") Magnum IO存儲的優(yōu)點和實施
Magnum IO存儲的優(yōu)點和實施
這是世界上第四個帖子加速 IO系列它解決了存儲問題,并與我們的合作伙伴分享了最近的成果和方向。我們將介紹新的 GPU 直接存儲版本、優(yōu)點和實施。
加速計算需要加速 IO 。否則,計算資源就會缺乏數(shù)據(jù)。考慮到所有工作流程中數(shù)據(jù)存儲在內(nèi)存中的比例正在減少,優(yōu)化存儲 IO 變得越來越重要。存儲數(shù)據(jù)的價值、竊取或破壞數(shù)據(jù)的行為以及保護(hù)數(shù)據(jù)的法規(guī)要求也在不斷增加。為此,人們對數(shù)據(jù)中心基礎(chǔ)設(shè)施的需求日益增長,這些基礎(chǔ)設(shè)施可以為用戶提供更大程度的隔離,使其與不應(yīng)訪問的數(shù)據(jù)隔離開來。
GPU 直接存儲
GPU 直接存儲簡化了存儲和 GPU 緩沖區(qū)之間的數(shù)據(jù)流,適用于在 GPU 上消費(fèi)或生成數(shù)據(jù)而無需 CPU 處理的應(yīng)用程序。不需要增加延遲和阻礙帶寬的額外拷貝。這種簡單的優(yōu)化導(dǎo)致了改變游戲規(guī)則的角色轉(zhuǎn)換,數(shù)據(jù)可以更快地從遠(yuǎn)程存儲(而不是 CPU 內(nèi)存)饋送到 GPU s 。
GPU 直系親屬的最新成員
GPUDirect系列技術(shù)能夠訪問 GPU 并有效地將數(shù)據(jù)移入和移出 GPU 。直到最近,它還專注于內(nèi)存到內(nèi)存的傳輸。隨著 GPU 直接存儲(GDS)的添加,使用存儲的訪問和數(shù)據(jù)移動也加快了。 GPU 直接存儲使在本地和遠(yuǎn)程存儲之間向 CUDA 添加文件IO邁出了重要的一步。
使用 CUDA 11 . 4 發(fā)布 v1 . 0
GPU 直接存儲經(jīng)過兩年多的審查,目前可作為生產(chǎn)軟件使用。 GDS 以前僅通過單獨(dú)安裝提供,現(xiàn)在已并入 CUDA 11 . 4 版及更高版本,它可以是 CUDA 安裝的一部分,也可以單獨(dú)安裝。對于 CUDA 版本X-Y的安裝,libcufile-X-Y. so 用戶庫gds-tools-X-Y默認(rèn)安裝,nvidia-fs.ko內(nèi)核驅(qū)動程序是可選安裝。有關(guān)更多信息,請參閱 GDS故障排除和安裝文檔。
GDS 現(xiàn)在在RAPIDS中提供。它還有PyTorch 集裝箱和MXNet 容器兩種版本。
GDS 說明和好處
GPU 直接存儲啟用存儲和 GPU 內(nèi)存之間的直接數(shù)據(jù)路徑。在本地 NVMe 驅(qū)動器或與遠(yuǎn)程存儲器通信的 NIC 中,使用直接內(nèi)存訪問( DMA )引擎移動數(shù)據(jù)。
