") 深度學(xué)習(xí):神經(jīng)網(wǎng)絡(luò)和函數(shù)
深度學(xué)習(xí):神經(jīng)網(wǎng)絡(luò)和函數(shù)
據(jù)報(bào)道稱,由于采用基于云的技術(shù)和在大數(shù)據(jù)中使用深度學(xué)習(xí)系統(tǒng),深度學(xué)習(xí)的使用在過去十年中迅速增長(zhǎng),預(yù)計(jì)到 2028 年,深度學(xué)習(xí)的市場(chǎng)規(guī)模將達(dá)到 930 億美元。但究竟什么是深度學(xué)習(xí),它是如何工作的?深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)子集,它使用神經(jīng)網(wǎng)絡(luò)來執(zhí)行學(xué)習(xí)和預(yù)測(cè)。深度學(xué)習(xí)在各種任務(wù)中都表現(xiàn)出了驚人的表現(xiàn),無論是文本、時(shí)間序列還是計(jì)算機(jī)視覺。深度學(xué)習(xí)的成功主要來自大數(shù)據(jù)的可用性和計(jì)算能力。然而,不僅如此,這使得深度學(xué)習(xí)遠(yuǎn)遠(yuǎn)優(yōu)于任何經(jīng)典的機(jī)器學(xué)習(xí)算法。
深度學(xué)習(xí):神經(jīng)網(wǎng)絡(luò)和函數(shù)
神經(jīng)網(wǎng)絡(luò)是一個(gè)相互連接的神經(jīng)元網(wǎng)絡(luò),每個(gè)神經(jīng)元都是一個(gè)有限函數(shù)逼近器。這樣,神經(jīng)網(wǎng)絡(luò)被視為通用函數(shù)逼近器。如果你還記得高中的數(shù)學(xué),函數(shù)就是從輸入空間到輸出空間的映射。一個(gè)簡(jiǎn)單的 sin(x) 函數(shù)是從角空間(-180° 到 180° 或 0° 到 360°)映射到實(shí)數(shù)空間(-1 到 1)。 讓我們看看為什么神經(jīng)網(wǎng)絡(luò)被認(rèn)為是通用函數(shù)逼近器。每個(gè)神經(jīng)元學(xué)習(xí)一個(gè)有限的函數(shù):f(.) = g(W*X) 其中 W 是要學(xué)習(xí)的權(quán)重向量,X 是輸入向量,g(.) 是非線性變換。W*X 可以可視化為高維空間(超平面)中的一條線(正在學(xué)習(xí)),而 g(.) 可以是任何非線性可微函數(shù),如 sigmoid、tanh、ReLU 等(常用于深度學(xué)習(xí)領(lǐng)域)。在神經(jīng)網(wǎng)絡(luò)中學(xué)習(xí)無非就是找到最佳權(quán)重向量 W。例如,在 y = mx+c 中,我們有 2 個(gè)權(quán)重:m 和 c。現(xiàn)在,根據(jù) 2D 空間中點(diǎn)的分布,我們找到滿足某些標(biāo)準(zhǔn)的 m & c 的最佳值:對(duì)于所有數(shù)據(jù)點(diǎn),預(yù)測(cè) y 和實(shí)際點(diǎn)之間的差異最小。
層的效果
現(xiàn)在每個(gè)神經(jīng)元都是一個(gè)非線性函數(shù),我們將幾個(gè)這樣的神經(jīng)元堆疊在一個(gè)「層」中,每個(gè)神經(jīng)元接收相同的一組輸入但學(xué)習(xí)不同的權(quán)重 W。因此,每一層都有一組學(xué)習(xí)函數(shù):[f1, f2, …, fn],稱為隱藏層值。這些值再次組合,在下一層:h(f1, f2, ..., fn) 等等。這樣,每一層都由前一層的函數(shù)組成(類似于 h(f(g(x))))。已經(jīng)表明,通過這種組合,我們可以學(xué)習(xí)任何非線性復(fù)函數(shù)。 深度學(xué)習(xí)是具有許多隱藏層(通常 > 2 個(gè)隱藏層)的神經(jīng)網(wǎng)絡(luò)。但實(shí)際上,深度學(xué)習(xí)是從層到層的函數(shù)的復(fù)雜組合,從而找到定義從輸入到輸出的映射的函數(shù)。例如,如果輸入是獅子的圖像,輸出是圖像屬于獅子類的圖像分類,那么深度學(xué)習(xí)就是學(xué)習(xí)將圖像向量映射到類的函數(shù)。類似地,輸入是單詞序列,輸出是輸入句子是否具有正面/中性/負(fù)面情緒。因此,深度學(xué)習(xí)是學(xué)習(xí)從輸入文本到輸出類的映射:中性或正面或負(fù)面。
