 如何在GPU上使用TensorRT部署深度學習應用程序
如何在GPU上使用TensorRT部署深度學習應用程序
NVIDIA TensorRT 是一個用于深度學習推理的 SDK 。 TensorRT 提供 api 和解析器來從所有主要的深度學習框架中導入經過訓練的模型。然后生成可部署在數據中心、汽車和嵌入式環境中的優化運行時引擎。
這篇文章簡單介紹了如何使用 TensorRT 。您將學習如何在 GPU 上部署深度學習應用程序,從而提高吞吐量并減少推理過程中的延遲。它使用 C ++示例來將您通過將 PyTorch 模型轉換成 ONX 模型并將其導入 TensorRT ,應用優化,并為數據中心環境生成高性能運行時引擎。
TensorRT 支持 C ++和 Python ;如果使用了兩者,工作流討論可能是有用的。如果您喜歡使用 Pyth
深度學習應用于廣泛的應用,如自然語言處理、推薦系統、圖像和視頻分析。隨著越來越多的應用程序在生產中使用深度學習,對準確性和性能的要求導致了模型復雜性和規模的強勁增長。
安全關鍵型應用(如汽車)對深度學習模型的吞吐量和延遲提出了嚴格的要求。對于包括推薦系統在內的一些消費者應用程序也是如此。
TensorRT 旨在幫助這些用例部署深度學習。通過對每一個主要框架的支持, TensorRT 通過強大的優化、降低精度的使用和高效的內存使用,幫助以低延遲處理大量數據。
為了繼續這篇文章,您需要一臺具有 CUDA -TensorRT 功能的計算機,或者一個安裝了 GPUs 的云實例。在 Linux 上,最容易開始的地方是從 GPU 容器注冊表下載帶有 TensorRT 集成的 GPU – 加速的 PyTorch 集裝箱 。
示例應用程序使用來自 Kaggle 的 腦 MRI 分割數據 的輸入數據來執行推斷。
簡單 TensorRT 示例
以下是此示例應用程序的四個步驟:
將預訓練圖像分割 PyTorch 模型轉換為 ONNX 。
將 ONNX 模型導入到 TensorRT 中。
應用優化并生成引擎。
對 GPU 執行推理。
導入 ONNX 模型包括從磁盤上保存的文件加載它,并將其從其本機框架或格式轉換為 TensorRT 網絡。 盒子 是一個表示深度學習模型的標準,使其能夠在框架之間進行轉換。
