") 使用NVIDIA TensorRT優(yōu)化T5和GPT-2
使用NVIDIA TensorRT優(yōu)化T5和GPT-2
這個(gè)transformer 體系結(jié)構(gòu)完全改變了(雙關(guān)語)自然語言處理( NLP )的領(lǐng)域。近年來,在 transformer 構(gòu)建塊 BERT 、 GPT 和 T5 上構(gòu)建了許多新穎的網(wǎng)絡(luò)體系結(jié)構(gòu)。隨著品種的增加,這些型號(hào)的尺寸也迅速增加。
雖然較大的神經(jīng)語言模型通常會(huì)產(chǎn)生更好的結(jié)果,但將它們部署到生產(chǎn)環(huán)境中會(huì)帶來嚴(yán)重的挑戰(zhàn),尤其是對(duì)于在線應(yīng)用程序,在這些應(yīng)用程序中,幾十毫秒的額外延遲可能會(huì)對(duì)用戶體驗(yàn)產(chǎn)生顯著的負(fù)面影響。
使用最新的TensorRT8.2 ,我們優(yōu)化了 T5 和 GPT-2 模型,以實(shí)現(xiàn)實(shí)時(shí)推理。您可以將 T5 或 GPT-2 模型轉(zhuǎn)換為 TensorRT 引擎,然后將此引擎用作推理工作流中原始 PyTorch 模型的插件替換。與 PyTorch GPU 推理相比,此優(yōu)化導(dǎo)致延遲減少 3-6 倍,與 PyTorch CPU 推理相比,延遲減少 9-21 倍。
在這篇文章中,我們將向您詳細(xì)介紹如何實(shí)現(xiàn)相同的延遲減少,使用我們最新發(fā)布的基于 Hugging Face transformers 的示例腳本和筆記本,使用 GPT-2 進(jìn)行開放式文本生成,使用 T5 進(jìn)行翻譯和摘要。
T5 和 GPT-2 簡介
在本節(jié)中,我們將簡要介紹 T5 和 GPT-2 模型。
T5 用于回答問題、總結(jié)、翻譯和分類
T5或文本到文本傳輸 transformer 是谷歌最近創(chuàng)建的一種體系結(jié)構(gòu)。它將所有自然語言處理( NLP )任務(wù)重新構(gòu)造為統(tǒng)一的文本到文本格式,其中輸入和輸出始終是文本字符串。 T5 的體系結(jié)構(gòu)允許將相同的模型、損失函數(shù)和超參數(shù)應(yīng)用于任何 NLP 任務(wù),如機(jī)器翻譯、文檔摘要、問答和分類任務(wù),如情感分析。
T5 模式的靈感來源于遷移學(xué)習(xí)在 NLP 中產(chǎn)生了最先進(jìn)的結(jié)果。遷移學(xué)習(xí)背后的原理是,基于大量可用的未經(jīng)訓(xùn)練的數(shù)據(jù)和自我監(jiān)督任務(wù)的模型可以在較小的任務(wù)特定標(biāo)記數(shù)據(jù)集上針對(duì)特定任務(wù)進(jìn)行微調(diào)。事實(shí)證明,這些模型比從頭開始針對(duì)特定任務(wù)數(shù)據(jù)集訓(xùn)練的模型具有更好的結(jié)果。
基于遷移學(xué)習(xí)的概念, Google 在用統(tǒng)一的文本到文本轉(zhuǎn)換器探索遷移學(xué)習(xí)的局限性中提出了 T5 模型。在本文中,他們還介紹了龐大的干凈爬網(wǎng)語料庫( C4 )數(shù)據(jù)集。在該數(shù)據(jù)集上預(yù)訓(xùn)練的 T5 模型在許多下游 NLP 任務(wù)上實(shí)現(xiàn)了最先進(jìn)的結(jié)果。已發(fā)布的預(yù)訓(xùn)練 T5 車型的參數(shù)范圍高達(dá) 3B 和 11B 。
GPT-2 用于生成優(yōu)秀的類人文本
生成性預(yù)訓(xùn)練 transformer 2 (GPT-2)是 OpenAI 最初提出的一種自回歸無監(jiān)督語言模型。它由 transformer 解碼器塊構(gòu)建,并在非常大的文本語料庫上進(jìn)行訓(xùn)練,以預(yù)測段落中的下一個(gè)單詞。它生成優(yōu)秀的類人文本。更大的 GPT-2 模型,最大參數(shù)達(dá)到 15 億,通常能寫出更好、更連貫的文本。
使用 TensorRT 部署 T5 和 GPT-2
使用 TensorRT 8.2 ,我們通過構(gòu)建并使用 TensorRT 發(fā)動(dòng)機(jī)作為原始 PyTorch 模型的替代品,優(yōu)化了 T5 和 GPT-2 模型。我們將帶您瀏覽scripts和 Jupyternotebooks,并重點(diǎn)介紹基于擁抱面部變形金剛的重要內(nèi)容。有關(guān)更多信息,請(qǐng)參閱示例腳本和筆記本以獲取詳細(xì)的分步執(zhí)行指南。
設(shè)置
最方便的開始方式是使用 Docker 容器,它為實(shí)驗(yàn)提供了一個(gè)隔離、獨(dú)立和可復(fù)制的環(huán)境。
構(gòu)建并啟動(dòng) TensorRT 容器:

這些命令啟動(dòng) Docker 容器和 JupyterLab 。在 web 瀏覽器中打開 JupyterLab 界面: 在 JupyterLab 中,要打開終端窗口,請(qǐng)選擇?File?、?New?、?Terminal?。編譯并安裝 TensorRT OSS 包:
在 JupyterLab 中,要打開終端窗口,請(qǐng)選擇?File?、?New?、?Terminal?。編譯并安裝 TensorRT OSS 包:

現(xiàn)在,您已經(jīng)準(zhǔn)備好繼續(xù)使用模型進(jìn)行實(shí)驗(yàn)。在下面的順序中,我們將演示 T5 模型的步驟。下面的代碼塊并不意味著可以復(fù)制粘貼運(yùn)行,而是引導(dǎo)您完成整個(gè)過程。為了便于復(fù)制,請(qǐng)參閱 GitHub 存儲(chǔ)庫上的notebooks。
在高層次上,使用 TensorRT 優(yōu)化用于部署的擁抱面 T5 和 GPT-2 模型是一個(gè)三步過程:
從 HuggingFace 模型動(dòng)物園下載模型。
將模型轉(zhuǎn)換為優(yōu)化的 TensorRT 執(zhí)行引擎。
使用 TensorRT 引擎進(jìn)行推理。
使用生成的引擎作為 HuggingFace 推理工作流中原始 PyTorch 模型的插件替換。
從 HuggingFace 模型動(dòng)物園下載模型
首先,從 HuggingFace 模型中心下載原始的 Hugging Face PyTorch T5 模型及其關(guān)聯(lián)的標(biāo)記器。

然后,您可以將此模型用于各種 NLP 任務(wù),例如,從英語翻譯為德語:

TensorRT 8.2 支持 GPT-2 至“ xl ”版本( 1.5B 參數(shù))和 T5 至 11B 參數(shù),這些參數(shù)可在 HuggingFace model zoo 上公開獲得。根據(jù) GPU 內(nèi)存可用性,也可支持較大型號(hào)。
將模型轉(zhuǎn)換為優(yōu)化的 TensorRT 執(zhí)行引擎。
在將模型轉(zhuǎn)換為 TensorRT 引擎之前,請(qǐng)將 PyTorch 模型轉(zhuǎn)換為中間通用格式。 ONNX 是機(jī)器學(xué)習(xí)和深度學(xué)習(xí)模型的開放格式。它使您能夠?qū)?TensorFlow 、 PyTorch 、 MATLAB 、 Caffe 和 Keras 等不同框架中的深度學(xué)習(xí)和機(jī)器學(xué)習(xí)模型轉(zhuǎn)換為單一的統(tǒng)一格式。
轉(zhuǎn)換為 ONNX
對(duì)于 T5 型號(hào),使用實(shí)用功能分別轉(zhuǎn)換編碼器和解碼器。

