 NVIDIA Hopper架構GPU的深入研究
NVIDIA Hopper架構GPU的深入研究
在 2022 NVIDIA GTC 主題演講中, NVIDIA 首席執行官 Jensen Huang 介紹了新的 NVIDIA H100 張量核心 GPU 基于新的 NVIDIA 漏斗 GPU 架構。這篇文章讓你看看新的 H100 GPU ,并介紹了NVIDIA Hopper 架構 GPU 的重要新功能。
NVIDIA H100 張量核心 GPU 介紹
NVIDIA H100 張量核心 GPU 是我們設計的第九代數據中心 GPU ,用于在前一代 NVIDIA A100 張量核心 GPU 上為大規模 AI 和 HPC 提供數量級性能跳躍。 H100 延續了 A100 的主要設計重點,提高了人工智能和 HPC 工作負載的可擴展性,大大提高了架構效率。
對于當今的主流 AI 和 HPC 機型,配備 InfiniBand interconnect 的 H100 的性能是 A100 的 30 倍。新的 NVLink 交換系統互連針對一些最大且最具挑戰性的計算工作負載,這些工作負載需要跨多個 GPU 加速節點的模型并行性來適應。這些工作負載帶來了新一代的性能飛躍,在某些情況下, InfiniBand 的性能比 H100 再次提高了三倍。
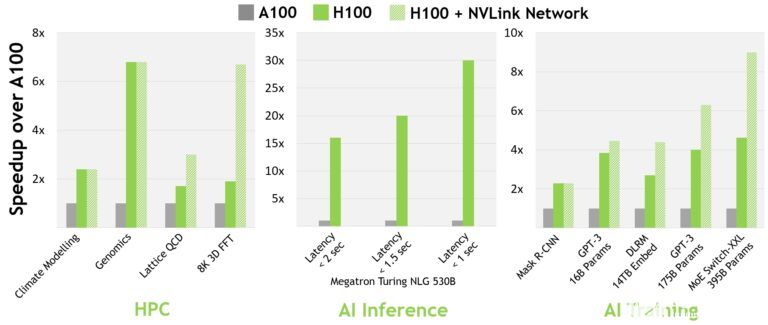
圖 2 。 H100 實現了下一代人工智能和高性能計算的突破
所有性能數據都是初步的,基于當前的預期,并可能會隨著運輸產品的變化而變化。 A100 集群: HDR IB 網絡。 H100 集群: NDR IB 網絡,帶有 NVLink 交換系統(如圖所示) GPU :氣候建模 1K , LQCD 1K ,基因組學 8 , 3D-FFT 256 , MT-NLG 32 (批次大小: A100 為 4 , 1 秒 H100 為 60 , A100 為 8 , 1.5 和 2 秒 H100 為 64 ), MRCNN 8 (批次 32 ), GPT-3 16B 512 (批次 256 ), DLRM 128 (批次 64K ), GPT-3 16K (批次 512 ), MoE 8K (批次 512 ,每個 GPU 一名專家)。
2022 年春天 GTC 宣布了新的NVIDIA Grace Hopper 超級芯片產品。NVIDIA Hopper H100 張量核心 GPU 將為 NVIDIA Grace Guffer-SuxCube CPU + GPU 架構,為兆字節規模加速計算而建,并在大型 AI 和 HPC 上提供 10X 更高性能。
NVIDIA Grace Hopper 超級芯片利用ARM體系結構的靈活性來創建一個 CPU 和服務器架構,從加速計算開始。H100與 Nvidia Grace CPU 配對,與超高速 NVIDIA 芯片到芯片互連,提供900 Gb/s的總帶寬,比PCIE GE5快7X。與當今最快的服務器相比,這種創新設計提供了高達30倍的聚合帶寬,對于使用TB數據的應用程序,其性能高達10倍。
NVIDIA H100 GPU 主要功能概述
新的 streaming multiprocessor ( SM )有許多性能和效率改進。主要的新功能包括:
新的 第四代張量核 芯片到芯片的速度比 A100 快 6 倍,包括每 SM 加速比、額外的 SM 計數和更高的 H100 時鐘。與上一代 16 位浮點選項相比,基于每個 SM , Tensor Core 在等效數據類型上的 MMA (矩陣乘法累加)計算速率是 A100 SM 的 2 倍,在使用新 FP8 數據類型時是 A100 的 4 倍。稀疏特性利用深度學習網絡中的細粒度結構化稀疏性,將標準張量核心運算的性能提高了一倍
新的 DPX Instructions 在 A100 GPU 上將動態編程算法的速度提高了 7 倍。兩個例子包括用于基因組處理的史密斯 – 沃特曼算法,以及用于在動態倉庫環境中為一組機器人尋找最佳路徑的弗洛伊德 – 沃沙爾算法。
3 倍于 IEEE FP64 和 FP32 與 A100 相比,芯片間的處理速度更快,因為每個 SM 的時鐘性能比 A100 快 2 倍,加上額外的 SM 計數和更高的 H100 時鐘。
新線程塊集群 功能 支持以比單個 SM 上的單個線程塊更大的粒度對局部性進行編程控制。這擴展了 CUDA 編程模型,向編程層次結構添加了另一個級別,現在包括線程、線程塊、線程塊集群和網格。集群允許多個線程塊在多個 SMs 上并發運行,以同步、協作方式獲取和交換數據。
分布式共享內存 允許在多個 SM 共享內存塊之間進行負載、存儲和原子的直接 SM-to-SM 通信。
新的 asynchronous execution 功能包括一個新的 張量記憶加速器( TMA ) 單元,它可以在全局內存和共享內存之間高效地傳輸大塊數據。 TMA 還支持集群中線程塊之間的異步復制。還有一個新的 異步事務屏障 用于進行原子數據移動和同步。
新transformer 發動機結合使用軟件和定制的 NVIDIA Hopper Tensor 核心技術,專門設計用于加速 transformer 模型訓練和推理。 transformer 引擎智能管理并動態選擇 FP8 和 16 位計算,自動處理每層 FP8 和 16 位之間的重新轉換和縮放,與上一代 A100 相比,在大型語言模型上提供高達 9 倍的人工智能訓練和高達 30 倍的人工智能推理加速。
HBM3 存儲子系統 的帶寬比上一代增加了近 2 倍。 H100 SXM5 GPU 是世界上第一款 GPU HBM3 內存,提供了一流的 3 TB / s 內存帶寬。
50MB 二級緩存體系結構 緩存了大量模型和數據集以供重復訪問,從而減少了對 HBM3 的訪問。