許多框架,如 Caffe2 、 Chainer 、 CNTK 、 paddlate 、 PyTorch 和 MXNet 都支持 ONNX 格式。接下來,根據輸入模型、目標 GPU 平臺和其他指定的配置參數,構建優化的 TensorRT 引擎。最后一步是向 TensorRT 引擎提供輸入數據以執行推理。
應用程序在 TensorRT 中使用以下組件:
ONX parser : 將一個經過 PyTorch 訓練的模型轉換成 ONNX 格式作為輸入,并在 TensorRT 中填充一個網絡對象。
建設者: 使用 TensorRT 中的網絡并生成針對目標平臺優化的引擎。
發動機: 獲取輸入數據,執行推斷,并發出推斷輸出。
記錄器: 與生成器和引擎關聯,以在構建和推理階段捕獲錯誤、警告和其他信息。
將預訓練圖像分割 PyTorch 模型轉換為 ONNX
從 NGC 注冊表中的 PyTorch 集裝箱 開始,預先安裝框架和 CUDA 組件,準備就緒。成功安裝 PyTorch 容器后,運行以下命令下載運行此示例應用程序所需的所有內容(示例代碼、測試輸入數據和引用輸出)、更新依賴項,并使用提供的 makefile 編譯應用程序。
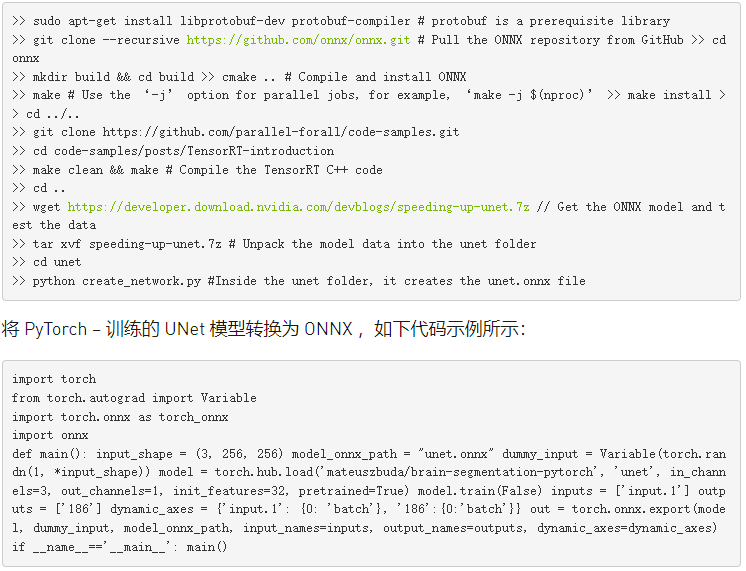
接下來,準備輸入數據以進行推斷。從 Kaggle 目錄下載所有圖像。將文件名中沒有_ mask 的任何三個映像復制到/ unet 目錄,然后實用工具。 py 來自 腦分割 -PyTorch 存儲庫的文件。準備三張圖片作為后面文章的輸入數據。準備輸入“ 0 ”。 pb 和輸出_ 0 。 pb 文件供以后使用,請運行以下代碼示例:
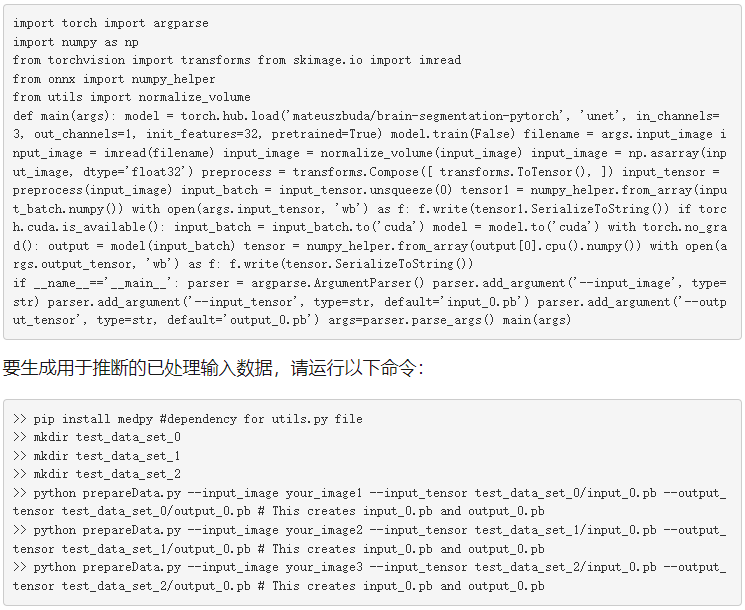
就這樣,輸入數據就可以進行推斷了。從應用程序的簡化版本 simpleONNX _ 1 。 cpp 開始并在此基礎上進行構建。后續版本可在同一文件夾 simpleonx _ 2 。 cpp 和 simpleonx 。 cpp 。
將 ONNX 模型導入到 TensorRT ,生成引擎并進行推理
使用經過訓練的模型和作為輸入傳遞的輸入數據運行示例應用程序。數據以 ONNX 協議文件的形式提供。示例應用程序將從 TensorRT 生成的輸出與同一文件夾中可用的 ONNX 。 pb 文件的參考值進行比較,并在提示符上總結結果。
導入 UNet ONNX 模型并生成引擎可能需要幾秒鐘的時間。它還生成便攜式灰度圖( PGM )格式的輸出圖像,如下所示:輸出。 pgm .