使用該 DMA 引擎意味著,盡管 DMA 的設(shè)置是一個 CPU 操作, CPU 和 GPU 完全不涉及數(shù)據(jù)路徑,使它們自由且不受阻礙(圖 1 )。在左側(cè),來自存儲器的數(shù)據(jù)通過 PCIe 交換機(jī)進(jìn)入,通過 CPU 進(jìn)入系統(tǒng)內(nèi)存,然后一直返回 GPU 。在右側(cè),數(shù)據(jù)路徑跳過 CPU 和系統(tǒng)內(nèi)存。下面總結(jié)了這些好處。
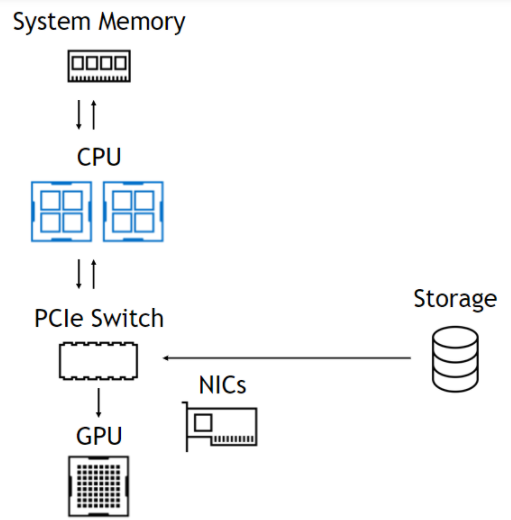
無 GPU 直接存儲
受進(jìn)出 CPU 的帶寬限制。導(dǎo)致 CPU 反彈緩沖區(qū)的延遲。內(nèi)存容量限制為 0 ( 1TB )。存儲不是 CUDA 的一部分。沒有基于拓?fù)涞膬?yōu)化。
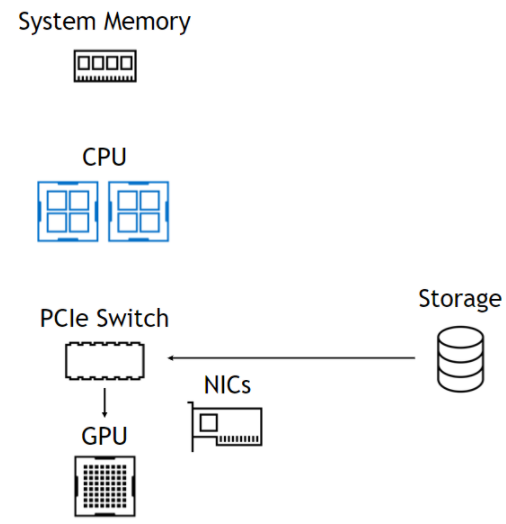
使用 GPU 直接存儲
GPU 的帶寬僅受 NIC 限制。由于直接復(fù)制,延遲更低。訪問 O ( PB )容量。簡單的 CUDA 編程模型。通過 NVLink 、 GPU 緩沖區(qū)自適應(yīng)路由。
圖 1 . GDS 軟件堆棧,其中應(yīng)用程序使用 cuFile API ,啟用 GDS 的存儲驅(qū)動程序調(diào)用nvidia-fs.ko內(nèi)核驅(qū)動程序以獲得正確的 DMA 地址。
GPU 直接存儲提供了三個基本的性能優(yōu)勢:
增加帶寬:通過消除通過 CPU 中的反彈緩沖區(qū)的需要,在某些平臺上可以使用備用路徑,包括通過 PCIe 交換機(jī)或 NVLink 提供更高帶寬的平臺。雖然 DGX 平臺同時具有 PCIe 交換機(jī)和 NVLink ,但并非所有平臺都具有。我們建議使用這兩種方法來最大限度地提高性能。火星著陸器的例子實現(xiàn)了 8 倍的帶寬增益。
潛伏期縮短:通過 CPU 內(nèi)存避免額外拷貝的延遲和管理內(nèi)存的開銷(在極端情況下可能非常嚴(yán)重),從而減少延遲。延遲減少 3 倍是常見的。
CPU 利用率降低:使用跳出緩沖區(qū)會在 CPU 上引入額外的操作,以執(zhí)行額外的復(fù)制和管理內(nèi)存緩沖區(qū)。當(dāng) CPU 利用率成為瓶頸時,有效帶寬會顯著下降。我們測量了多個文件系統(tǒng)的 CPU 利用率提高了 3 倍。
沒有 GDS ,只有一條可用的數(shù)據(jù)路徑:從存儲器到 CPU ,從 CPU 到具有 CUDA Memcpy 的相關(guān) GPU 。對于 GDS ,還有其他可用的優(yōu)化:
用于與 DMA 引擎交互的 CPU 線程與最近的 CPU 內(nèi)核密切相關(guān)。
如果存儲器和 GPU 掛斷不同的插槽,并且 NVLink 是可用的連接,則數(shù)據(jù)可通過存儲器附近的 GPU 內(nèi)存中的快速反彈緩沖區(qū)暫存,然后使用 CUDA 傳輸?shù)阶罱K的 GPU 內(nèi)存目標(biāo)緩沖區(qū)。這可能比使用 intersocket 路徑(例如 UPI )快得多。
