 如何用GPUDirect存儲器如何緩解CPU I / O瓶頸
如何用GPUDirect存儲器如何緩解CPU I / O瓶頸
保持 GPUs 忙碌
隨著 AI 和 HPC 數據集的大小不斷增加,加載給定應用程序的數據所花費的時間開始對整個應用程序的性能造成壓力。在考慮端到端應用程序性能時,快速 GPUs 越來越缺乏慢 I / O 。
I / O ,將數據從存儲器加載到 GPUs 進行處理的過程,歷史上一直由 CPU 控制。隨著計算速度從較慢的 CPU 轉移到更快的 GPUs , I / O 成為整個應用程序性能的瓶頸。
正如 GPU 直接 RDMA (遠程直接存儲器地址)在網絡接口卡( NIC )和 GPU 內存之間直接移動數據時提高了帶寬和延遲,一種稱為 GPU 直接存儲的新技術使本地或遠程存儲(如 NVMe 或 NVMe over Fabric , NVMe oF )和 GPU 內存之間實現了直接數據路徑。 GPU 直接 RDMA 和 GPU 直接存儲器都避免了通過 CPU 內存中的反彈緩沖區的額外拷貝,并使 NIC 或存儲器附近的直接內存訪問( DMA )引擎能夠在直接路徑上將數據移入或移出 GPU 內存—所有這些都不會給 CPU 或 GPU 帶來負擔。如圖 1 所示。對于 GPU 直接存儲,存儲位置無關緊要;它可以在機柜內、機架內或通過網絡連接。在 CPU DGX-2 中,從 NVIDIA 系統內存( SysMem )到 GPUs 的帶寬被限制為 50gb / s ,而來自 SysMem 、許多本地驅動器和許多 NICs 的帶寬可以組合起來,從而在 DGX-2 中達到近 200gb / s 的帶寬上限。
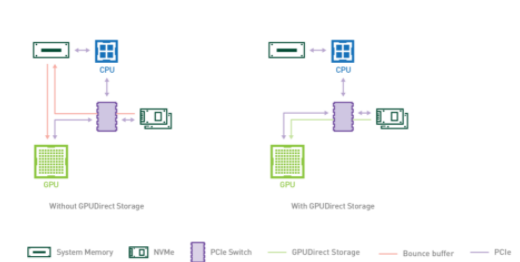
圖 1 : GPU 內存和 NVMe 驅動器之間的標準路徑使用系統內存中掛起的反彈緩沖區 CPU 。通過完全跳過 CPU ,來自存儲器的直接數據路徑獲得了更高的帶寬。
在本博客中,我們將擴展到一個 上一篇文章 演示 GPU 直接存儲:一個概念證明,可以通過 NVMe 從位于給定服務器的本地存儲或機柜外部的存儲器直接訪問內存( DMA )。我們證明了從存儲器到 GPU 的直接內存訪問緩解了 CPU I / O 瓶頸,并提高了 I / O 帶寬和容量。此外,我們根據 RAPIDS 項目的 GPU – 加速 CSV 閱讀器 提供了在圣何塞 GTC19 上展示的初始性能指標。最后,我們將提供一些關鍵應用程序的建議,這些應用程序可以利用更快和更高的帶寬、更低的延遲和更大的存儲與 GPUs 之間的容量。
在以后的文章中,當這個特性接近產品化時,我們將描述如何對它進行編程。一組新的 cuFile API 將被添加到 CUDA 中,以支持這個特性,并將本機集成到 RAPIDS ‘ cuDF 庫中。
直接內存訪問是如何工作的?
