") 視覺(jué)語(yǔ)言預(yù)訓(xùn)練(VLP)模型的最新進(jìn)展
視覺(jué)語(yǔ)言預(yù)訓(xùn)練(VLP)模型的最新進(jìn)展
讓機(jī)器做出與人類(lèi)相似的反應(yīng)一直是 AI 研究不懈追求的目標(biāo)。為了讓機(jī)器具有感知和思考的能力,研究人員進(jìn)行了一系列相關(guān)研究,如人臉識(shí)別、閱讀理解和人機(jī)對(duì)話(huà),通過(guò)這些任務(wù)訓(xùn)練和評(píng)估機(jī)器在特定方面的智能。一般來(lái)講,領(lǐng)域?qū)<彝ㄟ^(guò)手工構(gòu)建標(biāo)準(zhǔn)數(shù)據(jù)集,然后在這些數(shù)據(jù)集上訓(xùn)練和評(píng)估相關(guān)模型。然而,由于相關(guān)技術(shù)的限制,訓(xùn)練模型往往需要大量的標(biāo)注數(shù)據(jù),以獲得更好、更強(qiáng)大的模型。
基于 Transformer 架構(gòu)的預(yù)訓(xùn)練模型緩解了這個(gè)問(wèn)題。它們首先通過(guò)自監(jiān)督學(xué)習(xí)進(jìn)行預(yù)訓(xùn)練,從大規(guī)模未標(biāo)記數(shù)據(jù)中訓(xùn)練模型,從而學(xué)習(xí)通用表示。它們?cè)谙掠稳蝿?wù)上僅使用少量手動(dòng)標(biāo)記的數(shù)據(jù)進(jìn)行微調(diào)就能取得令人驚訝的效果。自 BERT 被應(yīng)用于 NLP 任務(wù)以來(lái),各種預(yù)訓(xùn)練模型在單模態(tài)領(lǐng)域快速發(fā)展,例如 Vision Transformer (ViT) 和 Wave2Vec。大量工作表明它們有利于下游單模態(tài)任務(wù),并避免從頭開(kāi)始訓(xùn)練新模型。
與單模態(tài)領(lǐng)域類(lèi)似,多模態(tài)領(lǐng)域也存在高質(zhì)量標(biāo)注數(shù)據(jù)較少的問(wèn)題。我們不禁會(huì)問(wèn),上述預(yù)訓(xùn)練方法能否應(yīng)用于多模態(tài)任務(wù)?研究人員已經(jīng)對(duì)這個(gè)問(wèn)題進(jìn)行了探索并取得了重大進(jìn)展。
在本文中,來(lái)自中國(guó)科學(xué)院自動(dòng)化研究所、中國(guó)科學(xué)院大學(xué)的研究者調(diào)查了視覺(jué) - 語(yǔ)言預(yù)訓(xùn)練(vision-language pre-training,VLP)最新進(jìn)展和新領(lǐng)域,包括圖像 - 文本預(yù)訓(xùn)練和視頻 - 文本預(yù)訓(xùn)練。VLP 通過(guò)對(duì)大規(guī)模數(shù)據(jù)的預(yù)訓(xùn)練來(lái)學(xué)習(xí)不同模態(tài)之間語(yǔ)義對(duì)應(yīng)關(guān)系。例如,在圖像 - 文本預(yù)訓(xùn)練中,研究者期望模型將文本中的狗與圖像中的狗外觀(guān)相關(guān)聯(lián)。在視頻 - 文本預(yù)訓(xùn)練中,研究者期望模型將文本中的對(duì)象 / 動(dòng)作映射到視頻中的對(duì)象 / 動(dòng)作。

為了實(shí)現(xiàn)這一目標(biāo),研究者需要巧妙地設(shè)計(jì) VLP 對(duì)象和模型架構(gòu),以允許模型挖掘不同模態(tài)之間的關(guān)聯(lián)。
