 AI公司如何才能走通制藥這條路?不想做外包 當不了藥神
AI公司如何才能走通制藥這條路?不想做外包 當不了藥神
AI能制藥,早已不是啥新鮮事了。
尤其是疫情之后,包括輝瑞、羅氏、默克、阿斯利康、葛蘭素史克、賽諾菲、強生等在內的頂級制藥公司,紛紛加速擁抱人工智能,不是與AI公司合作,就是收購或自建AI部門。
從分子實驗到制造供應鏈甚至市場營銷,AI已經在整個制藥價值鏈上,展現出極大的潛力。
AI與制藥的融合過程,以兩種模式為主:
一種是VIC模式,即“VC(風險投資)+IP(知識產權)+CRO(研發外包)”,其中AI公司作為技術外包,為藥廠提供降本增效的解決方案;
另一種是AI-Driven模式,專門以AI技術來驅動分析預測發現新的化合物、蛋白質,自己研發創新藥。
相比“傳統產業智能化”的外包服務商,AI企業“自立山頭”制藥,有著更大的商業想象空間,也確實在過去幾年間,吸引了大規模的融資和巨頭攜資入場,僅2021年中國該領域的投融資規模就超過了80億。
其中最具代表性的,就是谷歌母公司Alphabet不久前成立的AI藥物公司Isomorphic Labs,其創始人正是研發了AlphaFold2算法的AI先鋒DeepMind的CEO。顯然,谷歌也非常看好以尖端AI技術在生物學領域“大展拳腳”的前景。
那么問題來了,生物制藥領域是一個專業知識壁壘極高的領域, AI參與制藥已經有15-20年的時間了,期間機器學習方法一直被用于藥物發現和臨床試驗當中。2000年,利用機器進行“高通量篩選”已經被應用在化合物測試當中。但目前為止,還沒有一個驗證AI可以“獨立行走”創新藥的成功案例。
制藥這條路,野心勃勃的AI公司該如何走下去?作為AI“優等生”和醫藥“后進生”,中國在AI制藥上的贏面究竟有多大呢?
不是藥神,AI制藥現在究竟幾分熟?
制藥門檻如此之高,AI公司憑什么認為自己可以繞過物理學定律的限制“自立山頭”呢?AI真的能取代傳統實驗手段,成為全村的希望嗎?
正如當初深度學習爆火之后大眾對AI不切實際的想象和懼怕一樣,在制藥這件事上,AI也并非無所不能,我們應該對AI設定一個合理預期:
以深度學習為主的AI技術有其適用范圍,目前主要用在分析處理醫藥數據、預測疾病靶點、設計和優化化合物、實驗自動化等領域當中,解決制藥場景的實際問題。
未來,隨著這些細分場景的不斷成功和數據積累,不斷反哺AI模型,可能3-5年才會有較大的突破。詹姆斯·貝森(James Bessen)在《邊做邊學》(Learning By Doing)一書中也提出,至少5-10年的時間AI才會讓制藥行業真正轉型。
所以,在全球范圍內,AI制藥都處在較早期的階段,AI公司造的藥,目前可能才只有“一分熟”。指望突然掉下一款由AI主導研發的石破天驚的創新藥,還是很遙遠的。
既然隔行如隔山,由藥廠引入AI不是強強聯合、事半功倍嗎,為什么AI公司還要冒著失敗的風險去“另立山頭”,而資本市場也愿意買賬呢?
另立山頭,誰給AI企業的自信?
