") 無(wú)服務(wù)器架構(gòu)的基本概念及運(yùn)維
無(wú)服務(wù)器架構(gòu)的基本概念及運(yùn)維
前言
在介紹運(yùn)維之前,大家先來(lái)快速了解一下無(wú)服務(wù)器(serverless)的概念。由于筆者的實(shí)戰(zhàn)經(jīng)驗(yàn)是在AWS平臺(tái)上,本文中出現(xiàn)的無(wú)服務(wù)器均指使用AWS Lambda構(gòu)建的serverless應(yīng)用。Serverless的特點(diǎn)是用戶無(wú)需預(yù)配置或管理服務(wù)器,只需要部署功能代碼,服務(wù)會(huì)在需要的時(shí)候執(zhí)行代碼并自動(dòng)伸縮,從每天幾個(gè)請(qǐng)求到每秒數(shù)千個(gè)請(qǐng)求,輕松地實(shí)現(xiàn)FaaS(Function as a Service)。如下圖所示:
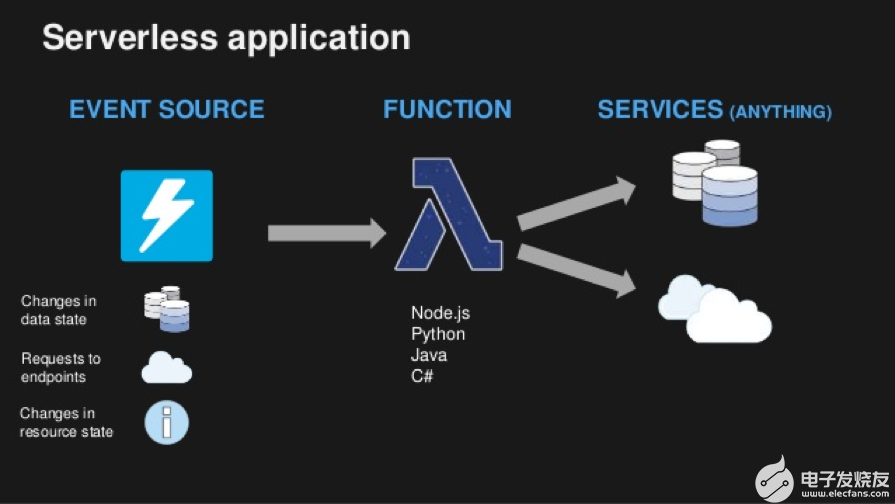
(圖片來(lái)自網(wǎng)絡(luò))
在傳統(tǒng)的應(yīng)用中,開(kāi)發(fā)團(tuán)隊(duì)除了需要編寫(xiě)功能代碼,還要監(jiān)控實(shí)時(shí)負(fù)載,并相應(yīng)地對(duì)應(yīng)用進(jìn)行伸縮,還要處理一些因非功能性故障導(dǎo)致的停機(jī)(硬盤(pán)、內(nèi)存等)。而無(wú)服務(wù)器架構(gòu)則將開(kāi)發(fā)團(tuán)隊(duì)從服務(wù)器維護(hù)的工作中解放出來(lái),繼而能更專注在功能代碼上(圖中的Function)。在實(shí)際的項(xiàng)目里,開(kāi)發(fā)者只需將功能代碼打包上傳到AWS Lambda,再進(jìn)行少量配置(環(huán)境變量,觸發(fā)條件,內(nèi)存,超時(shí)時(shí)間等)即可將應(yīng)用/服務(wù)上線。
以上是無(wú)服務(wù)器架構(gòu)的基本概念。接下來(lái),筆者將從日志,指標(biāo),監(jiān)控及報(bào)警,災(zāi)備這四個(gè)維度來(lái)介紹無(wú)服務(wù)器架構(gòu)下的運(yùn)維。
日志