轉(zhuǎn)換為 TensorRT
現(xiàn)在,您已經(jīng)準(zhǔn)備好解析 T5 ONNX 編碼器和解碼器,并將它們轉(zhuǎn)換為優(yōu)化的 TensorRT 引擎。由于 TensorRT 執(zhí)行了許多優(yōu)化,例如融合操作、消除轉(zhuǎn)置操作和內(nèi)核自動(dòng)調(diào)優(yōu),以在目標(biāo) GPU 體系結(jié)構(gòu)上找到性能最佳的內(nèi)核,因此此轉(zhuǎn)換過程可能需要一些時(shí)間。

使用 TensorRT 引擎進(jìn)行推理
最后,您現(xiàn)在有了一個(gè)針對(duì) T5 模型的優(yōu)化 TensorRT 引擎,可以進(jìn)行推斷。

類似地,對(duì)于 GPT-2 模型,您可以按照相同的過程生成 TensorRT 引擎。優(yōu)化的 TensorRT 引擎可作為 HuggingFace 推理工作流中原始 PyTorch 模型的插件替代品。
TensorRT transformer 優(yōu)化細(xì)節(jié)
基于轉(zhuǎn)換器的模型是 transformer 編碼器或解碼器塊的堆棧。編碼器(解碼器)塊具有相同的結(jié)構(gòu)和參數(shù)數(shù)量。 T5 由 transformer 編碼器和解碼器的堆棧組成,而 GPT-2 僅由 transformer 解碼器塊組成(圖 1 )。
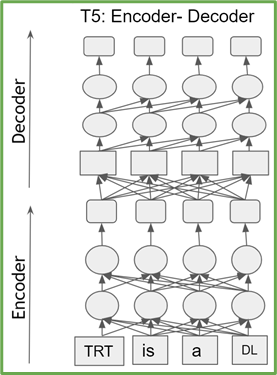
圖 1a 。 T5 架構(gòu)
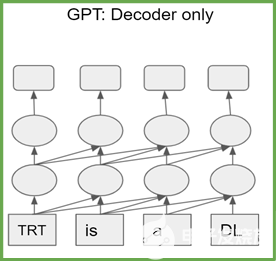
圖 1b 。 GPT-2 體系結(jié)構(gòu)
每個(gè) transformer 塊,也稱為自我注意塊,通過使用完全連接的層將輸入投影到三個(gè)不同的子空間,稱為查詢( Q )、鍵( K )和值( V ),由三個(gè)投影組成。然后將這些矩陣轉(zhuǎn)換為 QT和 KT用于計(jì)算標(biāo)準(zhǔn)化點(diǎn)積注意值,然后與 V 組合T生成最終輸出(圖 2 )。
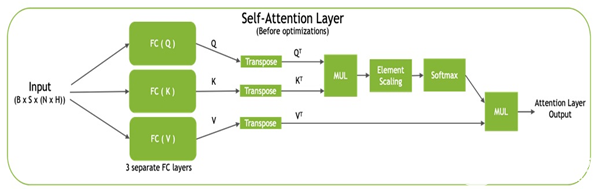
圖 2 。自我注意塊
TensorRT 通過逐點(diǎn)層融合優(yōu)化自我注意塊:
還原與電源操作相融合(用于圖層模板和剩余添加圖層)。
電子秤與 softmax 融合在一起。
GEMM 與 ReLU / GELU 激活融合。
此外, TensorRT 還優(yōu)化了推理網(wǎng)絡(luò):
消除轉(zhuǎn)置操作。
將三個(gè) KQV 投影融合為一個(gè) GEMM 。
當(dāng)指定 FP16 模式時(shí),控制逐層精度以保持精度,同時(shí)運(yùn)行 FP16 中計(jì)算最密集的運(yùn)算。
TensorRT 對(duì) PyTorch CPU 和 GPU 基準(zhǔn)
通過 TensorRT 進(jìn)行的優(yōu)化,我們看到 PyTorch GPU 推理的加速比高達(dá) 3-6 倍,而 PyTorch CPU 推理的加速比高達(dá) 9-21 倍。