PCI Express ( PCIe )接口將高速外圍設備(如網卡、 RAID / NVMe 存儲設備和 GPUs 連接到 CPU s 。用于 Volta GPUs 的系統接口 PCIe Gen3 可提供 16 GB / s 的聚合最大帶寬。一旦將協議頭的低效率和其他開銷考慮在內,最大可達數據速率超過 14gb / s 。
直接內存訪問( DMA )使用復制引擎在 PCIe 上異步移動大數據塊,而不是加載和存儲。它卸載了計算元素,讓它們可以自由地進行其他工作。在 GPUs 和存儲相關設備(如 NVMe 驅動程序和存儲控制器)中有 DMA 引擎,但通常在 CPU 中沒有。在某些情況下, DMA 引擎無法針對給定的目標進行編程;例如, GPU DMA 引擎不能以存儲為目標。沒有 GPU 直接存儲,存儲 DMA 引擎無法通過文件系統以 GPU 內存為目標。
然而, DMA 引擎需要由 CPU 上的驅動程序編程。當 CPU 對 GPU 的 DMA 進行編程時,從 CPU 到 GPU 的命令可能會干擾到 GPU 的其他命令。如果可以使用 NVMe 驅動器或存儲附近其他地方的 DMA 引擎來移動數據,而不是使用 GPU 的 DMA 引擎,那么 CPU 和 GPU 之間的路徑就沒有干擾。與 GPU 的 DMA 引擎相比,我們在本地 NVMe 驅動器上使用 DMA 引擎將 I / O 帶寬提高到 13 。 3 GB / s ,相對于下表 1 所示的 12 。 0 GB / s 的 CPU 到 GPU 內存傳輸速率,性能提高了大約 10% 。
緩解 I / O 瓶頸及相關應用
隨著研究人員將數據分析、人工智能和其他 GPU 加速應用程序應用于越來越大的數據集,其中一些數據集將無法完全放入 CPU 內存甚至本地存儲,因此,緩解存儲和 GPU 內存之間的數據路徑上的 I / O 瓶頸將變得越來越重要。數據分析應用程序對大量數據進行操作,這些數據往往從存儲中流入。在許多情況下,計算與通信的比率(也許用每字節的 flops 表示)非常低,這使得它們受到 IO 限制。例如,為了使深度學習能夠成功地訓練神經網絡,每天要訪問許多組文件,每個文件的大小為 10MB ,并多次讀取。在這種情況下,優化數據傳輸到 GPU 可能會對訓練人工智能模型的總時間產生重大而有益的影響。除了數據攝取優化之外,深度學習培訓還經常涉及檢查點的過程,即在模型訓練過程的各個階段,將訓練好的網絡權重保存到磁盤上。根據定義,檢查點位于關鍵 I / O 路徑上,減少相關開銷可以縮短檢查點周期和加快模型恢復。