原因之一,是AI的角色變了。
目前,制藥行業廣泛采用的是基于目標靶點的研究模式(Target-centric),即先要找到導致疾病的特定蛋白質(有效靶點),通過分析化合物、基因、疾病和蛋白質之間的關系,進行有效分子的篩選與設計。這個過程往往靠的是研究人員自身的創造力和經驗,離不開制藥公司大量高質量數據的支撐。
在這個過程中,AI的發揮空間就很大了。
1.更快。隨著基因組學的發展,尋找和選擇新藥分子已經成為一項數據密集型任務,利用AI來自動學習分析處理數據,能夠更快地推斷出疾病機制,發現新靶點,從而加速研發過程。比如麻省理工學院團隊推出的生物技術初創公司ReviveMed,就是基于MIT的代謝物數據庫,分析藥物-蛋白質、蛋白質-蛋白質的相互作用,識別特定的代謝物分子,找到一些有希望的治療靶點,這些代謝物分子就有可能是未來的藥物。
2.更早。如果醫療實驗數據是凌亂而未標記的,那么后續的分析處理預測都不容易實現,所以在新藥研發上面向AI的數據治理工作要開展得更早,現有的研發和業務流程必須重新設計,才能充分發揮AI、大數據、高性能計算等的協同價值,這涉及到大規模的組織轉型,也使得數據工程師、算法工程師在制藥領域的參與更早、更深。
3.更廣。“靶點-疾病”的研發范式,使得傳統制藥公司不會將精力集中在罕見疾病的治療上,因為ROI投資回報比太低,而AI技術可以通過表型數據(圖像)進行藥物的篩選和設計,反過來幫助找到新的治療靶點,在計算機中合成和測試分子,這讓罕見病有了治療甚至治愈的希望,對全人類來說都是好事。
從實驗室助手變成了新藥研發的主角,AI“獨立行走”的信心自然也就愈加強烈了。
原因之二,是重建一套新范式更方便。
雖然有一些制藥公司思想開明、態度開放,但事實是,制藥公司對其業務和研究方法的保守是出了名的,不愿意接受變革的占多數。一項研究顯示,2019年和2020年生命科學領域人工智能相關專利的申請中,只有不到2%是知名制藥公司提交的。
一些制藥公司甚至都沒有數字化,很多數據都用紙質檔案保存,采用AI還需要時間;有的大型制藥公司還是傳統思維占主導,傾向于研發傳統藥物制劑。還有的則傾向于保留數據和技術作為內部商業機密,不愿意分享給AI技術公司……既然如此,開辟一條全新的賽道自己制藥,對AI公司來說更加靈活,研發速度也更快。
與此同時,AI技術的發展,也讓AI主導的研發成為可能。
一方面,小樣本學習、生成技術等的應用,可以減少研發過程中的數據依賴。比如有公司就開發了一個名為Generative TensorialReinforcement Learning(GENTRL)的平臺,讓兩種DL深度學習模型來相互作用,一個生成分子,一個鑒別真假,解決實驗數據不足的問題。而一旦確定了標靶,就可以利用算法直接設計出所需要的分子結構了。
另外,雖說隔行如隔山,但端到端的深度學習,不需要算法人員去定義一些特征和規則,比如蛋白質結構預測模型能夠直接根據序列的特征輸出三維結構,目前已經達到實驗的精度。所以盡管目前人類科學對很多疾病的理解都還處于初級階段,算法人員也未必對生命科學知識十分精通,但運用AI工具來開發新藥,完全是可行的。
原因之三,就是自己做原研藥,這件事實在太香了。
目前,抗體藥這類生物藥已經逐漸超過了化學藥的數量,成為增長最快的治療藥物。全球已經有超過100款抗體藥上市,比如新冠特效藥就是抗體藥,找到能夠中和病毒的活性抗體來發揮作用。
以前,抗體藥需要從康復病人中去提取和篩選,這個過程費時費力,還有很大的不確定性。而通過AI直接對現有抗體進行設計和優化,實現高效的中和效果,一種新的抗體藥物就誕生了。
原研藥市場廣闊、利潤豐厚,自己研發無疑把握了最具價值的一環。所以說,AI公司自己做藥它不香嗎?
中國制藥,在AI畫布上描繪全新圖景
想必很多讀者通過新聞和行業報道都發現了,在AI制藥這個領域,美國在技術、資本、產業規模上都處于領先地位,AI開發的特效藥、疫苗、療法、平臺等不斷涌現。
而中國在AI技術上并不落后,這是否意味著有希望在制藥領域取得突破呢?在AI這塊技術畫布上描繪制藥藍圖,對于中國意味著三重價值:
1.將生命福祉把握在自己手里。
在醫藥醫療領域,數據都是非常敏感的,比如要針對個體的基因序列和新抗原設計出對應的藥物,對患者來說無疑是更有效、更精準、更普惠的。但是基因數據如果只能交給海外科技企業來分析和生產,其中存在的風險不用多說。
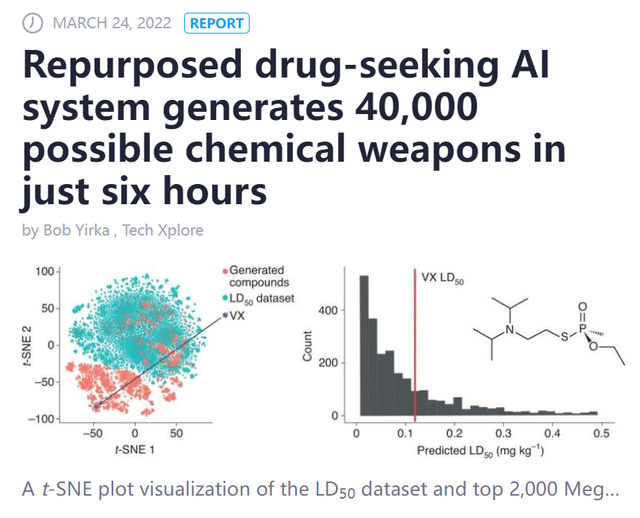
前不久《自然》雜志上就發布了一篇論文,總部位于美國北卡羅來納州的制藥公司Collaborations Pharmaceuticals,就與倫敦、瑞士的研究人員合作,訓練出了一個藥物開發工具MegaSyn,在短短六個小時內自動生產出40000種有毒的化學制劑。
利用AI結合群體基因特質,針對性地開發精準打擊的生物武器,并非不可能。所以中國必須將AI制藥的尖端科技掌握在自己手中。
2.在原研藥領域取得較大突破。
大家可能都看到了,最新引進的新冠特效藥價格高達數千元,原研藥的銷量高、利潤高,已經是大眾熟知的事實,而開發原研藥一直是中國制藥產業的老大難問題。必須意識到,在傳統生命科學領域,中國的起步較晚、基礎也相對薄弱,比如生物實驗中需要的高精度顯微鏡、測試試劑等也是被國外“卡脖子”的,在這種情況下,AI提供了一種開發原研藥的全新思路。
比如通過AI算法來代替冷凍電鏡,也可以解開蛋白質結構。目前,AlphaFold預測出來的結果已經可以和冷凍電鏡的方法相媲美。隨著中國在相關算法上的突破,未來能夠降低對一些卡脖子實驗技術的依賴。
在創新藥研發上,從科研到產業化之間的距離是非常近的,很多突破性技術和新分子都是從研究院所實驗室中誕生,再由藥廠進行轉化、評估、臨床試驗……而在AI研究領域,中國科研院所的能力已經處于一流水平。
AI重新定義制藥流程,有助于中國變成一個制藥強國。
3.進一步發揮中國的AI產業優勢。
我們都知道中國AI產業化的步伐很快,主要集中在互聯網、工業、礦山、城市管理等領域,在生命科學領域里的AI應用,總體還處于初級階段。
無論是AI公司驅動的創新藥,還是傳統藥廠的AI化,都有很大的發展空間。目前,幾乎中國頭部科技企業如BATH(百度、騰訊、阿里、華為)等都在AI藥物研發上有所動作。
隨著AI制藥的進一步發展,生命科學領域的數據、算力、算法都將進一步升級迭代,工具平臺生態也將進一步搭建和豐富起來,屆時,中國在AI領域的優勢也將進一步放大。
都說“一張白紙上可以畫出最新最美的圖畫”,AI制藥之于中國,就是在遠遠追趕的生命科學實驗道路之外,新建一條由數據鋪成的高速公路,搭乘智能小車跑得更快、更早抵達新藥研發的目的地。
盛名之下:AI解鎖制藥的三把鑰匙
AI發展最不可或缺的,是信心。歷史上的兩次AI寒冬,就與投資者和大眾對AI回報預期的垮掉,有著直接關系。AI制藥的投融資浪潮,似乎在大鳴大放之后,不得不面對一個骨感的現實:一開始想得很美,但突破來得很慢。
曾有一位AI制藥公司的創始人對媒體透露,第一輪融資時投資人希望能夠做藥,第二輪就開始建議他們做服務(也就是藥廠AI技術外包)了。
資本市場對AI制藥的疑慮,是高潮之下的正常調整,但要避免透支信任、解鎖光明的未來,AI制藥企業恐怕還需要拿到三把鑰匙:數據、算力、算法——沒錯,就是雖然樸實、但至關重要的AI“三駕馬車”。
實際上,大部分AI的問題都是因為數據不夠、算力不夠、算法不夠好。而解決方法也是從這三點入手。
先說數據。
前面提到,目前人類對生命科學的理解還非常初級,端到端學習也可以減少對一部分數據的依賴,但基本的高質量數據還是AI制藥必不可少的基礎。
受實驗手段、醫療技術的限制,目前AI對蛋白質功能的分析還是比較初級的,對分子的功能結構、關系序列等的描述不夠,這顯然會給AI學習帶來困擾,蛋白分子會不斷地和別的分子進行交互,形狀也會隨之改變,用純數據驅動的AI方法去生搬硬套,結果很可能是“無效設計”。
就如化學家Derek Lowe在《科學》雜志上指出的,即使兩種蛋白質具有物理上結合在一起的結構,也很難說它們實際上會粘合得有多好。用在動物或人身上的時候也不一定總是有效。