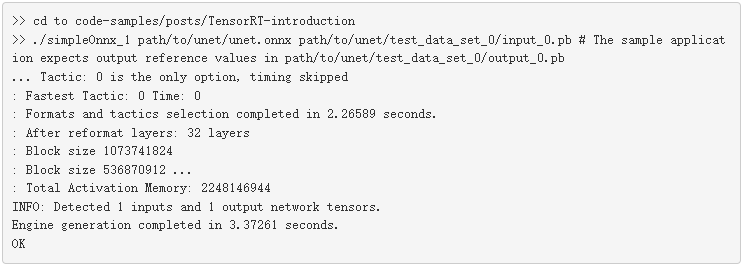
就這樣,你有一個用 TensorRT 優化并運行在你的 GPU 上的應用程序。圖 2 顯示了一個示例測試用例的輸出。
圖 2 :使用 TensorRT 對大腦 MRI 圖像進行推斷。
下面是前面示例應用程序中使用的幾個關鍵代碼示例。
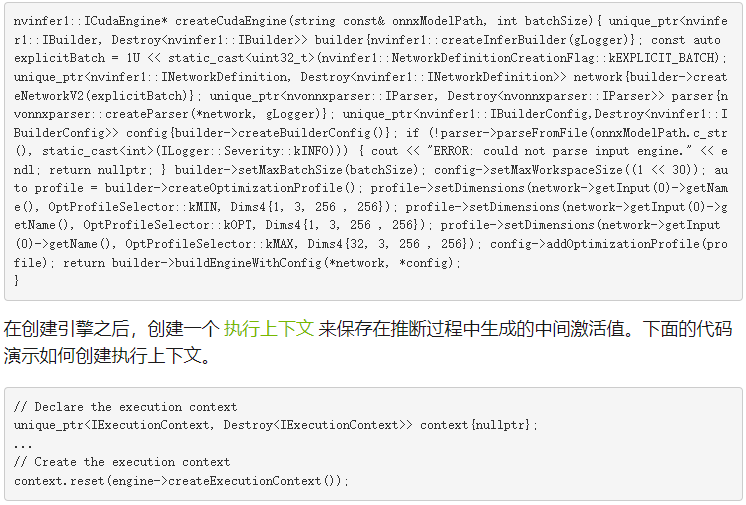
下面代碼示例中的 main 函數首先聲明一個 CUDA 引擎來保存網絡定義和經過訓練的參數。引擎是在 createCudaEngine 函數中生成的,該函數將指向 ONNX 模型的路徑作為輸入。

函數解析 ONNX 模型并將其保存在 createCudaEngine 對象中。要處理 U-Net 模型的輸入圖像和形狀張量的動態輸入尺寸,必須從 建設者 類創建一個優化配置文件,如下面的代碼示例所示。
優化配置文件 允許您設置外形的最佳輸入、最小和最大尺寸。構建器選擇一個內核,該內核將導致輸入張量維度的最低運行時間,并且對于最小和最大維度之間范圍內的所有輸入張量維度都有效。它還將網絡對象轉換為 TensorRT 引擎。
下面代碼示例中的 setMaxBatchSize 函數用于指定 TensorRT 引擎預期的最大批處理大小。 setMaxWorkspaceSize 函數允許您在引擎構建階段增加 GPU 內存占用。
此應用程序在下面的代碼示例所示的函數 launchInference 中異步地向 GPU 發送推理請求。輸入從主機( CPU )復制到 launchInference 內的設備( GPU ),然后使用 enqueue 函數執行推理,結果異步復制回來。
CUDA 使用異步流 GPU 管理流。異步推理執行通常通過重疊計算來提高性能,因為它最大化了 GPU 的利用率。 enqueue 函數將推理請求放在 CUDA 流上,并將批大小、指向輸入和輸出的指針以及用于內核執行的 CUDA 流作為輸入。使用 cudaMemcpyAsync 從主機到設備執行異步數據傳輸,反之亦然。

在調用 launchInference 之后使用 cudaStreamSynchronize 函數可以確保在訪問結果之前完成 GPU 計算。可以使用 ICUDA 發動機 類中的函數查詢輸入和輸出的數量以及每個輸入和輸出的值和維數。示例最后將參考輸出與 TensorRT 生成的推論進行比較,并將差異打印到提示。
批量輸入
此應用程序示例期望單個輸入,并在對其執行推理后返回輸出。實際應用通常是批量輸入,以獲得更高的性能和效率。一批形狀和大小相同的輸入可以在神經網絡的不同層上并行計算。
較大的批處理通常能夠更有效地使用 GPU 資源。例如,在 Volta 和 TuringGPUs 上,使用 32 倍倍數的批處理大小可能特別快速有效,因為 TensorRT 可以使用特殊的核來進行矩陣乘法和充分利用張量核的全連接層。