為了讓讀者更好地全面掌握 VLP,該研究首先從特征提取、模型架構(gòu)、預(yù)訓(xùn)練目標(biāo)、預(yù)訓(xùn)練數(shù)據(jù)集和下游任務(wù)五個(gè)方面回顧其最近進(jìn)展。然后,文章詳細(xì)總結(jié)了具體的 VLP 模型。最后,文章討論了 VLP 的新領(lǐng)域。據(jù)了解,這是對(duì) VLP 領(lǐng)域的首次調(diào)查。研究者希望這項(xiàng)調(diào)查能夠?yàn)?VLP 領(lǐng)域的未來(lái)研究提供啟示。
VLP 綜述
VLP 五個(gè)方面回顧及其最近進(jìn)展
在特征處理方面:論文主要介紹了 VLP 模型如何進(jìn)行預(yù)處理和表示圖像、視頻和文本以獲得對(duì)應(yīng)特征。
為了充分利用單模態(tài)預(yù)訓(xùn)練模型,VLP 隨機(jī)初始化標(biāo)準(zhǔn) transformer 編碼器來(lái)生成視覺(jué)或文本表示。從視覺(jué)來(lái)講,VLP 利用預(yù)訓(xùn)練視覺(jué) transformer(例如 ViT 和 DeiT)對(duì) ViT-PF 進(jìn)行編碼。從文本來(lái)講,VLP 使用預(yù)訓(xùn)練文本 transformer(例如 BERT)對(duì)文本特征進(jìn)行編碼。為簡(jiǎn)單起見(jiàn),該研究將這些 transformer 命名為 Xformer。
在模型架構(gòu)方面:論文從兩個(gè)不同的角度介紹 VLP 模型架構(gòu):(1)從多模態(tài)融合的角度來(lái)觀(guān)察單流與雙流架構(gòu)(2)從整體架構(gòu)設(shè)計(jì)來(lái)比較編碼器以及編碼器 - 解碼器對(duì)比。
單流架構(gòu)是指將文本和視覺(jué)特征組合在一起,然后饋入單個(gè) transformer 塊,如下圖 1 (a) 所示。單流架構(gòu)通過(guò)合并注意力來(lái)融合多模態(tài)輸入。單流架構(gòu)的參數(shù)效率更高,因?yàn)閮煞N模式都使用相同的參數(shù)集。
雙流架構(gòu)是指文本和視覺(jué)特征沒(méi)有組合在一起,而是獨(dú)立饋入到兩個(gè)不同的 transformer 塊,如圖 1 (b) 所示。這兩個(gè) transformer 塊不共享參數(shù)。為了獲得更高的性能,交叉注意力(如 圖 1 (b) 中的虛線(xiàn)所示)用于實(shí)現(xiàn)跨模態(tài)交互。為了實(shí)現(xiàn)更高的效率,視覺(jué) transformer 塊和文本 transformer 塊之間也可以不采用交叉注意力。
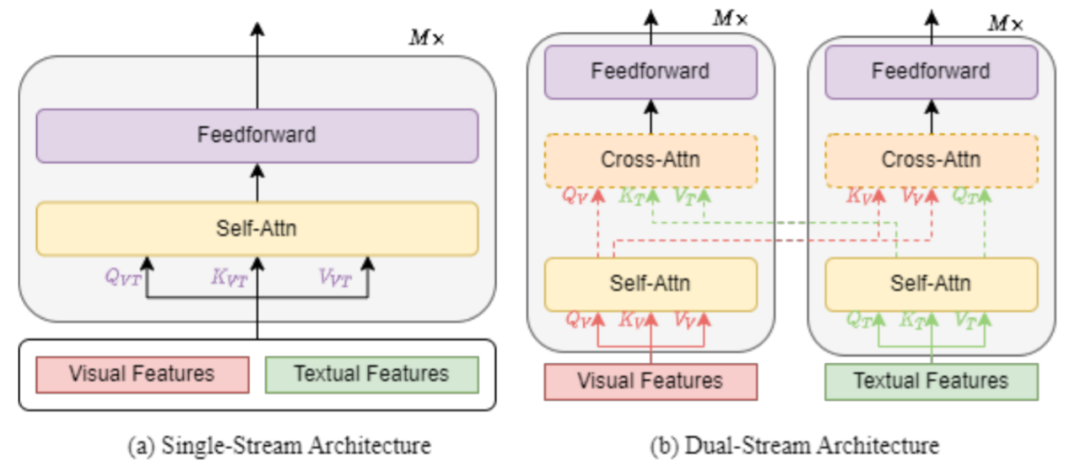
許多 VLP 模型只采用編碼器架構(gòu),不同模態(tài)表示直接饋入輸出層。相比之下,其他 VLP 模型提倡使用 transformer 編碼器 - 解碼器架構(gòu),不同模態(tài)表示首先饋入解碼器,然后饋入輸出層。
在預(yù)訓(xùn)練目標(biāo)方面:論文通過(guò)使用不同的預(yù)訓(xùn)練目標(biāo)來(lái)預(yù)訓(xùn)練 VLP 模型,并將預(yù)訓(xùn)練目標(biāo)總結(jié)為四類(lèi):完成、匹配、時(shí)間和特定類(lèi)型。