第二代多實例 GPU ( MIG )技術與 A100 相比,每個 GPU 實例的計算容量增加約 3 倍,內存帶寬增加近 2 倍。 MIG level TEE 現在首次提供機密計算能力。最多支持七個單獨的 GPU 實例,每個實例都有專用的 NVDEC 和 NVJPG 單元。現在,每個實例都包含自己的一組性能監視器,可與 NVIDIA 開發人員工具配合使用。
新的機密計算支持 保護用戶數據,抵御硬件和軟件攻擊,并在虛擬化和 MIG 環境中更好地隔離和保護虛擬機( VM )。 H100 實現了世界上第一個本機機密計算 GPU ,并以全 PCIe 線速率使用 CPU 擴展了可信執行環境( TEE )。
第四代 NVIDIA NVLink 在所有 reduce 操作中提供了 3 倍的帶寬增加,與上一代 NVLink 相比,一般帶寬增加了 50% ,多 GPU IO 的總帶寬為 900 GB / s ,是 PCIe Gen 5 帶寬的 7 倍。
Third-generation NVSwitch 技術包括駐留在節點內部和外部的交換機,用于連接服務器、群集和數據中心環境中的多個 GPU 。節點內的每個 NVSwitch 提供 64 個第四代 NVLink 鏈路端口,以加速多 GPU 連接。交換機總吞吐量從上一代的 7.2 TB / s 增加到 13.6 TB / s 。新的第三代 NVSwitch 技術還為集體運營提供了硬件加速,多播和 NVIDIA 的網絡規模大幅縮減。
新的 NVLink 交換系統 互連技術和基于第三代 NVSwitch 技術的新的第二級 NVLink 開關 引入了地址空間隔離和保護,使多達 32 個節點或 256 個 GPU 能夠在 2:1 錐形胖樹拓撲中通過 NVLink 連接。這些連接的節點能夠提供 57.6 TB / s 的全對全帶寬,并能提供令人難以置信的 FP8 稀疏 AI 計算的 1 exaFLOP 。
PCIe 第 5 代 提供 128 GB / s 的總帶寬(每個方向 64 GB / s ),而第 4 代 PCIe 的總帶寬為 64 GB / s (每個方向 32 GB / s )。 PCIe Gen 5 使 H100 能夠與性能最高的 x86 CPU 和 SmartNIC 或數據處理器( DPU )連接。
還包括許多其他新功能,以改進強大的可擴展性,減少延遲和開銷,并通常簡化 GPU 編程。
NVIDIA H100 GPU 深入架構
基于新NVIDIA Hopper GPU 架構的 Nvidia H100 GPU 具有多個創新:
新的第四代張量核在更廣泛的人工智能和高性能計算任務中執行比以往更快的矩陣計算。
新的 transformer 引擎使 H100 的人工智能訓練速度提高了 9 倍,人工智能訓練速度提高了 30 倍。與前一代 A100 相比,大型語言模型的推理速度有所提高。
新的 NVLink 網絡互連使 GPU 能夠跨多個計算節點在多達 256 個 GPU 之間進行 GPU 通信。
安全 MIG 將 GPU 劃分為獨立的、大小合適的實例,以最大限度地提高較小工作負載的服務質量( QoS )。
許多其他新的體系結構功能使許多應用程序的性能提高了 3 倍。
NVIDIA H100 是第一款真正的異步 GPU 。 H100 將 A100 的全局異步傳輸擴展到所有地址空間的共享異步傳輸,并增加了對張量內存訪問模式的支持。它使應用程序能夠構建端到端的異步管道,將數據移入和移出芯片,完全重疊并隱藏數據移動和計算。
現在,使用新的張量內存加速器管理 H100 的全部內存帶寬只需要少量 CUDA 線程,而大多數其他 CUDA 線程可以專注于通用計算,例如新一代張量核的預處理和后處理數據。
H100 將 CUDA 線程組層次結構擴展為一個稱為線程塊集群的新級別。集群是一組線程塊,保證可以并發調度,并支持跨多個 SMs 的線程的高效協作和數據共享。集群還可以更高效地協同驅動異步單元,如張量內存加速器和張量內核。
協調越來越多的片上加速器和不同的通用線程組需要同步。例如,使用輸出的線程和加速器必須等待產生輸出的線程和加速器。
NVIDIA asynchronous transaction barriers 使集群內的通用 CUDA 線程和片上加速器能夠高效地同步,即使它們位于不同的 SMs 上。所有這些新功能使每個用戶和應用程序都能隨時充分使用其 H100 GPU 的所有單元,使 H100 成為迄今為止功能最強大、可編程性最強、能效最高的 NVIDIA GPU 。
為 H100 GPU 供電的完整 GH100 GPU 是使用為 NVIDIA 定制的 TSMC 4N 工藝制造的,具有 800 億個晶體管,芯片尺寸為 814 毫米2,以及更高頻率的設計。
NVIDIA GH100 GPU 由多個 GPU 處理集群( GPC )、紋理處理集群( TPC )、流式多處理器( SMS )、 L2 高速緩存和 HBM3 存儲器控制器組成。
GH100 GPU 的全面實施包括以下裝置:
8 個 GPC , 72 個 TPC ( 9 個 TPC / GPC ), 2 個 SMs / TPC ,每個完整 GPU 144 條 SMs
每個 SM 128 個 FP32 CUDA 內核,每個完整 GPU 18432 個 FP32 CUDA 內核
每個 SM 4 個第四代張量核,每個完整 GPU 576 個
6 個 HBM3 或 HBM2e 堆棧, 12 個 512 位內存控制器
60 MB 二級緩存
第四代 NVLink 和 PCIe 第 5 代
NVIDIA H100 GPU 與 SXM5 板形因子包括以下單元:
8 條 GPC , 66 條 TPC , 2 條 SMs / TPC ,每個 GPU 132 條 SMs
每個 SM 128 個 FP32 CUDA 核,每個 GPU 16896 個 FP32 CUDA 核