默認(rèn)情況下,應(yīng)用運(yùn)行時(shí)產(chǎn)生的日志會(huì)保存在應(yīng)用服務(wù)器本機(jī),在需要查看日志的時(shí)候,需要運(yùn)維人員遠(yuǎn)程登錄到這臺(tái)服務(wù)器獲取日志信息。這種方式操作起來(lái)稍顯繁瑣,而且當(dāng)應(yīng)用服務(wù)器的數(shù)量增多后,由于需要先找出產(chǎn)生錯(cuò)誤信息的那臺(tái)服務(wù)器,會(huì)嚴(yán)重降低查找日志的效率。
一種解決辦法是ELK(ElasticSearch, Logstash, Kibana),這三個(gè)開(kāi)源工具各司其職,Logstash負(fù)責(zé)日志的推送和轉(zhuǎn)換,ElasticSearch作為數(shù)據(jù)庫(kù)與搜索引擎,Kibana作為圖形界面。好處是搭建容易,良好的伸縮性,以及免費(fèi)。但帶來(lái)的額外成本是,獨(dú)立出來(lái)的日志服務(wù)也需要做好全方位的監(jiān)控(應(yīng)用狀態(tài),硬盤(pán),網(wǎng)絡(luò)等),避免因?yàn)榛A(chǔ)服務(wù)的問(wèn)題導(dǎo)致系統(tǒng)全面故障。
AWS無(wú)服務(wù)器架構(gòu)中的日志是一個(gè)開(kāi)箱即用的服務(wù),所有日志自動(dòng)采集到AWS CloudWatch Logs中,只要根據(jù)服務(wù)名稱找到對(duì)應(yīng)的日志組,即可進(jìn)行查詢搜索,不需要任何配置,也沒(méi)有任何維護(hù)成本。
指標(biāo)
通常情況下,運(yùn)維工作會(huì)包含采集線上應(yīng)用的運(yùn)行指標(biāo),來(lái)反映應(yīng)用的健康狀況,故障率,性能,訪問(wèn)量,訪問(wèn)頻率等。這里以一個(gè)使用Spring Boot構(gòu)建的API服務(wù)來(lái)舉例,Spring Boot中的Actuator扮演了采集指標(biāo)的角色。默認(rèn)配置下,對(duì)于每個(gè)API,Actuator會(huì)自動(dòng)采集以下幾個(gè)指標(biāo):
uri,例如/api/person/{id}
method,例如GET或POST
status,例如200或500
當(dāng)然我們可以通過(guò)實(shí)現(xiàn)一些接口來(lái)擴(kuò)展/自定義采集指標(biāo),這里就不展開(kāi)了。有了指標(biāo)數(shù)據(jù),還需要對(duì)應(yīng)的報(bào)表或儀表盤(pán)工具,以便更好地查詢和展示,可以選擇像Prometheus,Grafana這樣的工具。