除了數據分析和深度學習之外,研究網絡交互的圖形分析還有很高的 I / O 需求。當遍歷一個圖來尋找有影響的節點或從這里到那里的最短路徑時,計算只占總求解時間的一小部分。從當前節點開始,確定下一步要去哪里,可能涉及來自一個 PB 大小的數據湖的 1 到數百個文件的 I / O 查詢。雖然本地緩存有助于跟蹤可直接操作的數據,但圖形遍歷對延遲和帶寬都很敏感。隨著 NVIDIA 通過 cuGraph 庫 RAPIDS 擴展了 GPU 圖形分析加速功能,消除文件 I / O 開銷對于繼續提供光速解決方案至關重要。
將存儲和帶寬選項擴展到 GPUs
數據分析和人工智能之間的一個共同主題是,用于獲取見解的數據集通常是海量的。 NVIDIA DGX-2 由 16 個 Tesla V100 組成,包含 30TB NVMe SSD 內存( 8x 3 。 84TB )和 1 。 5TB 系統內存的庫存配置。啟用驅動器的 DMA 操作允許快速訪問內存,同時增加帶寬、降低延遲和潛在的無限存儲容量。
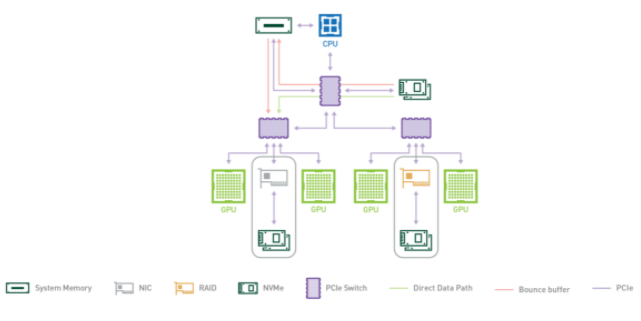
圖 2 :從存儲模塊外部獲得更多帶寬和更多存儲空間。遠離 PCI 交換機的 NIC 支持 NVMe-oF 的遠程存儲擴展,而 RAID 卡支持附近的存儲。所示的 RAID 卡僅為原型,并不表示當前或未來的 DGX-2 產品。
DGX-2 機柜包含兩個 CPU ,每個 CPU 都有兩個 PCIe 子樹實例,如圖 2 所示。從存儲器或 SysMem 到 GPUs 的多條 PCIe 路徑由兩個級別的 PCIe 交換機支持,這使得 DGX-2 成為 GPU 直接存儲原型化的良好測試工具。表 1 的左列列出了向 GPU 傳輸數據的各種來源,第二列列出了從該源測得的帶寬,第三列標識了此類路徑的數量,最后一列是中間兩列的乘積,顯示了該類源可用的總帶寬。對于 4 個 PCIe 樹( 12-12 。 5 GB / s )中的每一個,從 CPU 的系統內存( SysMem )有一條路徑,另一條路徑來自每個 PCIe 樹上掛起的?個驅動器的另一條路徑,速度為 13 。 3 GB / s 。 DGX-2s 每對 GPUs 都有一個 PCIe 插槽。該插槽可以由一個 NIC 占用,該 NIC 的測量速度為 10 。 5 GB / s ,或者,在本博客中使用的原型中,可以使用 RAID 卡,其測量速度為 14 GB / s 。 NVMe of ( over fabric )是一種通用協議,它使用 NIC 訪問遠程存儲,例如通過 Infiniband 網絡。如果在 8 個 PCIe 插槽中使用 RAID 卡(圖 2 中每個 PCIe 子樹 2 個),則在所有源上添加的 PCIe 帶寬的右側列總和為 215 GB / s ;如果在這些插槽中使用 NIC ,則總和會更低。