每個 SM 4 個第四代張量核,每個 GPU 528 個
80 GB HBM3 , 5 個 HBM3 堆棧, 10 個 512 位內存控制器
50 MB 二級緩存
第四代 NVLink 和 PCIe 第 5 代
具有 PCIE Gen 5 板形狀因子 的NVIDIA H100 GPU 包括以下單元:
7 或 8 個 GPC , 57 個 TPC , 2 條 SMs / TPC ,每個 GPU 114 條 SMs
128 個 FP32 CUDA 顏色/ SM ,每個 GPU 14592 個 FP32 CUDA 顏色
每個 SM 4 個第四代張量核,每個 GPU 456 個
80 GB HBM2e , 5 個 HBM2e 堆棧, 10 個 512 位內存控制器
50 MB 二級緩存
第四代 NVLink 和 PCIe 第 5 代
與基于 TSMC 7nm N7 工藝的上一代 GA100 GPU 相比,使用 TSMC 4N 制造工藝使 H100 能夠增加 GPU 核心頻率,提高每瓦性能,并包含更多 GPC 、 TPC 和 SMs 。
圖 3 顯示了一個完整的 GH100 GPU 和 144 條短信。 H100 SXM5 GPU 有 132 條短信, PCIe 版本有 114 條短信。 H100 GPU 主要用于執行 AI 、 HPC 和數據分析的數據中心和邊緣計算工作負載,但不用于圖形處理。 SXM5 和 PCIe H100 GPU 中只有兩個 TPC 支持圖形(也就是說,它們可以運行頂點、幾何體和像素著色器)。
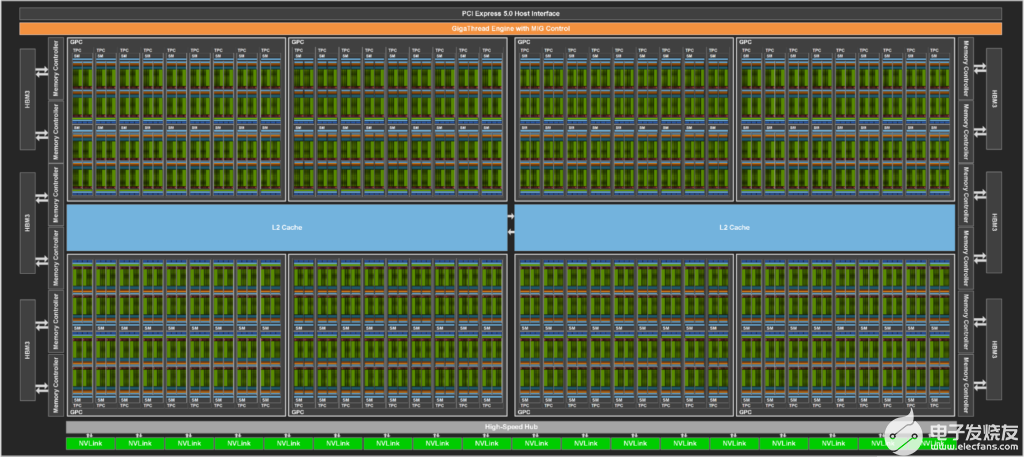
Figure 3. GH100 全 GPU 帶 144 條 SMs
H100 SM 架構
在NVIDIA A100 張量核心 GPU SM 架構上, H100 SM 由于引入了 FP8 而使每 100 浮點運算功率 A100 峰值翻倍,并且在先前所有張量核心、 FP32 和 FP64 數據類型、時鐘時鐘上加倍 A100 原始 SM 計算功率。
與上一代 A100 相比,新的 transformer 引擎與 NVIDIA Hopper FP8 Tensor Core 相結合,在大型語言模型上提供了高達 9 倍的人工智能訓練和 30 倍的人工智能推理加速。新的 NVIDIA Hopper DPX 指令使史密斯 – 沃特曼算法處理基因組學和蛋白質測序的速度提高了 7 倍。
新的 NVIDIA Hopper 第四代 Tensor Core 、 Tensor Memory Accelerator ,以及許多其他新的 SM 和通用 H100 架構改進,在許多其他情況下,共同提供高性能計算機和人工智能高達 3 倍的性能。

Peak TF32 Tensor Core1500 TFLOPS | 1000 TFLOPS2400 TFLOPS | 800 TFLOPS2
Peak FP16 Tensor Core11000 TFLOPS | 2000 TFLOPS2800 TFLOPS | 1600 TFLOPS2
Peak BF16 Tensor Core11000 TFLOPS | 2000 TFLOPS2800 TFLOPS | 1600 TFLOPS2
Peak FP8 Tensor Core12000 TFLOPS | 4000 TFLOPS21600 TFLOPS | 3200 TFLOPS2
Peak INT8 Tensor Core12000 TOPS | 4000 TOPS21600 TOPS | 3200 TOPS2
表 1 。 NVIDIA H100 Tensor Core GPU 初步性能規范
H100 的初步性能評估基于當前預期,并可能會隨著運輸產品的變化而變化
使用稀疏特性的有效 TFLOPS / top
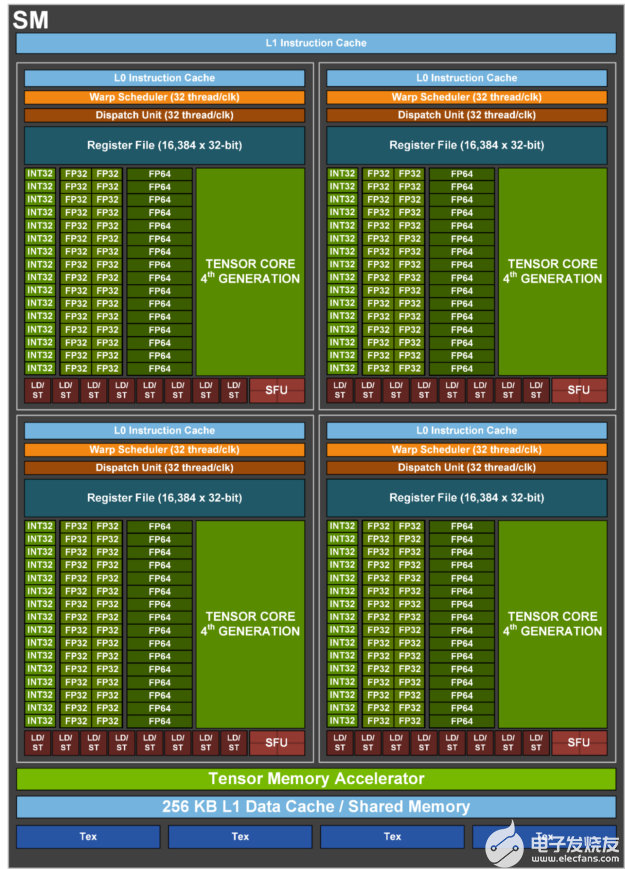
圖 4 。 GH100 流式多處理器
H100 SM 主要功能概述
第四代張量核:
與 A100 相比,芯片到芯片的速度提高了 6 倍,包括每 SM 的加速比、額外的 SM 計數和更高的 H100 時鐘。
與上一代 16 位浮點選項相比,基于每個 SM , Tensor Core 在等效數據類型上的 MMA (矩陣乘法累加)計算速率是 A100 SM 的 2 倍,在使用新 FP8 數據類型時是 A100 的 4 倍。
稀疏特性利用深度學習網絡中的細粒度結構化稀疏性,將標準張量核心運算的性能提高了一倍
新的 DPX instructions 在 A100 GPU 上將動態編程算法的速度提高了 7 倍。兩個例子包括用于基因組處理的史密斯 – 沃特曼算法,以及用于在動態倉庫環境中為一組機器人尋找最佳路徑的弗洛伊德 – 沃沙爾算法。
3 倍于 IEEE FP64 和 FP32 與 A100 相比,芯片間的處理速度更快,因為每個 SM 的時鐘性能比 A100 快 2 倍,加上額外的 SM 計數和更高的 H100 時鐘。
256 KB 的組合共享內存和一級數據緩存,比 A100 大 1.33 倍。
新的 asynchronous execution 功能包括一個新的 張量記憶加速器( TMA ) 單元,它可以在全局內存和共享內存之間高效地傳輸大塊數據。 TMA 還支持集群中線程塊之間的異步復制。還有一個新的 異步事務屏障 用于進行原子數據移動和同步。
新的 線程塊簇 功能公開了對多條短信的位置控制。
分布式共享內存 支持跨多個 SM 共享內存塊的裝載、存儲和原子的 SM 到 SM 直接通信
H100 張量核結構
張量核是專門用于矩陣乘法和累加( MMA )數學運算的高性能計算核,為人工智能和 HPC 應用提供了突破性的性能。與標準浮點( FP )、整數( INT )和融合乘法累加( FMA )操作相比,在一個 NVIDIA GPU 中跨 SMs 并行運行的張量核在吞吐量和效率上都有了顯著提高。