完成(completion)指的是利用未掩碼部分來(lái)重建掩碼元素。以掩碼語(yǔ)言建模 (MLM) 為例,其最早由 taylor 提出,由于 BERT 將其作為預(yù)訓(xùn)練任務(wù)而廣為人知。VLP 模型中的 MLM 類(lèi)似于預(yù)訓(xùn)練語(yǔ)言模型 (PLM) 中的 MLM,它不僅可以通過(guò)其余文本 token 來(lái)預(yù)測(cè)掩碼文本 token,還可以通過(guò)視覺(jué) token 來(lái)預(yù)測(cè)掩碼文本 token。根據(jù)經(jīng)驗(yàn),遵循 BERT 的 VLP 模型以 15% 的掩碼率隨機(jī)掩碼每個(gè)文本輸入 token,并在 80% 的時(shí)間使用特殊 token [MASK]、10% 的時(shí)間使用隨機(jī)文本 token,剩余 10% 的時(shí)間使用原始 token 來(lái)替換被掩碼掉的文本。不過(guò)在普林斯頓大學(xué)陳丹琦等人的論文《Should You Mask 15% in Masked Language Modeling?》中,作者發(fā)現(xiàn):在有效的預(yù)訓(xùn)練方案下,他們可以掩蔽 40-50% 的輸入文本,并獲得比默認(rèn)的 15% 更好的下游性能。
在掩碼視覺(jué)建模 (MVM) 中,與 MLM 一樣,MVM 對(duì)視覺(jué)(圖像或視頻)區(qū)域或 patch 進(jìn)行采樣,并且通常以 15% 的概率掩碼其視覺(jué)特征。VLP 模型需要在給定剩余的視覺(jué)特征和所有文本特征的情況下重建掩碼的視覺(jué)特征。
視覺(jué) - 語(yǔ)言匹配 (VLM) 是最常用的預(yù)訓(xùn)練目標(biāo),用于對(duì)齊視覺(jué)和語(yǔ)言。在單流 VLP 模型中,研究者使用特殊 token [CLS] 表示作為兩種模態(tài)的融合表示。在雙流 VLP 模型中,研究者將特殊視覺(jué) token [CLSV] 視覺(jué)表示和特殊文本 token [CLST] 文本表示連接起來(lái),作為兩種模態(tài)的融合表示。VLP 模型將兩種模態(tài)的融合表示提供給 FC 層和 sigmoid 函數(shù)以預(yù)測(cè) 0 到 1 之間的分?jǐn)?shù),其中 0 表示視覺(jué)和語(yǔ)言不匹配,1 表示視覺(jué)和語(yǔ)言匹配。在訓(xùn)練期間,VLP 模型在每一步從數(shù)據(jù)集中采樣正對(duì)或負(fù)對(duì)。
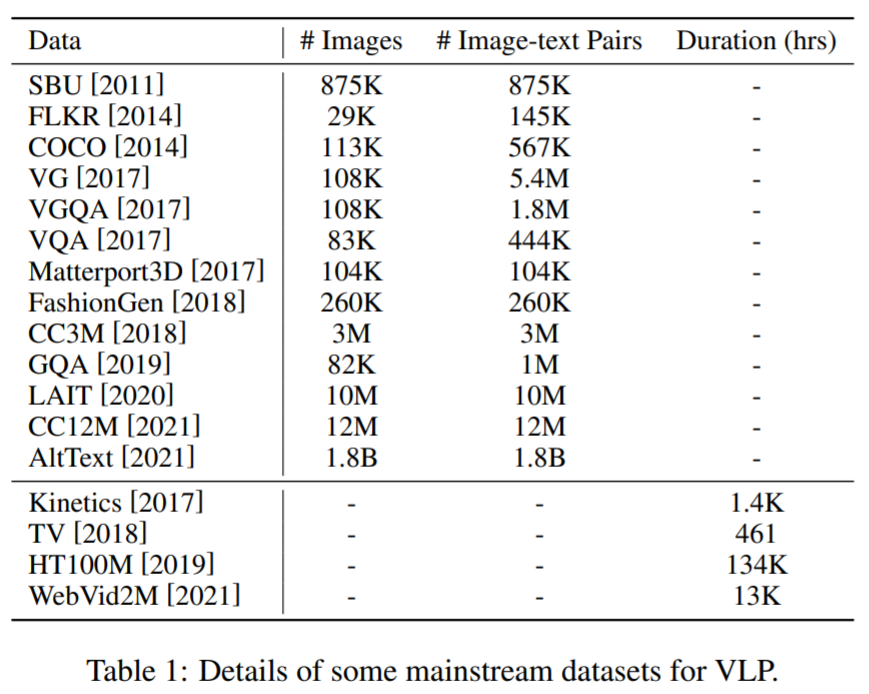
在預(yù)訓(xùn)練數(shù)據(jù)集方面:大多數(shù)用于 VLP 的數(shù)據(jù)集是通過(guò)組合跨多模態(tài)任務(wù)的公共數(shù)據(jù)集構(gòu)建而成。這里,一些主流語(yǔ)料庫(kù)及其詳細(xì)信息如下表 1 所示。
在下游任務(wù)方面:各種各樣的任務(wù)需要視覺(jué)和語(yǔ)言知識(shí)融合。本小節(jié)論文介紹了此類(lèi)任務(wù)的基本細(xì)節(jié)和目標(biāo),并將其分為五類(lèi):分類(lèi)、回歸、檢索、生成和其他任務(wù),其中分類(lèi)、回歸和檢索任務(wù)也稱(chēng)為理解任務(wù)。