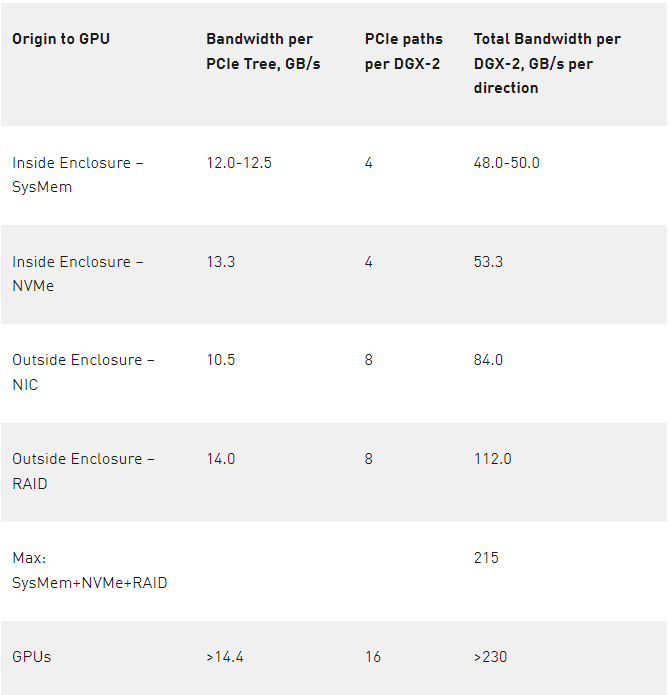
表 1 : DGX-2 到 GPUs 的帶寬選項。機柜內有 4 個 PCIe 子樹和 8 個 NIC 或 RAID 卡。
GPU 直接存儲的一個主要優點是,無論是存儲在存儲模塊內部還是外部、系統內存或 NVMe 驅動器上的快速數據訪問都是跨各種源的累加。使用內部 NVMe 和系統內存并不排除使用 NVMe 或 RAID 存儲。最后,這些帶寬是雙向的,支持復雜的編排,其中數據可以從分布式存儲中引入,緩存在本地磁盤中,并且可以通過在 CPU 系統內存***享的數據結構與 CPU 協作,總帶寬超過 GPU 峰值 IO 的 90% 。對這三個源中的每一個的讀寫操作可能同時發生。圖 3 對各種來源進行顏色編碼,并將相加組合顯示為堆疊條形圖。在下面的列標簽中,源實例的數量在括號中,例如 16 個 NVMe 驅動器或 8 個執行 NVMe 操作的 NIC 。每個選項可用的粗略容量顯示在列標簽的最后。
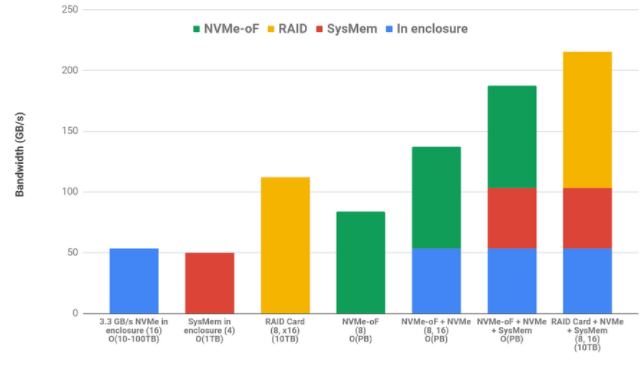
圖 3 :來自不同來源的帶寬限制是累加的
GPU CSV 閱讀器加速案例研究
NVIDIA 支持的 RAPIDS 開源軟件 專注于端到端 GPU ——加速數據科學。其中一個庫 cuDF 提供了類似 pandas 的體驗,允許用戶在 GPU 上加載、過濾、連接、排序和瀏覽數據集。 NVIDIA 工程師能夠利用 GPU 直接存儲到 GPU 上,使吞吐量比原始的 cuDF CSV 閱讀器提高了 8 。 8 倍,比 cuDF 庫更新后使用的當前最大努力實現速度提高了 1 。 5 倍。這些改進如圖 4 所示。
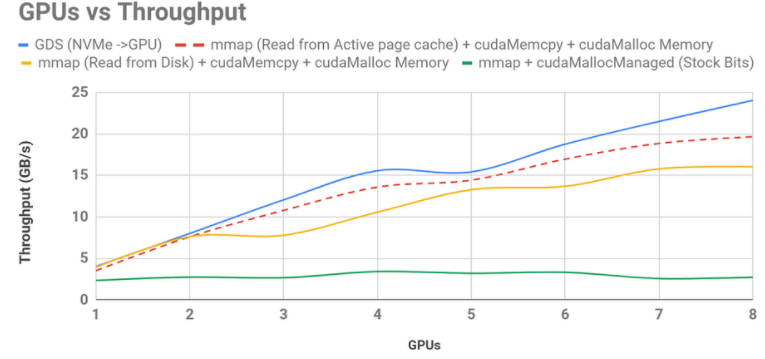
圖 4 :最初的( 0 。 7 ) cuDF csv 峎 u 讀卡器實現,在底部以綠色顯示,它沒有按 GPU 并發進行伸縮,因為它導致從 SysMem 到 GPU 的錯誤,從存儲到 SysMem 的錯誤,以及通過 CPU 緩沖區取消固定的數據移動。現在隨 RAPIDS 一起發布的改進的 bounce buffer 實現使用了最好的可用內存管理,顯式的數據移動以黃色顯示。從預熱頁緩存讀取數據顯示為紅色虛線,藍色的 GPU 直接存儲優于所有這些,僅受 NVMe 驅動器速度的限制。這些測量碰巧只使用了 8 個 GPUs 和 8 個 NVMe 驅動器。