在NVIDIA V100GPU 中首次引入張量核,并在每個新的 NVIDIA GPU 體系結構生成中進一步增強。
H100 中新的第四代 Tensor Core 體系結構每 SM (時鐘對時鐘)提供的原始密集稀疏矩陣數學吞吐量是 A100 的兩倍,考慮到 H100 比 A100 更高的 GPU 升壓時鐘,這一數字甚至更高。支持 FP8 、 FP16 、 BF16 、 TF32 、 FP64 和 INT8 MMA 數據類型。新的 Tensor 核還具有更高效的數據管理,可節省高達 30% 的操作數傳遞能力。
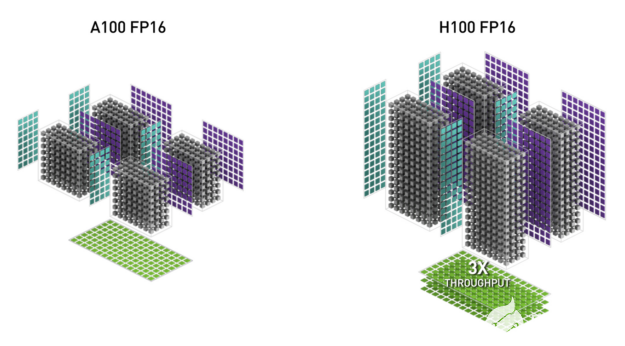
圖 5 。 H100 FP16 Tensor Core 的吞吐量是 A100 FP16 Tensor Core 的 3 倍
NVIDIA Hopper FP8 數據格式
H100 GPU 增加了 FP8 張量核,以加速人工智能訓練和推理。如圖 6 所示, FP8 張量磁芯支持 FP32 和 FP16 累加器,以及兩種新的 FP8 輸入類型:
具有 4 個指數位、 3 個尾數位和 1 個符號位的 E4M3
E5M2 ,具有 5 個指數位、 2 個尾數位和 1 個符號位
E4M3 支持需要更少動態范圍和更高精度的計算,而 E5M2 提供更寬的動態范圍和更低的精度。與 FP16 或 BF16 相比, FP8 將數據存儲需求減半,吞吐量翻倍。
本文后面介紹的新 transformer 引擎使用 FP8 和 FP16 精度來減少內存使用并提高性能,同時仍保持大型語言和其他模型的準確性。
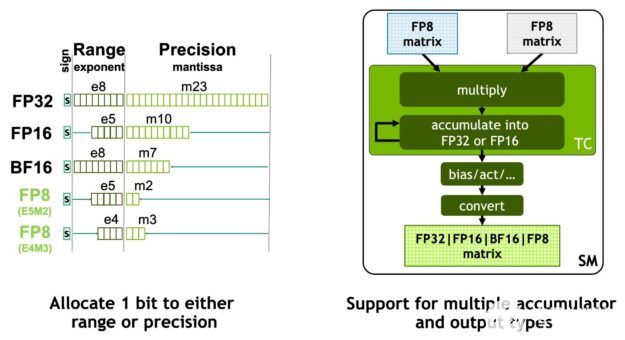
圖 6 。新NVIDIA Hopper FP8 精度:吞吐量是 H100 FP16 或 BF16 的 2 倍,占地面積是后者的一半
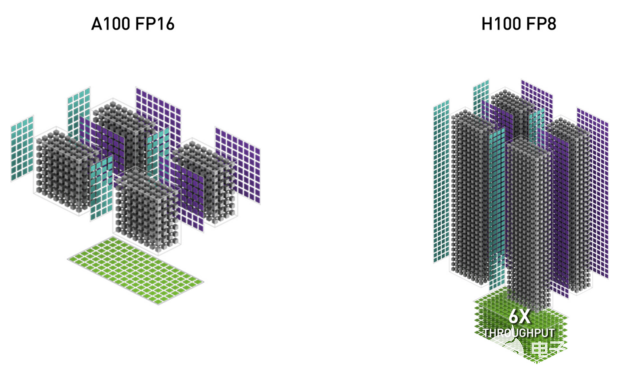
圖 7 。 H100 FP8 Tensor Core 的吞吐量是 A100 FP16 Tensor Core 的 6 倍
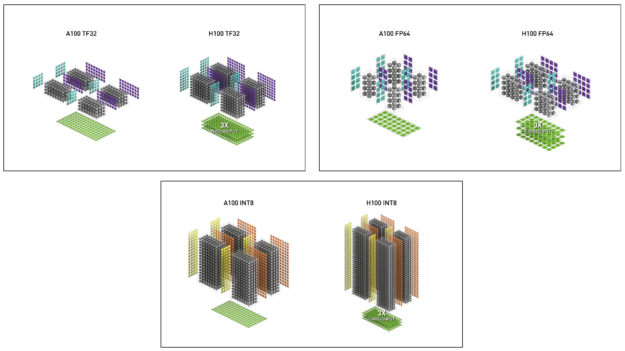
圖 8 。 H100 TF32 、 FP64 和 INT8 張量核的吞吐量都是 A100 的 6 倍
表 2 顯示了多種數據類型的 H100 數學加速比超過 A100 。
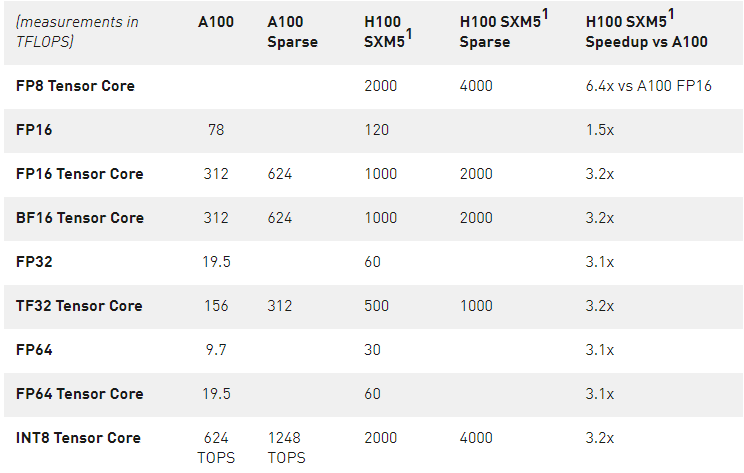
表 2 。 H100 的加速比超過 A100 ( H100 的初步性能, TC =張量核心)
。除非另有規定,否則所有測量值均以 Tflop 為單位。
1 – H100 基于當前預期和運輸產品變化的初步性能估計
用于加速動態規劃的新 DPX 指令
許多蠻力優化算法的特點是,在解決較大的問題時,子問題的解決方案會被多次重用。動態規劃( DP )是一種通過將復雜的遞歸問題分解為更簡單的子問題來解決它的算法技術。通過存儲子問題的結果,無需在以后需要時重新計算, DP 算法將指數問題集的計算復雜度降低到線性范圍。
DP 通常用于廣泛的優化、數據處理和基因組學算法。
在快速發展的基因組測序領域,史密斯 – 沃特曼 DP 算法是最重要的方法之一。
在機器人技術領域, Floyd Warshall 是一個關鍵算法,用于實時通過動態倉庫環境為一組機器人尋找最佳路線。
H100 引入 DPX 指令,使 DP 算法的性能比 NVIDIA Ampere GPU 提高了 7 倍。這些新指令為許多 DP 算法的內環提供高級融合操作數支持。這將大大加快疾病診斷、物流路線優化甚至圖形分析的解決速度。
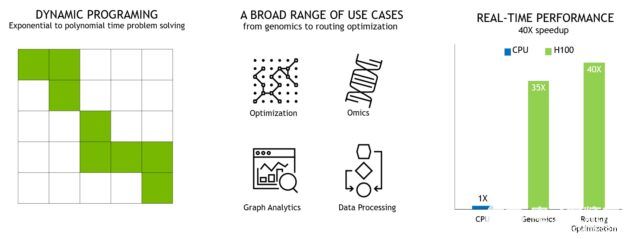
圖 9 。 DPX 指令加速動態編程
H100 計算性能摘要
總體而言,考慮到 H100 的所有新計算技術進步, H100 的計算性能比 A100 提高了約 6 倍。圖 10 以級聯方式總結了 H100 的改進:
132 條短信比 A100 108 條短信增加 22%
由于新的第四代 Tensor 內核, H100 短信的速度提高了兩倍。
在每個 Tensor 內核中,新的 FP8 格式和相關的 transformer 引擎提供了另一個 2 倍的改進。
H100 中時鐘頻率的增加帶來了大約 1.3 倍的性能提升。
總的來說,這些改進使 H100 的峰值計算吞吐量約為 A100 的 6 倍,這對于世界上最需要計算的工作負載來說是一個重大飛躍。
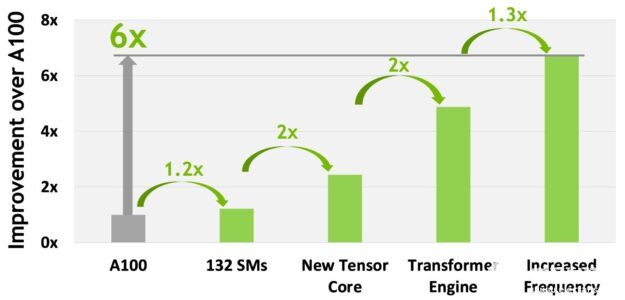
圖 10 。 H100 計算改進總結
H100 的吞吐量是全球的 6 倍大多數需要計算的工作負載。
H100 GPU 層次結構和異步改進
在并行程序中實現高性能的兩個關鍵是數據局部性和異步執行。通過將程序數據移動到盡可能靠近執行單元的位置,程序員可以利用對本地數據進行低延遲和高帶寬訪問所帶來的性能。 異步執行涉及尋找與內存傳輸和其他處理重疊的獨立任務。目標是讓 GPU 中的所有單元都得到充分利用。
在下一節中,我們將探討添加到 NVIDIA Hopper 中 GPU 編程層次結構中的一個重要新層,它以比單個 SM 上的單個線程塊更大的規模公開局部性。我們還介紹了新的異步執行功能,這些功能可以提高性能并減少同步開銷。
線程塊簇
CUDA 編程模型長期以來依賴于 GPU 計算體系結構,該體系結構使用包含多個線程塊的網格來利用程序中的局部性。線程塊包含在單個 SM 上并發運行的多個線程,這些線程可以與快速屏障同步,并使用 SM 的共享內存交換數據。然而,隨著 GPU 超過 100 個 SMs ,計算程序變得更加復雜,作為編程模型中表示的唯一局部單元的線程塊不足以最大限度地提高執行效率。