使用以下代碼在命令行上將圖像傳遞給應用程序。在本例中,作為輸入參數在命令行上傳遞的圖像(。 pb 文件)的數量決定了批處理的大小。使用 test _ data _ set _ x 從所有目錄獲取所有輸入的_ 0 。 pb 文件。下面的命令不是只讀取一個輸入,而是讀取文件夾中所有可用的輸入。
目前,下載的數據有三個輸入目錄,因此批處理大小為 3 。此版本的示例分析應用程序并將結果打印到提示符。有關更多信息,請參閱下一節,概要介紹應用程序。
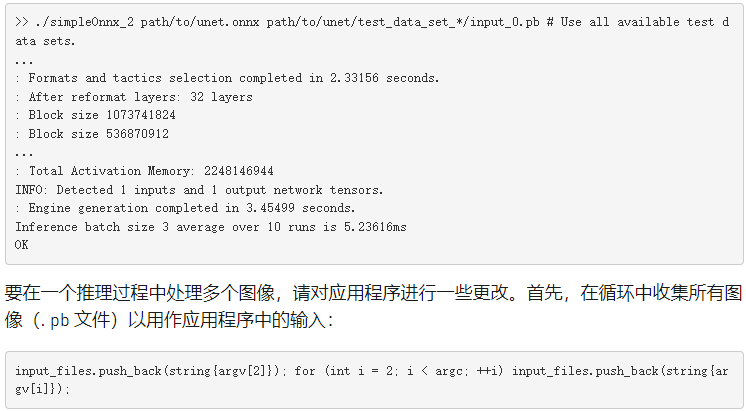
接下來,使用 setMaxBatchSize 函數指定 TensorRT 引擎預期的最大批處理大小。然后,構建器通過選擇在目標平臺上最大化其性能的算法來生成一個針對該批處理大小進行調整的引擎。雖然引擎不接受較大的批處理大小,但允許在運行時使用較小的批處理大小。
最大 值的選擇取決于應用程序以及任何給定時間的預期推理流量(例如,圖像的數量)。一個常見的做法是構建多個針對不同批量大小優化的引擎(使用不同的 最大 值),然后在運行時選擇最優化的引擎。
未指定時,默認批處理大小為 1 ,這意味著引擎不處理大于 1 的批大小。按以下代碼示例所示設置此參數:

分析應用程序
現在您已經看到了一個示例,下面是如何度量它的性能。網絡推理最簡單的性能度量是輸入到網絡和輸出返回之間經過的時間,稱為 延遲。
對于嵌入式平臺上的許多應用程序,延遲是至關重要的,而消費者應用程序需要服務質量。較低的延遲使這些應用程序更好。此示例使用 GPU 上的時間戳測量應用程序的平均延遲。在 CUDA 中有很多方法可以評測您的應用程序。有關詳細信息,請參見 如何在 CUDA C / C ++中實現性能度量 。
CUDA 為 創造 、 破壞 和 記錄 事件提供輕量級事件 API 函數,并計算它們之間的時間。應用程序可以在 CUDA 流中記錄事件,一個在啟動推理之前,另一個在推理完成后,如下面的代碼示例所示。
在某些情況下, MIG ht 關心在推理開始之前和推理完成之后在 GPU 和 CPU 之間傳輸數據所需的時間。有一些技術可以將數據預取到 GPU 中,也可以將計算與數據傳輸重疊,從而顯著地隱藏數據傳輸開銷。函數 cudaEventElapsedTime 測量在 CUDA 流中遇到這兩個事件之間的時間。
使用上一節開頭的代碼示例運行此示例并查看分析輸出。要評測應用程序,請將推理啟動包裝在 simpleONNX _ 2 。 cpp 中的函數 doInference 中。這個例子包括一個更新的函數調用。

許多應用程序對為脫機處理而積累和批處理的大量輸入數據執行推斷。每秒可能的最大推斷數被稱為 吞吐量 ,是這些應用程序的一個有價值的指標。