那么AWS無(wú)服務(wù)器架構(gòu)是否提供了類(lèi)似的指標(biāo)采集呢?答案是肯定的,AWS CloudWatch Metrics自動(dòng)采集了Lambda function的以下四個(gè)指標(biāo):
Invocations(實(shí)際調(diào)用量)
Errors
Duration(執(zhí)行時(shí)間)
Throttles(超過(guò)并行限制而被阻止的調(diào)用的數(shù)量)
Invocations和Errors取一段時(shí)間的總數(shù),結(jié)合二者可以得出應(yīng)用的錯(cuò)誤率,如下
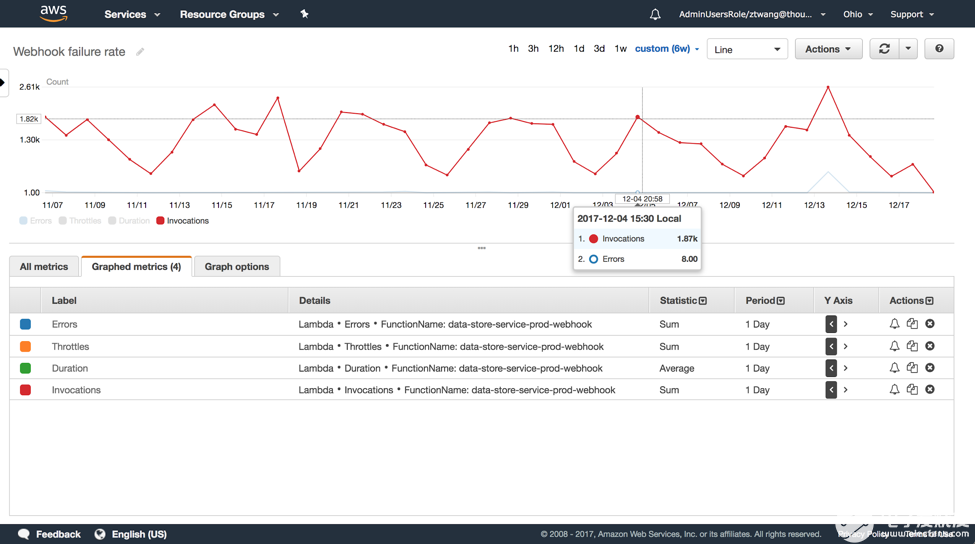
Duration則通過(guò)取平均數(shù)來(lái)反映一段時(shí)間的性能表現(xiàn),在筆者的項(xiàng)目中Lambda function的耗時(shí)主要集中在SQL的查詢上,這個(gè)數(shù)字可以相應(yīng)地反映技術(shù)人員對(duì)查詢優(yōu)化的效果。當(dāng)然,在實(shí)際情況中,這些檢驗(yàn)都可以在預(yù)發(fā)布環(huán)境下進(jìn)行,這個(gè)例子只是為了方便理解。
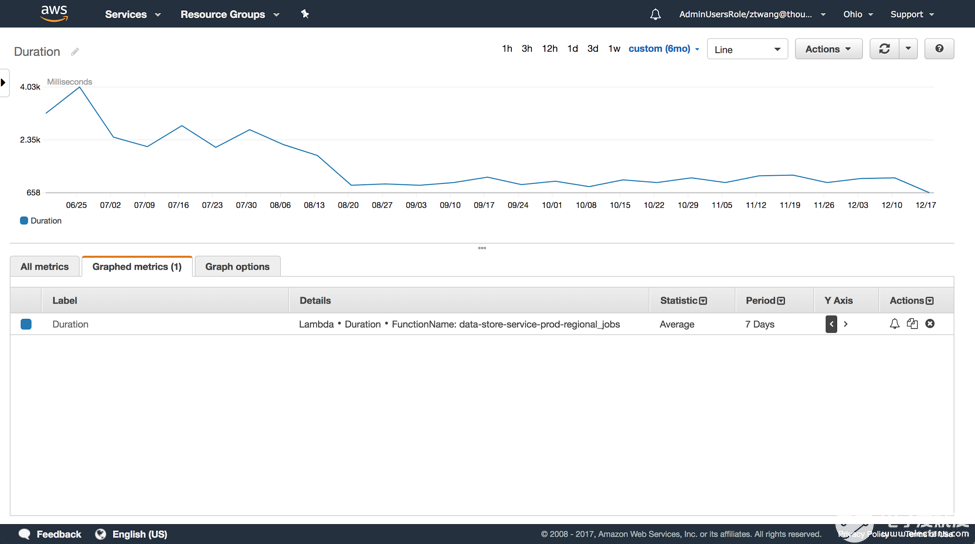
在筆者目前的項(xiàng)目中,Throttle并未被使用到,默認(rèn)的并發(fā)限制是1000/秒,而用量最大的Lambda function的調(diào)用頻率也不過(guò)每分鐘150次,距離超限差得很遠(yuǎn),不過(guò)這一數(shù)據(jù)對(duì)于并發(fā)高的應(yīng)用有很重要的意義。
除了開(kāi)箱即用的幾個(gè)指標(biāo)以外,還可以結(jié)合CloudWatch metrics的API,在相應(yīng)的功能代碼中埋點(diǎn),定制化采集指標(biāo)。例如,對(duì)于一個(gè)Lambda function,代碼里三個(gè)子task,默認(rèn)提供的Duration只能反映總體的運(yùn)行效率,如果需要統(tǒng)計(jì)每個(gè)task的消耗,就需要用到AWS CloudWatch metrics API。
監(jiān)控&報(bào)警