圖 3 顯示了批量為 1 的 T5-3B 模型的推理結(jié)果,該模型用于將短短語從英語翻譯成德語。 A100 GPU 上的 TensorRT 引擎與在雙插槽 Intel Platinum 8380 CPU 上運(yùn)行的 PyTorch 相比,延遲減少了 21 倍。
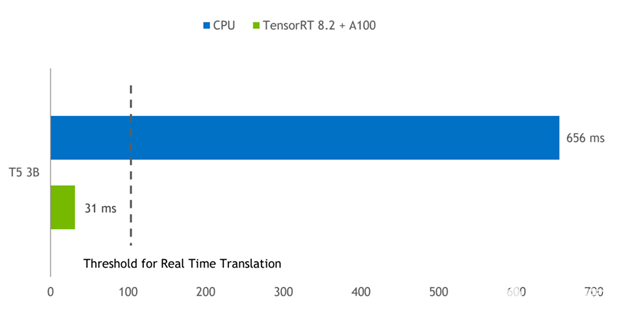
圖 3 。 A100 GPU 上的 T5-3B 模型推斷比較 TensorRT 提供的延遲比 PyTorch CPU 推斷小 21 倍。
CPU :英特爾白金 8380 , 2 個(gè)插槽。
GPU:NVIDIA A100 PCI Express 80GB 。軟件: PyTorch 1.9 , TensorRT 8.2.0 EA 。
任務(wù):“將英語翻譯成德語:這很好。”
結(jié)論
在這篇文章中,我們向您介紹了如何將擁抱臉 PyTorch T5 和 GPT-2 模型轉(zhuǎn)換為優(yōu)化的 TensorRT 推理引擎。 TensorRT 推理機(jī)用作原始 HuggingFace T5 和 GPT-2 PyTorch 模型的替代品,可提供高達(dá) 21x CPU 的推理加速比。要為您的模型實(shí)現(xiàn)此加速,從 TensorRT 8.2 開始今天的學(xué)習(xí).
關(guān)于作者
About Vinh Nguyen是一位深度學(xué)習(xí)的工程師和數(shù)據(jù)科學(xué)家,發(fā)表了 50 多篇科學(xué)文章,引文超過 2500 篇。在 NVIDIA ,他的工作涉及廣泛的深度學(xué)習(xí)和人工智能應(yīng)用,包括語音、語言和視覺處理以及推薦系統(tǒng)。
About Nikhil Srihari是 NVIDIA 的深入學(xué)習(xí)軟件技術(shù)營銷工程師。他在自然語言處理、計(jì)算機(jī)視覺和語音處理領(lǐng)域擁有廣泛的深度學(xué)習(xí)和機(jī)器學(xué)習(xí)應(yīng)用經(jīng)驗(yàn)。 Nikhil 曾在富達(dá)投資公司和 Amazon 工作。他的教育背景包括布法羅大學(xué)的計(jì)算機(jī)科學(xué)碩士學(xué)位和印度蘇拉斯卡爾卡納塔克邦國家理工學(xué)院的學(xué)士學(xué)位。
About Parth Chadha是 NVIDIA 的深度學(xué)習(xí)軟件工程師。他在 TensorRT 上工作,這是一個(gè)高性能的深度學(xué)習(xí)推理 SDK 。 Parth 在卡內(nèi)基梅隆大學(xué)獲得電氣和計(jì)算機(jī)工程碩士學(xué)位,主要研究機(jī)器學(xué)習(xí)和并行計(jì)算機(jī)體系結(jié)構(gòu)。
About Charles Chen20 歲時(shí)在加州大學(xué)圣地亞哥分校獲得計(jì)算機(jī)科學(xué)碩士學(xué)位后, Charles Chen 專注于為尖端人工智能框架、發(fā)展中國家的計(jì)算機(jī)教育和人機(jī)交互做出貢獻(xiàn)。在 NVIDIA , Charles 是一名深度學(xué)習(xí)軟件工程師,致力于 TensorRT ,一款高性能的深度學(xué)習(xí)推理 SDK 。
