") 用NVIDIA H100 CNX構(gòu)建人工智能系統(tǒng)
用NVIDIA H100 CNX構(gòu)建人工智能系統(tǒng)
人們對能夠以更快的速度將數(shù)據(jù)從網(wǎng)絡(luò)傳輸?shù)?GPU 的服務(wù)器的需求不斷增加。隨著人工智能模型不斷變大,訓(xùn)練所需的數(shù)據(jù)量需要多節(jié)點訓(xùn)練等技術(shù)才能在合理的時間范圍內(nèi)取得成果。 5G 的信號處理比前幾代更復(fù)雜, GPU 可以幫助提高這種情況發(fā)生的速度。機器人或傳感器等設(shè)備也開始使用 5G 與邊緣服務(wù)器通信,以實現(xiàn)基于人工智能的決策和行動。
專門構(gòu)建的人工智能系統(tǒng),比如最近發(fā)布的 NVIDIA DGX H100 ,是專門為支持?jǐn)?shù)據(jù)中心用例的這些需求而設(shè)計的。現(xiàn)在,另一種新產(chǎn)品可以幫助企業(yè)獲得更快的數(shù)據(jù)傳輸和更高的邊緣設(shè)備性能,但不需要高端或定制系統(tǒng)。
NVIDIA 首席執(zhí)行官 Jensen Huang 上周在 NVIDIA 公司 GTC 宣布, NVIDIA H100 CNX 是一個高性能的企業(yè)包。它結(jié)合了 NVIDIA H100 的能力與 NVIDIA ConnectX-7 SmartNIC 先進的網(wǎng)絡(luò)能力。這種先進的體系結(jié)構(gòu)在 PCIe 板上提供,為主流數(shù)據(jù)中心和邊緣系統(tǒng)的 GPU 供電和 I / O 密集型工作負載提供了前所未有的性能。
H100 CNX 的設(shè)計優(yōu)勢
在標(biāo)準(zhǔn) PCIe 設(shè)備中,控制平面和數(shù)據(jù)平面共享相同的物理連接。然而,在 H100 CNX 中, GPU 和網(wǎng)絡(luò)適配器通過直接 PCIe Gen5 通道連接。這為 GPU 和使用 GPUDirect RDMA 的網(wǎng)絡(luò)之間的數(shù)據(jù)傳輸提供了專用的高速路徑,并消除了通過主機的數(shù)據(jù)瓶頸。
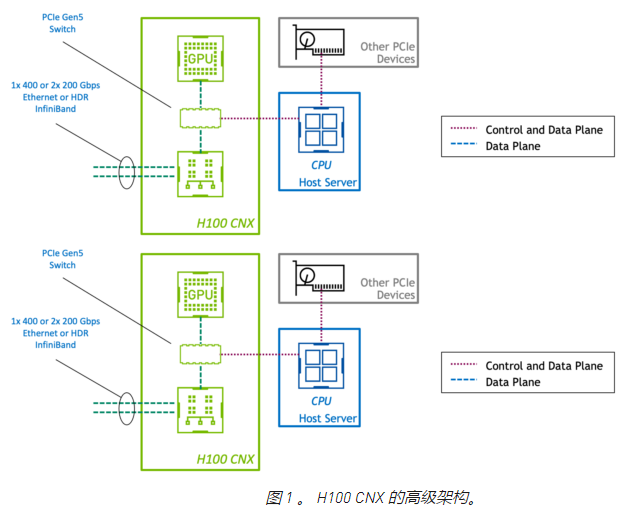
通過將 GPU 和 SmartNIC 組合在一塊板上,客戶可以利用 PCIe Gen4 甚至 Gen3 上的服務(wù)器。通過高端或?qū)iT構(gòu)建的系統(tǒng)實現(xiàn)一次性能水平可以節(jié)省硬件成本。將這些組件放在一塊物理板上也可以提高空間和能源效率。
將 GPU 和 SmartNIC 集成到單個設(shè)備中,通過設(shè)計創(chuàng)建了一個平衡的體系結(jié)構(gòu)。在具有多個 GPU 和 NIC 的系統(tǒng)中,聚合加速卡強制 GPU 與 NIC 的比例為 1:1 。這避免了服務(wù)器 PCIe 總線上的爭用,因此性能會隨著附加設(shè)備線性擴展。
NVIDIA 的核心加速軟件庫(如 NCCL 和 UCX )自動利用性能最佳的路徑將數(shù)據(jù)傳輸?shù)?GPU 。現(xiàn)有的加速多節(jié)點應(yīng)用程序可以在不做任何修改的情況下利用 H100 CNX ,因此客戶可以立即從高性能和可擴展性中受益。
H100 CNX 用例
H100 CNX 提供 GPU 加速,同時具有低延遲和高速網(wǎng)絡(luò)。這是在較低的功耗下完成的,與兩個分立的卡相比,占用空間更小,性能更高。許多用例可以從這種組合中受益,但以下幾點尤其值得注意。
5G 信號處理
使用 GPU 進行 5G 信號處理需要盡快將數(shù)據(jù)從網(wǎng)絡(luò)移動到 GPU ,并且具有可預(yù)測的延遲也是至關(guān)重要的。 NVIDIA 聚合加速器與 NVIDIA Aerial SDK 相結(jié)合,為運行 5G 應(yīng)用程序提供了性能最高的平臺。由于數(shù)據(jù)不經(jīng)過主機 PCIe 系統(tǒng),因此處理延遲大大減少。在使用速度較慢的 PCIe 系統(tǒng)的商品服務(wù)器時,甚至可以看到這種性能的提高。
加速 5G 以上的邊緣人工智能