沒有cudaMemcpy參與分割 IO 傳輸,以適應(yīng) GPU BAR1 孔徑,其大小隨 GPU SKU 變化,或者在目標(biāo)緩沖區(qū)未固定cuFileBufRegister的情況下,分割到預(yù)固定緩沖區(qū)。這些操作由libcufile.so用戶庫代碼管理。
處理未對齊的訪問,其中要傳輸?shù)奈募械臄?shù)據(jù)偏移量與頁面邊界不對齊。
在未來的GDS版本中,cuFileAPI將支持異步和批處理操作。這使得 CUDA 內(nèi)核能夠在 CUDA 流中的讀取之后對其進(jìn)行排序,該 CUDA 流為該內(nèi)核提供輸入,并且在生成要寫入的數(shù)據(jù)的內(nèi)核之后對寫入進(jìn)行排序。隨著時間的推移,cuFileAPI也將在 CUDA 圖形的上下文中可用。
表 1 顯示了 NVIDIA DGX-2 和 DGX A100 系統(tǒng)的峰值和測量帶寬。該數(shù)據(jù)表明,在理想條件下,從本地存儲到 GPU s 的可實現(xiàn)帶寬超過了 CPU 內(nèi)存的最大帶寬,最高可達(dá) 1 TB 。通常從 PB 級遠(yuǎn)程內(nèi)存測量的帶寬可能是 CPU 內(nèi)存實際提供帶寬的兩倍以上。
將 GPU 內(nèi)存中無法容納的數(shù)據(jù)溢出到甚至 PB 的遠(yuǎn)程存儲中,可能會超過將其分頁回 CPU 內(nèi)存中 1 TB 的可實現(xiàn)性能。這是歷史的一次顯著逆轉(zhuǎn)。
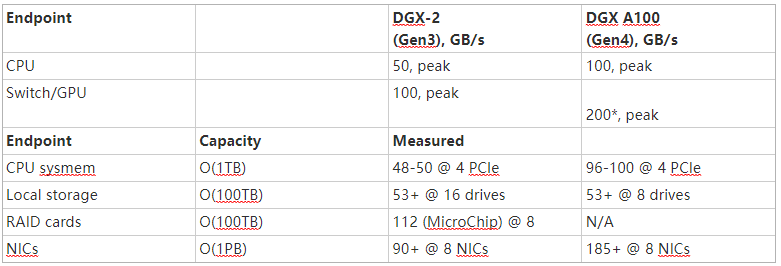
表 1 .在帶寬超過 CPU 內(nèi)存 1 TB 的情況下,可以訪問數(shù) PB 的數(shù)據(jù)。
*此處顯示的 NVIDIA GPU 直接存儲在 NVIDIA DGX A100 插槽 0-3 和 6-9 上的性能數(shù)字不是官方支持的網(wǎng)絡(luò)配置,僅供實驗使用。為計算和存儲共享相同的網(wǎng)絡(luò)適配器可能會影響 NVIDIA 先前在 DGX A100 系統(tǒng)上發(fā)布的標(biāo)準(zhǔn)或其他基準(zhǔn)測試的性能。
GDS 的工作原理
NVIDIA 尋求盡可能采用現(xiàn)有標(biāo)準(zhǔn),并在必要時明智地擴(kuò)展這些標(biāo)準(zhǔn)。 POSIX 標(biāo)準(zhǔn)的pread和pwrite提供了存儲和 CPU 緩沖區(qū)之間的拷貝,但尚未啟用到 GPU 緩沖區(qū)的拷貝。隨著時間的推移, Linux 內(nèi)核中不支持 GPU 緩沖區(qū)的缺點將得到解決。
一種稱為 dma _ buf 的解決方案正在進(jìn)行中,該解決方案支持 NIC 或 NVMe 和 GPU 等設(shè)備之間的拷貝,它們是 PCIe 總線上的對等設(shè)備,以解決這一差距。同時, GDS 帶來的性能提升太大,無法等待上游解決方案傳播到所有用戶。多種供應(yīng)商提供了支持 GDS 的替代解決方案,包括 MLNX _ OFED (表 2 )。 GDS 解決方案涉及與 POSIXpread和pwrite類似的新 APIcuFileRead或cuFileWrite。
