 用NVIDIA TSPP和Triton推理服務器加速模型推理
用NVIDIA TSPP和Triton推理服務器加速模型推理
在這篇文章中,我們詳細介紹了最近發布的 NVIDIA 時間序列預測平臺( TSPP ),這是一個設計用于輕松比較和實驗預測模型、時間序列數據集和其他配置的任意組合的工具。 TSPP 還提供了探索超參數搜索空間的功能,使用分布式訓練和自動混合精度( AMP )運行加速模型訓練,并在NVIDIA Triton 推理服務器上加速和運行加速模型格式的推理。
事實證明,在理解和管理復雜系統(包括但不限于電網、供應鏈和金融市場)時,使用以前的值準確預測未來的時間序列值至關重要。在這些預測應用中,預測精度的單位百分比提高可能會產生巨大的財務、生態和社會影響。除了需要精確之外,預測模型還必須能夠在實時時間尺度上運行。
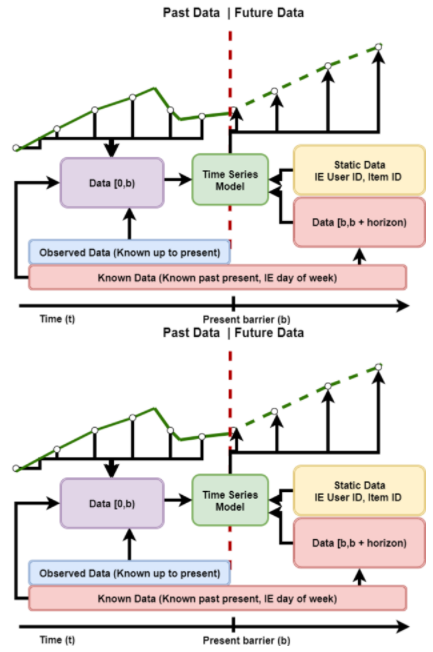
圖 1 :典型滑動窗口時間序列預測問題的描述。每個滑動窗口都由時間序列數據組成,這些數據分為過去和未來兩部分。
滑動窗口預測問題,如圖 1 所示,涉及使用先前的數據和未來值的知識來預測未來的目標值。傳統的統計方法,如 ARIMA 及其變體,或 Holt-Winters 回歸,長期以來一直用于執行這些任務的回歸。然而,隨著數據量的增加和回歸所要解決的問題變得越來越復雜, 深度學習方法已經證明它們能夠有效地表示和理解這些問題。
盡管出現了深度學習預測模型,但從歷史上看,還沒有一種方法可以有效地在任意一組數據集中試驗和比較時間序列模型的性能和準確性。為此,我們很高興公開開源 NVIDIA 時間序列預測平臺 。
什么是 TSPP ?
時間序列預測平臺是一個端到端的框架,使用戶能夠訓練、調整和部署時間序列模型。其分層配置系統和豐富的功能規范 API 允許輕松集成和試驗新模型、數據集、優化器和指標。 TSPP 設計用于香草 PyTorch 型號,對云或本地平臺不可知。

圖 2 :NVIDIA 時間序列預測平臺的基本架構。 CLI 向 TSPP 啟動器提供輸入,后者實例化訓練所需的對象(模型、數據集等),并運行指定的實驗以生成性能和準確性結果。
TSPP 如圖 2 所示,以命令行控制的啟動器為中心。根據用戶對 CLI 的輸入,啟動器可以實例化 hyperparameter 管理器,該管理器可以并行運行一組訓練實驗,也可以通過創建所描述的組件(如模型、數據集、度量等)來運行單個實驗。
支持的模型
TSPP 默認支持 NVIDIA 優化時間融合變壓器 ( TFT )。在 TSPP 中, TFT 訓練可以使用多 GPU 訓練、自動混合精度和指數移動權重平均來加速。可以使用上述推理和部署管道部署模型。
TFT 模型是一種混合架構,將 LSTM 編碼和可解釋 transformer 注意層結合在一起。預測基于三種類型的變量:靜態(給定時間序列的常數)、已知(整個歷史和未來提前知道)、觀察(僅歷史數據已知)。所有這些變量都有兩種類型:分類變量和連續變量。除了歷史數據,我們還向模型提供時間序列本身的歷史值。
通過學習嵌入向量,將所有變量嵌入高維空間。范疇變量嵌入是在嵌入離散值的經典意義上學習的。該模型為每個連續變量學習一個向量,然后根據該變量的值進行縮放,以便進一步處理。下一步是通過變量選擇網絡( VSN )過濾變量,該網絡根據輸入與預測的相關性為輸入分配權重。靜態變量用作其他變量的變量選擇上下文,以及 LSTM 編碼器的初始狀態。
編碼后,變量被傳遞給多頭注意層(解碼器),從而產生最終的預測。整個體系結構與剩余連接交織在一起,門控機制允許體系結構適應各種問題。

