 NVIDIA Jetson Nano 2GB:視覺類腳本的環境配置與映射
NVIDIA Jetson Nano 2GB:視覺類腳本的環境配置與映射
在 TAO 提供的數據類范例中,每個腳本的第一個步驟都是環境配置(0. Set up env variables and map drives),包括要求用戶提供在 NGC 所生成的密鑰,對后面訓練的模型進行保護,以及指定要使用的 GPU 數量等等,這幾個設定都很直觀容易處理,但接下去的環境變量配置部分,就讓大部分初學者停滯不前,因為任何一項路徑配置錯誤,都會影響后面工作的正常進行,而每個實驗腳本所提供的說明,對初學者來的幫助并不大,很多新手按照其字面解釋去進行設定,但總是沒法調整到完全正確。
因此我們必須在大家執行實驗之前,先以專文將這部分的配置說明清楚,然后提供一個最簡單的步驟,讓大家用最輕松的方法來進行配置。
本文使用范例的 detectnet_v2.ipynb 做示范,首先看一下第一指令塊中的設定內容:
[ ] import os%env KEY=tlt_encode%env NUM_GPUS=1%env USER_EXPERIMENT_DIR=/workspace/tao-experiments/detectnet_v2%env DATA_DOWNLOAD_DIR=/workspace/tao-experiments/data# %env NOTEBOOK_ROOT=~/tao-samples/detectnet_v2os.environ["LOCAL_PROJECT_DIR"] = FIXMEos.environ["LOCAL_DATA_DIR"] = os.path.join(os.getenv("LOCAL_PROJECT_DIR", os.getcwd()),"data")os.environ["LOCAL_EXPERIMENT_DIR"] = os.path.join(os.getenv("LOCAL_PROJECT_DIR", os.getcwd()),"detectnet_v2")# The sample spec files are present in the same path as the downloaded samples.os.environ["LOCAL_SPECS_DIR"] = os.path.join(os.getenv("NOTEBOOK_ROOT", os.getcwd()),"specs")%env SPECS_DIR=/workspace/tao-experiments/detectnet_v2/specs
稍微整理一下,除了KEY與 NUM_GPUS 兩個變量之外,共有7個與路徑有關的變量:
-
USER_EXPERIMENT_DIR
-
DATA_DOWNLOAD_DIR
-
LOCAL_PROJECT_DIR
-
LOCAL_DATA_DIR
-
LOCAL_EXPERIMENT_DIR
-
LOCAL_SPECS_DIR
-
SPECS_DIR
其實稍微整理一下就更容易理解,下表就是將這7個變量分為兩組,以 “LOCAL_” 開頭的屬于 “容器外” 用途,另外 3 個屬于容器內用途。
|
用途 |
容器外(主機上) |
容器內(沿用TLT的習慣) |
|
項目工作位置 |
LOCAL_PROJECT_DIR |
|
|
存放模型訓練輸出結果 |
LOCAL_EXPERIMENT_DIR |
USER_EXPERIMENT_DIR |
|
存放數據集的路徑 |
LOCAL_DATA_DIR |
DATA_DOWNLOAD_DIR |
|
配置文件存放路徑 |
LOCAL_SPECS_DIR |
SPECS_DIR |
什么是容器內與容器外?前面提過 TAO 用兩套獨立的 Docker 容器,分別為視覺類與對話類提供模型訓練功能,并透過 TAO 啟動器的 CLI 指令執行各項任務。
雖然我們所有操作都在容器外的宿主機上,例如在指令終端下達 “tao detectnet_v2 train ...”,或者在 Jupyter 交互環境里執行 “!taodetectnet_v2 train ...” 指令,但是 TAO 啟動器會將這些指令傳遞到容器,在后臺為我們執行對應的任務。
這種處理方式的最大好處是,讓不懂 Docker 的初學者完全無需理會容器技術,只要專注于 “模型訓練” 的重點工作就行,如此就能讓 TAO 的普及程度更快與更廣,這也是 TAO 工具的一項非常重要意義。
但為何需要使用兩套路徑來處理呢?全部都在容器內執行不是更加簡單?這里有個最嚴肅的問題是 “容器的生命周期” ,如果將數據保留在容器內處理的話,一旦容器關閉或銷毀時,我們所有實驗數據都將付之一炬,這是一項大家都承擔不起的風險,因此我們必須將所有的數據存放在容器外面,然后透過路徑映射 (mapping) 的方式來處理。
其次就是對于數據整理與文件修改的能力,在容器內操作是相對不方便的。要知道在執行模型訓練之前,通常得先下載數據集的壓縮文件、移動文件、進行解壓縮、修改配置文件等等,這些任務在宿主機上操作是相對輕松的。