深度學(xué)習(xí)作為插值
從生物學(xué)的解釋來看,人類通過逐層解釋圖像來處理世界的圖像,從邊緣和輪廓等低級(jí)特征到對(duì)象和場(chǎng)景等高級(jí)特征。神經(jīng)網(wǎng)絡(luò)中的函數(shù)組合與此一致,其中每個(gè)函數(shù)組合都在學(xué)習(xí)關(guān)于圖像的復(fù)雜特征。用于圖像的最常見的神經(jīng)網(wǎng)絡(luò)架構(gòu)是卷積神經(jīng)網(wǎng)絡(luò) (CNN),它以分層方式學(xué)習(xí)這些特征,然后一個(gè)完全連接的神經(jīng)網(wǎng)絡(luò)將圖像特征分類為不同的類別。 通過再次使用高中數(shù)學(xué),給定一組 2D 數(shù)據(jù)點(diǎn),我們嘗試通過插值擬合曲線,該曲線在某種程度上代表了定義這些數(shù)據(jù)點(diǎn)的函數(shù)。我們擬合的函數(shù)越復(fù)雜(例如在插值中,通過多項(xiàng)式次數(shù)確定),它就越適合數(shù)據(jù);但是,它對(duì)新數(shù)據(jù)點(diǎn)的泛化程度越低。這就是深度學(xué)習(xí)面臨挑戰(zhàn)的地方,也就是通常所說的過度擬合問題:盡可能地?cái)M合數(shù)據(jù),但在泛化方面有所妥協(xié)。幾乎所有深度學(xué)習(xí)架構(gòu)都必須處理這個(gè)重要因素,才能學(xué)習(xí)在看不見的數(shù)據(jù)上表現(xiàn)同樣出色的通用功能。 深度學(xué)習(xí)先驅(qū) Yann LeCun(卷積神經(jīng)網(wǎng)絡(luò)的創(chuàng)造者和 ACM 圖靈獎(jiǎng)獲得者)在他的推特上發(fā)帖(基于一篇論文):「深度學(xué)習(xí)并沒有你想象的那么令人印象深刻,因?yàn)樗鼉H僅是美化曲線擬合的插值。但是在高維中,沒有插值之類的東西。在高維空間,一切都是外推。」因此,作為函數(shù)學(xué)習(xí)的一部分,深度學(xué)習(xí)除了插值,或在某些情況下,外推。就這樣!
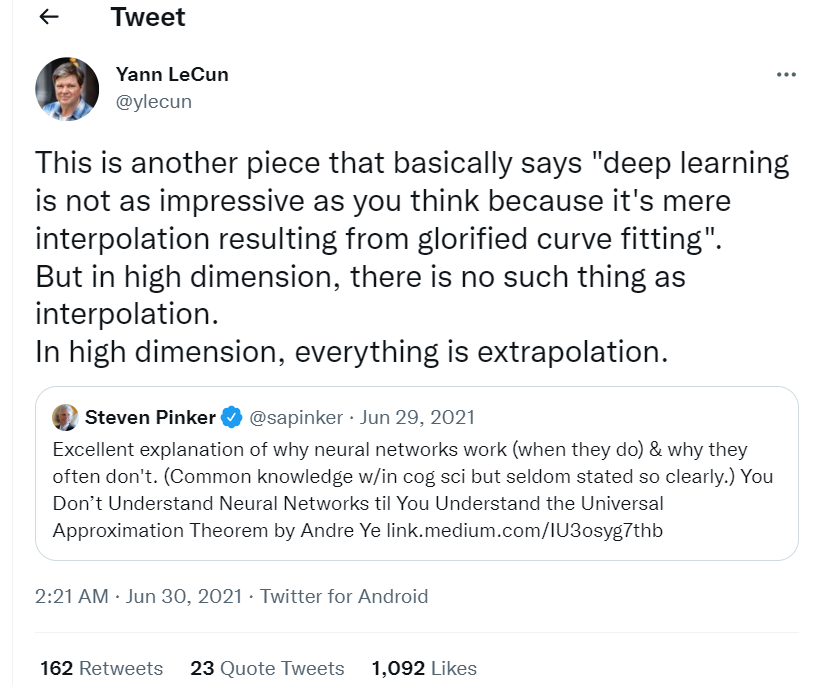
Twitter 地址:https://twitter.com/ylecun/status/1409940043951742981?lang=en
學(xué)習(xí)方面
那么,我們?nèi)绾螌W(xué)習(xí)這個(gè)復(fù)雜的函數(shù)呢?這完全取決于手頭的問題,而這決定了神經(jīng)網(wǎng)絡(luò)架構(gòu)。如果我們對(duì)圖像分類感興趣,那么我們使用 CNN。如果我們對(duì)時(shí)間相關(guān)的預(yù)測(cè)或文本感興趣,那么我們使用 RNN 或 Transformer,如果我們有動(dòng)態(tài)環(huán)境(如汽車駕駛),那么我們使用強(qiáng)化學(xué)習(xí)。除此之外,學(xué)習(xí)還涉及處理不同的挑戰(zhàn):
確保模型學(xué)習(xí)通用函數(shù),而不僅僅適合訓(xùn)練數(shù)據(jù);這是通過使用正則化處理的;
根據(jù)手頭的問題,選擇損失函數(shù);松散地說,損失函數(shù)是我們想要的(真實(shí)值)和我們當(dāng)前擁有的(當(dāng)前預(yù)測(cè))之間的誤差函數(shù);
梯度下降是用于收斂到最優(yōu)函數(shù)的算法;決定學(xué)習(xí)率變得具有挑戰(zhàn)性,因?yàn)楫?dāng)我們遠(yuǎn)離最優(yōu)時(shí),我們想要更快地走向最優(yōu),而當(dāng)我們接近最優(yōu)時(shí),我們想要慢一些,以確保我們收斂到最優(yōu)和全局最小值;
