 利用NVIDIA安培結構和TensorRT部署神經網絡
利用NVIDIA安培結構和TensorRT部署神經網絡
在部署神經網絡時,考慮如何使網絡運行更快或占用更少的空間是很有用的。一個更高效的網絡可以在有限的時間預算內做出更好的預測,對意外的輸入做出更快的反應,或者適應受限的部署環境。
稀疏性是一種有希望達到這些目標的優化技術。如果網絡中有零,則不需要對其進行存儲或操作。稀疏的好處似乎很簡單。要實現承諾的收益,長期以來存在三個挑戰。
Acceleration – 細粒度、非結構化、權重稀疏缺乏結構,無法使用高效硬件中可用的向量和矩陣指令來加速常見的網絡操作。標準稀疏格式對于除高稀疏以外的所有格式都是低效的。
Accuracy – 為了實現具有細粒度、非結構化稀疏性的有用加速,必須使網絡稀疏,這通常會導致精度損失。嘗試使加速更容易的替代修剪方法,例如去除權重塊、通道或整個層的粗粒度修剪,可能更快地遇到精度問題。這限制了潛在的性能優勢。
Workflow – 當前在網絡修剪方面的許多研究都可以作為有用的存在性證明。研究表明,網絡 A 可以實現稀疏性 X 。當您嘗試將稀疏性 X 應用于網絡 B 時,麻煩就來了。由于網絡、任務、優化器或任何超參數的不同,它可能無法工作。
在本文中,我們將討論 NVIDIA 安培體系結構如何應對這些挑戰。今天, NVIDIA 發布了 TensorRT 版本 8 。 0 ,它引入了對 NVIDIA 安培體系結構 GPU 上可用的稀疏張量核的支持。
TensorRT 是一個用于高性能深度學習推理的 SDK ,它包括一個優化器和運行時,可以最大限度地減少延遲和提高生產中的吞吐量。稀疏張量核通過一個簡單的訓練流程和 TensorRT 8 。 0 部署,可以消除神經網絡中不必要的計算,與密集網絡相比,可以獲得 30% 以上的性能/瓦特增益。
稀疏張量核加速了 2 : 4 細粒度結構稀疏性
NVIDIA A100 GPU 為其張量核增加了對細粒度結構稀疏性的支持,稀疏張量核加速了 2 : 4 的稀疏模式。在四個值的每個連續塊中,兩個值必須為零。這自然會導致 50% 的稀疏度,這是細粒度的。沒有矢量或塊結構修剪在一起。這樣的規則模式易于壓縮,并且元數據開銷較低(圖 1 )。
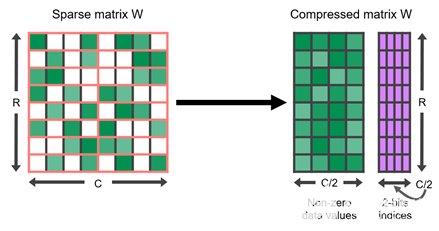
圖 1 。 2 : 4 結構稀疏矩陣 W 及其壓縮表示
稀疏張量核通過只對壓縮矩陣中的非零值進行運算來加速這種格式。它們使用與非零一起存儲的元數據僅從另一個未壓縮的操作數中提取必要的值。因此,對于 2x 的稀疏性,它們可以在一半的時間內完成相同的有效計算。表 1 顯示了稀疏張量核支持的各種數據類型的詳細信息。
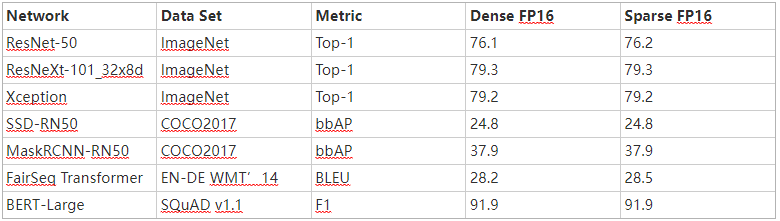
表 1 。稀疏張量核在 NVIDIA 安培結構中的性能。
2 : 4 結構化稀疏網絡保持精度
當然,沒有良好的準確性,性能是毫無意義的。我們開發了一個簡單的培訓工作流程,可以輕松生成 2 : 4 結構化稀疏網絡,匹配密集網絡的精度:
從密集的網絡開始。我們的目標是從一個已知的好模型開始,該模型的權重已經收斂,從而得到有用的結果。
在稠密網絡上,對權值進行剪枝以滿足 2 : 4 的結構稀疏性準則。在每四個元素中,只刪除兩個。
重復原來的培訓程序。
此工作流在步驟 2 中使用一次修剪。在修剪階段之后,稀疏模式被修復。有很多方法可以做出修剪的決定。哪些權重應該保留,哪些權重應該強制為零?我們發現一個簡單的答案很有效:重量大小。我們更喜歡刪減已經接近零的值。
正如您所料,突然將網絡中的一半權重變為零會影響網絡的精度。第三步通過足夠多的權重更新步驟來恢復精度,讓權重收斂,并且有足夠高的學習率讓權重充分移動。在廣泛的網絡中,它生成一個稀疏模型,從步驟 1 開始保持密集網絡的精度。
表 2 是我們使用 PyTorch 庫 自動稀疏( ASP ) 中實現的此工作流獲得的 FP16 精度結果示例。有關 FP16 和 INT8 的完整結果的更多信息,請參閱 加速稀疏深度神經網絡 白皮書。
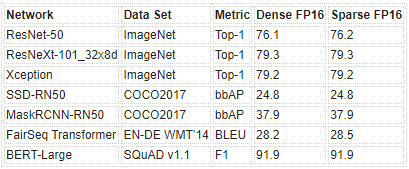
表 2 。用我們的配方訓練的 2 : 4 結構化稀疏網絡的樣本精度。
案例研究: ResNeXt-10132x8d
以下是以 ResNeXt-10132x8d 為目標使用工作流的簡單程度。
生成稀疏模型
您使用 torchvision 預訓練的 model ,因此步驟 1 已經完成。因為您使用的是 ASP ,所以第一個代碼更改是導入庫:

加載此訓練運行的預訓練模型。不過,與其訓練密集權重,不如在訓練循環之前修剪模型并準備優化器(工作流的步驟 2 ):

就這樣。訓練循環正常進行,默認命令從預訓練模型開始,該模型重用原始超參數和優化器設置進行再訓練:

當訓練完成(第 3 步)時,網絡精度應恢復到與預訓練模型的精度相匹配,如表 2 所示。通常,性能最好的檢查點可能不是來自最后一個歷元。
準備推理
對于推理,使用 TensorRT 8 。 0 導入訓練模型的稀疏檢查點。在導入 TensorRT 之前,需要將模型從本機框架格式轉換為 ONNX 格式。可以按照 quickstart/IntroNotebooks GitHub repo 中的筆記本進行轉換。
我們已經將稀疏 ResNeXt-10132x8d 轉換為 ONNX 格式。你可以從 NGC 下載這個模型。如果沒有安裝 NGC ,請使用以下命令安裝 NGC :

安裝 NGC 后,通過運行以下命令下載 ONNX 格式的稀疏 ResNeXt-10132x8d :
![]()
要將 ONNX 模型導入到 TensorRT ,請克隆 TensorRT repo 并設置 Docker 環境,如 NVIDIA / TensorRT 自述 中所述。
進入 trtexec 根目錄后,使用 TensorRT 將稀疏 ONNX 模型轉換為 TensorRT 引擎。創建一個目錄以存儲模型和引擎:

將下載的 ResNext ONNX 模型復制到 /workspace/TensorRT/model 目錄,然后執行 trtexec 命令,如下所示:

名為 resnext101 _ engine 。 trt 的新文件創建于/ workspace / TensorRT / model /。 resnext101 _ engine 。 trt 文件現在可以通過以下方法之一序列化以執行推斷:
TensorRT 運行時的 C ++或 Python ,如在這個 示例筆記本 中所示
NVIDIA Triton ?聲波風廓線儀推斷服務器
TensorRT 8 。 0 中的性能
將 TensorRT 8 。 0 中的稀疏模型在 A100 GPU 上以不同批量大小進行基準測試顯示了兩個重要趨勢:
性能優勢隨著 A100 所做的工作量的增加而增加。更大的批量通常會帶來更大的改進,在高端接近 20% 。
在較小的批處理規模下, A100 時鐘速度可以保持在較低的水平,使用稀疏性可以將它們推到更低的水平,以獲得相同的性能,從而導致比性能本身更大的功率效率改進,從而獲得高達 36% 的性能/瓦增益。
別忘了,這個網絡和密集基線的精確度是一樣的。這種額外的效率和性能不需要懲罰的準確性。
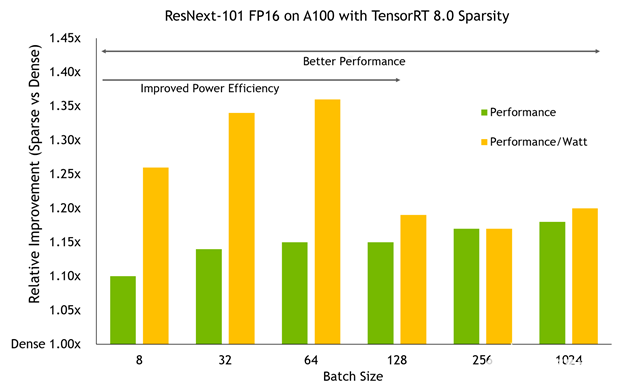
圖 2 。性能和能效方面的稀疏性改進(以密集為基準)
概括
稀疏性是神經網絡壓縮和簡化研究的熱點。不過,到目前為止,細粒度稀疏性還沒有兌現其性能和準確性的承諾。我們開發了 2 : 4 細粒度結構稀疏性,并將支持直接構建到 NVIDIA 安培結構稀疏張量核中。通過這個簡單的三步稀疏再訓練工作流,您可以生成與基線精度匹配的稀疏神經網絡, TensorRT 8 。 0 在默認情況下對其進行加速。
關于作者
About Jeff Pool
Jeff Pool 是深入學習體系結構團隊的高級架構師,負責研究高效的 DL 方法。在 2012 年加入 NVIDIA 之后,他對各種體系結構的許多領域做出了貢獻,但最近他一直在使用稀疏神經網絡。 Jeff 擁有計算機科學博士學位,專注于高效圖形硬件。
About Abhishek Sawarkar
Abhishek Sawarkar 責在 NVIDIA Jarvis 框架上開發和展示以深度學習為重點的內容。他的背景是計算機視覺和機器學習,但目前他正致力于整個 Jarvis 多模式管道,包括 ASR 、 NLP 、 TTS 和 CV 。他是卡內基梅隆大學的一名應屆畢業生,具有電氣和計算機工程碩士學位。
About Jay Rodge
Jay Rodge 是 NVIDIA 的產品營銷經理,負責深入學習和推理產品,推動產品發布和產品營銷計劃。杰伊在芝加哥伊利諾伊理工學院獲得計算機科學碩士學位,主攻計算機視覺和自然語言處理。在 NVIDIA 之前,杰伊是寶馬集團的人工智能研究實習生,為寶馬最大的制造廠使用計算機視覺解決問題。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100566 -
NVIDIA
+關注
關注
14文章
4949瀏覽量
102828 -
SDK
+關注
關注
3文章
1029瀏覽量
45782
發布評論請先 登錄
相關推薦
LSTM神經網絡的結構與工作機制
遞歸神經網絡和循環神經網絡的模型結構





 工商網監
工商網監
評論