 NVIDIA Riva用于AI應用程序的GPU加速SDK
NVIDIA Riva用于AI應用程序的GPU加速SDK
語音人工智能用于各種應用,包括授權人工智能的呼叫中心、虛擬助理的語音接口以及視頻會議中的實時字幕。語音人工智能包括自動語音識別( ASR )和文本語音轉換( TTS )。 ASR 管道接收原始音頻并將其轉換為文本, TTS 管道接收文本并將其轉換為音頻。
開發和運行這些實時語音人工智能服務是一項復雜而艱巨的任務。構建語音 AI 應用程序需要數十萬小時的音頻數據、基于特定用例構建和自定義模型的工具,以及可擴展的部署支持。它還意味著實時運行,與用戶進行自然交互的時間遠低于 300 毫秒。 NVIDIA Riva 簡化了開發語音 AI 服務的端到端流程,并為類人交互提供實時性能。
Riva SDK
NVIDIA Riva 是用于開發語音 AI 應用程序的 GPU 加速 SDK 。 Riva 旨在幫助您輕松快速地訪問對話 AI 功能。只需幾個命令,您就可以通過 API 操作訪問高性能服務并嘗試演示。
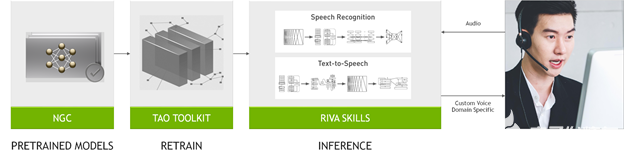
圖 1 . Riva 構建語音應用程序的工作流
Riva SDK 包括 pretrained speech and language models 、 NVIDIA TAO Toolkit ,用于在自定義數據集上微調這些模型,以及用于語音識別、語言理解和語音合成的優化端到端技能。
使用 Riva ,您可以輕松地對數據上的最新模型進行微調,以更深入地了解其特定上下文。優化推理以提供運行時間為 150 毫秒( ms )的實時服務,而在 CPU 純平臺上需要 25 秒。
特定于任務的 AI 服務和 gRPC 端點提供現成的高性能 ASR 、 NLP 和 TTS 。所有這些人工智能服務都經過數千小時的公共和內部數據集培訓,以達到高精度。您可以開始使用預訓練的模型,或者使用自己的數據集對其進行微調,以進一步提高模型性能。
Riva 使用 NVIDIA Triton Inference Server 為多個模型提供服務,以實現高效、穩健的資源分配,并在高吞吐量、低延遲和高精度方面實現高性能。
Riva 技能概述
Riva 為實時轉錄和虛擬助理等用例提供高度優化的語音識別和語音合成服務。語音識別技能在各種真實世界、特定領域的數據集上進行培訓和評估。它包括來自電信、播客和醫療保健的詞匯,以在生產用例中提供世界級的準確性。
與 NVIDIA V100 GPU 上的 Tacotron 2 和 WaveGlow 模型相比, Riva 文本到語音或語音合成技能可生成類似人類的語音,并使用非自回歸模型在 NVIDIA A100 GPU 上提供 12 倍的性能。此外,該服務使您能夠為每個品牌和虛擬助理創建一個自然定制的聲音,每天 30 分鐘的演員數據。