好了,當我們清楚 TAO 的視覺類模型訓練腳本中,存在容器內與容器外兩組環境路徑的原因之后,接著就來看該如何設置與映射。
我們將前面的列表進行展開,前面 4 個是容器外的變量、后面 3 個是容器內變量:
|
環境變量 |
設定值 |
|
LOCAL_PROJECT_DIR |
需要設置 |
|
LOCAL_EXPERIMENT_DIR |
$LOCAL_PROJECT_DIR/<項目名> |
|
LOCAL_DATA_DIR |
$LOCAL_PROJECT_DIR/data |
|
LOCAL_SPECS_DIR |
<執行腳本所在目錄>/specs |
|
USER_EXPERIMENT_DIR |
/workspace/tao-experiments/<項目名> |
|
DATA_DOWNLOAD_DIR |
/workspace/tao-experiments/data |
|
SPECS_DIR |
/workspace/tao-experiments/<項目名>/specs |
假如在執行格內的變量按照上表的順序去排列,事情就會變得非常單純。
事實上,從頭到尾我們只要將 “LOCAL_PROJECT_DIR” 設置為”執行腳本所在目錄”,那么后面三個容器外變量就立即建立好對應關系,我們完全不需要做任何處理理會。至于容器內的三個變量,每個腳本的配置規則都是一樣,也就是不需要去改變。
把上面的對應關系了解清楚之后,整個狀況就變得非常簡單,現在回頭看看第一個指令塊,里面需要輸入的變量其實只有以下三個:
-
%env KEY= <自己在NGC上申請的秘鑰>
-
%env NUM_GPUS= <根據設備配置,給定調用的GPU數量>
-
os.environ["LOCAL_PROJECT_DIR"] = os.getcwd()
其他 6 個變量完全不做任何修改,這樣就能夠順暢地跑動后面的指令塊。
接下去的工作就是執行 “路徑映射” 任務,為容器內外的路徑建立對應的關系。幾乎所有訓練腳本都采用下面的映射方式:
[ ] # Define the dictionary with the mapped drivesdrive_map = {"Mounts": [# Mapping the data directory{"source": os.environ["LOCAL_PROJECT_DIR"],"destination": "/workspace/tao-experiments"},# Mapping the specs directory.{"source": os.environ["LOCAL_SPECS_DIR"],"destination": os.environ["SPECS_DIR"]},]}
執行這個路徑映射的指令塊之后,會將這些值寫入 “~/.tao_mounts.json” 文件里面,這是 TAO 啟動器每次調用容器時都需要參考的配置文件,但是這個文件是 “唯一” 的,也就是同一時間只會存在一組容器內外的路徑映射關系,這表示系統不能同時執行兩個以上的模型訓練腳本,這點也請務必牢記。
緊跟著的 “1.Install the TAO launcher” 步驟可以直接跳過,因為我們在前面已經帶著大家安裝好 TAO 啟動器,這里頂多執行 “!taoinfo” 指令,確認一下是否回應正確訊息。
現在就可以開始進行 TAO 所提供的各種神經網絡的模型訓練腳本。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
NVIDIA
+關注
關注
14文章
4949瀏覽量
102829 -
變量
+關注
關注
0文章
613瀏覽量
28334
原文標題:NVIDIA Jetson Nano 2GB 系列文章(57):視覺類腳本的環境配置與映射
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
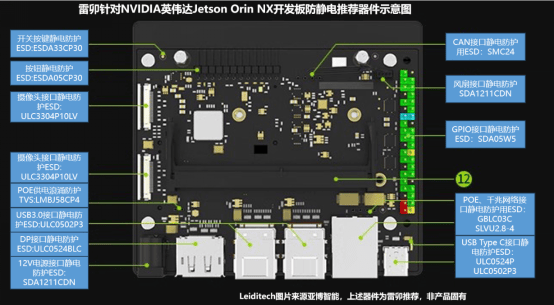
雷卯針對NVIDIA英偉達JETSON Orin NX開發板防靜電推薦器件示意圖
初創公司借助NVIDIA Metropolis和Jetson提高生產線效率
Made with KiCad(二):Jetson Origin Baseboard

使用NVIDIA Jetson打造機器人導盲犬
e絡盟發售功能強大的入門級 Raspberry Pi 5 2GB

使用myAGV、Jetson Nano主板和3D攝像頭,實現了RTAB-Map的三維建圖功能!

Nvidia Jetson Nano + CYW55573/AWXB327MA-PUR M.2無法使用操作系統內置的網絡管理器管理Wi-Fi如何解決?
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
NVIDIA推出搭載GB200 Grace Blackwell超級芯片的NVIDIA DGX SuperPOD?
為什么低端獨立顯卡通常都標配2GB的顯存?
FPGA模擬MIPI相機接入Jetson方案
使用 NVIDIA Isaac 仿真并定位 Husky 機器人





 工商網監
工商網監
評論