您可以通過為更大的特定批處理大小生成優化的引擎來測量吞吐量,運行推斷,并測量每秒可處理的批處理數。使用每秒的批數和批大小來計算每秒的推斷數,但這超出了本文的范圍。
優化應用程序
現在,您已經知道如何批量運行推理并分析應用程序,請對其進行優化。 TensorRT 的關鍵優勢在于其靈活性和技術的使用,包括混合精度、在所有 GPU 平臺上的高效優化,以及跨多種模型類型進行優化的能力。
在本節中,我們將介紹一些提高吞吐量和減少應用程序延遲的技術。有關詳細信息,請參見 TensorRT 性能最佳實踐 。
以下是一些常見的技巧:
使用混合精度計算
更改工作區大小
重新使用 TensorRT 引擎
使用混合精度計算
TensorRT 默認情況下使用 FP32 算法進行推理,以獲得最高的推理精度。但是,在許多情況下,可以使用 FP16 和 INT8 精度進行推理,對結果的準確性影響最小。
使用降低的精度來表示模型可以使您在內存中適合更大的模型,并在降低精度的數據傳輸要求較低的情況下實現更高的性能。您還可以將 FP32 和 FP16 精度中的計算與 TensorRT 混合使用,稱為混合精度,或者對權重、激活和執行層使用 INT8 量化精度。
對于支持快速 FP16 數學的設備,通過將 setFp16Mode 參數設置為 true 來啟用 FP16 內核。

setFp16Mode 參數向構建器表明,較低的計算精度是可以接受的。 TensorRT 如果 FP16 優化內核在所選配置和目標平臺上表現更好,則使用它們。
啟用此模式后,可以在 FP16 或 FP32 中指定權重,并自動轉換為計算所需的適當精度。您還可以靈活地為輸入和輸出張量指定 16 位浮點數據類型,這超出了本文的范圍。
更改工作區大小
TensorRT 允許您在引擎構建階段使用 setMaxWorkspaceSize 函數增加 GPU 內存占用。增加限制可能會影響同時共享 GPU 的應用程序的數量。將此限制設置得太低可能會過濾掉一些算法并創建一個次優引擎。 TensorRT 只分配所需的內存,即使在 IBuilder::setMaxWorkspaceSize 中設置的內存量要高得多。因此,應用程序應該允許 TensorRT 生成器盡可能多的工作空間。 TensorRT 分配不超過這個值,通常更少。
這個例子使用 1GB ,這讓 TensorRT 選擇任何可用的算法。

重新使用 TensorRT 引擎
構建引擎時, builder 對象為所選平臺和配置選擇最優化的內核。從網絡定義文件構建引擎可能非常耗時,并且不應在每次執行推斷時重復,除非模型、平臺或配置發生更改。
圖 3 顯示,您可以在生成后轉換引擎的格式,并將其存儲在磁盤上以供以后重用,稱為 序列化引擎 。反序列化發生在將引擎從磁盤加載到內存中并繼續使用它進行推理時。
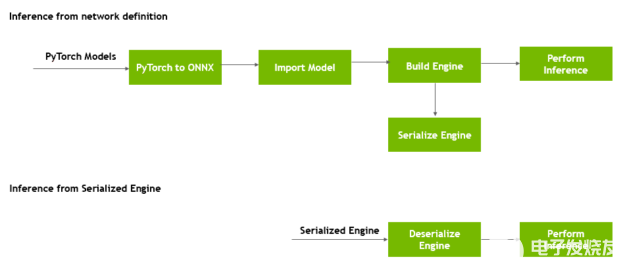