此外,直接數據路徑將 80 GB 數據的端到端延遲降低了 3 。 8 倍。在另一個對 16 GPUs 的 cuDF CSV 閱讀器研究中,如圖 5 所示,使用藍色的直接、非錯誤數據路徑,讀取帶寬更平滑、更可預測、延遲更低,而改進的直接 cuDF 行為仍然使用紅色的反彈緩沖區,或黃色的原始行為。
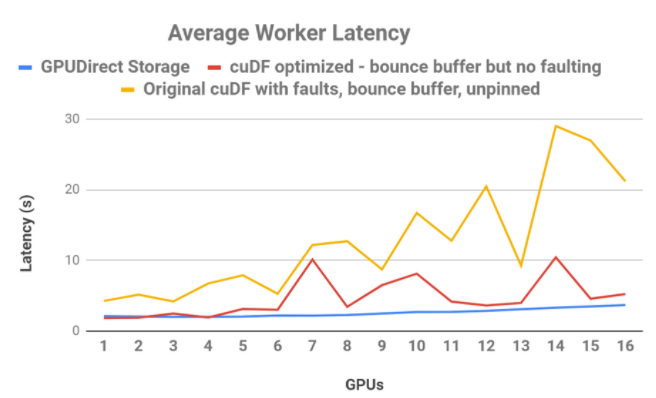
圖 5 : cuDF read _ csv 的延遲比較。當 CPU 反彈緩沖區在帶有錯誤(黃色)的原始 cuDF 版本中使用時,作為 GPUs 函數的延遲是不穩定和不穩定的。 cuDF 已經過優化,以消除直接傳輸( red )的故障,從而提高了性能和穩定性。 GPU 直接存儲(藍色),在處理擴展到額外的 GPUs 時提供平滑和可預測的延遲。
帶寬和 CPU 負載研究
圖 6 突出顯示了不同傳輸方法可實現的相對帶寬。可以使用緩沖 I / O 將數據從存儲器傳輸到 CPU 內存,并使用文件系統的頁緩存(黃線)進行保留。使用頁緩存有一些開銷,比如在 CPU 內存中增加一個副本,但是相對于 DMA 從存儲器中取出數據并使用一個緩沖區(紅線)直到傳輸大小足夠大,足以分攤 DMA 編程時,這是一個勝利。因為使用 GPUDirect 存儲(藍線)的存儲器和 GPU 之間的帶寬比 CPU 和 GPU 之間的帶寬要高得多,所以它可以在任何傳輸大小下獲勝。
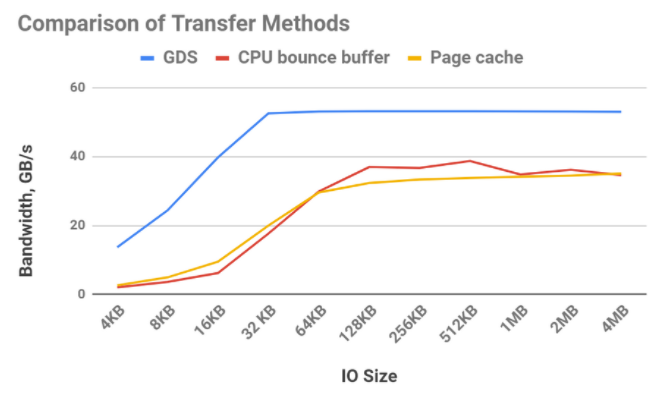
圖 6 : GPU 直接存儲( GDS )的帶寬明顯優于使用緩沖區( CPU GPU )或使用緩沖 IO 啟用文件系統的頁緩存。 16 個 NVMe 驅動器與 16 個 GPUs 一起使用。
獲得更高的帶寬是一回事,但有些應用程序對 CPU 負載很敏感。如果我們檢查這三種方法的帶寬除以 CPU 利用率,結果會更加引人注目,如圖 7 所示。
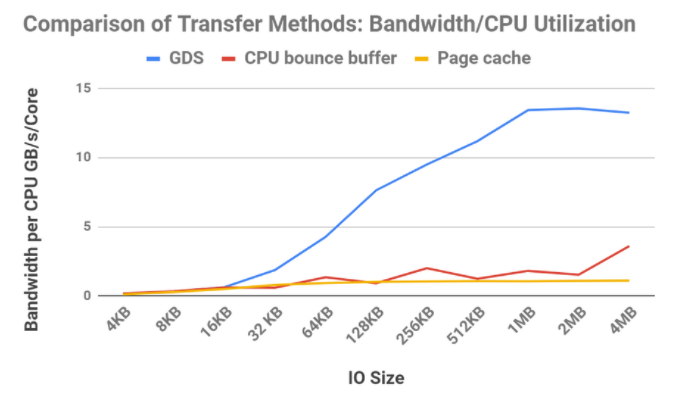
圖 7 :帶寬除以 CPU 核心的部分利用率。16個 NVMe 驅動器與16個 GPU 一起使用
TPC-H 案例研究