在分類(lèi)任務(wù)中,其包括視覺(jué)問(wèn)答 (VQA)、視覺(jué)推理和合成問(wèn)答 (GQA)、視覺(jué) - 語(yǔ)言推理 (VLI)、自然語(yǔ)言視覺(jué)推理 (NLVR)、視覺(jué)常識(shí)推理 (VCR) 等。在 VQA 中,提供圖像或視頻視覺(jué)輸入,它通常被認(rèn)為是一個(gè)分類(lèi)任務(wù),模型從一個(gè)選擇池中預(yù)測(cè)出最合適的答案;在 GQA 中,我們可以將 GQA 視為 VQA 的升級(jí)版,旨在推進(jìn)自然場(chǎng)景視覺(jué)推理的研究;在 VLI 中,給定具有對(duì)齊字幕的視頻剪輯作為前提,并與基于視頻內(nèi)容的自然語(yǔ)言假設(shè)配對(duì),模型需要推斷該假設(shè)是否與給定視頻剪輯相矛盾。
在回歸任務(wù)中,多模態(tài)情感分析 (MSA) 旨在利用多模態(tài)信號(hào)(如視覺(jué)、語(yǔ)言等)檢測(cè)視頻中的情緒。它是作為一個(gè)連續(xù)的強(qiáng)度變量來(lái)預(yù)測(cè)話(huà)語(yǔ)的情感走向。
在檢索任務(wù)中,視覺(jué) - 語(yǔ)言檢索 (VLR) 通過(guò)適當(dāng)?shù)钠ヅ洳呗詠?lái)理解視覺(jué)(圖像或視頻)和語(yǔ)言,其包括兩個(gè)子任務(wù),視覺(jué)到文本檢索和文本到視覺(jué)檢索,其中視覺(jué)到文本檢索是根據(jù)視覺(jué)從更大的描述池中獲取最相關(guān)的文本描述,反之亦然。
在生成任務(wù)中,視覺(jué)字幕 (VC) 旨在為給定的視覺(jué)(圖像或視頻)輸入生成語(yǔ)義和語(yǔ)法上合適的文本描述。此外,論文還介紹了其他下游任務(wù),例如多模態(tài)機(jī)器翻譯 (MMT)、視覺(jué)語(yǔ)言導(dǎo)航 (VLN) 和光學(xué)字符識(shí)別 (OCR) 等。
SOTA VLP 模型
圖像 - 文本 VLP 模型。VisualBERT 被稱(chēng)為第一個(gè)圖像 - 文本預(yù)訓(xùn)練模型,使用 Faster R-CNN 提取視覺(jué)特征,并將視覺(jué)特征和文本嵌入連接起來(lái),然后將連接后的特征饋送到單個(gè)由 BERT 初始化的 transformer 中。許多 VLP 模型在調(diào)整預(yù)訓(xùn)練目標(biāo)和預(yù)訓(xùn)練數(shù)據(jù)集時(shí)遵循與 VisualBERT 相似的特征提取和架構(gòu)。最近,VLMO 利用圖像 patch 嵌入和文本詞嵌入,將組合嵌入與模態(tài)專(zhuān)家一起輸入到單個(gè) transformer 中,并取得了令人印象深刻的性能。METER 探索了如何使用單模態(tài)預(yù)訓(xùn)練模型,并提出一種雙流架構(gòu)模型來(lái)處理多模態(tài)融合,從而在許多下游任務(wù)上實(shí)現(xiàn)了 SOTA 性能。
視頻 - 文本 VLP 模型。VideoBERT 被稱(chēng)為第一個(gè)視頻 - 文本預(yù)訓(xùn)練模型,其擴(kuò)展 BERT 模型以同時(shí)處理視頻和文本。VideoBERT 使用預(yù)訓(xùn)練的 ConvNet 和 S3D 來(lái)提取視頻特征并將它們與文本詞嵌入連接起來(lái),并饋送到以 BERT 進(jìn)行初始化的 transformer。在訓(xùn)練 VideoBERT 時(shí),ConvNet 和 S3D 被凍結(jié),這表明該方法不是端到端的。最近,受 ViT 的啟發(fā),F(xiàn)rozen 和 Region-Learner 首先將視頻剪輯處理成幀,并根據(jù) ViT 處理每一幀圖像的方法獲得 patch 嵌入。Frozen 和 Region-Learner 以端到端的方式優(yōu)化自身并實(shí)現(xiàn) SOTA 性能。