圖 3 。序列化和反序列化 TensorRT 引擎。
運行時對象反序列化引擎。
而不是每次都創建引擎, simpleonx 。 cpp 包含 getCudaEngine 函數來加載并使用引擎(如果存在)。如果引擎不可用,它將創建引擎并將其保存在當前目錄中,名稱為 unet _ batch4 。 engine 。在這個例子嘗試構建一個新引擎之前,如果當前目錄中有這個引擎,它會選擇它。
要強制使用更新的配置和參數構建新引擎,請在重新運行代碼示例之前,使用 makeclean _ engines 命令刪除存儲在磁盤上的所有現有序列化引擎。

將此保存的引擎用于不同的批處理大小。下面的代碼示例獲取輸入數據,與批處理大小變量重復相同的次數,然后將附加的輸入傳遞給示例。第一次運行創建引擎,第二次運行嘗試反序列化引擎。
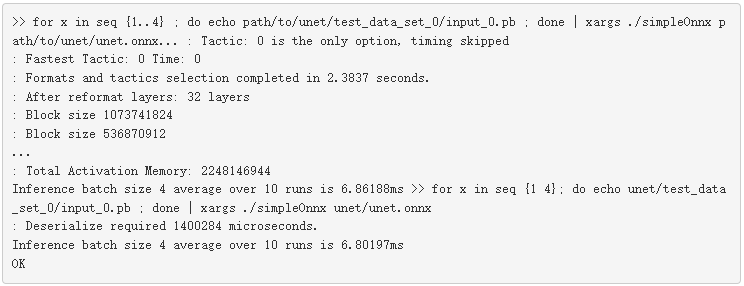
現在您已經了解了如何使用 TensorRT 加快簡單應用程序的推理速度。我們用 TensorRT 7 測量了 NVIDIA Titan VGPUs 的早期性能。
下一步行動
真實世界的應用程序有更高的計算需求,更大的深度學習模型,更多的數據處理需求,以及更嚴格的延遲限制。 TensorRT 為計算量大的深度學習應用程序提供了高性能的優化,是一個非常寶貴的推理工具。
希望這篇文章讓您熟悉了使用 TensorRT 獲得驚人性能所需的關鍵概念。這里有一些想法可以應用您所學的,使用其他模型,并通過更改本文中介紹的參數來探索設計和性能權衡的影響。
TensorRT 支持矩陣 為 TensorRT api 、解析器和層提供了受支持的特性和軟件。這個例子使用 C ++, TensorRT 同時提供 C ++和 Python API 。若要運行此帖子中包含的示例應用程序,請參見 TensorRT 開發者指南 中的 API 和 Python 和 C ++代碼示例。
使用參數 setFp16Mode 將模型的允許精度更改為 true / false ,并分析應用程序以查看性能差異。
更改運行時用于推斷的批處理大小,并查看這如何影響模型和數據集的性能(延遲、吞吐量)。
將 最大值 參數從 64 改為 4 ,可以看到在前五個內核中選擇了不同的內核。使用 Nprof 公司 查看分析結果中的內核。
本文未涉及的一個主題是在 TensorRT 中以 INT8 精度精確地執行推理。 TensorRT 自動轉換 FP32 網絡以進行部署,同時降低精度損失。為了實現這一目標, TensorRT 使用了一種校準過程,在用有限的 8 位整數表示來近似 FP32 網絡時,可以將信息損失最小化。有關詳細信息,請參見 基于 TensorRT 3 的自主車輛快速 INT8 推理 。
有許多資源可以幫助您加速圖像/視頻、語音應用程序和推薦系統的應用程序。這些工具從代碼示例、自行掌握進度的深度學習機構實驗室和教程到用于分析和調試應用程序的開發工具。