監(jiān)控的意義在于全面了解應(yīng)用的資源使用率,性能和運(yùn)行情況,這些數(shù)據(jù)可以用來(lái)幫助團(tuán)隊(duì)及時(shí)作出調(diào)整,保證應(yīng)用程序順暢運(yùn)行。這通常包括CPU使用率,數(shù)據(jù)傳輸,磁盤(pán)使用等。在突發(fā)狀況導(dǎo)致系統(tǒng)不可用的時(shí)候,團(tuán)隊(duì)的響應(yīng)速度,往往取決于監(jiān)控和報(bào)警的及時(shí)性,全面性和準(zhǔn)確度。如果能在對(duì)歷史數(shù)據(jù)的分析之上對(duì)監(jiān)控系統(tǒng)進(jìn)行合理的配置,團(tuán)隊(duì)甚至能預(yù)測(cè)不好的事情將要發(fā)生,提前做好防范,未雨綢繆。
同上,這里還是以一個(gè)Spring Boot應(yīng)用為例,在上一小節(jié)指標(biāo)數(shù)據(jù)的采集中提到過(guò)Actuator,事實(shí)上Actuator除了可以記錄上面提到的指標(biāo),還可以用來(lái)收集監(jiān)控?cái)?shù)據(jù)。這里我們只需要設(shè)置一個(gè)Spring Boot Admin應(yīng)用,給需要進(jìn)行監(jiān)控的應(yīng)用加上Spring Boot Admin client配置,監(jiān)控?cái)?shù)據(jù)就會(huì)通過(guò)Actuator暴露的API傳遞給Spring Boot Admin。
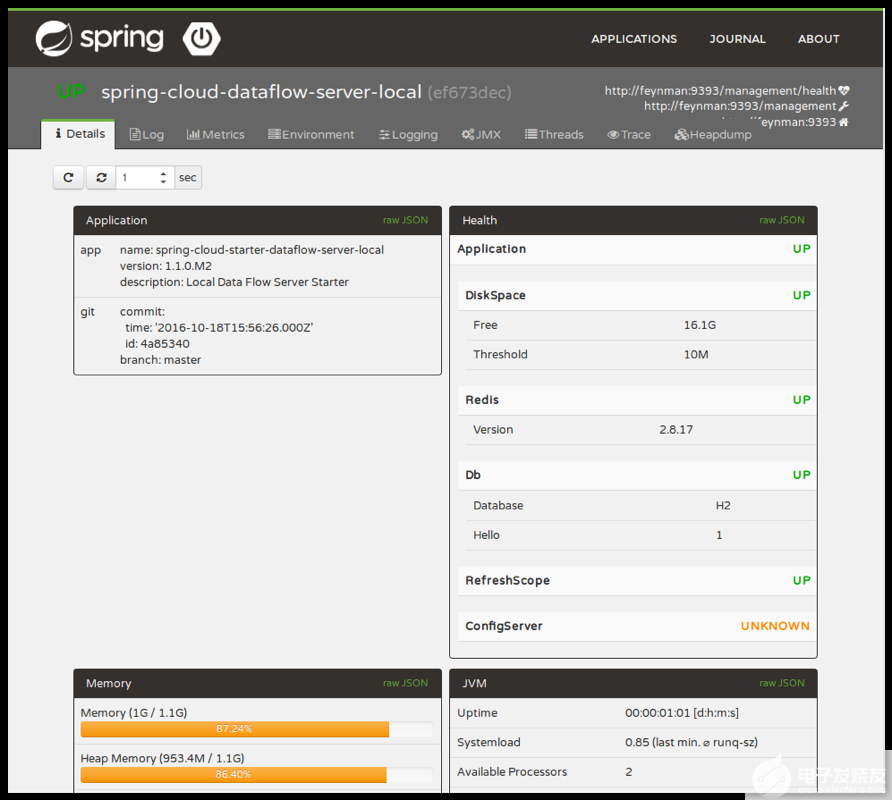
報(bào)警功能一般則要根據(jù)實(shí)際情況自行實(shí)現(xiàn)。Spring Boot Admin中實(shí)現(xiàn)了對(duì)Pagerduty,Slack等第三方工具的集成,如果只是需要簡(jiǎn)單的郵件提醒,實(shí)現(xiàn)起來(lái)也不復(fù)雜,這里就不展開(kāi)了。
隨著云上基礎(chǔ)設(shè)施的普及,上面提到的監(jiān)控和報(bào)警早已是各個(gè)平臺(tái)的標(biāo)準(zhǔn)配置,根本輪不到開(kāi)發(fā)者去操心如何實(shí)現(xiàn)及維護(hù),運(yùn)營(yíng)團(tuán)隊(duì)可以把更多的精力放在配置優(yōu)化的工作中去。