H100 引入了一種新的線程塊集群體系結構,它以比單個 SM 上的單個線程塊更大的粒度公開了對局部性的控制。線程塊集群擴展了 CUDA 編程模型,并在 GPU 的物理編程層次結構中添加了另一個級別,以包括線程、線程塊、線程塊集群和網格。
集群是一組線程塊,保證并發調度到一組 SMs 上,其目標是實現多個 SMs 之間線程的高效協作。 H100 中的集群在 GPC 內的 SMs 中同時運行。
GPC 是硬件層次結構中的一組 SMs ,它們在物理上總是緊密相連。集群具有硬件加速障礙和新的內存訪問協作能力,將在以下部分討論。 GPC 中用于 SMs 的專用 SM-to-SM 網絡在群集中的線程之間提供快速數據共享。
在 CUDA 中,網格中的線程塊可以在內核啟動時選擇性地分組到集群中,如圖 11 所示,集群功能可以從 CUDA cooperative_groups API 中利用。
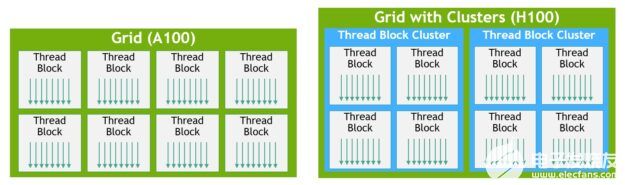
圖 11 。線程塊簇和帶簇的網格
網格由傳統 CUDA 編程模型中的線程塊組成,如 A100 所示,如圖左半部分所示。NVIDIA 的 Hopper 架構增加了可選的集群層次結構,在圖的右半部分顯示。
分布式共享內存
使用集群,所有線程都可以通過加載、存儲和原子操作直接訪問其他 SM 的共享內存。此功能稱為分布式共享內存( DSEM ),因為共享內存虛擬地址空間在邏輯上分布在集群中的所有塊上。
DSEM 使 SMs 之間的數據交換更加高效,不再需要通過全局內存寫入和讀取數據來傳遞數據。群集專用的 SM-to-SM 網絡確保了對遠程 DSEM 的快速、低延遲訪問。與使用全局內存相比, DSEM 將線程塊之間的數據交換速度提高了約 7 倍。
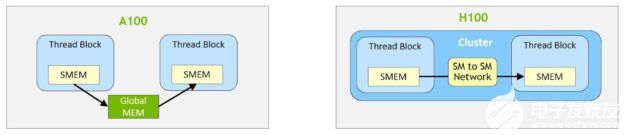
圖 12 。線程塊到線程塊的數據交換( A100 與 H100 的集群)
在 CUDA 級別,集群中所有線程塊的所有 DSEM 段都映射到每個線程的通用地址空間中,這樣所有 DSEM 都可以用簡單的指針直接引用。 CUDA 用戶可以利用 cooperative _ groups API 構造指向集群中任何線程塊的通用指針。 DSEM 傳輸也可以表示為異步復制操作,與基于共享內存的屏障同步,以跟蹤完成情況。
圖 13 顯示了在不同算法上使用集群的性能優勢。集群使您能夠直接控制 GPU 的更大部分,而不僅僅是單個 SM ,從而提高了性能。集群支持與更多線程的協作執行,與單線程塊相比,集群可以訪問更大的共享內存池。
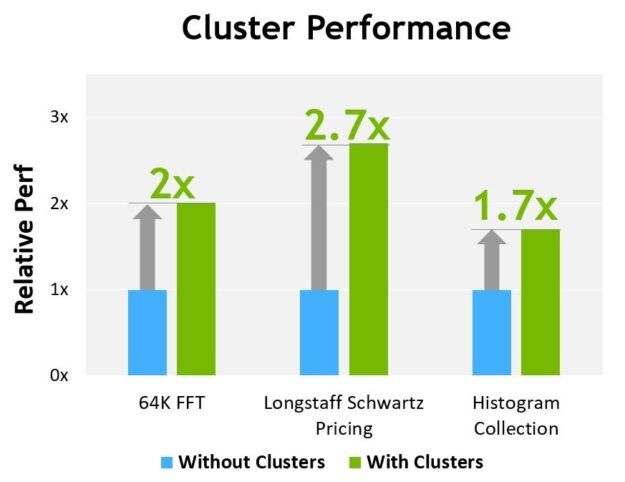
圖 13 。集群與非集群性能比較
H100 的初步性能評估基于當前預期,并可能會隨著運輸產品的變化而變化
異步執行
每一代 NVIDIA GPU 都包括許多架構增強功能,以提高性能、可編程性、能效、 GPU 利用率和許多其他因素。最近幾代 NVIDIA GPU 包含了異步執行功能,以實現數據移動、計算和同步的更多重疊。
在 NVIDIA Hopper 架構提供了新的功能,提高異步執行,并使進一步重疊的內存副本與計算和其他獨立的工作,同時也最小化同步點。我們描述了稱為張量內存加速器( TMA )的新異步內存復制單元和一個新的異步事務屏障。
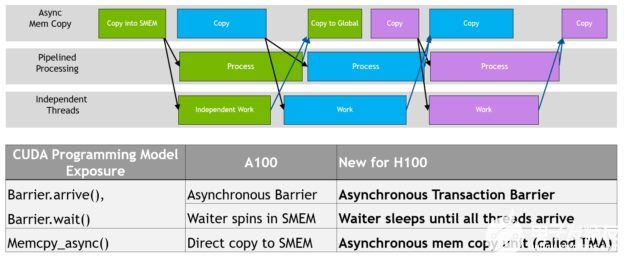
圖 14 。 NVIDIA Hopper 中的異步執行并發性和增強功能
數據移動、計算和同步的編程重疊。異步并發和最小化同步點是性能的關鍵。
張量記憶加速器
為了幫助提供強大的新 H100 張量內核,新的張量內存加速器( TMA )提高了數據獲取效率,它可以將大數據塊和多維張量從全局內存傳輸到共享內存,然后再傳輸回來。
TMA 操作使用拷貝描述符啟動,該描述符使用張量維度和塊坐標指定數據傳輸,而不是每個元素尋址(圖 15 )。可以指定達到共享內存容量的大數據塊,并將其從全局內存加載到共享內存,或從共享內存存儲回全局內存。 TMA 通過支持不同的張量布局( 1D-5D 張量)、不同的內存訪問模式、縮減和其他功能,顯著降低了尋址開銷,提高了效率。
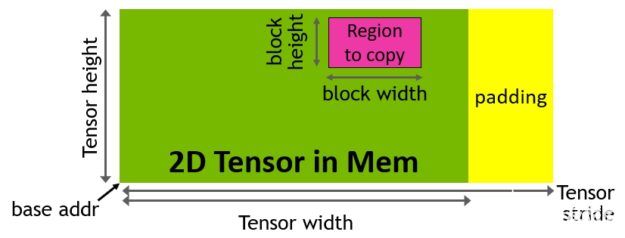
圖 15 。通過復制描述符生成 TMA 地址
TMA 操作是異步的,并利用 A100 中引入的基于共享內存的異步屏障。此外, TMA 編程模型是單線程的,其中選擇 warp 中的一個線程來發出異步 TMA 操作( cuda::memcpy_async ),以復制張量。因此,多個線程可以在 cuda::barrier 上等待數據傳輸的完成。為了進一步提高性能, H100 SM 增加了硬件來加速這些異步屏障等待操作。
TMA 的一個關鍵優點是,它可以釋放線程來執行其他獨立的工作。在 A100 上(圖 16 ,左圖),異步內存拷貝是使用一條特殊的LoadGlobalStoreShared指令執行的,因此線程負責生成所有地址并在整個拷貝區域中循環。
在 NVIDIA Hopper 上, TMA 負責一切。在啟動 TMA 之前,單個線程會創建一個拷貝描述符,從那時起,地址生成和數據移動將在硬件中處理。 TMA 提供了一個簡單得多的編程模型,因為它承擔了復制張量段時計算跨距、偏移和邊界計算的任務。
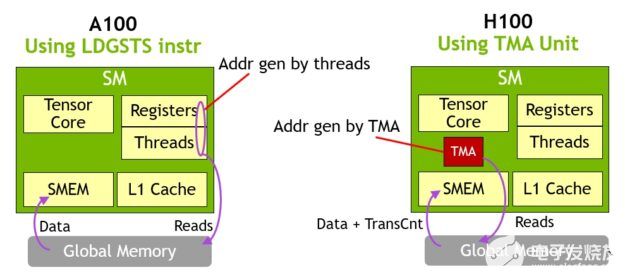
圖 16 。 H100 上 TMA 與 A100 上 LDGSTS 的異步內存復制
異步事務屏障
異步屏障最初引入NVIDIA 安培架構(圖 17 ,左)。考慮一組線程產生數據,它們在一個屏障之后都消耗的數據。異步屏障將同步過程分為兩個步驟。