TensorRT 簡介 (網絡研討會)
TensorRT 最佳實踐指南
TensorRT 4 概述
TensorRT 4 的神經機器翻譯
使用 TensorRT 進行 8 位推理
使用 TensorRT 優化` NMT
關于作者
About Houman Abbasian是 NVIDIA 的高級深度學習軟件工程師。他一直致力于開發和生產 NVIDIA 在自動駕駛車輛中的深度學習解決方案,提高 DNN 的推理速度、精度和功耗,并實施和試驗改進 NVIDIA 汽車 DNN 的新思想。他在渥太華大學獲得計算機科學博士學位,專注于機器學習
About Josh Park是 NVIDIA 的汽車解決方案架構師經理。到目前為止,他一直在研究使用 DL 框架的深度學習解決方案,例如在 multi-GPUs /多節點服務器和嵌入式系統上的 TensorFlow 。此外,他一直在評估和改進各種 GPUs + x86 _ 64 / aarch64 的訓練和推理性能。他在韓國大學獲得理學學士和碩士學位,并在德克薩斯農工大學獲得計算機科學博士學位
About Siddharth Sharma是NVIDIA 加速計算的高級技術營銷經理。在加入NVIDIA 之前, Siddharth 是 Mathworks Simulink 和 Stateflow 的產品營銷經理,與汽車和航空航天公司密切合作,采用基于模型的設計來創建控制軟件。
About Sirisha Rella 是 NVIDIA 的技術產品營銷經理,專注于計算機視覺、語音和基于語言的深度學習應用。 Sirisha 獲得了密蘇里大學堪薩斯城分校的計算機科學碩士學位,是國家科學基金會大學習中心的研究生助理。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4939瀏覽量
102814 -
gpu
+關注
關注
28文章
4700瀏覽量
128698
發布評論請先 登錄
相關推薦
FPGA在深度學習應用中或將取代GPU
Mali GPU支持tensorflow或者caffe等深度學習模型嗎
如何在Raspberry Pi 3上構建機器學習應用程序
基于TensorRT完成NanoDet模型部署

如何使用框架訓練網絡加速深度學習推理

利用深度學習模型如何構建實時視頻AI應用程序
使用NVIDIA TensorRT部署實時深度學習應用程序
如何使用NVIDIA Docker部署GPU服務器應用程序
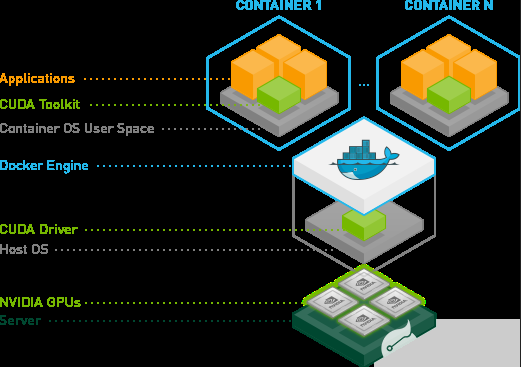
深度學習模型轉成TensorRT引擎的流程
何時使用機器學習或深度學習
學習資源 | NVIDIA TensorRT 全新教程上線

GPU在深度學習中的應用與優勢






 工商網監
工商網監
評論