AWS默認(rèn)提供了非常完備的監(jiān)控?cái)?shù)據(jù),也允許自定義監(jiān)控dashboard,通過(guò)把一系列重要的指標(biāo)添加到創(chuàng)建好的dashboard中,應(yīng)用的運(yùn)行狀況一目了然。
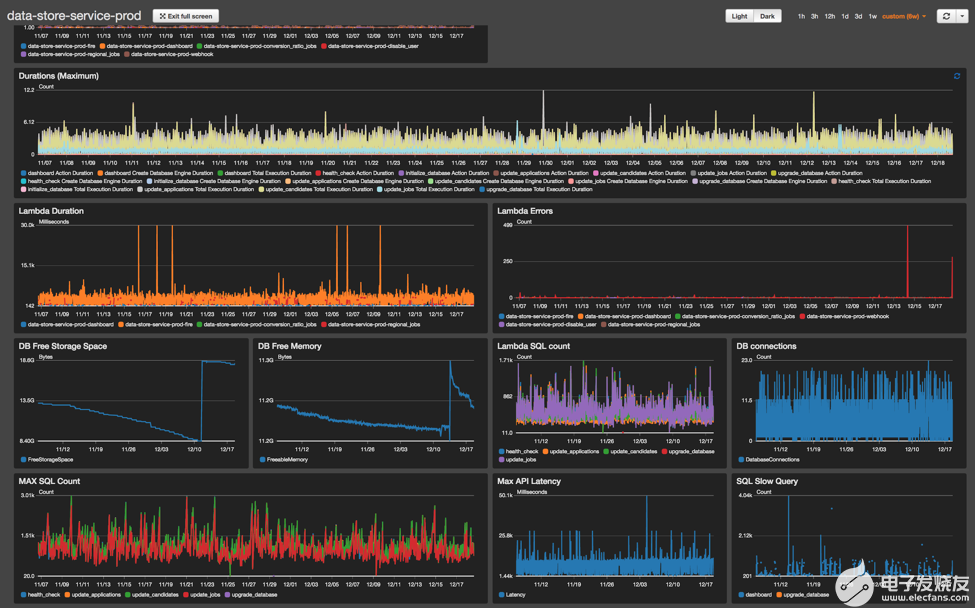
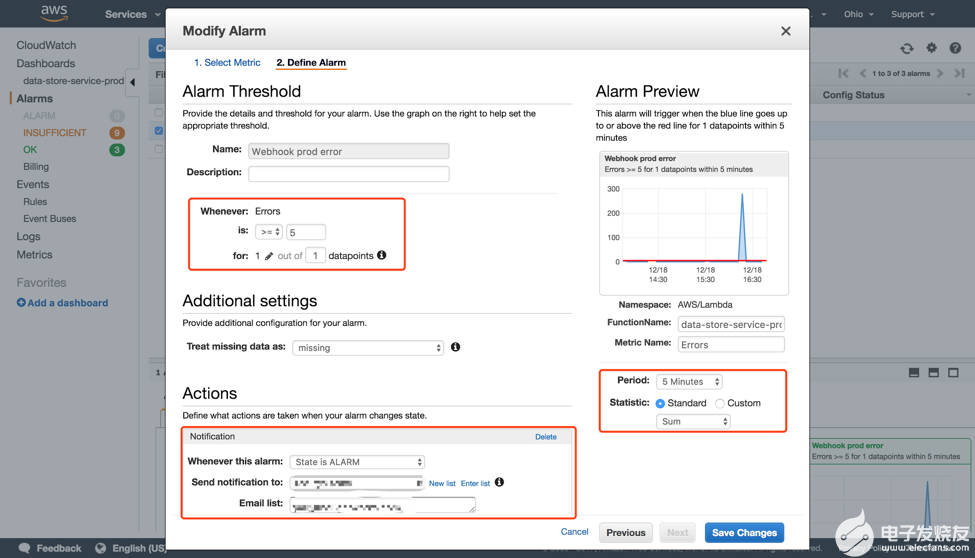
前面已經(jīng)提到過(guò),在出現(xiàn)錯(cuò)誤,或性能底下時(shí),根據(jù)某些關(guān)鍵指標(biāo)的變動(dòng)情況發(fā)送警告通知非常必要。筆者所在的項(xiàng)目的做法是使用AWS CloudWatch和AWS SNS提供的告警通知功能,只需要先選擇指標(biāo)然后設(shè)定觸發(fā)閾值和檢查間隔時(shí)間即可,AWS SNS支持HTTP、SMS、Email等多種訂閱方式。下圖展示了如何設(shè)定當(dāng)某個(gè)Lambda在過(guò)去5分鐘內(nèi)發(fā)生了5次以上錯(cuò)誤的時(shí)候發(fā)送通知。
災(zāi)難備份&恢復(fù)
在系統(tǒng)鏡像,構(gòu)建工具還有容器技術(shù)越來(lái)越普及的今天,災(zāi)難備份的意義很大程度上是為了有效保護(hù)重要數(shù)據(jù)。通常的做法是設(shè)定一些定期任務(wù),將數(shù)據(jù)傳輸?shù)竭h(yuǎn)端的災(zāi)備中心,從物理上抵御不可抗災(zāi)難。如果數(shù)據(jù)量過(guò)大,出現(xiàn)網(wǎng)絡(luò)傳輸效率跟不上的情況,可以參考AWS用卡車(chē)?yán)瓟?shù)據(jù)的解決辦法。
真正需要用到災(zāi)難備份的情況在筆者有限的經(jīng)歷中還沒(méi)有發(fā)生過(guò),但是如果不未雨綢繆,真正發(fā)生時(shí)的后果將難以設(shè)想。筆者項(xiàng)目中用到的AWS RDS默認(rèn)啟用了以7天為周期的自動(dòng)備份,這個(gè)配置可以手動(dòng)調(diào)整也可以將配置寫(xiě)入構(gòu)建基礎(chǔ)設(shè)施的腳本中去。 如果災(zāi)難真的發(fā)生,光有數(shù)據(jù)備份是不夠的,還需要能夠快速重建應(yīng)用運(yùn)行時(shí)的基礎(chǔ)設(shè)施。