下表 2 總結(jié)了更多現(xiàn)有的主流 VLP 模型:
未來(lái),在現(xiàn)有工作的基礎(chǔ)上,研究者希望 VLP 可以從以下幾個(gè)方面進(jìn)一步發(fā)展:
結(jié)合聲學(xué)信息,以往的多模態(tài)預(yù)訓(xùn)練研究大多強(qiáng)調(diào)語(yǔ)言和視覺(jué)的聯(lián)合建模,而忽略了隱藏在音頻中的信息;
知識(shí)學(xué)習(xí)和認(rèn)知,盡管現(xiàn)有的 VLP 模型已經(jīng)取得了顯著的性能,但它們本質(zhì)上是擬合大規(guī)模多模態(tài)數(shù)據(jù)集,讓 VLP 模型更有知識(shí)對(duì)于未來(lái)的 VLP 很重要;
提示優(yōu)化,通過(guò)設(shè)計(jì)離散或連續(xù)提示并將 MLM 用于特定的下游任務(wù),這些模型可以減少微調(diào)大量參數(shù)的計(jì)算成本,彌合預(yù)訓(xùn)練和微調(diào)之間的差距。
原文標(biāo)題:多模態(tài)綜述 | 一文了解Language-Vision預(yù)訓(xùn)練最新進(jìn)展和新領(lǐng)域
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
審核編輯:湯梓紅
-
AI
+關(guān)注
關(guān)注
87文章
30107瀏覽量
268401 -
模型
+關(guān)注
關(guān)注
1文章
3171瀏覽量
48711 -
Transformer
+關(guān)注
關(guān)注
0文章
141瀏覽量
5982
原文標(biāo)題:多模態(tài)綜述 | 一文了解Language-Vision預(yù)訓(xùn)練最新進(jìn)展和新領(lǐng)域
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
中國(guó)龍芯CPU及產(chǎn)品最新進(jìn)展
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的預(yù)訓(xùn)練
風(fēng)光互補(bǔ)技術(shù)及應(yīng)用新進(jìn)展
風(fēng)光互補(bǔ)技術(shù)原理及最新進(jìn)展
DIY懷表設(shè)計(jì)正式啟動(dòng),請(qǐng)關(guān)注最新進(jìn)展。
車(chē)聯(lián)網(wǎng)技術(shù)的最新進(jìn)展
介紹IXIAIP測(cè)試平臺(tái)和所提供測(cè)試方案的最新進(jìn)展
ITU-T FG IPTV標(biāo)準(zhǔn)化最新進(jìn)展如何?
VisionFive 2 AOSP最新進(jìn)展即將發(fā)布!
UWB通信技術(shù)最新進(jìn)展及發(fā)展趨勢(shì)
利用視覺(jué)語(yǔ)言模型對(duì)檢測(cè)器進(jìn)行預(yù)訓(xùn)練
多維度剖析視覺(jué)-語(yǔ)言訓(xùn)練的技術(shù)路線(xiàn)
ASML***的最新進(jìn)展






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論