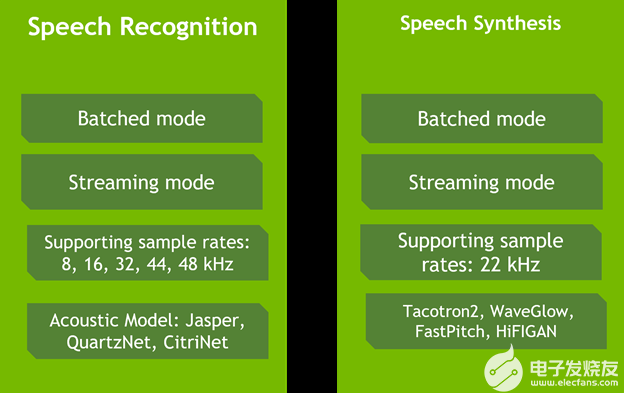
圖 2 . Riva 服務能力
為了充分利用 GPU 的計算能力, Riva 基于 NVIDIA Triton 推理服務器,為神經網絡和集成管道提供服務,以便與 NVIDIA TensorRT 高效運行。
Riva 服務通過 gRPC 端點可訪問的 API 操作公開,這些操作隱藏了所有復雜性。圖 3 顯示了系統的服務器端。 gRPC API 操作由運行在 Docker 容器中的 API 服務器公開。他們負責處理所有語音和 NLP 傳入和傳出數據。
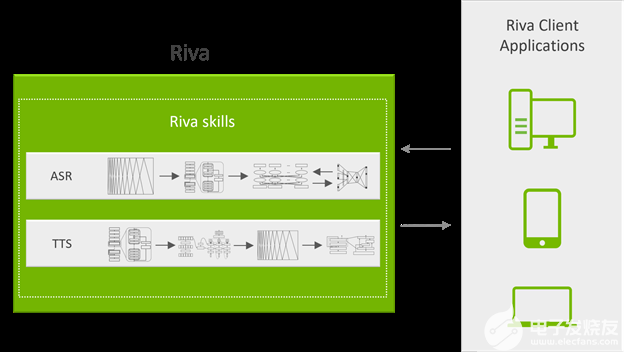
圖 3 . Riva 服務管線
API 服務器向 NVIDIA Triton 發送推斷請求并接收結果。
NVIDIA Triton 是后端服務器,可同時處理多個 GPU 上的多個神經網絡或集成管道的多個推理請求。
對于會話 AI 應用程序,將延遲保持在給定閾值以下至關重要。這種延遲要求轉化為推斷請求一到達就執行。要使 GPU 飽和并提高性能,必須增加批大小并延遲推理執行,直到收到更多請求并形成更大的批。
NVIDIA Triton 還負責在一個請求和另一個請求之間切換網絡的上下文。
Riva 可以通過從 NGC 下載適當的模型和容器的簡單腳本直接安裝在裸機上,也可以通過 Helm chart 將其部署在 Kubernetes 上。
下面簡要介紹一下如何與 Python 交互。 Riva 接口通過簡單的 Python API 操作,使客戶端與 Riva 服務器的通信更加容易。例如,下面介紹如何通過三個步驟創建對現有 TTS Riva 服務的請求。
首先,導入 Riva API :
import src.riva_proto.riva_tts_pb2 as rtts
import src.riva_proto.riva_tts_pb2_grpc as rtts_srv
import src.riva_proto.riva_audio_pb2 as ri
接下來,創建到 Riva 端點的 gRPC 通道:
channel = grpc.insecure_channel('localhost:50051')
riva_tts = rtts_srv.RivaSpeechSynthesisStub(channel)
然后,創建一個 TTS 請求:
req = rtts.SynthesizeSpeechRequest()
req.text = "We know what we are, but not what we may be?"