動態(tài)路由、 NVLink 的使用以及 CUDA 流中使用的異步 API (僅可從 GDS 獲得)等優(yōu)化使cuFileAPI 成為 CUDA 編程模型的持久特性,即使在 Linux 文件系統(tǒng)中的漏洞得到解決之后也是如此。
以下是GDS實現(xiàn)的功能。首先,當(dāng)前Linux實現(xiàn)的基本問題是通過虛擬文件系統(tǒng)(VFS)向下傳遞 GPU 緩沖區(qū)地址作為DMA目標(biāo),以便本地NVMe或網(wǎng)絡(luò)適配器中的DMA引擎可以執(zhí)行到 GPU 內(nèi)存或從 GPU 內(nèi)存的傳輸。這會導(dǎo)致出現(xiàn)錯誤情況。我們現(xiàn)在有辦法解決這個問題:在 CPU 內(nèi)存中傳遞一個緩沖區(qū)地址。
當(dāng)使用cuFileAPI (如cuFileRead或cuFileWrite)時,libcufile。因此,用戶級庫捕獲 GPU 緩沖區(qū)地址,并替換傳遞給 VFS 的代理 CPU 緩沖區(qū)地址。就在緩沖區(qū)地址用于 DMA 之前,啟用 GDS 的驅(qū)動程序?qū)vidia-fs.ko的調(diào)用識別 CPU 緩沖區(qū)地址,并再次提供替代 GPU 緩沖區(qū)地址,以便 DMA 可以正確進(jìn)行。
libcufile.so中的邏輯執(zhí)行前面描述的各種優(yōu)化,如動態(tài)路由、預(yù)固定緩沖區(qū)的使用和對齊。圖 2 顯示了用于此優(yōu)化的堆棧。cuFileAPI 是 Magnum IO 靈活抽象體系結(jié)構(gòu)原則的一個示例,它支持特定于平臺的創(chuàng)新和優(yōu)化,如選擇性緩沖和 NVLink 的使用。
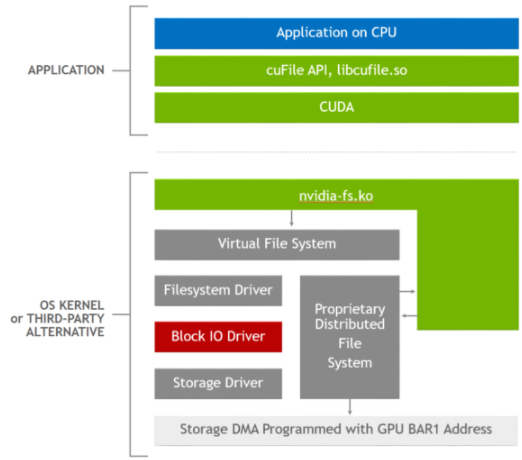
圖 2 . GDS 軟件堆棧,其中應(yīng)用程序使用 cuFile API ,啟用 GDS 的存儲驅(qū)動程序調(diào)用 NVIDIA -fs . ko 內(nèi)核驅(qū)動程序以獲得正確的 DMA 地址。
關(guān)于作者
CJ Newburn 是 NVIDIA 計算軟件組的首席架構(gòu)師,他領(lǐng)導(dǎo) HPC 戰(zhàn)略和軟件產(chǎn)品路線圖,特別關(guān)注系統(tǒng)和規(guī)模編程模型。 CJ 是 Magnum IO 的架構(gòu)師和 GPU Direct Storage 的聯(lián)合架構(gòu)師,與能源部領(lǐng)導(dǎo) Summit Dev 系列產(chǎn)品,并領(lǐng)導(dǎo) HPC 容器咨詢委員會。在過去的 20 年里, CJ 為硬件和軟件技術(shù)做出了貢獻(xiàn),擁有 100 多項專利。他是一個社區(qū)建設(shè)者,熱衷于將硬件和軟件平臺的核心功能從 HPC 擴(kuò)展到 AI 、數(shù)據(jù)科學(xué)和可視化。在卡內(nèi)基梅隆大學(xué)獲得博士學(xué)位之前, CJ 曾在幾家初創(chuàng)公司工作過,致力于語音識別器和 VLIW 超級計算機(jī)。他很高興能為他媽媽使用的批量產(chǎn)品工作。