首先,當線程完成生成其共享數據部分時,會向Arrive發送信號。此Arrive是非阻塞的,因此線程可以自由執行其他獨立工作。
最終,這些線程需要所有其他線程生成的數據。此時,它們執行一個Wait,這會阻止它們,直到每個線程都發出Arrive信號。
異步屏障的優點是,它們使提前到達的線程能夠在等待時執行獨立的工作。這種重疊是額外性能的來源。如果所有線程都有足夠的獨立工作,那么障礙實際上就沒有了,因為Wait指令可以立即失效,因為所有線程都已經到達。
NVIDIA Hopper 的新功能是 waiting 線程能夠在所有其他線程到達之前休眠。在以前的芯片上,等待線程會在共享內存中的屏障對象上旋轉。
盡管異步屏障仍然是NVIDIA 的漏斗編程模型的一部分,但它增加了一種新的屏障形式,稱為異步交易屏障。異步事務屏障類似于異步屏障(圖 17 ,右圖)。它也是一個分割屏障,但它不僅計算線程到達,還計算事務。
NVIDIA Hopper 包含一個用于寫入共享內存的新命令,該命令傳遞要寫入的數據和事務計數。事務計數本質上是字節計數。異步事務屏障在Wait命令處阻塞線程,直到所有生產者線程執行Arrive,并且所有事務計數之和達到預期值。
異步事務屏障是用于異步 mem 拷貝或數據交換的強大新原語。如前所述,集群可以通過隱含的同步進行線程塊到線程塊的數據交換,集群的能力建立在異步事務壁壘之上。
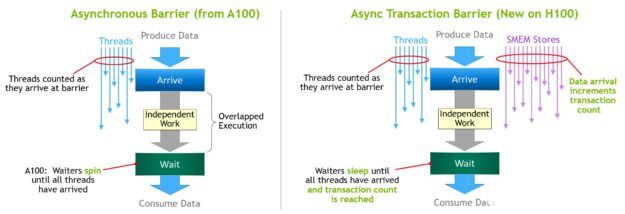
圖 17 。 A100 中的異步障礙與 H100 中的異步事務障礙
H100 HBM 和二級緩存內存體系結構
GPU 內存體系結構和層次結構的設計對應用程序性能至關重要,并影響 GPU 大小、成本、功耗和可編程性。 GPU 中存在許多內存子系統,從大量片外 DRAM (幀緩沖)設備內存、不同級別和類型的片上內存,到 SM 中用于計算的寄存器文件。
H100 HBM3 和 HBM2e DRAM 子系統
隨著 HPC 、 AI 和數據分析數據集的規模不斷擴大,計算問題變得越來越復雜,需要更大的 GPU 內存容量和帶寬。
NVIDIA P100 是世界上第一個支持高帶寬 HBM2 存儲技術的 GPU 體系結構。
NVIDIA V100 提供了更快、更高效、更高容量的 HBM2 實現。
NVIDIA A100 GPU 進一步增加 HBM2 的性能和容量。
H100 SXM5 GPU 通過支持 80 GB (五層)的快速 HBM3 內存,提供了超過 3 TB /秒的內存帶寬,實際上比兩年前推出的 A100 內存帶寬增加了 2 倍。 PCIe H100 提供 80 GB 的高速 HBM2e ,內存帶寬超過 2 TB /秒。
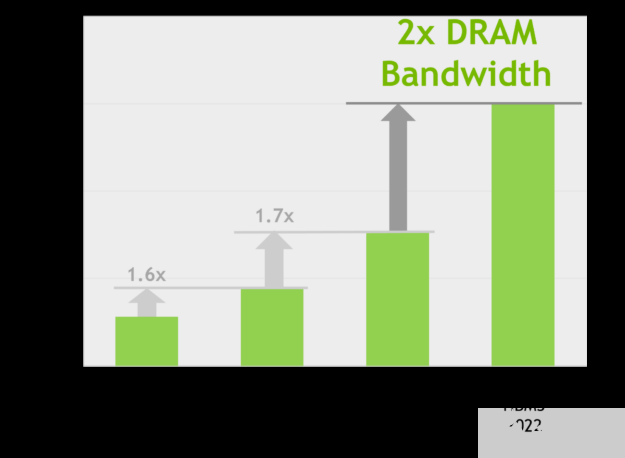
圖 18 。世界上第一款 HBM3 GPU 內存體系結構, 2 倍帶寬
內存數據速率未最終確定,可能會在最終產品中發生變化。
H100 二級緩存
H100 中的 50 MB 二級緩存比 A100 40 MB 二級緩存大 1.25 倍。它可以緩存更大部分的模型和數據集,以便重復訪問,減少對 HBM3 或 HBM2e DRAM 的訪問,并提高性能。
二級緩存使用分區交叉結構,對直接連接到分區的 GPC 中 SMs 的內存訪問進行本地化和緩存數據。二級緩存駐留控制優化容量利用率,使您能夠有選擇地管理應保留在緩存中或被逐出的數據。
HBM3 或 HBM2e DRAM 和二級緩存子系統都支持數據壓縮和解壓縮技術,以優化內存和緩存的使用和性能。
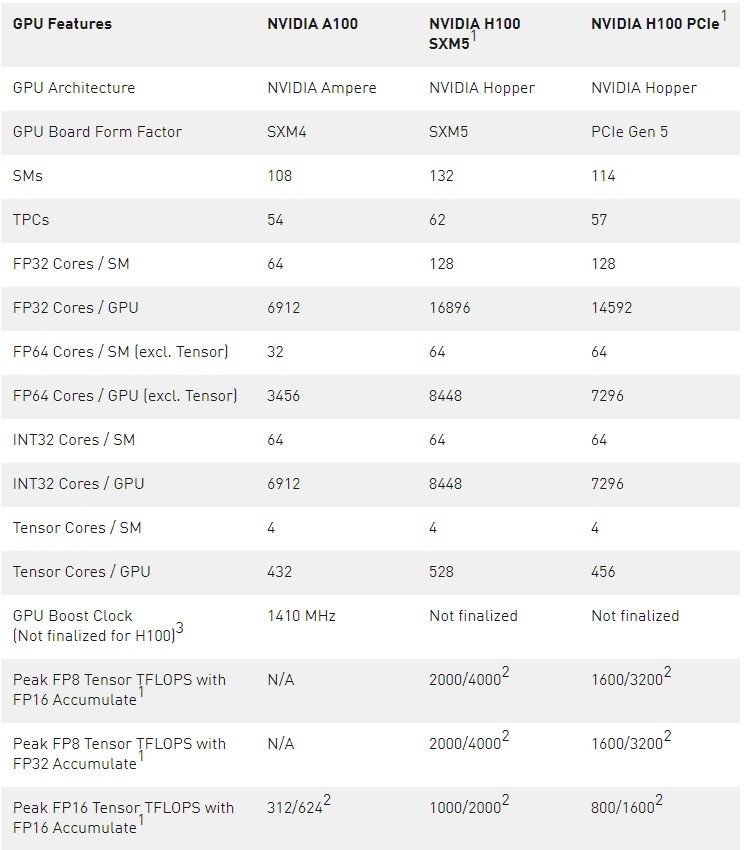
表 3 。比較 或NVIDIA A100 和 H1001數據中心 GPU
H100 的初步規格基于當前預期,并可能會在運輸產品中發生變化
使用稀疏特性的有效頂部/ t 頂部
GPU Peak Clock and GPU Boost Clock are synonymous for NVIDIA Data Center GPU
由于 H100 和 A100 Tensor Core GPU 設計用于安裝在高性能服務器和數據中心機架中,為 AI 和 HPC 計算負載供電,因此它們不包括顯示連接器、用于光線跟蹤加速的 NVIDIA RT Core 或 NVENC 編碼器。
計算能力
H100 GPU 支持新的計算能力 9.0 。表 4 比較了 NVIDIA GPU 體系結構不同計算能力的參數。
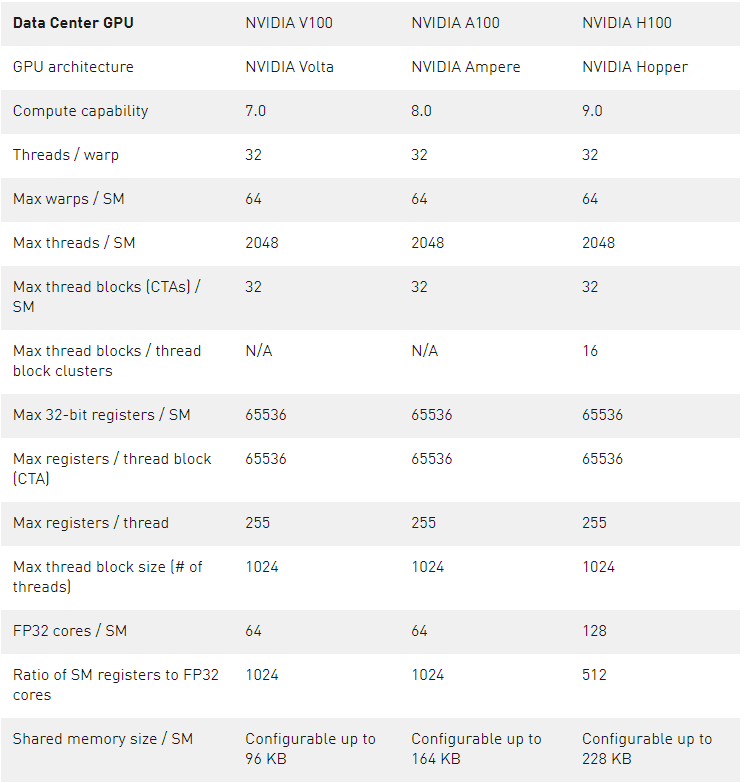
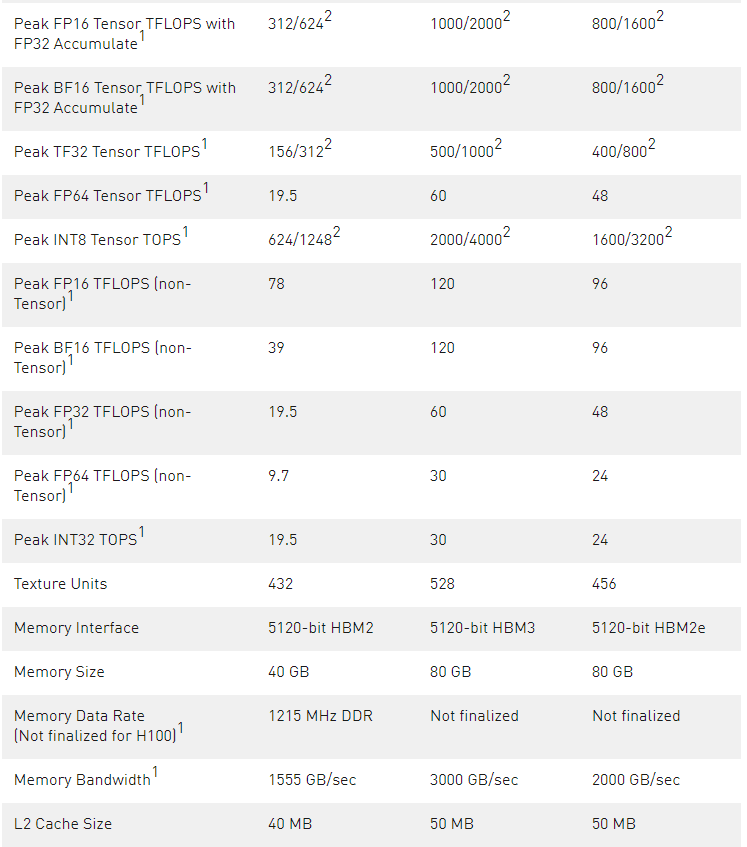
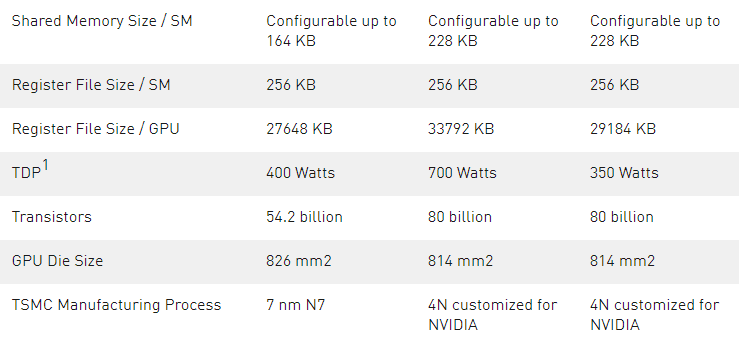
表 1 。計算能力: V100 vs.A100 vs.H100
Transformer 發動機
Transformer 模型是當今廣泛使用的語言模型(從 BERT 到 GPT-3 )的支柱,它們需要巨大的計算資源。 Transformers 最初是為自然語言處理( natural language processing , NLP )開發的,越來越多地應用于計算機視覺、藥物發現等不同領域。
它們的規模繼續呈指數級增長,現在已達到數萬億個參數,導致它們的培訓時間長達數月,這對于業務需求來說是不切實際的,因為需要大量計算。例如, Megatron 圖靈 NLG ( MT-NLG )需要 2048 NVIDIA A100 GPU 運行 8 周才能進行訓練。總體而言, transformer 模型在過去 5 年中以每 2 年 275 倍的速度增長,遠遠快于大多數其他人工智能模型(圖 19 )。
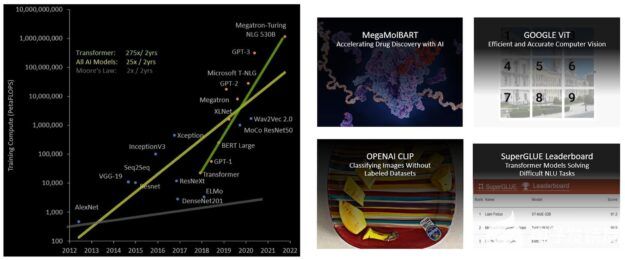
圖 19 。 transformer 模型尺寸隨著許多不同的用例呈指數增長