圖 3 : TFT 架構圖: Bryan Lim 、 Sercan O.Arik 、 Nicolas Loeff 、 Tomas Pfister ,來自可解釋多地平線時間序列預測的時間融合轉換器, 2019 年。
加速訓練
在使用深度學習模型進行實驗時,訓練加速可以極大地增加在給定時間內可以進行的實驗迭代次數。時間序列預測平臺提供了通過自動混合精度、多 GPU 訓練和指數移動權重平均的任意組合來加速訓練的能力。
訓練快速開始
一旦進入 TSPP 容器,運行 TSPP 就很簡單,只需結合數據集、模型和其他您想要使用的組件調用啟動器。例如,要使用電力數據集訓練 TFT ,我們只需調用:
Python launch_tspp.py dataset=electricity model=tft criterion=quantile
生成的日志、檢查點和初始配置將保存到輸出中。有關包含更復雜工作流的示例,請參考 repository 文檔。
自動混合精度
自動混合精度( AMP )是深度學習培訓的一種執行模式,適用的計算以 16 位精度而不是 32 位精度計算。 AMP 執行可以極大地加快深度學習訓練,而不會降低準確性。 AMP 包含在 TSPP 中,只需在啟動呼叫中添加一個標志即可啟用。
多 GPU 訓練
多 GPU 數據并行訓練通過在所有可用 GPU 上并行運行模型計算來增加全局批量大小,從而加速模型訓練。這種方法可以在不損失模型精度的情況下大大縮短模型訓練時間,尤其是在使用了許多 GPU 的情況下。它通過 PyTorch DistributedDataParallel 包含在 TSPP 中,只需在啟動調用中添加一個元素即可啟用。
指數移動加權平均
指數移動加權平均是一種技術,它維護一個模型的兩個副本,一個通過反向傳播進行訓練,另一個模型是第一個模型權重的加權平均。在測試和推理時,平均權重用于計算輸出。實踐證明,這種方法可以縮短收斂時間,提高收斂精度,但代價是模型 GPU 內存需求翻倍。 EMWA 包含在 TSPP 中,只需在啟動調用中添加一個標志即可啟用。
沒有超參數
模型超參數調整是深度學習模型的模型開發和實驗過程中必不可少的一部分。為此, TSPP 包含與 Optuna 超參數搜索庫的豐富集成。用戶可以通過指定要搜索的超參數名稱和分布來運行廣泛的超參數搜索。一旦完成, TSPP 可以并行運行多 GPU 或單 GPU 試驗,直到探索出所需數量的超參數選項。
搜索完成時, TSPP 將返回最佳單次運行的超參數,以及所有運行的日志文件。為了便于比較,日志文件是用NVIDIA DLLOGER 生成的,并且易于搜索,并且與張量板繪圖兼容。
可配置性
TSPP 中的可配置性由 Facebook 提供的開源庫 Hydra 驅動。 Hydra 允許用戶使用運行時組合的 YAML 文件定義分層配置系統,使啟動運行簡單到聲明“我想用這個數據集嘗試這個模型”。
特性規范
特征規范包含在配置的數據集部分,是時間序列數據集的標準描述語言。它對每個表格特征的屬性進行編碼,其中包含關于未來是已知的、觀察到的還是靜態的、特征是分類的還是連續的以及更多可選屬性的信息。這種描述語言為模型提供了一個框架,可以根據任意描述的輸入自動配置自己。
組件集成
向 TSPP 添加一個新的數據集非常簡單,只需為其創建一個功能規范并描述數據集本身。一旦定義了特征規范和其他一些關鍵值,與 TSPP 集成的模型將能夠根據新的數據集進行配置。
將新模型添加到 TSPP 只需要模型期望特性規范提供的數據位于正確的通道中。如果模型正確地解釋了功能規范,那么模型應該與集成到 TSPP 、過去和未來的所有數據集一起工作。
除了模型和數據集, TSPP 還支持任意組件的集成,例如標準、優化器和目標度量。通過使用 Hydra 使用 config 直接實例化對象,用戶可以集成他們自己的定制組件,并在 TSPP 發布時使用該規范。
推理和部署
推理是任何 Machine Learning 管道的關鍵組成部分。為此, TSPP 內置了推理支持,可與平臺無縫集成。除了支持本機推理, TSPP 還支持將轉換后的模型單步部署到 NVIDIA Triton 推理服務器。
NVIDIA Triton 型號導航器
TSPP 為 NVIDIA Triton 型號導航器 。兼容的模型可以輕松轉換為優化的格式,包括 TorchScript 、 ONNX 和 NVIDIA TensorRT 。在同一步驟中,這些轉換后的模型將部署到 NVIDIA Triton 推理服務器 。甚至可以選擇在單個步驟中對給定模型進行剖面分析和生成舵圖。例如,給定一個 TFT 輸出文件夾,我們可以通過使用以下命令導出到 ONNX ,將模型轉換并部署為 fp16 中的 NVIDIA TensorRT 格式:
Python launch_deployment.py export=onnx convert=trt config.inference.precision=fp16 config.evaluator.checkpoint=/path/to/output/folder/
TFT 模型
我們在兩個數據集上對 TSPP 內的 TFT 進行了基準測試: UCI 數據集存儲庫中的電力負荷(電力)數據集和 PEMs 流量數據集(流量)。 TFT 在兩個數據集上都取得了很好的結果,在兩個數據集上都實現了最低的可見誤差,并證實了 TFT 論文作者的評估。