Kiran K. Modukuri 是 NVIDIA 的首席軟件工程師,負(fù)責(zé)加速 IO 管道。他是 GPU 直接存儲產(chǎn)品的聯(lián)合架構(gòu)師。在加入 NVIDIA 之前,他曾在 NetApp 擔(dān)任高級軟件工程師。他在亞利桑那大學(xué)獲得了計算機(jī)科學(xué)碩士學(xué)位。他在分布式文件系統(tǒng)和存儲技術(shù)方面擁有超過 15 年的經(jīng)驗。
Kushal Datta 是 Magnum IO 的產(chǎn)品負(fù)責(zé)人,專注于加速多 GPU 系統(tǒng)上的 AI 、數(shù)據(jù)分析和 HPC 應(yīng)用程序。他的興趣包括創(chuàng)建新的工具和方法,以提高復(fù)雜人工智能和大規(guī)模系統(tǒng)上的科學(xué)應(yīng)用的總掛鐘時間。他發(fā)表了 20 多篇學(xué)術(shù)論文、多篇白皮書和博客文章。他擁有五項美國專利。他在北卡羅來納大學(xué)夏洛特分校獲得歐洲經(jīng)委會博士學(xué)位,并在印度賈達(dá)夫普爾大學(xué)獲得計算機(jī)科學(xué)學(xué)士學(xué)位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4940瀏覽量
102818 -
計算機(jī)
+關(guān)注
關(guān)注
19文章
7424瀏覽量
87719 -
AI
+關(guān)注
關(guān)注
87文章
30163瀏覽量
268427
發(fā)布評論請先 登錄
相關(guān)推薦
一文解讀Linux 5種IO模型
華納云監(jiān)視Linux磁盤IO性能命令:iotop,iostat,vmstat,atop,dstat,ioping
本地IO與遠(yuǎn)程IO:揭秘工業(yè)自動化中的兩大關(guān)鍵角色
NAND Flash與其他類型存儲器的區(qū)別
Linux磁盤IO詳細(xì)解析

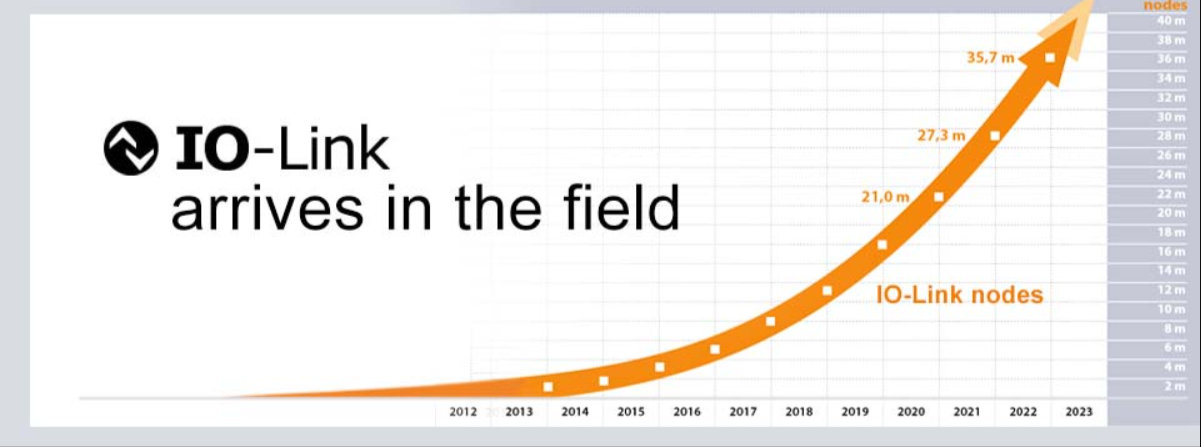
初識IO-Link及IO-Link設(shè)備軟件協(xié)議棧
遠(yuǎn)程IO與分布式IO的區(qū)別
存儲虛擬化有哪些常見類型?有什么優(yōu)點?
什么是智能存儲系統(tǒng)?對比傳統(tǒng)存儲柜,智能存儲柜有哪些優(yōu)點?

EtherCAT IO的接線方法和流程是怎樣的?
SSD硬盤的優(yōu)點和缺點
鉭電容的優(yōu)點和缺點
存儲信息的方式有哪些種類
淺談符號IO域和圖形IO域





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論