H100 包括一個新的 transformer 引擎,該引擎使用軟件和定制的 NVIDIA Hopper Tensor 核心技術,顯著加速變壓器的人工智能計算。
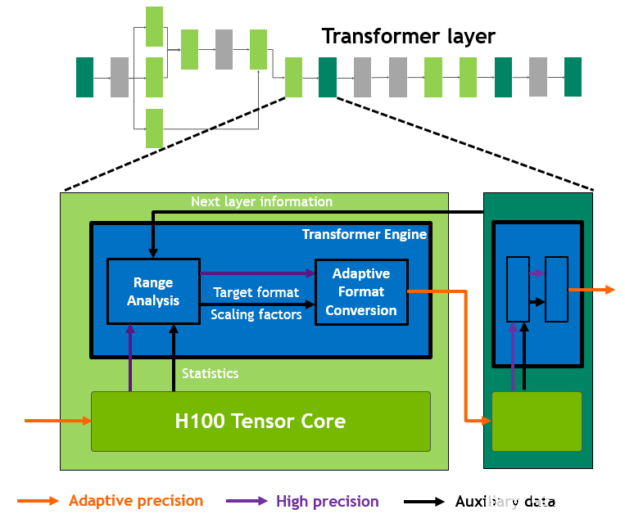
圖 20 。 transformer 發動機概念操作
混合精度的目標是智能地管理精度以保持精度,同時仍能獲得更小、更快的數值格式的性能。在 Transformer 模型的每一層, transformer 引擎分析張量核產生的輸出值的統計信息。
Transformer 引擎知道下一個是哪種類型的神經網絡層,以及它所需的精度,因此在將張量存儲到內存之前,還可以決定將張量轉換為哪種目標格式。與其他數字格式相比, FP8 的范圍更為有限。
為了最佳地使用可用范圍, Transformer 引擎還使用根據張量統計數據計算的比例因子,動態地將張量數據縮放到可表示的范圍。因此,每一層都以其所需的精確范圍運行,并以最佳方式加速。
第四代 NVLink 和 NVLink 網絡
新興的 exascale HPC 和萬億參數人工智能模型(用于超人類對話人工智能等任務)需要數月的訓練,即使是在超級計算機上。將這種延長的培訓時間從幾個月壓縮到幾天,以便對企業更有用,需要服務器集群中每個 GPU 之間進行高速、無縫的通信。 PCIe 帶寬有限,造成了瓶頸。為了構建最強大的端到端計算平臺,需要更快、更可擴展的 NVLink 互連。
NVLink 是NVIDIA 的高帶寬、節能、低延遲、無損 GPU 到 – GPU 互連,包括彈性特性,如鏈路級錯誤檢測和數據包重放機制,以保證數據的成功傳輸。新的第四代 NVLink 在 H100 GPU 中實現,與NVIDIA A100 張量核心 GPU 中使用的第三代 NVLink 相比,提供 1.5 倍的通信帶寬。
對于多 GPU I / O 和共享內存訪問,新的 NVLink 以 900 GB / s 的總帶寬運行,提供的帶寬是 PCIe Gen 5 的 7 倍。 A100 GPU 中的第三代 NVLink 在每個方向上使用四個差分對(通道),以創建單個鏈路,在每個方向上提供 25 GB / s 的有效帶寬。相比之下,第四代 NVLink 在每個方向上僅使用兩個高速差分對來形成單個鏈路,在每個方向上也提供 25 GB / s 的有效帶寬。
H100 包括 18 個第四代 NVLink 鏈路,可提供 900 GB / s 的總帶寬。
A100 包括 12 個第三代 NVLink 鏈路,可提供 600 GB /秒的總帶寬。
在第四代 NVLink 的基礎上, H100 還引入了新的 NVLink 網絡互連,這是 NVLink 的一個可擴展版本,使 GPU 能夠跨多個計算節點在多達 256 個 GPU 節點之間進行 GPU 通信。
與常規 NVLink 不同, NVLink 網絡引入了一個新的網絡地址空間,所有 GPU 共享一個公共地址空間,請求直接使用 GPU 物理地址路由。 H100 中的新地址轉換硬件支持將所有 GPU 地址空間彼此隔離,并與網絡地址空間隔離。這使得 NVLink 網絡能夠安全地擴展到更大數量的 GPU 。
由于 NVLink 網絡端點不共享公共內存地址空間,因此不會在整個系統中自動建立 NVLink 網絡連接。相反,與 InfiniBand 等其他網絡接口類似,用戶軟件應該根據需要明確地在端點之間建立連接。
第三代網絡交換機
新的第三代 NVSwitch 技術包括駐留在節點內部和外部的交換機,用于連接服務器、集群和數據中心環境中的多個 GPU 。節點內的每個新的第三代 NVSwitch 都提供 64 個第四代 NVLink 鏈路端口,以加速多 GPU 連接。交換機總吞吐量從上一代的 7.2 TB / s 增加到 13.6 TB / s 。
新的第三代 NVSwitch 還通過多播和 NVIDIA SHARP 在網絡縮減方面提供了集體操作的硬件加速。加速集體包括write broadcast(all_gather)、reduce_scatter和broadcast atomics。與在 A100 上使用 NVIDIA 集體通訊圖書館 ( NCCL )相比,結構內多播和減少提供了高達 2 倍的吞吐量增益,同時顯著減少了小數據塊大小集合的延遲。 NVSwitch collectives 的加速功能顯著降低了短信在集體通信中的負載。
新型 NVLink 交換系統
結合新的 NVLINK 網絡技術和新的第三代 NVSwitch , NVIDIA 能夠以前所未有的通信帶寬水平構建大規模 NVLINK 交換系統網絡。每個 GPU 節點暴露出節點中 GPU 的所有 NVLink 帶寬的 2:1 錐形級別。這些節點通過 NVLink 交換機模塊中包含的第二級 NVSwitch 連接在一起, NVLink 交換機模塊位于計算節點之外,并將多個節點連接在一起。
NVLink 交換機系統最多支持 256 GPU 。連接的節點可以提供 57.6 TB 的全對全帶寬,并可以提供令人難以置信的 FP8 稀疏人工智能計算的 1 倍。
圖 21 顯示了基于 A100 和 H100 的 32 節點 256 GPU DGX 疊加的比較。基于 H100 的 SuperPOD 使用新的 NVLink 交換機互連 DGX 節點。
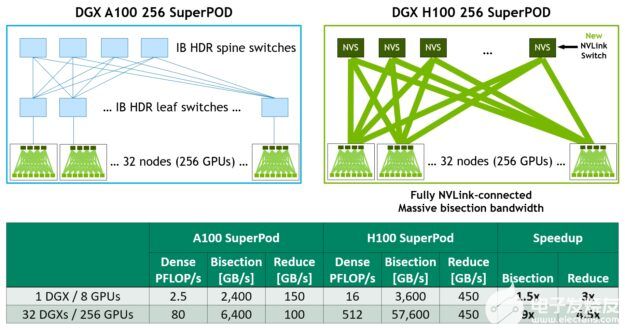
圖 21 。 DGX A100 與 DGX H100 256 節點 NVIDIA SuperPOD 架構比較
DGX H100 SuperPads 可跨越多達 256 GPU ,使用基于第三代 NVSwitch 技術的新型 NVLink 交換機,通過 NVLink 交換機系統完全連接。如圖所示,與基于 A100 、具有類似規模、采用 leaf spine 架構的機器相比, H100 系統根本不需要 InfiniBand 連接。