更深入地理解生物世界,離不開大量優質的數據,這些往往通過幾十年的積累和實驗獲得,掌握在藥企自己手里,不會輕易分享。此外基因數據、醫療數據還涉及到隱私倫理問題,需要在嚴格的數據保護法律法規之下使用。
所以對于AI企業來說,亟需要探索一種與藥企合作、分利的模式,解開數據的桎梏。
再說算力。
以蛋白質結構預測為例,它往往需要超大規模的算力支持。因為生物系統中分子之間的相互作用特別多,設計出來的模型可能參數不大,但比較復雜,比計算機視覺、NLP等模型要大很多。
此前曾有中國AI公司訓練出了中國版AlphaFold2,團隊成員表示遇到最大的困難,就是GPU資源(算力)有限,難以同時進行多次訓練來比較效果,所以只好在模型設計上下功夫,盡量減少試錯次數。
另一個科學家也向腦極體透露,其開發的蛋白質結構預測平臺,對一個模型的一個數據點(data point)進行計算就需要800G顯存,意味著需要十幾塊頂級顯卡,如果要做全規模訓練那算力成本簡直不可想象。
所以,一方面,需要加強AI算力基礎設施建設,提供更多更普惠的算力資源,通過產業合作等方式來支撐生命科學的AI應用發展。另一方面,對生物AI模型的“瘦身”優化成為大勢所趨,過大的模型即便在實驗室里有充沛的算力支持,在實際部署落地的時候也會對內存存儲等提出挑戰。
這自然就要提到更好的算法。
新藥研發是個非常復雜、探索未知的過程,世界一流的算法和成果,離不開世界一流的科研。目前來看,中國在AI領域“跟隨”更多,面向底層、有影響力的突破較少。
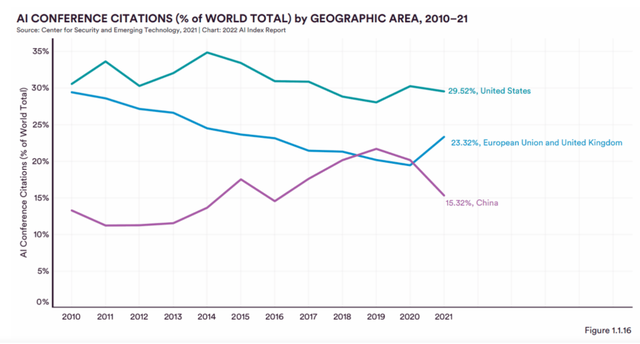
斯坦福大學發布的2022年人工智能指數報告(2022 AI Index Report)中也顯示,2021 年,中國在人工智能期刊、會議和知識庫出版物的數量上繼續領先世界,比美國高出 63.2%,但在引用數量上卻低于美國、歐盟和英國。
在一個全新的領域開發出新的算法,沒有任何經驗可循,核心還是在人才。首先需要人才具備尋找問題、提出問題的能力,以及耐心安心解決底層技術問題的科研環境,此外還需要具備生物學、藥劑學、化學等交叉知識,這些都給AI學科建設和人才培養提出了新的挑戰。
一位AI科學家告訴我,在她看來,現在對AI人來說既是最好的時代,也是最壞的時代。一方面AI產業發展帶來的新機遇非常多,另一方面從業者也會感受到一種沉甸甸的責任感,技術迭代速度之快帶來了高強度的研究壓力。
不難看出,AI驅動的研究范式也帶來了全新的挑戰,能否在產業重新分工中占據優勢,中國AI還有一些關卡要過,其中很多基礎條件需要長期的、體系化、科學的投入。
無論如何,AI必將引領生物制藥領域未來十年甚至更遠的創新方向。從這個角度看,AI制藥公司“自立山頭”,邁出了關鍵的一步,這一選擇是必須肯定且支持的。接下來的重點在于,如何在成果數量與質量上趕超和引領世界一流水平。
就像科學史家托馬斯·庫恩在《科學革命的結構》中所寫的那樣,科學就是通過不斷地轉換范式,打破舊有框架束縛,才取得了進步。
人類的健康和希望,就隱藏在這樣的“不走尋常路”中。
-
AI
+關注
關注
87文章
30146瀏覽量
268419
發布評論請先 登錄
相關推薦
PLC加藥計量泵數據采集遠程監控系統方案
神盾集團與Arm達成合作,推動AI HPC晶片創新
專業PCB設計,高速PCB設計,PCB設計外包, PCB Layout,PCB Design,PCB畫板公司,PCB設計公司,迅安通科技公司介紹
制藥廠DCS數據采集遠程監控解決方案

微軟被曝將AI研發外包給OpenAI
2013 款路虎神行者 2 車偶發性無法起動


性能強勁、穩定高效的雷神雙路64核服務器升級亮相
制藥裝備企業如何實現制粒機遠程監控和運維管理

PLC遠程監控在制藥行業的應用

德睿智藥與復宏漢霖達成戰略合作,共同研發AI賦能的ADC藥物和抗衰老療法平臺
生物制藥智能照明控制系統解決方案





 工商網監
工商網監
評論