About Joohoon Lee領(lǐng)導(dǎo) NVIDIA 的汽車深度學(xué)習(xí)解決方案架構(gòu)師團(tuán)隊(duì)。他專注于將深度學(xué)習(xí)研究轉(zhuǎn)化為用于生產(chǎn)部署的真實(shí)世界自主駕駛軟件。他的團(tuán)隊(duì)使汽車客戶能夠使用英偉達(dá)驅(qū)動(dòng)平臺(tái)進(jìn)行 DNN 培訓(xùn)、微調(diào)、優(yōu)化和部署。在加入 NVIDIA 之前,他曾擔(dān)任 GPU 軟件架構(gòu)師,負(fù)責(zé)加速 DNN 算法。 Joohoon 在卡內(nèi)基梅隆大學(xué)獲得電氣和計(jì)算機(jī)工程學(xué)士和碩士學(xué)位。
About Jay Rodge是 NVIDIA 的產(chǎn)品營銷經(jīng)理,負(fù)責(zé)深入學(xué)習(xí)和推理產(chǎn)品,推動(dòng)產(chǎn)品發(fā)布和產(chǎn)品營銷計(jì)劃。杰伊在芝加哥伊利諾伊理工學(xué)院獲得計(jì)算機(jī)科學(xué)碩士學(xué)位,主攻計(jì)算機(jī)視覺和自然語言處理。在 NVIDIA 之前,杰伊是寶馬集團(tuán)的人工智能研究實(shí)習(xí)生,為寶馬最大的制造廠使用計(jì)算機(jī)視覺解決問題。
審核編輯:郭婷
-
cpu
+關(guān)注
關(guān)注
68文章
10826瀏覽量
211160 -
NVIDIA
+關(guān)注
關(guān)注
14文章
4940瀏覽量
102818
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
瑞薩RA-T系列芯片ADC和GPT功能模塊的配合使用

使用NVIDIA TensorRT提升Llama 3.2性能
TensorRT-LLM低精度推理優(yōu)化

NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓(xùn)練數(shù)據(jù)

魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
寶塔面板Docker一鍵安裝:部署GPTAcademic,開發(fā)私有GPT學(xué)術(shù)優(yōu)化工具
OpenAI CEO: GPT-4o and GPT-5引領(lǐng)未來12個(gè)月編程領(lǐng)域,GPT-5更具潛力
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
奇瑞捷途T5山海版首展,續(xù)航1400km預(yù)計(jì)明年上市
Bota Systems推出一款新型力扭矩傳感器SensONE T5
OpenAI預(yù)計(jì)最快今年夏天發(fā)布GPT-5
極狐阿爾法T5限時(shí)優(yōu)惠2.5萬元,起售價(jià)13.08萬元
Google Gemma優(yōu)化后可在NVIDIA GPU上運(yùn)行
TensorRT LLM加速Gemma!NVIDIA與谷歌牽手,RTX助推AI聊天
Torch TensorRT是一個(gè)優(yōu)化PyTorch模型推理性能的工具






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論