req.language_code = "en-US" req.encoding = ri.AudioEncoding.LINEAR_PCM req.sample_rate_hz = 22050 req.voice_name = "ljspeech" resp = riva_tts.Synthesize(req)
audio_samples = np.frombuffer(resp.audio, dtype=np.float32)
使用數據自定義模型
使用 NVIDIA TAO Toolkit ,您可以在 Riva 中使用定制的訓練模型(圖 4 )。 NVIDIA TAO Toolkit 是一種無編碼工具,用于在特定于域的數據集上微調模型。
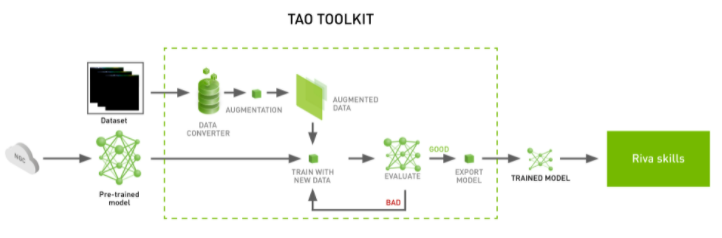
圖 4 。 NVIDIA TAO 工具包管道
例如,要進一步提高 ASR 轉錄文本的易讀性和準確性,請向 ASR 系統添加自定義標點符號和大小寫模型,以生成沒有這些特征的文本。
從預訓練的 BERT 模型開始,第一步是準備數據集。對于培訓數據集中的每個單詞,目標是預測以下內容:
單詞后面的標點符號。
這個詞是否應該大寫。
數據集準備就緒后,下一步是通過運行先前提供的腳本進行培訓。完成培訓并達到所需的最終精度后,使用附帶的腳本為 NVIDIA Triton 創建模型存儲庫。
NVIDIA Riva Speech Skills 文檔包含有關如何訓練或微調其他模型的更多詳細信息。這篇文章只展示了使用 TAO 工具包進行定制的眾多可能性中的一種。
在 Riva 中部署模型
Riva 是為大規模對話 AI 而設計的。為了幫助您在不同的服務器上高效、可靠地為模型提供服務, NVIDIA 使用 Helm 圖表提供了按鈕式模型部署(圖 5 )。
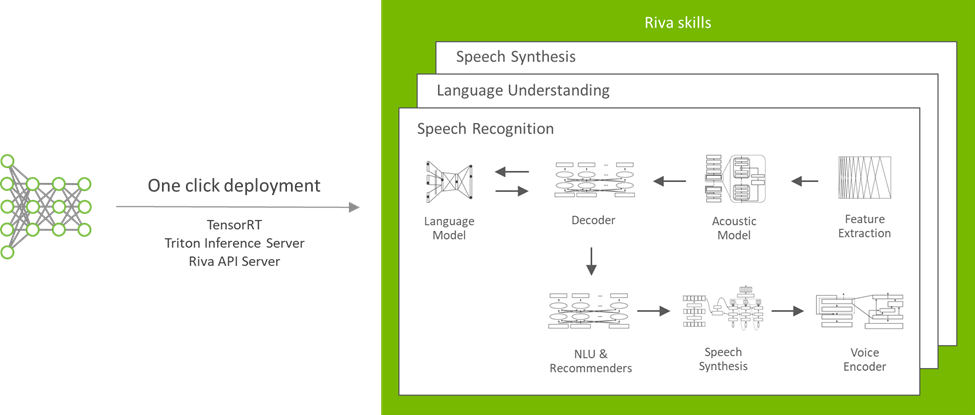
圖 5 。通過修改可用的舵圖,可以在 Riva 中部署模型
NGC catalog 中提供的舵圖配置可以針對自定義用例進行修改。您可以更改與要部署的模型、存儲它們的位置以及如何公開服務相關的設置。
結論
Riva 是 NVIDIA Developer Program 成員的公開測試版。對于您的實時轉錄、虛擬助理或自定義語音實現, Riva 將支持您的開發。如果您正在大規模部署, Riva Enterprise 將為您大規模部署,并包括 AI 專家的支持。
關于作者
Davide Onofrio 是 NVIDIA 的高級深度學習軟件技術營銷工程師。他在 NVIDIA 專注于深度學習技術開發人員關注內容的開發和演示。戴維德在生物特征識別、虛擬現實和汽車行業擔任計算機視覺和機器學習工程師已有多年經驗。他的教育背景包括米蘭理工學院的信號處理博士學位。