筆者所在的團(tuán)隊(duì)(下文簡(jiǎn)稱團(tuán)隊(duì))分別使用了AWS CloudFormation和Serverless framework,CloudFormation用來(lái)重建數(shù)據(jù)庫(kù)、網(wǎng)絡(luò)等基礎(chǔ)設(shè)施,Serverless framework用來(lái)重建Lambda function,在重建數(shù)據(jù)庫(kù)的時(shí)候,通過(guò)持續(xù)集成流水線,以環(huán)境變量的方式傳入最近一次數(shù)據(jù)備份快照的Id,15分鐘以內(nèi)即可重建一套產(chǎn)品環(huán)境。
總結(jié)
筆者所在的團(tuán)隊(duì)是10個(gè)人左右的配置,采用結(jié)對(duì)編程的方式,3對(duì)pair,包含web端、業(yè)務(wù)層、數(shù)據(jù)層。從產(chǎn)品原型確定到第一次上線(MVP)耗時(shí)30天,每周至少發(fā)布一次新版本,story的平均交付時(shí)間(cycle time,從需求確定到上線)為8天。這樣的速度也許不能算快,但是如果沒(méi)有Serverless架構(gòu)在運(yùn)維端提供的支持,我們想要在交付速度上有更高的突破會(huì)困難得多。
最后來(lái)談一下成本,俗話說(shuō)拋開(kāi)商業(yè)化談技術(shù)都是耍流氓,大部分人看到一個(gè)強(qiáng)大易用的工具都會(huì)下意識(shí)里覺(jué)得開(kāi)銷(xiāo)會(huì)很大。實(shí)際上并不是這樣,我們做了一個(gè)粗算,選用雙核CPU,8G內(nèi)存的M4型服務(wù)器,開(kāi)銷(xiāo)是$72每月。dev,staging,prod三個(gè)環(huán)境都用同樣的配置就是$216每月,而實(shí)際上Lambda每個(gè)月的開(kāi)銷(xiāo)包含所有環(huán)境在$20左右,需要注意的是Lambda的計(jì)費(fèi)是根據(jù)使用量來(lái)的,我們的API訪問(wèn)大約在150萬(wàn)每月的量級(jí)。可以預(yù)見(jiàn)到當(dāng)訪問(wèn)達(dá)到一定數(shù)量的時(shí)候Lambda的開(kāi)銷(xiāo)會(huì)和使用服務(wù)器的方案持平甚至更大,但是在量小的時(shí)候優(yōu)勢(shì)明顯。