TPC-H 是一個決策支持基準。對于這個基準測試有很多查詢,我們主要關注 QueryFour ( Q4 ),它傳輸大量數據,并對這些數據的 GPU 進行一些處理。數據的大小由比例因子( SF )決定。比例因子 1K 意味著數據集的大小接近 1TB ( 82 。 4GB 的二進制數據); 10K 意味著 10 倍的大小,這不能完全放入 CPU 內存中。在非 GPU 直接存儲的情況下, CPU 內存中的空間必須被分配,從磁盤中填充,然后釋放,如果數據可以在消耗時按需直接傳輸到 GPU 內存中,那么所有這些都需要時間,而這些時間最終都是無關緊要的。圖 8 顯示了與不使用 GPU 直接存儲相比, GPU 直接存儲具有較大的性能提升: SF 1K 為 6 。 7 倍, SF 10K 為 32 。 8 倍。
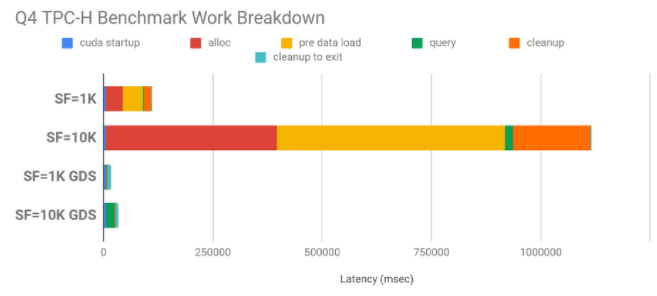
圖 8 : TPC-H 查詢 4 ,有和沒有 GPU 直接存儲( GDS )。使用了 1K (~ 1TB )和 10K (~ 10TB )的比例因子( SF ),加速分別為 4 。 9x 和 19 。 6x 。 CPU 內存中的重復分配、將數據加載到內存中以及釋放 CPU 側的內存是 GPU 直接存儲中避免的大瓶頸。
數據***案例研究
從存儲器到 GPU 的直接路徑也適用于不完全適合 GPU 幀緩沖區的數據集。在一個實驗中, NVIDIA 使用了 1TB 的輸入數據集和 DGX-2 的 512GB 聚合 GPU 內存,用 GPU 直接存儲來證明,即使在內存超額訂閱的情況下, 16 GPUs 的數據 I / O 速度也比主機內存快。直接讀取和寫入數據的速度提高了 2 倍,但分塊、使用更小的批處理和其他優化進一步提高了速度。總的來說, GPU 直接存儲將數據操作速度提高了 4 。 3 倍。
GPU 直接存儲的值
GPU 直接存儲器提供的關鍵功能是,它使 DMA 能夠通過這個文件系統從存儲器到 GPU 存儲器。它以多種方式提供價值:
2-8 倍的帶寬,直接在存儲器和 GPU 之間傳輸數據。
顯式的數據傳輸既不出錯也不經過跳出緩沖區,也具有較低的延遲;我們演示了低 3 。 8 倍的端到端延遲的示例。
避免顯式和直接傳輸的錯誤可以使延遲在 GPU 并發性增加時保持穩定和平坦。
在存儲器附近使用 DMA 引擎對 CPU 負載的影響較小,并且不會干擾 GPU 負載。使用更大尺寸的 GPU 直接存儲,帶寬與部分 CPU 利用率之比要高得多。我們觀察到(但沒有在本博客中以圖形方式顯示)當其他 DMA 引擎將數據推入或拉入 GPU 內存時, GPU 利用率仍然接近于零。
GPU 不僅成為帶寬最高的計算引擎,而且成為 IO 帶寬最高的計算單元,例如 215 GB / s ,而 CPU 的 50 GB / s 。
無論數據存儲在何處,所有這些好處都是可以實現的——實現對 PB 級遠程存儲的快速訪問,甚至比 CPU 內存中的頁緩存都要快。