例如,與上一代 InfiniBand 系統相比,采用 2:1 錐形胖樹拓撲結構的 NVLink 網絡互連使所有對所有交換機的對分帶寬增加了 9 倍,使所有減少的吞吐量增加了 4.5 倍。
PCIe 第 5 代
H100 集成了 PCI Express Gen 5 x16 通道接口,提供 128 GB / s 的總帶寬(每個方向 64 GB / s ),而 A100 中包含的 Gen 4 PCIe 總帶寬為 64 GB / s (每個方向 32 GB / s )。
使用其 PCIe Gen 5 接口, H100 可以與性能最高的 x86 CPU 和 SmartNICs 以及 數據處理器 ( DPU )接口。 H100 設計用于與 NVIDIA BlueField-3 DPU 的最佳連接,用于 400 Gb / s 以太網或下一個數據速率( NDR ) 400 Gb / s InfiniBand 網絡加速,用于安全的 HPC 和 AI 工作負載。
H100 增加了對本機 PCIe 原子操作的支持,如 32 位和 64 位數據類型的原子 CA 、原子交換和原子提取添加,加快了 CPU 和 GPU 之間的同步和原子操作。 H100 還支持單根輸入/輸出虛擬化( SR-IOV ),該虛擬化支持為多個進程或虛擬機共享和虛擬化單個 PCIe 連接的 GPU 。 H100 允許連接 GPU 的單個 SR-IOV PCIe 的虛擬功能( VF )或物理功能( PF )通過 NVLink 訪問對等方 GPU 。
關于作者
Michael Andersch 是NVIDIA 首席 GPU 建筑師和高級建筑經理。他在計算架構團隊開始了自己的職業生涯,在那里他專注于提升 GPU 的能力,以應對世界上各種 CUDA 工作負載。近年來, Michael 推動了硬件和軟件的改進,特別是為了提高深度神經網絡訓練的性能,他的團隊現在參與到訓練性能至關重要的任何地方;從調整深度學習社區的最新神經網絡到設計下一代 GPU 。
Greg Palmer 是 GPU 建筑集團的NVIDIA 杰出工程師。自 2006 年費米一代以來,格雷格一直擔任 GPU 前端管道的系統架構師。他主要關注 GPU 內的工作分配和調度、上下文調度和同步、圖形和計算搶占機制,以及多實例 GPU 功能。在加入NVIDIA 之前,格雷格曾在幾家超級計算和網絡初創公司設計過 ASIC 。
Ronny Krashinsky 設計 NVIDIA GPU 已有 10 年。他開始了他的 NVIDIA 研究生涯,后來加入了流式多處理器團隊,設計了 voltasm 。羅尼是 100 個深度學習特性的首席架構師,他現在管理著 NVIDIA 的深度學習架構路線圖。
Vishal 是 NVIDIA 的高級開發技術工程師,專注于 GPU 應用程序的性能優化。他在 GPU 計算領域工作了 10 多年。他熱衷于向用戶教授 CUDA 和 GPU 計算,并推動 CUDA 編程指南的內容。他的日常活動包括與領域科學家和行業專家合作,以改善他們在 GPU 上的工作負載。
Nick Stam 是NVIDIA 的高級技術營銷總監。他的團隊為媒體和行業分析師提供技術支持,同時還生成白皮書和評論員輔助資料。在加入 NVIDIA 之前, Nick 曾在 PC 雜志《美國》工作多年,并與他人共同創建了 ExtremeTech 網站。自 1980 年以來,尼克一直在計算機行業擔任各種技術和管理職位。
Gonzalo Brito 是 NVIDIA 計算性能與 HPC 團隊的高級開發技術工程師,工作于硬件和軟件的交叉點。他熱衷于讓加速計算變得更容易實現。在加入NVIDIA 之前,岡薩洛在 RWTH 亞琛大學空氣動力學研究所開發了多物理方法,用于顆粒流。
Sridhar Ramaswamy 是NVIDIA 的技術營銷總監。他的團隊通過白皮書、技術產品指南和嵌入式人工智能計算、機器學習、云游戲、流媒體設備和自動駕駛汽車領域的其他輔助資料,幫助媒體和分析師了解 NVIDIA 的產品和技術。在加入 NVIDIA 之前, Sridhar 自 1996 年起擔任幾代圖形芯片組的首席工程師和架構師。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102828 -
gpu
+關注
關注
28文章
4703瀏覽量
128726 -
PCIe
+關注
關注
15文章
1227瀏覽量
82454
發布評論請先 登錄
相關推薦
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
GPU服務器AI網絡架構設計

軟銀升級人工智能計算平臺,安裝4000顆英偉達Hopper GPU
NVIDIA Colossus超級計算機集群突破10萬顆Hopper GPU
NVIDIA 以太網加速 xAI 構建的全球最大 AI 超級計算機

AMD與NVIDIA GPU優缺點
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
倫敦商學院深入研究中國神州數碼戰略轉型

進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
NVIDIA推出兩款基于NVIDIA Ampere架構的全新臺式機GPU
NVIDIA的Maxwell GPU架構功耗不可思議

深入解讀AMD最新GPU架構
英偉達Grace-Hopper提供一個緊密集成的CPU + GPU解決方案
揭秘GPU: 高端GPU架構設計的挑戰

AWS成為第一個提供NVIDIA GH200 Grace Hopper超級芯片的提供商





 工商網監
工商網監
評論