得益于強(qiáng)大的AWS生態(tài),利用Lambda構(gòu)建的無(wú)服務(wù)器應(yīng)用經(jīng)過(guò)少量甚至無(wú)需任何配置,即可以極低的價(jià)格獲得完整的運(yùn)維功能和體驗(yàn)。與自己利用開(kāi)源工具進(jìn)行搭建的方式相比,研發(fā)團(tuán)隊(duì)可以從繁瑣的運(yùn)維工作——特別是基礎(chǔ)工程搭建——中解脫出來(lái),更加專注于產(chǎn)品本身,極大的提高軟件交付速度,可用性、可靠性和可擴(kuò)展性也相當(dāng)有保障。換來(lái)的代價(jià)是更高的遷移成本,某些功能的不可定制化可能成為瓶頸,以及對(duì)底層實(shí)現(xiàn)原理的屏蔽也可能對(duì)開(kāi)發(fā)者的學(xué)習(xí)和成長(zhǎng)有影響。
審核編輯:湯梓紅
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9028瀏覽量
85194 -
架構(gòu)
+關(guān)注
關(guān)注
1文章
510瀏覽量
25449 -
運(yùn)維
+關(guān)注
關(guān)注
1文章
253瀏覽量
7544
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
SSR與傳統(tǒng)服務(wù)器的對(duì)比分析
GPU服務(wù)器AI網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)

如何優(yōu)化Linux服務(wù)器的性能
基于高通主板的ARM架構(gòu)服務(wù)器
美國(guó)輕量云服務(wù)器是什么?和云服務(wù)器有哪些區(qū)別
S參數(shù)的概念及應(yīng)用
如何在阿里ECS服務(wù)器上架設(shè)自己的OpenVPN服務(wù)器?
ai服務(wù)器是什么架構(gòu)類(lèi)型
接口測(cè)試怎么測(cè)多個(gè)服務(wù)器連接
華為云函數(shù)工作流:引領(lǐng)未來(lái)無(wú)服務(wù)器計(jì)算時(shí)代

什么是DTU和串口服務(wù)器的區(qū)別
訊維運(yùn)維管理平臺(tái):從基礎(chǔ)運(yùn)維到智能運(yùn)維的飛躍
如何使用dd命令來(lái)查看服務(wù)器磁盤(pán)的IO性能呢?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論