大量隱藏層需要處理梯度消失問題;跳過連接和適當(dāng)?shù)姆蔷€性激活函數(shù)等架構(gòu)變化,有助于解決這個(gè)問題。
計(jì)算挑戰(zhàn)
現(xiàn)在我們知道深度學(xué)習(xí)只是一個(gè)學(xué)習(xí)復(fù)雜的函數(shù),它帶來了其他計(jì)算挑戰(zhàn):
要學(xué)習(xí)一個(gè)復(fù)雜的函數(shù),我們需要大量的數(shù)據(jù);
為了處理大數(shù)據(jù),我們需要快速的計(jì)算環(huán)境;
我們需要一個(gè)支持這種環(huán)境的基礎(chǔ)設(shè)施。
使用 CPU 進(jìn)行并行處理不足以計(jì)算數(shù)百萬或數(shù)十億的權(quán)重(也稱為 DL 的參數(shù))。神經(jīng)網(wǎng)絡(luò)需要學(xué)習(xí)需要向量(或張量)乘法的權(quán)重。這就是 GPU 派上用場(chǎng)的地方,因?yàn)樗鼈兛梢苑浅?焖俚剡M(jìn)行并行向量乘法。根據(jù)深度學(xué)習(xí)架構(gòu)、數(shù)據(jù)大小和手頭的任務(wù),我們有時(shí)需要 1 個(gè) GPU,有時(shí),數(shù)據(jù)科學(xué)家需要根據(jù)已知文獻(xiàn)或通過測(cè)量 1 個(gè) GPU 的性能來做出決策。 通過使用適當(dāng)?shù)纳窠?jīng)網(wǎng)絡(luò)架構(gòu)(層數(shù)、神經(jīng)元數(shù)量、非線性函數(shù)等)以及足夠大的數(shù)據(jù),深度學(xué)習(xí)網(wǎng)絡(luò)可以學(xué)習(xí)從一個(gè)向量空間到另一個(gè)向量空間的任何映射。這就是讓深度學(xué)習(xí)成為任何機(jī)器學(xué)習(xí)任務(wù)的強(qiáng)大工具的原因。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4762瀏覽量
100535 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45927 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120975
原文標(biāo)題:這就是深度學(xué)習(xí)如此強(qiáng)大的原因
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)模型
簡(jiǎn)單認(rèn)識(shí)深度神經(jīng)網(wǎng)絡(luò)
前饋神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)和常見激活函數(shù)
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
深度神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)方法
BP神經(jīng)網(wǎng)絡(luò)屬于DNN嗎
bp神經(jīng)網(wǎng)絡(luò)是深度神經(jīng)網(wǎng)絡(luò)嗎
BP神經(jīng)網(wǎng)絡(luò)激活函數(shù)怎么選擇
卷積神經(jīng)網(wǎng)絡(luò)激活函數(shù)的作用
深度學(xué)習(xí)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用
卷積神經(jīng)網(wǎng)絡(luò)的原理是什么
卷積神經(jīng)網(wǎng)絡(luò)和bp神經(jīng)網(wǎng)絡(luò)的區(qū)別
深度神經(jīng)網(wǎng)絡(luò)模型有哪些
神經(jīng)網(wǎng)絡(luò)中的激活函數(shù)有哪些
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論