)航”
英特爾首推面向AI時(shí)代的系統(tǒng)級代工—英特爾代工


英特爾量產(chǎn)3D Foveros封裝技術(shù)
2023?英特爾On技術(shù)創(chuàng)新大會中國站,相約12月19日!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論