Vinh Nguyen 是一位深度學習的工程師和數據科學家,發表了 50 多篇科學文章,引文超過 2500 篇。在 NVIDIA ,他的工作涉及廣泛的深度學習和人工智能應用,包括語音、語言和視覺處理以及推薦系統。
Siddharth Sharma 是NVIDIA 加速計算的高級技術營銷經理。在加入NVIDIA 之前, Siddharth 是 Mathworks Simulink 和 Stateflow 的產品營銷經理,與汽車和航空航天公司密切合作,采用基于模型的設計來創建控制軟件。
Alex Qi 是英偉達 AI 軟件集團的產品經理。她的重點是對話 AI 框架( Riva )和多媒體流 AI / ML ( Maxine )的 AI 軟件和應用程序。在加入 NVIDIA 之前,她在領導技術和工程組織中各種角色的具有挑戰性的技術項目方面擁有豐富的經驗,如數據科學家、計算建模和設計工程。 Alex 擁有麻省理工學院的雙學位碩士學位:麻省理工學院斯隆管理學院的 MBA 學位,以及工程機械工程學院的理學碩士學位,她在該學院主要研究機器人技術和人工智能。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102826 -
服務器
+關注
關注
12文章
9029瀏覽量
85207 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237669
發布評論請先 登錄
相關推薦
NVIDIA AI正加速推進藥物研發
NVIDIA加速AI在日本各行各業的應用
日本企業借助NVIDIA產品加速AI創新
NVIDIA RTX AI套件簡化AI驅動的應用開發
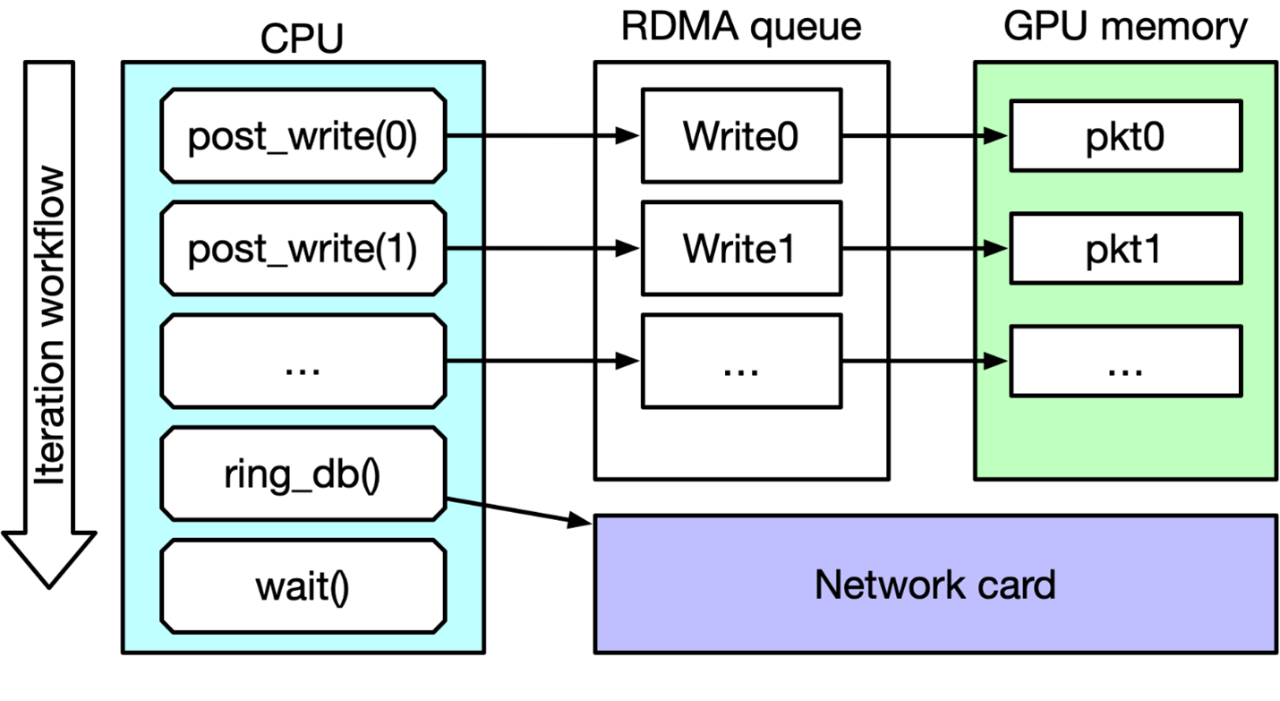
IB Verbs和NVIDIA DOCA GPUNetIO性能測試
HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
借助NVIDIA DOCA 2.7增強AI 云數據中心和NVIDIA Spectrum-X
NVIDIA發布DeepStream 7.0,助力下一代視覺AI開發
利用NVIDIA AI Enterprise IGX在邊緣賦能任務關鍵型AI
利用NVIDIA組件提升GPU推理的吞吐
NVIDIA數字人技術加速部署生成式AI驅動的游戲角色

NVIDIA 推出 Blackwell 架構 DGX SuperPOD,適用于萬億參數級的生成式 AI 超級計算

如何選擇NVIDIA GPU和虛擬化軟件的組合方案呢?






 工商網監
工商網監
評論