表 1 :
訓練表現
圖 4 和圖 5 分別顯示了電力和交通數據集上 TFT 的每秒吞吐量。每個批次大小為 1024 ,包含來自同一數據集中不同時間序列的各種時間窗口。使用自動混合精度計算了 100 次運行。顯然, TFT 在 A100 GPU 上具有優異的性能和可擴展性,尤其是與在 96 核 CPU 上執行相比。

圖 4:GPU 上電力數據集的 TFT 訓練吞吐量與 CPU 的對比。 GPU : 8x Tesla A100 80 GB 。 CPU:Intel ( R ) Xeon ( R ) Platinum 8168 CPU @ 2.70GHz ( 96 線程)。

圖 5 。 GPU 上流量數據集的 TFT 訓練吞吐量與 CPU 。 GPU : 8x Tesla A100 80 GB 。 CPU:Intel ( R ) Xeon ( R ) Platinum 8168 CPU @ 2.70GHz ( 96 線程)。
訓練時間
圖 6 和圖 7 分別顯示了 TFT 在電力和交通數據集上的端到端訓練時間。每個批次大小為 1024 ,包含來自同一數據集中不同時間序列的各種時間窗口。使用自動混合精度計算 100 次完成的運行。在這些實驗中,在 GPU 上, TFT 的訓練時間為分鐘,而 CPU 的訓練時間約為半天。
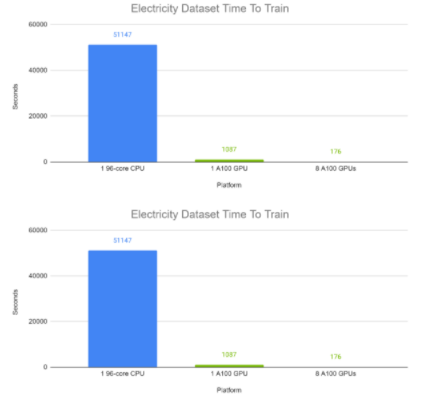
圖 6:TFT 在 GPU 上的電力數據集上的端到端訓練時間與 CPU 的比較。 GPU : 8x Tesla A100 80 GB 。 CPU:Intel ( R ) Xeon ( R ) Platinum 8168 CPU @ 2.70GHz ( 96 線程)。
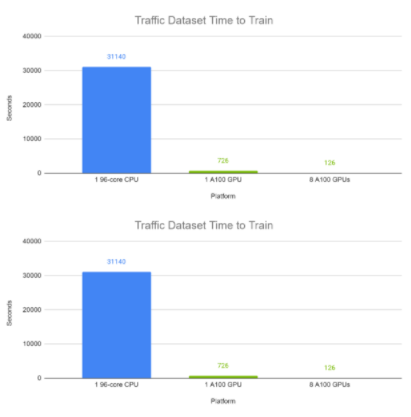
圖 7:TFT 在 GPU 上的流量數據集上的端到端訓練時間與 CPU 的比較。 GPU : 8x Tesla A100 80 GB 。 CPU:Intel ( R ) Xeon ( R ) Platinum 8168 CPU @ 2.70GHz ( 96 線程)。
推理性能
圖 8 和圖 9 展示了電力數據集上不同批量大小的 A100 80GB GPU 與 96 核 CPU 的相對單設備推理吞吐量和平均延遲。由于較大的批量大小通常產生更大的推斷吞吐量,所以我們考慮 1024 元素批處理結果,其中顯而易見的是, A100 GPU 具有令人難以置信的性能,每秒處理大約 50000 個樣本。此外,更大的批量往往會導致更高的延遲,從 CPU 值可以明顯看出,這似乎與批量成正比。相比之下,與 CPU 相比, A100 GPU 具有接近恒定的平均延遲。
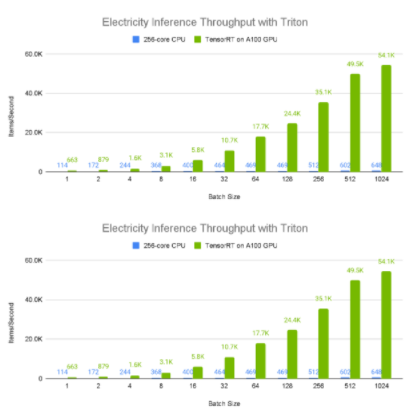
圖 8:TFT 在 GPU vs CPU 上部署到 NVIDIA Triton 推理服務器容器 21.12 時的電量數據集吞吐量。 GPU :使用 TensorRT 8.2 部署 1x Tesla A100 80 GB 。 CPU :使用 ONNX 部署的雙 AMD Rome 7742 ,總計 128 核@ 2.25 GHz (基本), 3.4 GHz (最大提升)( 256 個線程)。