從 CPU 存儲器、本地存儲器和遠程存儲器進入 GPU 存儲器的帶寬可以相加地組合起來,使進入和流出 GPUs 的帶寬幾乎飽和。這變得越來越重要,來自大型分布式數據集的數據被緩存在本地存儲器中,工作表可以緩存在 CPU 系統內存中,并與 CPU 協同使用。
除了使用 GPUs 而不是 CPU 加快計算的好處外,一旦整個數據處理管道轉移到 GPU 執行,直接存儲就起到了一個力倍增器的作用。這一點變得尤為重要,因為數據集大小不再適合系統內存,而且 GPUs 的數據 I / O 增長成為處理時間的瓶頸。當人工智能和數據科學繼續重新定義可能的藝術時,啟用直接路徑可以減少甚至完全緩解這個瓶頸。
關于作者
Adam Thompson 是 NVIDIA 的高級解決方案架構師。他有信號處理方面的背景,他的職業生涯一直在參與和領導一些項目,這些項目專注于射頻分類、數據壓縮、高性能計算、統計信號處理以及管理和設計針對大數據框架的應用程序。他擁有喬治亞理工大學電子與計算機工程碩士學位和克萊姆森大學學士學位。
CJ Newburn 是 NVIDIA 計算軟件組的首席架構師,他領導 HPC 戰略和軟件產品路線圖,特別關注系統和規模編程模型。 CJ 是 Magnum IO 的架構師和 GPU Direct Storage 的聯合架構師,與能源部領導 Summit Dev 系列產品,并領導 HPC 容器咨詢委員會。在過去的 20 年里, CJ 為硬件和軟件技術做出了貢獻,擁有 100 多項專利。他是一個社區建設者,熱衷于將硬件和軟件平臺的核心功能從 HPC 擴展到 AI 、數據科學和可視化。在卡內基梅隆大學獲得博士學位之前, CJ 曾在幾家初創公司工作過,致力于語音識別器和 VLIW 超級計算機。他很高興能為他媽媽使用的批量產品工作。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102820 -
gpu
+關注
關注
28文章
4702瀏覽量
128710 -
計算機
+關注
關注
19文章
7425瀏覽量
87722
發布評論請先 登錄
相關推薦
什么是ROM存儲器的定義
內存儲器主要用來存儲什么
內存儲器分為隨機存儲器和什么
高速緩沖存儲器有什么作用

PLC主要使用的存儲器類型
內部存儲器有哪些
ram存儲器和rom存儲器的區別是什么
虛擬存儲器的概念和特征
內存儲器與外存儲器的主要區別
存儲器和寄存器的區別
全面解析存儲器層次結構原理
I/O接口防靜電保護方案設計及ESD二極管選型
隨機訪問存儲器(RAM)和只讀存儲器(ROM)的區別





 工商網監
工商網監
評論