NVIDIA AI on 5G 由 NVIDIA EGX 企業(yè)平臺、 NVIDIA 公司的 SDK 軟件定義的 5G 虛擬無線局域網(wǎng)和企業(yè) AI 框架組成。這包括像 NVIDIA ISAAC 和 NVIDIA Metropolis 這樣的 SDK 。攝像機、工業(yè)傳感器和機器人等邊緣設(shè)備可以使用人工智能,并通過 5G 與服務(wù)器通信。
H100 CNX 可以在單個企業(yè)服務(wù)器中提供此功能,而無需部署昂貴的專用系統(tǒng)。與NVIDIA 多實例 GPU 技術(shù)相比,應(yīng)用于 5G 信號處理的相同加速器可用于邊緣 AI 。這使得共享 GPU 用于多種不同目的成為可能。
多節(jié)點人工智能訓(xùn)練
多節(jié)點培訓(xùn)涉及不同主機上 GPU 之間的數(shù)據(jù)傳輸。在一個典型的數(shù)據(jù)中心網(wǎng)絡(luò)中,服務(wù)器通常會在性能、規(guī)模和密度方面受到各種限制。大多數(shù)企業(yè)服務(wù)器不包括 PCIe 交換機,因此 CPU 成為這種流量的瓶頸。數(shù)據(jù)傳輸受主機 PCIe 背板的速度限制。雖然 GPU:NIC 的比例為 1:1 是理想的,但服務(wù)器中 PCIe 通道和插槽的數(shù)量可能會限制設(shè)備的總數(shù)。
H100 CNX 的設(shè)計緩解了這些問題。從網(wǎng)絡(luò)到 GPU 有一條專用路徑,供 GPUDirect RDMA 以接近線路速度運行。無論主機 PCIe 背板如何,數(shù)據(jù)傳輸也會以 PCIe Gen5 的速度進行。主機內(nèi) GPU 功率的放大可以以平衡的方式進行,因為 GPU:NIC 的比例是 1:1 。服務(wù)器還可以配備更多的加速能力,因為與離散卡相比,聚合加速器所需的 PCIe 通道和設(shè)備插槽更少。
NVIDIA H100 CNX 預(yù)計可在今年下半年購買。如果你有一個用例可以從這個獨特而創(chuàng)新的產(chǎn)品中受益,請聯(lián)系你最喜歡的系統(tǒng)供應(yīng)商,詢問他們計劃何時將其與服務(wù)器一起提供。
關(guān)于作者:About Charu Chaubal
Charu Chaubal 在NVIDIA 企業(yè)計算平臺集團從事產(chǎn)品營銷工作。他在市場營銷、客戶教育以及技術(shù)產(chǎn)品和服務(wù)的售前工作方面擁有 20 多年的經(jīng)驗。 Charu 曾在云計算、超融合基礎(chǔ)設(shè)施和 IT 安全等多個領(lǐng)域工作。作為 VMware 的技術(shù)營銷領(lǐng)導(dǎo)者,他幫助推出了許多產(chǎn)品,這些產(chǎn)品共同發(fā)展成為數(shù)十億美元的業(yè)務(wù)。此前,他曾在 Sun Microsystems 工作,在那里他設(shè)計了分布式資源管理和 HPC 基礎(chǔ)設(shè)施軟件解決方案。查魯擁有化學(xué)工程博士學(xué)位,并擁有多項專利。
-
人工智能
+關(guān)注
關(guān)注
1791文章
46859瀏覽量
237571 -
5G
+關(guān)注
關(guān)注
1353文章
48367瀏覽量
563382 -
H100
+關(guān)注
關(guān)注
0文章
31瀏覽量
282
發(fā)布評論請先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
英偉達H100芯片市場降溫
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第一章人工智能驅(qū)動的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
FPGA在人工智能中的應(yīng)用有哪些?
首批1024塊H100 GPU,正崴集團將建中國臺灣最大AI計算中心
德克薩斯大學(xué)將創(chuàng)建一個學(xué)術(shù)界最強大的生成性人工智能研究中心
進一步解讀英偉達 Blackwell 架構(gòu)、NVlink及GB200 超級芯片
英特爾發(fā)布人工智能芯片新版,對標(biāo)Nvidia
英偉達H200和H100的比較
嵌入式人工智能的就業(yè)方向有哪些?
扎克伯格的Meta斥資數(shù)十億美元購買35萬塊Nvidia H100 GPU






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論