圖 9:TFT 在 GPU vs CPU 上部署到 NVIDIA Triton 推理服務器容器 21.12 時,電力數據集的平均延遲。 GPU :使用 TensorRT 8.2 部署 1x Tesla A100 80 GB 。 CPU :使用 ONNX 部署的雙 AMD Rome 7742 ,總計 128 核@ 2.25 GHz (基本), 3.4 GHz (最大提升)( 256 個線程)。
端到端示例
結合前面的例子,我們演示了 TFT 模型在電力數據集上的簡單訓練和部署。我們首先從源代碼構建并啟動 TSPP 容器:
cd DeeplearningExamples/Tools/PyTorch/TimeSeriesPredictionPlatform source scripts/setup.sh docker build -t tspp . docker run -it --gpus all --ipc=host --network=host -v /your/datasets/:/workspace/datasets/ tspp bash
接下來,我們使用電力數據集 TFT 和分位數損耗啟動 TSPP 。我們還讓 10 年的歷次訓練負擔過重。一旦對模型進行了培訓,就會在 outputs /{ date }/{ time }中創建日志、配置文件和經過培訓的檢查點,在本例中為 outputs / 01-02-2022 /:
Python launch_tspp.py dataset=electricity model=tft criterion=quantile config.trainer.num_epochs=10
使用檢查點目錄,可以將模型轉換為 NVIDIA TensorRT 格式,并部署到 NVIDIA Triton 推理服務器。
Python launch_deployment.py export=onnx convert=trt config.evaluator.checkpoint=/path/to/checkpoint/folder/
可利用性
NVIDIA 時間序列預測平臺提供從訓練到時間序列模型的推斷的端到端 GPU 加速。平臺中包含的參考示例經過優化和認證,可在 NVIDIA DGX A100 和 NVIDIA 認證系統上運行。
關于作者
Kyle Kranen 是NVIDIA 的深度學習軟件工程師。他在加利福尼亞大學伯克利分校獲得電氣工程和計算機科學學士學位。在NVIDIA ,他的研究目前集中在推薦系統和時間序列建模上。
Pawel Morkisz 是一位深度學習算法經理。他擁有計算數學博士學位。在NVIDIA ,他專注于推動時間序列和推薦系統的深度學習算法。
Carl (Izzy) Putterman 最近加入 NVIDIA ,擔任深度學習算法工程師。他畢業于加利福尼亞大學,伯克利在應用數學和計算機科學學士學位。在 NVIDIA ,他目前致力于時間序列建模和圖形神經網絡,重點是推理。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102817 -
深度學習
+關注
關注
73文章
5492瀏覽量
120978
發布評論請先 登錄
相關推薦

高效大模型的推理綜述

FPGA和ASIC在大模型推理加速中的應用

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

AMD助力HyperAccel開發全新AI推理服務器







 工商網監
工商網監
評論