 在動態環境中使用CUDA圖提高實際應用程序性能
在動態環境中使用CUDA圖提高實際應用程序性能
通過將計算密集型部件卸載到 GPU 上,可以大大加快許多工作負載。在 CUDA 術語中,這被稱為啟動內核。當這些內核很多且持續時間很短時,啟動開銷有時會成為一個問題。
CUDA Graphs提供了一種減少開銷的方法。圖形之所以有效,是因為它們將任意數量的異步 CUDA API 調用(包括內核啟動)組合到一個只需要一次啟動的操作中。它們在創建時確實會產生一些開銷,因此它們的最大好處來自多次重用。
在 ToolkitVersion10 中引入 CUDA 圖形時,可以對其進行更新,以反映其實例化中的一些細微變化。此后,此類更新操作的覆蓋范圍和效率顯著提高。在這篇文章中,我描述了一些通過使用 CUDA 圖來提高實際應用程序性能的場景,其中一些場景包括圖更新功能。
上下文
考慮一個應用程序,該函數具有啟動許多短運行內核的功能,例如:

如果每次遇到此函數時都以相同的方式執行,則可以使用流捕獲將其轉換為 CUDA 圖。在本例中,必須引入一個開關布爾值captured,以指示是否已經創建了圖形。將此開關的解除 Clara 操作和初始化放在源代碼中,使其范圍包括對函數tight_loop的每次調用。

接下來,用代碼包裝函數的任何實際調用,以創建對應的 CUDA 圖(如果它不存在),然后啟動該圖。

對 tight _循環函數的調用實際上并不執行任何內核啟動或其他 CUDA 操作。它只記錄所有這些操作并將它們存儲在數據結構中。
關注啟動內核的函數。在實際應用中,它看起來像以下代碼:

顯然,如果函數的參數在連續調用后發生變化,那么表示 GPU 內部工作的 CUDA 圖也應該發生變化。不能重復使用原始圖形。但是,假設多次遇到相同的函數參數集,您至少可以通過兩種不同的方式來處理這種情況:保存和識別圖形或更新圖形。
保存并識別 CUDA 圖形
第一種方法從 C ++標準模板庫中引入容器來存儲參數集。每當您遇到一個新的參數集來唯一地定義函數tight_loop,請將它連同相應的可執行圖形一起添加到容器中。
當您遇到容器中已經存在的參數集時,啟動相應的 CUDA 圖形。假設在本例中,變量first、params.size和delta唯一地定義了tight_loop。這個三胞胎是鑰匙用于區分圖形。您可以在源代碼中定義它和要使用的容器,使其范圍包括對函數tight_loop的每次調用。

無論函數tight_loop出現在何處,都要用填充鍵的代碼將其包裝起來,并在容器中查找。如果找到鍵,代碼將啟動相應的可執行 CUDA 圖。否則,它將創建一個新圖形,將其添加到容器中,然后啟動它(圖 1 )。

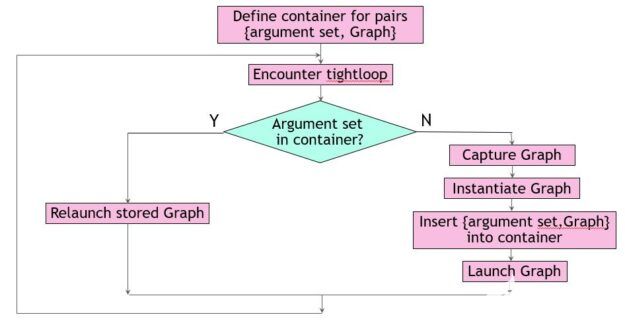
圖 1 。保存和識別圖形。
這種方法通常效果很好,但有一些固有的危險。在本例中,您確定只需要三個參數來定義容器中的鍵。對于不同的工作負載,這可能不同,或者另一個開發團隊成員可能會默默地向結構中添加字段MyStruct。這會影響非平凡函數cmpKeys的編寫方式。此函數是容器所必需的,用于確定某個密鑰是否比另一個密鑰小。
為 STL 容器編寫一個非平凡的比較函數通常并不困難,但當一個鍵由多個非平凡的實體組成時,可能會很乏味。一種普遍適用的方法是使用詞典比較。對于本例,以下代碼示例有效:

更新 CUDA 圖
請記住,要重用以前捕獲的可執行 CUDA 圖,它必須與調用上下文完全匹配:
相同拓撲
圖節點的數量和類型相同
圖節點之間的依賴關系相同
相同節點參數
但是,如果 CUDA 圖的拓撲結構保持不變,則可以調整它以使其符合新的需要。存在一種方便的機制來確認拓撲等價性,同時調整節點參數以返回修改后的可執行圖。它由cudaGraphExecUpdate提供,其工作原理是將現有的可執行圖與新派生的圖進行比較(例如,通過流捕獲方便地獲得)。如果可能,差異用于進行更改。
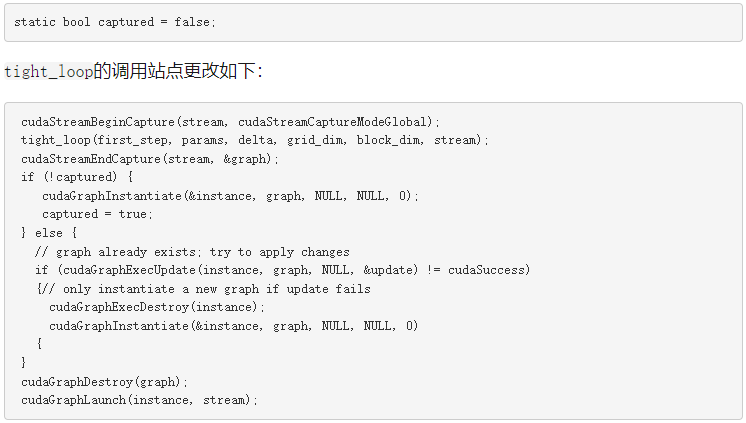
這種方法的好處是雙重的。首先,當更新足夠時,可以避免昂貴的新 CUDA 圖實例化。第二,你不必知道是什么讓圖形獨一無二。任何圖形比較都由 update 函數隱式執行。下面的代碼示例實現了此方法。與之前一樣,它從開關的解除 Clara 和初始化開始,以指示先前創建的圖形。
在這個場景中,您總是執行流捕獲來收集關于tight_loop中 CUDA 操作的信息。這是一個相對便宜的操作,完全在主機上執行,而不是 GPU 。它可以與以前的 CUDA 圖形啟動重疊,這些啟動本身就是異步操作(圖 2 )。
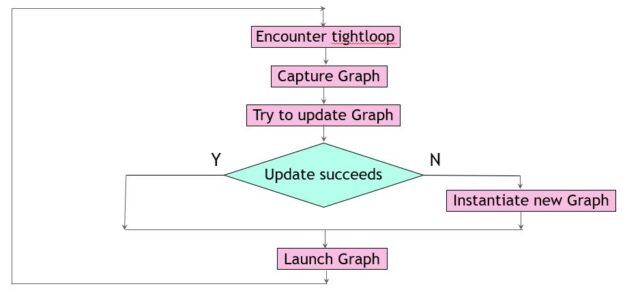
圖 2 。更新圖形
一句警告的話已經準備好了。cudaGraphExecUpdate的復雜性大致與 CUDA 圖形節點的更改數量成正比,因此如果大部分節點發生更改,則效率會降低。
后果
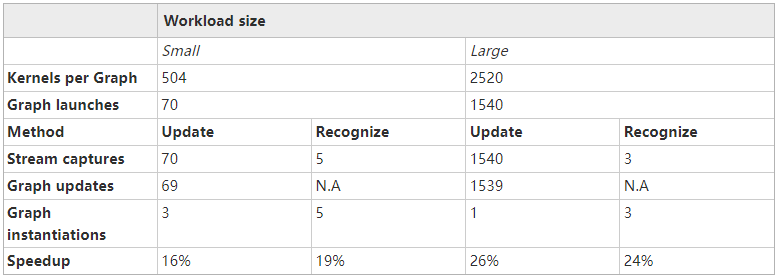
推動這兩種方法以靈活方式管理 CUDA 圖的應用程序有兩種不同的工作負載大小,但行為有所不同(表 1 )。所有涉及的內核在單個 NVIDIA A100 GPU 上執行需要 2 – 8 微秒。報告的加速是針對代碼中可以轉換為 CUDA 圖形的部分。
結論
具有許多小 CUDA 內核的應用程序通常可以使用 CUDA 圖進行加速,即使內核啟動模式在整個應用程序中發生變化。鑒于這種動態環境,最佳方法取決于應用程序的具體情況。希望您能發現本文中描述的兩個示例易于理解和實現。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4936瀏覽量
102812 -
gpu
+關注
關注
28文章
4700瀏覽量
128697
發布評論請先 登錄
相關推薦
XScale 應用程序性能的優化策略
快速識別應用程序性能瓶頸
DVFS對程序性能影響模型
使用Eclipse將Android應用程序添加本機x86架構中
了解CPI對分析程序性能的意義
如何通過多線程并發設計來提高應用程序的性能
LabVIEW應用程序中性能瓶頸的解決
如何使用CMake工具套件構建CUDA應用程序
使用CUDA流順序內存分配器助于提高現有應用程序的性能
在JavaScript中動態的創建QML對象
第6代光纖通道:加速全閃存數據中心的數據訪問和應用程序性能

使用Brocade Gen 7 SAN確保應用程序性能和可靠性





 工商網監
工商網監
評論